【読書】SREの探求
第1部 SREの導入
1章 SREにおけるコンテキストとコントロール
SREが開発チームに可用性に対するコンテキストを共有することが大事とする考え方。
コントロールはデプロイ権を取り上げるなどの開発チームに対してのコントロール。
コンテキスト駆動型のモデルをサポートして可用性を改善するためには、そうしたデータに影響する、ドメイン固有の知識を知らなければなりません。
そのためには情報を収集して、可用性に関するストーリーを物語る形式へと昇華させる必要があります。
このような変換を適用することで、このコンテキストを必要に応じてチームにプッシュでき、その結果チームは、所定のマイクロサービスで可用性が改善されているか どうかを計測できるようになります。
つまり、開発チームに対してメトリクスという只の情報を与えるのではなく、理解しやすい変換を行わなければいけない。
重要なのは「人々 が漫然と運用業務を行っているわけではなく、適切な意思決定を行うためのコンテキストが欠如しているだけだ」という原則を出発点とすることです。
ただし、自律的な改善が見られない場合(可用性が悪化しているなど)はコントロール駆動に切り替える必要性がある。
可用性に対して、ある程度の許容量がある場合にはコンテキスト型が良さそうな感じがある。
2章 サイトリライアビリティエンジニアの面接
SREを採用する時になったら読み返そう
3章 なるほど、SREチームを作りたいのですね
結局は開発チーム・経営陣など上の立場からどれだけの理解を得られるかどうかの話なんだよな。
それなくしてはSREは成り立たない。
皆さんが SRE チームを編成したと想像してみます。それが良好に機能しているかどうかは、 どのようにすれば判断できるでしょうか。より少ない人員で信頼性を高められるでしょう か。リリース速度を向上できるでしょうか。何が計測可能でしょうか。
これは自分の場合、「複数人のSREチームになったらどうなるか?」を想像してみないといけない。
4章 インシデントのメトリクスを用いたSREの大規模な改善
メトリクスの選出判断に用いる 好循環
TTD(インシデントを把握するまでの時間) +
TTE(エンジニアが関与するまでの時間) +
TTF(問題の軽減にかかる時間)
= TTM(軽減時間)
ポストモーテムでの対応案を短期アイテムと長期アイテムでそれぞれ分けて考えるのは良いかも。取り入れたい。
5章 サードパーティとの協力を円滑に進める重要性
責任ある SRE としては、個人的な関心よりビジネス目標に優先順位を置くこと で成功へと導けます。おもしろいからと取り組むことが必ずしもビジネスにとって最善ではないと いうのが、残念ながら現実なのです。
合成モニタリングとRUM(リアルユーザーモニタリング)って何?
合成モニタリング:ユーザー体験測定の一つで、テスト環境で様々なページの性能測定を行う
RUM:合成モニタリングと違い、実際のユーザーのリクエストレスポンスなどを元に性能を測定する
サードパーティは補助的な存在ではなく、自社の技術スタックの拡張です。
6章 専任SREチームなしでSREの原則を適用する方法
SoundCloudのお話。
オンコールのローテーションに関するベストプラクティスに従えば、8名がチームの最小規模となります。SoundCloud と同じくらいの規模の組織だと(つまりエンジニアがざっと 100 名)、こうした最小規模の SRE チームが 1 つだけでも、すでにエンジニア総数の 5~10% を占めることになるでしょう。
エンジニアの約10%をSREにするという前提に従えば、各チームに割り当てられるSRE は多くて 1 名となりました。
「専任の SRE チームを 1 つは維持しうるだけの規模があるとはいえ、機能が多様なために我が社は実質的に、もっと小さな組織と同じ状況に置かれている。だから、Google の SRE をそのままコピーしてもだめで、自分たちの環境に合わせてアプローチを調整しなければならない」
結局のところSRE チームとは、運用の懸念をソフトウェアエンジニアの発想とツールボックスで解決するという前提があるとはいえ、あるレベルでは運用チームなのです。SREの原則を私たちのシ ナリオにうまく適用するためには、SREの発想を全員に吹き込むことが必要でした。
