LLM 日本語データセット向けに C++ で minhash 重複除去を行うメモ
ChatGPT クンにレヴューさせたのでこちら参考にして読んでね
背景
LLM 向けデータセット(コーパス)では重複のない品質の高いデータセットが重要となります.
よくあるのは minhash で fuzzy に行うのと, suffix array で exact に行うもののようです.
(RefinedWeb 論文 https://arxiv.org/abs/2306.01116 より)
今回は minhash での fuzzy dedup を取り上げます.
参考となる実装は HojiChar にありますが, いかんせん Python はやはり遅い...
C++ でやります!
情報
minhash
- テキストの N-gram 表現を作る. これに対して hash を計算する.
- hash を BUCKET_SIZE(b) * N_BUCKET(r) の合計 k 個用意する
- 通常はハッシュ関数(アルゴリズム)は同じで, seed を変えて対応
- ハッシュ関数は衝突が少ないものがよい. murmurhash3 がよく使われるようであるが, FNV などの軽量ハッシュ関数でもいいかも https://qiita.com/yamasaki-masahide/items/d478dd111690bc84784a
- N-gram の item M 個に対してハッシュを計算し, 値が小さいのを選んで保存 => k 個の hash 値
- v: b 個のハッシュを連結して一つの値にする
- optional: b-bit minhash: BUCKET_SIZE から b bit(HojiChar では 2 byte(b = 16bit))切り出し, BUCKET_SIZE * (b / 8) バイトのハッシュ値を N_BUCKET ぶん作る
- bucket(r 個)内のいずれかで連結した値 v が一致したら, potential match とする
Jaccard similarity
minhash で potential match したものにしたいして,
1 - (1 - s^b)^r で potential match 率(?)が求まる.
s は Jaccard index(生真面目に計算した Jaccard 係数)っぽい.
b = 20, r = 450 だと, Jaccard index s がおよそ 0.8 になると, potential match が 1.0 となる(つまり, hash の重複が一つでもあると, 確率的に Jaccard 係数はおよそ 0.8 以上)
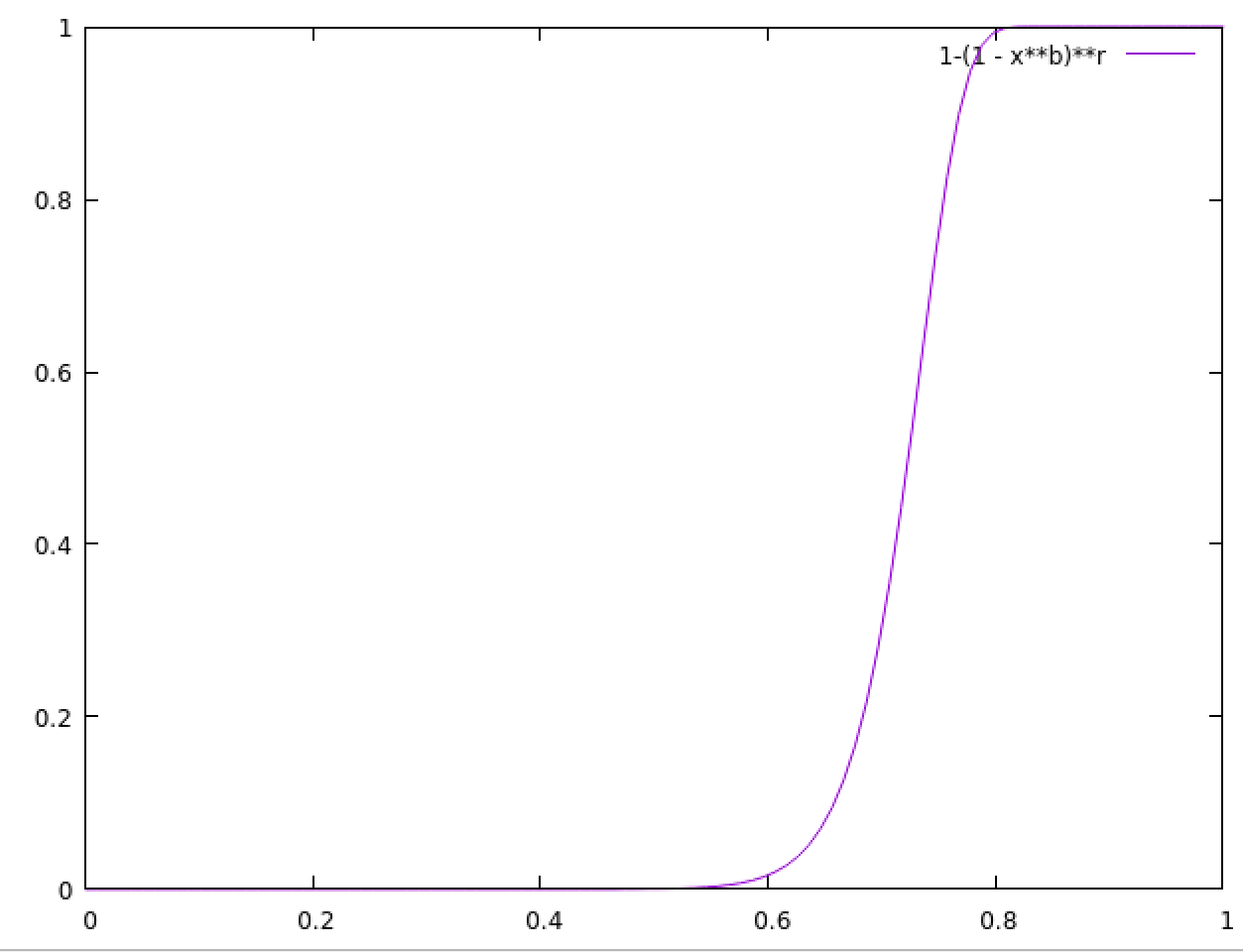
b = 20, r = 10 だと 0.96 くらい

b = 20, r = 40 だと 0.9 くらい

したがって r(N_BUCKETS) は大きいほうがよいが, 計算量との兼ね合い.
false positive 対策のため, potential match したのに対して実際に Jaccard index を求めるのがよいようであるが, 計算量次第ではこれはスキップしてもよいでしょう.
