MonoDepth2でKITTI Datasetを単眼Depth推定してみる



モデル概要
目的
自己教師あり学習によるアプローチで、単眼深度推定を行う
コアとなるアイディア
- 単眼Depth推定を教師なし学習によって行う
- Depth CNNとPose CNNの二つのネットワークで構成される
- Depth CNNはターゲット画像(It)から深度マップを生成する
- Pose CNNはターゲット画像付近の時間軸画像(It-1, It+1)から対応点(P)の動きを推定
- DepthとPoseの結果から合成画像を生成し、ターゲット画像と比較を行い損失計算する

基となったモデル
SfMLearner
教師なしによる単眼Depth推定の先駆け的モデル
ネットワーク
- Depth network
- スキップ接続を用いたencoder-decoder構造
- 深度スケールの調整を行う
- Pose network
- ターゲット画像とソース画像を入力。出力はターゲットとソースの相対的な姿勢
- 各層で畳み込み後、global average poolingにより全空間位置の予測値を集約
- Explainability Maskという試みにより動く物体については損失計算しない

損失関数
- ターゲット画像と合成画像の比較による損失
- 合成画像とターゲット画像とで全ピクセルの絶対誤差を最小化
- 深度マップのsmoothness-loss
- 深度マップのグラデーションを滑らかにするため、予測された深度マップの2次勾配のL1ノルムを最小化
問題点や課題
- オクルージョンの推定に難あり(下画像の4,5行目)
- 深度マップにスケール不定性が残っている

今回のモデル
MonoDepth2
SfMLearner以降に改良されたモデル
ネットワーク
- SfMLearnerと同様にU-Net構造のDepthとPoseネットワークを持つ
改良点
- SfMLearnerで課題となっていたオクルージョンへの対応
- ターゲット画像と近い時間の画像(ソース画像)からいくつかの合成画像を生成し、それら合成画像から損失が最も小さいソース画像が選択されるようにする
- フレーム間で変化の無い物や並進している物体など、深度が無限大となる領域に対し損失の対象としないようマスクする
- 低解像度部分の深度マップにおける低テクスチャ領域が無限大として推定されてしまう問題への対応
- 低解像度の深度マップの解像度をアップサンプリングし、誤差計算を行う
問題点や課題
- 歪み、反射、色が飽和している領域に対して深度推定できないことがある(下画像)
- 深度マップにスケール不定性が残っている

動かしてみる
今回はpretrainモデルで、kittiデータセットの単眼depth推定を行います。
データセット準備
KITTIデータセットからテスト用のraw dataを取得
今回はCityの2011_09_26から始まる以下のファイルを取得する
- Data category: City
- 2011_09_26_drive_0117(synced+rectified data, calibration)
- 2011_09_26_drive_0104(synced+rectified data)
- 2011_09_26_drive_0096(synced+rectified data)
- 2011_09_26_drive_0093(synced+rectified data)
- 2011_09_26_drive_0084(synced+rectified data)
- 2011_09_26_drive_0009(synced+rectified data)
上記URLにアクセスし、以下の画像の項目から、上記ファイルを取得する(raw data全て欲しい場合は、monodepth2のgithubページからwgetなどで取得する方法が記してありますので、そちらを参考に)