最終的にDevOpsも出来る開発チームが出来上がった。但し、これはSREの原則違反ではある。
このメリットとしてある程度成熟した開発チームに対してオンコールもお願いすることで、オンコール疲れを回避することができる。
従来型の運用チームや Google スタイルの SRE チームとの大きな違いは、SoundCloud の ProdEng チームには、機能のリリースを止める公式の権限がなく、ましてエラーバジェットなどの高度な セーフガードも提供しないことです
さながら技術のカンブリア爆発となったことで、ツー ル管理やフレームワークを巡る取り組みが持続不可能なほどに断片化してしまいました。
SoundCloudではRuby一辺倒から多くの言語を採用すると舵を切ったがために上記のような状況になってしまった。
ただし、そのメリットが新たな道を切り開くコスト を上回るのであれば、導入することは可能です。
一旦はJAVA, Scalaなどに寄せることにしたがその後多大なメリットがあると判断し、Goに切り替えたというお話。
結局、言語統一した方が楽だけどそこにずっと居座るのも良くないよねって感じかな。
7章 SREのいないSRE:Spotifyのケーススタディ
Spotify が実際には SRE 部門を持っていないことに多くの人は驚きます。中央の SRE チームが なく、SRE のみのチームすらありませんが、それでも時間の経過とともにスケールしていく能力 にとって拠り所となってきたのは、業務遂行のあらゆる取り組みに SRE の原則を適用する能力 です。
Enbedded SREのような形っぽい。
運用エンジニアが最初からチームの一員であったことで、その自然な延長として、運用の健全性
をぎりぎりまで放っておくのではなく、議論の中で他のテーマと同等に扱うという社風が確立され
ました。
初期にSREを携えるのは成長するにつれてメリットがあって良いというお話。
デフォルトの運用:
スケーラビリティや信頼性に関する開発者との定例の議論で最初から運用を取り上げること は、Spotify におけるエンジニアリングのアプローチの基盤を築く上で重要でした。サービ スの開発や保守であれ、インフラストラクチャの改善を支援する自発的な取り組みであれ、 あらゆる開発者の業務を支える基盤が運用だったのです。
デフォルトの運用って名前だとわかりにくいが「運用を常に開発の中でデフォルトに考える」っていう解釈の方がしっくりくる。
こうした成長に伴う双子の難問(ユーザーと社員両方の急増)は、運用チームにとって大きな打 撃となりました。3 名から 5 名へと増員されたにもかかわらず、運用チームが直面する状況はまさ にパーフェクトストーム(複数の対応困難な事態が同時発生することによる壊滅的な状況)でし た。
ユーザー増に伴うインシデントの増加、社員増加に伴う問い合わせの増加がリソースを圧迫しだした。
機能の開発者には、スプリント期間中に 1 日の「システム所有者デー」も割り当てられ、この日 は各自のサービスのメンテナンス、アップグレード、一般的な改善強化に専念する時間が与えられ るようになりました。各サービスの開発所有者は、必要に応じて運用エンジニアの助言を求めても よいことになっていました。これは運用にかかるプレッシャーを少し緩和しました。
そういった中での対応策。
ゴールキーパーは運用エンジニアが 1 週間ごとに交替で務め、勤務時間内に運用チー ムに入ってくるリクエストすべてに関する「指定された避雷針」として機能しました。
これには負荷の軽減とサイロ化の防止という2つのメリットがある。
システム異常の渦中 および事後に腕まくりをしてフォレンジック†4 の作業を行うときです。
†4 監訳注:原文の forensics は「法医学」や「鑑定科学」というような意味合いがもともとあり、転じてシステム異常の原因調査の意味で使われています。
運用所有者という従来のアプローチは、Spotify が小さな組織だった頃には良好に機能しました が、技術と組織の両面で複雑さとスケーラビリティの問題がありました。もはや 1 人または 2 人 1 組 のシステム所有者に頼って、すべての問題を解決することは不可能でした。
