Kindleの蔵書を取得する - TypeScript入門
概要
Pappeteerによるスクレイピングの練習のためにKindle Cloud Readerから蔵書の一覧を持ってくるコードを作成します。
Eメールアドレスとパスワードを入力してログインする基本的な操作方法を覚えます。
ゴール
購入済のkindleのタイトルと冊数を出力します。

必要なもの
- 作業時間:10分
- nodejs(npm)
- Puppeteerが動く環境
- Amazonアカウント
スクレイピングの実行
-
ソースを作成する
ちょっと長めですが全量書きます。ユーザー名とパスワードは準備したものを使用してください。scraping.tsimport puppeteer from "puppeteer"; const main = async () => { // トップページを表示する const browser = await puppeteer.launch() const page = await browser.newPage() await page.goto("https://read.amazon.co.jp") // ログインページに遷移する await page.waitForSelector("#top-sign-in-btn") await page.click("#top-sign-in-btn") // Eメールとパスワードを入力してログインする await page.waitForSelector("#signInSubmit") await page.type("input[name=email]", "email address") await page.type("input[name=password]", "password") await page.click("#signInSubmit") // APIを直にたたいて蔵書をjsonで取得する(ブラウザのセッションをそのまま使う) // 50件ずつしか取得できないようなので繰り返し取得する await page.waitForNavigation() let books:any = [] for (let paginationToken=0; paginationToken != undefined;) { await page.goto("https://read.amazon.co.jp/kindle-library/search?&sortType=acquisition_asc&paginationToken=" + paginationToken) const respons = JSON.parse((await page.$eval("pre", e => e.textContent)) ?? "{}") books = books.concat(respons.itemsList) paginationToken = respons.paginationToken } // タイトルと冊数を出力する books.map((book:any) => console.log(book.title)) console.log("蔵書数は" + books.length + "冊です。") await browser.close() } main() -
スクレイピングを実行する
npx ts-nodeコマンドでスクレイピングを実行します。蔵書のタイトルの一覧と冊数が表示されました。漫画ばっかりですね。。。npx ts-node scraping.ts
ソース解説
-
トップページに遷移する
基本的にChromeの操作と同じことをコーディングするイメージでです。
ブラウザを起動し、新しいページ(タブと思えばよい)を作成してhttps://read.amazon.co.jpを表示します。
このURLは/landingへのリダイレクト(302)を返してくるのですが、Chromeなのでリダイレクト先への遷移も自動的に行われます。手で触っているのと同じですね。// トップページを表示する const browser = await puppeteer.launch() const page = await browser.newPage() await page.goto("https://read.amazon.co.jp")上記のコードが動いた後のの画面はこうなっているはずです。

-
ログインボタンをクリックする
ログインボタンにはid属性top-sign-in-btnが付与されていることを別途確認しています。
page.waitForSelectorで指定の要素が見つかるまで待機し、page.clickで指定の要素をクリックします。// ログインページに遷移する await page.waitForSelector("#top-sign-in-btn") await page.click("#top-sign-in-btn")上記のコードが動いた後のの画面はこうなっているはずです。
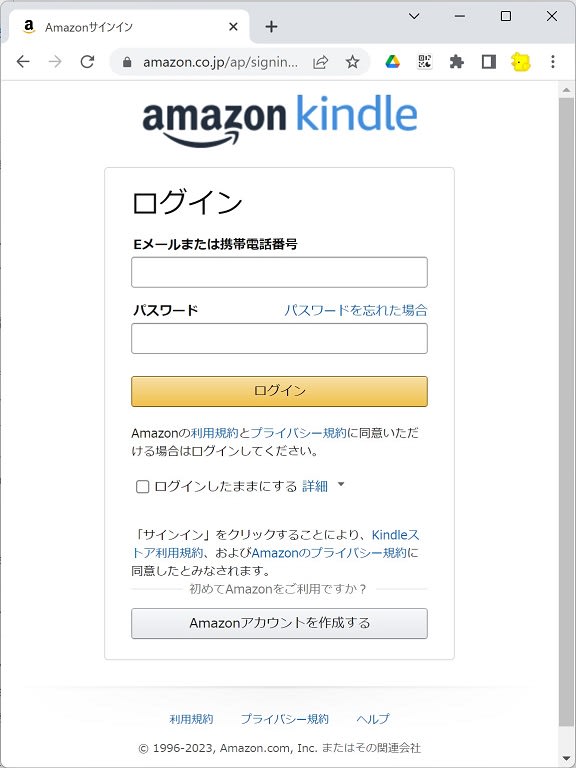
-
Eメールアドレスとパスワードを入力してログインボタンをクリックする
Eメールアドレス入力ボックスはinputタグでname属性がemailとなっており、パスワード入力ボックスはinputタグでname属性がpasswordとなっていることを別途確認しています。
page.pypで指定の要素に入力を行います。// Eメールとパスワードを入力してログインする await page.waitForSelector("#signInSubmit") await page.type("input[name=email]", "email address") await page.type("input[name=password]", "password") await page.click("#signInSubmit")上記のコードが動いた後のの画面はこうなっているはずです。

-
本の情報をjson形式で取得する
ログイン後のHTMLパースしていってもよいのですが、初期表示では36冊分の情報しか含まれていないようです。画面の動きを確認すると、ページ下部を表示した場合に追加で取得する動作となっていました。
このため、情報を取得するAPIを直接たたいてjsonを取得するアプローチで進めることにします。
このAPIは50件までしか情報を返さず、続きがある場合はpaginationToken要素が帰ってくるようなので、paginationTokenがなくなるまでAPIを呼び出し続ける実装としました。// APIを直にたたいて蔵書をjsonで取得する(ブラウザのセッションをそのまま使う) // 50件ずつしか取得できないようなので繰り返し取得する await page.waitForNavigation() let books:any = [] for (let paginationToken=0; paginationToken != undefined;) { await page.goto("https://read.amazon.co.jp/kindle-library/search?&sortType=acquisition_asc&paginationToken=" + paginationToken) const respons = JSON.parse((await page.$eval("pre", e => e.textContent)) ?? "{}") books = books.concat(respons.itemsList) paginationToken = respons.paginationToken }上記のコードが動いている間は以下のような画面が表示されています。

サンプルコード
この記事で使用するコードはgithub上に公開しています。
Discussion