(RefinedWeb ではスキップしている)
また, よりよい dedup をするためにここから The edit similarity を算出(後述参照)する.
日本語の場合
日本語の場合は UTF-8 文字単位で処理が多い. 今回は UTF-8 文字単位にしましたが,
rinna tokenizer など, 日本語トークナイザを使う手もあるかもです.
また, 日本語は事前に dedup 向けに正規化(normalize)しておくのが推奨です.
5-gram?
HojiChar では 5-gram(5 文字)にしています.
The Pile や RefinedWeb も 5-gram ですが, これは英語で 5 単語づつなので, 日本語の場合はもうちょっと増やしてもいいのかもはしれません(8 とか)
実装
マルチスレッド化と template で struct など固定サイズにして効率化しましたが, 結構 naiive に実装したからか, すごい速いとはなりませんでした.
minhash 計算時間
75B tokens(jsonl + zstd 圧縮時 80 GB. 展開で 240 GB ほど)で, Ryzen9 3950X 16 コアで 225 分かかりました.
(json 読み書き, ngram 分解などの時間含む)
概ね 5.5 M chars(日本語文字)/sec という感じでしょうか.
dedup
あとは minhash のハッシュ値で重複判定すればいけます.
bucket 単位で判定したり, マッチした hash / key_items で近似 Jaccard 係数を出してしきい値(0.7 など)以上であれば一致と判断するのがよいようですが, LLM データセットの場合は重複が無いのが重要となるため, 今回は bucket 単位は無視し, 一個でも hash 値がすでにあるかどうかで重複判断するようにしました.
これにより, 重複していないが, 重複と判断されてしまうのも出てくるでしょうがが,
LLM データセットでは重複があるよりは無い方がよいのでまあヨシ! とします.
ちなみに 1 document 200 個(20 x 10) hash 計算では概ね 8 ~ 11 % ほどの重複判断となりました(下記参照)
unordered_set の keyer
とりま重複管理に std::unordered_set 使いました.
unordered_set, unordered_map の場合は key の hasher が必要になります.
key の各要素はすでにハッシュ値になっていますので, hash combine をするだけでよいです.
今回は cityhash を使いました.
murmurhash3 なハッシュ値を cityhash で key combine して(効率良いのかどうか)は要検証ですね.
template<uint32_t BUCKET_SIZE = 10, uint32_t B = 2>
struct MinHashValHasher
{
static_assert(B == 2, "B must be 2 for now.");
size_t operator()(const MinHashVal<BUCKET_SIZE, B> &k) const {
size_t seed = k.vals[0];
for (uint32_t i = 1; i < k.nitems(); i++) {
hash_combine(seed, k.vals[i]);
}
return seed;
}
};
実装
dedup 処理時間
TOTAL: duplicated 10066046 documents(total 91701905). ratio = 10.9769 %
real 49m51.016s
およそ 75 B tokens(~200 GB), ドキュメント数(JSON アイテム数) 9,170 万で 11 % ほどの重複を除去となりました.
処理時間は i9-12900K 1 core で 50 分ほどでした.
今回は dedup 用にテキストの正規化(数字は 0 にする, 句点は除くなど)はしていないので, テキスト正規化して minhash 計算したらもうちょっと dedup rate 上がるかもしれません.
さらなる高みを目指して
mimhash 高速化
あたりが参考になるでしょう.
日本語の場合, ほぼ 3 bytes として 3 * N gram 単位で処理したり, uint32_t で char 表現(トークナイズ)してもいいかもしれません.
dedup のマルチスレッド化, out-of-core 対応
minhash 自体はスレッド化しやすいですが, dedup で set はそのままではマルチスレッド化しづらいです.
bucket 単位もしくは, set の key のハッシュ値の上位 8 byte で 256 entry 作るなどしたらいい感じになるやもはしれません.
LLM 向けデータセット構築ではおおむね minhash dedup での重複率が 5 ~ 10 % と想定し, 全文(全ドキュメント)に対して重複判定したいだけであれば, hash 値を一括で読んでソートさせてで判定もよさそうです.
(hash 値の場合ある程度一様に分布していると考えられるので, ソート処理も worst case にはならずにできると予想)
あとは今後より大きなデータセットを dedup するときに, メモリに入らない場合は NVMe 使って out-of-core 処理とか.
よりよい dedup
Deduplicating Training Data Makes Language Models Better
RefinedWeb では Lee et al. 2001 と同じ設定で, 5-gram 表現を使い, ドキュメントあたり 9000 hashes(20 * 450 buckets)を計算しています!
↑の HojiChar だと The Pile と同様に 20 * 10 buckets(200 hashes)になっています.
(RefienedWeb では 10 buckets では lower dedup rate になってしまうとある)
Lee et al. では minhash での potential match と求まった Jaccard index が 0.8 以上の場合に, edit similarity を計算して類似度判定をしています(document の graph(なんの?)を構築する必要がありちょっと実装はめんどそう)
TODO
-
minhash で Bucket 単位で dedup 場合としない場合でどうなるか調査する
- 非 bucket 単位と判定の精度が同じくらいになるのであれば, bucket 単位でマルチスレッドで dedup 処理することができそう
Discussion