結局サービス毎に特定の人に運用を自律的に任せることは完全には無理で、問題が多発するようになった。
そこで分隊型運用として、バックエンドエンジニアにも責任を引き渡すことになった。
そのため、SREチームは円滑化のためのツールの整備やドキュメンテーションなどの投資を続けることになる。
多くのインシデントに見舞わ れているチームは多くの場合、ポストモーテムを省略していました。その理由は、タイムラインを 確立し、根本原因を特定し、改善策を定義するという作業を週に 10~20 件ものインシデントにつ いて行うのは負担が重すぎるように思われたからです。
ポストモーテムを省いて、そもそもの根本解決を優先するというやり方もありっちゃありか。
TeamCity は、Spotify で使用される唯一の継続的インテグレーション(CI)システムでした。 これがバックエンドサービス開発者にとっては扱いにくくなりすぎたため、独自の Jenkins インス タンスを運用する分隊が現れ始めました。これこそチームの自律性と実験精神の発露とばかりに、 Jenkins の使用は急速に他の分隊にも広がり、まもなくバックエンドサービス向け CI ツールの事実 上の標準となりました。
ただ、脆弱性アップデートの放置などメンテナンスが守られない状況が起こった。
これについては実験精神が悪い方向に働いた例。結局、SREチームが間に入ることになったが、こういうバランス感覚を保つのは難しそう。
最終幕を考えると、技術環境は変化していくことから、サイトリライアビリティに関するニーズ も変化します。私たちが可能性を検討している領域の 1 つは機械学習です。
SRE × 機械学習、何か実例がないか調べたい。
8章 大企業におけるSREの導入
ビジネスケースの要素と してはまず最初に、SRE というリソースがいなければ、従来のエンジニアリングリソースはビジネ スで優先されるプロダクトの強化や改善に集中できないという事実を強調すべきでしょう。
ビジネスケースと併せたSREのアピールポイントについてのお話。
SREがいなかったら開発チームのリソースがインシデントに食い潰されて、本来取り組みたいタスクが疎かになる。
→ コンテキストスイッチは想像以上にお高い
→ 開発チームなどからこういったストーリーを収集して、改善ストーリーまで作り込めたら👌
こうした対話の中で誰もが同意したのは、エンジニアリングのリソースがプロダクトの破綻を 防ぐために、いま定義したような SRE に相当する役割を担っていることでした。
暗黙的にSREを誰かが担っている。こういう取り組みを続けるとコンテキストスイッチによる集中力減退などにも繋がるため、集中的に取り組めるSREチームを設立した方がいい。
SRE チームは組織内で独自性の強い存在となることから、その存在価値を示すためには、一貫したメトリクスを定義、計測、更新してステークホルダーに報告することが重要です。
SRE 導入の成功度を計測するための優れた出発点となるのは、Google の「4大シグナル」です。すなわち、トラフィック(1 分あたりのリクエスト数)、エラー(1 日あたり/プロダクトあたりのインシデント /エラー数)、サチュレーション(アクティブな Web ワーカー数)、レイテンシ(タイムアウト回数 またはページロード時間)です。
そういえば報告義務を怠っていたかもなぁ。もう少し密にやるようにしないと。
SREの走り出しからチーム結成まではこんな流れ
- 現在の状況の理解
・話がわかる上長や幹部を把握する
・現況に合わせたSREの導入のコストとメリットを集める
・組織上の類似部門の統一化などの組織的コスト削減
・問題点を含めたインフラのフットプリントの理解 - ステークホルダーとの対話
・組織に合わせたSREの定義を詰めるために1on1
・SREの定義作成 - ビジネスケースに併せたSREが取り組むべき課題の作成・提示
- SREチームの編成
その先のロードマップも提示してあったので貼り付け。





9章 25ページでシステム管理者からSREへ
たとえレイテンシの増加が無視できる程度であっ ても顧客が不便を感じる原因となるようなら、SRE は重大な問題として対処することになります。