モデル準備
- モデルをcloneする。
git clone https://github.com/FangGet/tf-monodepth2
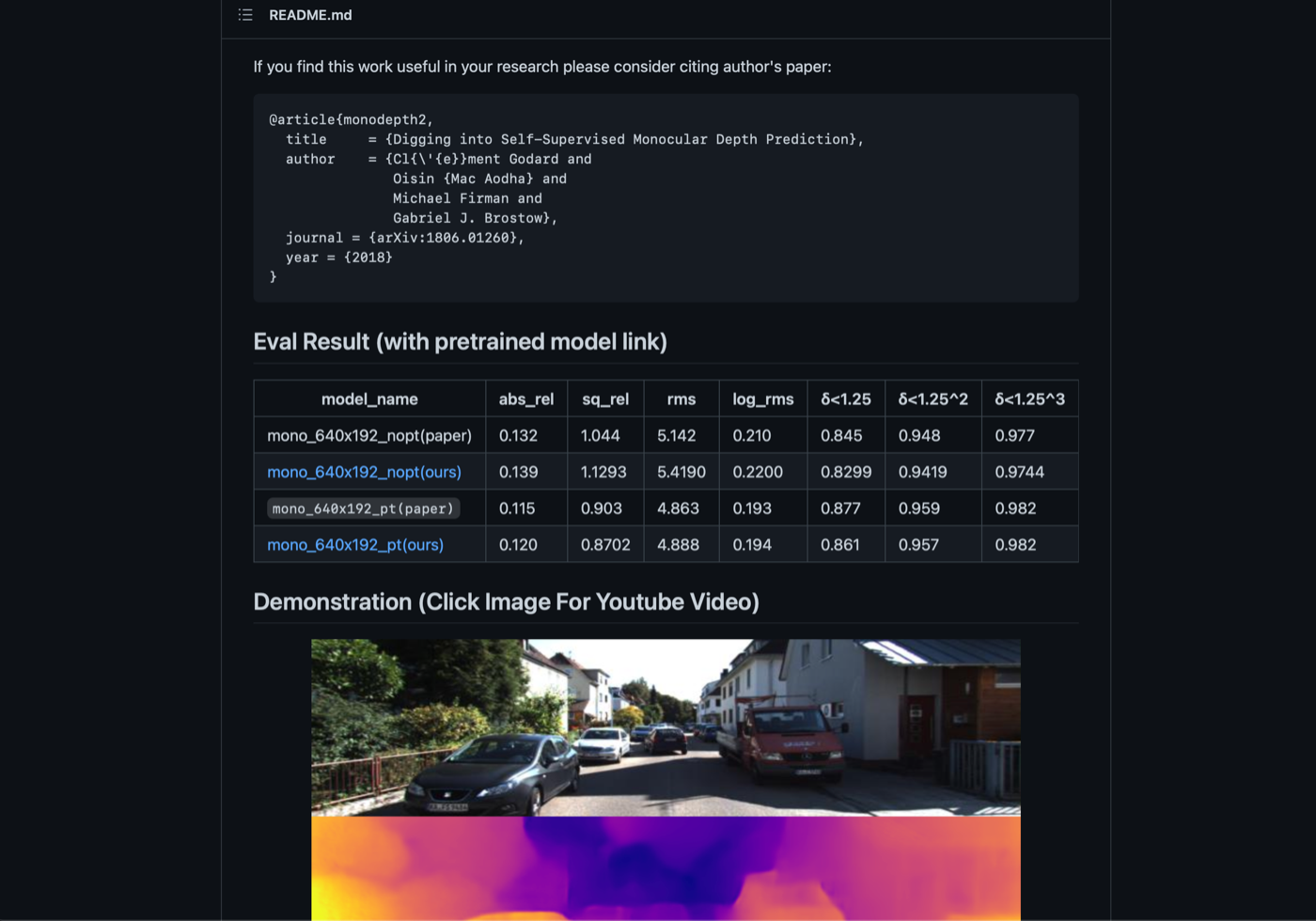
- Eval Result(with pretrained model link)の部分からmono_640x192_pt(ours)を取ってきます(取ってきたモデルは、tf-monodepth2-masterの直下に置いてください)。
前処理
- 先程取得したデータセットに対して以下の前処理を行います。
- PoseNetにターゲット画像とソース画像を渡すために、t-1,t,t+1の3枚をconcatした画像を作成する
- データセットを学習用とテスト用に分ける
- まず、以下のように取得したデータをdata/kitti/2011_09_26下に置き、caribrationファイルの中身を同じディレクトリに配置します。
~
├── data
│ ├── __init__.py
│ ├── cityscapes
│ │ ├── __init__.py
│ │ └── cityscapes_loader.py
│ ├── kitti
│ │ ├── 2011_09_26
│ │ │ ├── 2011_09_26_drive_0117_sync
│ │ │ ├── 2011_09_26_drive_0104_sync
│ │ │ ├── 2011_09_26_drive_0096_sync
│ │ │ ├── 2011_09_26_drive_0093_sync
│ │ │ ├── 2011_09_26_drive_0094_sync
│ │ │ ├── 2011_09_26_drive_0084_sync
│ │ │ ├── 2011_09_26_drive_0009_sync
│ │ │ ├── calib_cam_to_cam.txt
│ │ │ ├── calib_imu_to_velo.txt
│ │ │ └── calib_velo_to_cam.txt
│ │ ├── __init__.py
│ │ ├── kitti_odom_loader.py
│ │ ├── kitti_raw_loader.py
│ │ ├── static_frames.txt
│ │ ├── test_files_eigen.txt
│ │ ├── test_files_stereo.txt
│ │ ├── test_scenes_eigen.txt
│ │ └── test_scenes_stereo.txt
│ └── prepare_train_data.py
~
- 上記のようなディレクトリ構造となったら、以下コマンドを叩き、前処理を実施します。
$ python data/prepare_train_data.py --dataset_dir=data/kitti/ --dataset_name='kitti_raw_eigen' --dump_root=dump_data/ --seq_length=3 --img_width=640 --img_height=192 --num_threads=4
progress 0/312....
学習
-
学習を行いたい場合は、以下のようにmonodepth2_kitti.ymlを設定し、自分のデータ数に合わせてパラメータを設定し直してください。
-
論文では学習用データ40000枚に対しバッチサイズ12で20epoch回しているため、論文と同様の実験をしたい場合は、config/monodepth2_kitti.ymlでそのように設定してください。
-
dump_data/train.txtを開き、学習データの数がバッチサイズの12で除算できる数に調整します。例として20枚の学習データがtrain.txtにある場合、13行までを学習データとして残し、残りの行は削除します。(13行目としているのは、最後の学習データが使用されない構造となっているため、結果として13-1枚が使用されることとなります)
-
以下コマンドを叩いて学習を開始します。
python monodepth2.py train config/monodepth2_kitti.yml created_model
テスト
- 学習により生成されたモデル、又は学習済みモデルがtf-monodepth2-maseterの直下に存在していることが確認できたら、テスト用のconfigファイルを作成します。
- 以下のようにして、monodepth_kitti.ymlをコピーしてテスト用に作成してください。
dataset:
root_dir: 'dump_data'
image_height: 192
image_width: 640
min_depth: 0.1
max_depth: 100.
preprocess: True
model:
root_dir: ''
learning_rate: 1e-4
batch_size: 12
num_source: 3
num_scales: 4
epoch: 1
beta1: 0.9
reproj_alpha: 0.85
smooth_alpha: 1e-3
batch_norm_decay: 0.95
batch_norm_epsilon: 1e-5
pose_scale: 1e-2
auto_mask: True
continue_ckpt: ''
torch_res18_ckpt: ''
summary_freq: 1
pose_type: 'seperate' # seperate or shared
- 最後に以下コマンドを叩き、テストを行います。
python monodepth2.py test config/monodepth2_kitti.yml 作成したmodel名 or 学習済みmodel名
結果
- 車や木など距離が近いほど明るく描画され、人に対してもそれらしい形が描画されています。