要はユーザー体験を損ねる問題はSREの担当領域ということ。
検討したメトリクスが選択対象となる適切な候補であるか、それとも明確に却下すべきものかを
判断するにあたって積極的に答えを出す必要があるのは、比較的単純な 2 つの疑問だけです。
● このメトリクスはユーザーが把握できるか。
● このメトリクスはユーザーにとって(およびサービスの顧客としての観点から)、所定のレ ベルに維持するか特定の範囲内に収める必要があるほどの重要なものか。
つまりユーザーが軸になるメトリクスかどうか。
最終顧客が直接利用するわけではないサービスの場合にも、やはり独自の SLA を定めるべきで しょうか。答えは「イエス」ですが、
内部向けに関しては要らないかと思ったけどいるのか。後続の文章を読むと、内部コンポーネントもサービス全体の一部と捉えた時にたとえ直接ユーザーが触るところでなくても問題が波及する可能性がある。
例えばメール送信に関する内部コンポーネントが挙げられているが、多大な遅延が発生した場合に最終的にユーザーへの影響となる。
この章のSLA・エラーバジェットの計算系の話は役に立ちそう。
10章 大企業でSRE導入の道を開く方法
トイルは、将来のトイルを防止するエンジニアリング作業に必要となる時間も食い潰します。うかうかしていると、組織におけるトイルのレベルは、その増加防止に必要なキャパシティを確保できなくなる状態も超えて高まる可能性があります。技術的負債という比喩に乗っかるなら、これは図 10 - 1 が示すように、「エンジニアリング破産」と表現できるでしょう。
こうした相互関連性があるため、大企業ではトイルを取り除くことがとても難しい課題となりま す。チームの中だけで発生したトイルであれば、分かりやすいエンジニアリング作業で取り除けます。しかし、組織の別の部分に存在する条件やシステムと密接に結び付いているトイルの全体につ いてはどうでしょうか。
様々な要因による関連性が結びついているため、トイルの取り除きのコストが高い。
大企業では孤立して存在するものは何もないことを思い出してください。何か意味のあることをやろうとすれば一般に、情報と作業は組織の 1 つ以上の境界を超えなければならないこと になります。
大企業ではサイロ化が顕著で、断絶から来る問題が山積する。
大企業におけるSREの出発点としてトヨタ生産方式の紹介がされていたので本買った。
ここでサイロが敵であることを思い出してください。この種の分析を個人的に行うか「専門 家」のチームに限定するのでは、組織にもたらす価値は最小限でしかありません。大企業の悪 いところは情報を区分化して囲い込むことです。
分析作業はオープンに行い、できるだけ多くの人々の参加を奨励します。貢献してもらえる知 識のある参加者がいないか、上流側と下流側にも目を向けます。開発者、プログラムマネー ジャー、その他の運用チームにも声をかけます。何を変える必要があるのかについて可能な限り多くの人々が同様の理解を持つことになれば、SRE への変革は成功の見込みが大きくなり ます。
サイロを打ち壊すためのオープン化
SRE(および他の機能別の役割)をプロダクト 専用チームに参加させるものです。この方法では、サービスを開始から廃止まで所有できる機能横 断型チームが作られます。開発と継続的な運用はすべて、この機能横断型チーム内で実行されま す。大企業の観点からすると、これは概して、従来の組織モデルからの完全な離脱とみなされます。 聞いたことがある人もいるでしょうが、このパターンは Netflix モデルと呼ばれる場合があります。
Embedded SREの言及。Core SREについてはGoogleモデルと説明されている。
DevOps は、SRE の中核的な方針のいくつかを、幅広い組織、管理の構造、個人に対して一般 化したものと捉えることもできるでしょう。同様に、SRE を DevOps に独特の拡張を少し加え たプラクティスと捉えることもできるでしょう
SRE は、DevOps で始まった機運を有効に活用し、ライフサイクルで残ったデプロイ後 の部分にまで変革の取り組みを継続していく機会となります。
11章 DevOpsの幅広い実践現場で活用されているSREのパターン
「私が定義する SRE と は、ソフトウェアエンジニアが運用グループを作るときにできあがるものです」
HRR でプロダクションの承認が最も早いチームは、早期の設計段階からローンチに至るまで、 SRE と最も早くから協力していたチームです。それに素晴らしいのは、SRE にボランティア でプロジェクトを支援してもらうのが常に簡単なことです。SRE は誰もが、プロジェクトチー ムに早い段階で助言することに価値があると考えているので、そのために数時間でも数日でも 自発的に協力してくれるでしょう。
これを読むとEmbedded SREが最強では?と思ってしまわなくもない。
ちなみにHRRは引き継ぎレディネスレビューのこと。ローンチレディネスレビュー(Launch Readiness Review = LRR)もある。
12章 DevOpsとSRE: コミュニティからの声
DevOpsとSREの違いについて様々な意見。
RE とは 単なる一連のプラクティスではなく、定義された SRE の役割があって一連の責任を伴うからです。 これも SRE と DevOps の根本的な違いで、「DevOps エンジニア」の役割が明確に定義されている わけではありません。
これが一番しっくりした。DevOpsはSREに内包されるもので、SREは開発 -> デリバリ以降も信頼性を主軸に責任を負うという認識。
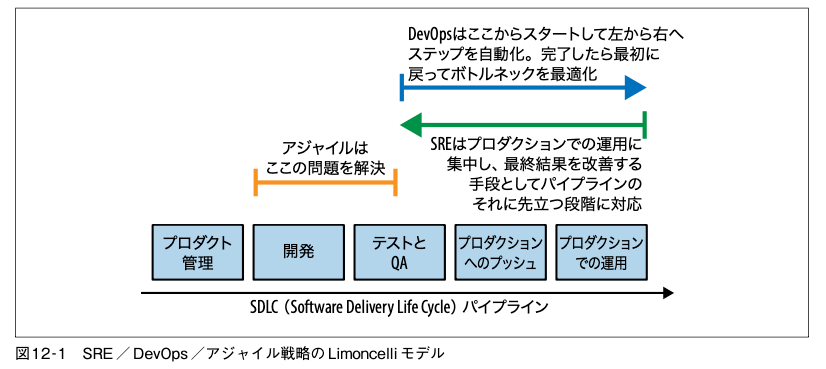
これも分かりみが深い。DevOpsとSREとではパイプラインに対するスタート地点がそもそも違うという感じ。
全体的に「DevOpsは手段・アプローチの名称で、SREは役職・役割名である」という区別の仕方が多いように思える。
DevOps が開発者の生産性(例:ビルドシステムなどのツール管理、トレーニング、テストの精度向上)に比重を置いて集中できるのに対して、SRE は稼働時間の維持、プロダクションシステムの整備、専門ツールの管理 (例:分散トレーシングのインフラストラクチャ)などに集中します。
DevOpsのCAMSモデルの概念がかなりSREに当てはまるところが多いらしい。
CAMSは「Culture, Automation, Measurement and Sharing(文化、自動化、計測、共有)」の頭文字から取られている。
13章 Facebookにおけるプロダクションエンジニアリング
プロダクションエンジニアリングとは、運用の問題はソフトウェ アソリューションを通じて解決すべきであり、ソフトウェアを実際に構築しているエンジニアこそ がそのソフトウェアをプロダクションで運用する最善の担当者であるという考え方から生まれたものです。
Facebook におけるプロダクションエンジニ アリング(Production Engineering = PE)チームとは、ソフトウェアエンジニアリング(SWE) と運用の統合という概念を単純に復活させようとしている試みと考えることができます。
専属の運用部隊(≠ エンジニア)を持つのではなく、エンジニアがソフトウェアエンジニアリングを用いつつ運用も回す。
私たちが直面した最大の課題は、SRE、AppOps、SWE の役割に対する期待が不明確だったこと です。そのため、火消し作業、サーバーの障害、キャパシティの新規増設といった業務のバランス を図ることができず、アーキテクチャの変更を要請するのだが SWE チームへの信頼性が低いとい う弊害をもたらしていました。
対応として、 Site Reliability Operations(SRO)チームを新設し、SREとAppOpsを統合。
SWEが期待している安定性・運用の問題をSWEが責任を持つことなど。
私たちのモデルは、いくつかの企業の独自の組織構造や、いくつかの SRE チームおよび運 用チームの派遣型の性格からアイデアを拝借していますが、これらはいずれもプロダクトグループ や事業単位の直属です。私たちは集中型の報告構造(centralized reporting structure)と分散型配属構造(decentralized seating structure)を取っています。
集中型の報告構造は自らの目標設定に従って自律的に作業する構造。研究職とかに近いのかな?