最後に
推論を実施して深度推定できたといえ、精度はまだ低いので、finetuningするなどして精度を高める試みをしてみると面白いかもしれません。
参考文献
-
SfMLearner: Unsupervised Learning of Depth and Ego-Motion from Video
-
Monodepth2: Digging Into Self-Supervised Monocular Depth Estimation
Discussion
前処理の際、python data/prepare_train_data.py --dataset_dir=data/kitti/ --dataset_name='kitti_raw_eigen' --dump_root=dump_data/ --seq_length=3 --img_width=640 --img_height=192 --num_threads=4 を実行すると、
usage: prepare_train_data.py [-h] --dataset_dir DATASET_DIR --dataset_name
{kitti_raw_eigen,kitti_raw_stereo,kitti_odom,cityscapes} --dump_root DUMP_ROOT
--seq_length SEQ_LENGTH [--img_height IMG_HEIGHT] [--img_width IMG_WIDTH]
[--num_threads NUM_THREADS]
prepare_train_data.py: error: argument --dataset_name: invalid choice: "'kitti_raw_eigen'" (choose from 'kitti_raw_eigen', 'kitti_raw_stereo', 'kitti_odom', 'cityscapes') というエラーが出るのですが、解決法をご存じでしょうか?
恐らくですが、シングルクオテーションを含んだままダブルクオテーションでkitti_raw_eigenを指定していることが原因かと思います。
ですので、'kitti_raw_eigen'というクオテーション込みの文字列を指定してしまっているものかと。
以下のようにシングルまたはダブルクオテーションのみでkitti_raw_eigenを指定して実施ください。