分散型配属構造はEmbedded SREぽい話。PEがSWEの近くにいて、プロダクトに関するアレコレを把握しておくことで、円滑な運用をこなせるようになる。
Andrew Ryan は、「サービスピラミッド」という概念を着想しました。
私たちはこのサービス階層構造を用いることで、プロダクションエンジニアがチームと最初に 関わり合うときに行う作業のタイプに優先順位を付けています。
雇用または養成するPEに期待するのは、 ネットワークプロトコルとそのデバッグ方法を理解することです。システムの下位レベルに関する知識があり、ソフトウェアがカーネル、ハードウェア、ネットワークレイヤーとやり取りする方 法を理解している必要があります。さらにキャリアを積みたければ、分散システムの構築方法を理 解することが必要です。これらは PE を雇用する際に求める一般的なスキルです。
このくらいのレベル感にはなってくるよなぁ・・・
ソフトウェアチームが PE、SRE、その他 を対等な貢献者と考えているのなら、アーキテクチャに関する議論は両方のグループが同室に集 まって行われるでしょう。逆に、運用チームが対等だとみなされておらず、事後報告を受けるだけ なら、PE モデルの導入はうまくいっていないことになります。
第Ⅱ部 SREの周辺領域
第14章 初めにカオスありき
カオスエンジニアリングの話
それでは、システムの望ましくない動作を防止または最小化するにはどうすればよいのでしょう か。論理的な選択肢は 2 つあります。複雑なシステムではなくなるように複雑さを減らすか、シス テムの動作原理を込み入った詳細まで理解していなくてもシステムの舵取りができる別の方法を見 つけるかです。後者を私たちは複雑さをナビゲートすると呼んでいます。
複雑さを減らすことにも限界があるので、複雑さをナビゲートしよう。
→ 複雑さって何?
→ 4つの複雑さの柱:https://gist.github.com/syossan27/12296a330d37cc3d6563e63abcc65e27
・状態(State)
システムが取りうる構成の数と性質
・関係(Relationship)
システムの部分(人間のオペレータを含む)が情報をやり取りする方法の数と性質
・環境(Environment)
システムにとっては外部の環境によって持ち込まれる不確実性
・不可逆性(Irreversibility)
システムに対する変更を容易に取り消しうる程度
状態以外はナビゲートできそう。
Chaos Monkey は、サービスのインスタンスを 1 日 に 1 つ擬似ランダムに選んで不意に停止させます。ただし、これを行うのは勤務時間内だけです。
インスタンス消失問題へ立ち向かうために生まれたカオスエンジニアリング。
Chaos Monkey の成功に基づいて、Netflix はさらに徹底することを決断しました。単にインスタンスを終了するのではなく、リージョン全体を停止するのです。これをChaos Kongと呼んでい ます。
カオスエンジニアリングの目的 は、どのように機能するかを明らかにすることではありません。目的はモデルの妥当性確認(validation)です。私たちが求めるのはモデルの実証(verification)です。複雑なシス テムは個人が全体像を完全に把握できるものではないことは、すでに分かっています。その ため、どのように機能するかを明らかにするのではなく、機能するかどうかに集中し続けた いと考えます。定常状態の挙動に集中することで、「機能するかどうか」にずっと注意を払 い続けられるようになり、カオスエンジニアリングから最大限の価値を引き出すのに役立ちます。
つまり、「定常状態」にあるかどうかをカオスエンジニアリングでチェックすることが目的であり、例えば対象となるシステムが「間違った応答」を普段から返していたとしてもそれは定常性を保っていると言え、問題はないと考えられる。
カオスエンジニアリングについての導入QAもあったので気になったら読み返すのも👌
15章 信頼性とプライバシーが交わるところ
プライバシーエンジニアリングについて。SREと関係あるのか?となるが、ユーザーがサービスへ向ける信頼性の中の一つにプライバシーの尊重も含まれるべきであるといったお話の流れ。
-> 個人情報流出の防止と読み直すと襟を正す必要が出てくる
プライバシーに関する作業は、3 つの主要なカテゴリに分類できる傾向があります
防護(Guard):プロダクトに関するプライバシー上の潜在的な問題を発見して解決します
強化(Strengthen):すべてのチームが「正しいことをする」プロダクトを容易に開発できるようにします
消火(Extinguish):プライバシーに関して「火事」が発生したときには、プライバシーエンジニアが消火活動を 行います
アクセス制御の話などはわかるものの全体的にふわっとしてて読み飛ばしちった🤔
16章 データベースリライアビリティエンジニアリング
DBREと略すみたい
従来のデータベース管理者(database administrator = DBA)が行っ ていたのは言わば、サイロやスノーフレーク†2 を作り出すことでした。
†2 翻訳注:スノーフレークとはこの場合、設定や構成が少しずつ異なる多くのデータベース環境を意味します。
コラボレーションの文化が定着しているチームの場合、厳密な職務分掌は重荷となるばかりか、イノベーションやスピード感を制約することにもなりかねません。
DBREがこなすべきタスクは「DBRE以外のエンジニアがDBに関する業務力を強化すること」であり、DBに関する番人をやることではない。
=> enablingさせていくことを考える
特殊なスノーフレークとコモディティであるサービスコンポーネントの違いを示すためによく使 われるのが、「ペット」対「家畜」という比喩です。
ペットとしてのサーバーは、管理者が餌を与 え、よく世話をし、病気になったら健康を取り戻すように看病します。名前も付けてもらえます。
家畜としてのサーバーに与えられるのは名前ではなく番号です。こうしたサーバーの場合、管理 者がカスタマイズに時間を費やすことはなく、個別のホストにログインすることもありません。
たまにエンジニア関連書籍でこの例えが出てくる。(k8sの文脈とかでも)
要は個別の"何か"として丹精込めて面倒を見るものか、特別視せずに扱うものかの違い。
データストアは”データ”を保持する特性上、"ペット"として扱わなければいけない。
信頼性を考えたときに以下の2つに着目する必要がある
- データの完全性と耐久性
- リカバリ
- CD
- システム的なCI/CDの話に合わせて"教育"も必要
- ベストプラクティスの制定など
- システム的なCI/CDの話に合わせて"教育"も必要
DBRE の仕事は、エンジニアが知識、コンテキスト、履歴情報を利用できるようにして、彼らが日常的に意思決定を行いながら、DBRE に監督されなくても機能の作業に取り組めるようにするこ とです。
17章 データ耐久性のエンジニアリング
耐久性 =データの損失や破損を避ける
=> 可用性を担う要素の一つ
Dropbox 草創期のことですが、壊滅的な障害の発生後にプロダクション用のデータベースを再起 動するだけで 8 時間かかると分かって愕然としたものです。
データはすべて無傷だったとはいえ、 MySQL の innodb_max_dirty_pages_pct パラメータに設定する値が大きすぎたため、クラッシュからのリカバリ時に redo ログをスキャンするだけで MySQL が 8 時間を要する結果となったのです。
幸い、このデータベースには重要なデータが保存されていなかったため、これを完全にバ イパスすることにより数時間で dropbox.com をオンラインに復帰させることができました。
DBのレプリケーションなどデータ周りの耐久性のお話。
耐久性エンジニアリングには4本の柱がある。
- 分離(冗長性の確保)
- DBサーバの物理的分離
- レプリケーションなどの論理的分離
- 運用上の分離、保護のセクションと被るが人間のミスを防ぐために個々のプロセスを分離し、自動化する
- 保護 (人間のミスを防ぐ)
- テスト
- 作業ミスを防ぐセーフガード
- リカバリ
- 検証(障害を検出)
- エラーが0だと確信するような検出
- 負荷なども含めて検証システム
- Disk Scrubber(ストレージの破損チェック)
- Index Scanner(ストレージのブロックチェック)
- Storage Watcher(特定のブロックを長期的にチェック)
- 監視機能の監視
- 自動化
- アラート疲れを防ぐための自動化
- 人間よりも"信頼性"に優れる
近づいてきていることに誰も気付かなかったブラックスワンイベントのような「知らないでいることを知らない」状況が次の予期せぬ大惨事となる恐れがあるときでも、先手を打って対応できるようにすること。
18章 SREのための機械学習入門

19章 ドキュメント作成業務の改善:エンジニアリングワークフローへのドキュメンテーションの統合
ドキュメンテーション品質の定義とは、基本的に単純なものです。
ドキュメントが優れているのは目的にかなっている場合です。
とはいえドキュメントの品質を測る指標として
- 構造品質(structural quality):表記と文法の正しさや、構成が整理されていて閲覧しやすいなど
-
機能品質(functional quality):ドキュメントの有効性のことで、「オンコールの義務を遂行するためにチームは手順書を頼りにできるか?」など
の2種類がある。
ド キュメンテーションでも無理に完全を追求すべきではありません。
完全さにはコストがかかりすぎ、それを追求することで別のドキュメンテーションや場合によってはサービス自体を改善しうる作業に回るべきコストが犠牲になります。
重要な点は、特に内部ドキュメンテーションについては、重要な情報が盛り込まれて明確に伝わることです。
ビジネスの目標を達成するためには機能品質を第一の目標にしなければならないと、私たちは確信しています。