階層クラスタリング結果をCSVに出力するPythonコード解説
📌はじめに
1000人以上のユーザーが、
- 自社商品
- A社商品
- B社商品
のどれを選んだのか——その傾向を決定木で分析することになりました。
しかし、人数が多すぎるため、そのままでは扱いづらい状況です。
そこでまずは、階層クラスタリングで似たユーザー同士をグループ分けすることにしました。
Pythonで階層的クラスタリングを実行すると、こんな「トーナメント表」みたいなデンドログラムが出力されます。
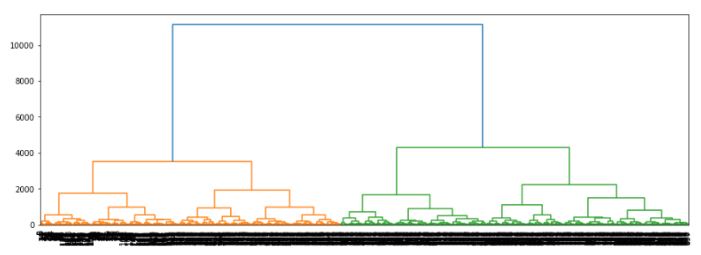
でも…
「誰がどのグループに入っているのか?」
——これ、まったくわからんのです。
そこで今回は、クラスタリング結果をわかりやすくCSVファイルに出力する方法を紹介します。
📌クラスタリング条件(仮定)
パターン①:距離(高さ)によるクラスタ分割
- クラスタリング位置指定:y軸1500でカット
- ファイル形式:X軸の並び順(デンドログラムの左から右への順)に沿って作成
パターン②:クラスタ数による分割
- クラスタ数指定:8クラスタ
- 出力ファイルは 顧客IDの昇順(ID番号が小さい順)で作成
📌分析用データ(仮定)

sample.csv
| カラム名 | 説明 |
|---|---|
| 顧客ID | ユニークID(顧客ごとの識別子) |
| 年間購入金額(万円) | 年間の購入金額 |
| 年齢 | 年齢(整数) |
| 性別 | 1 → 男性、2 → 女性 |
| 年収(万円) | 世帯年収 |
📌フォルダ構成
├── 1_flow/
│ └── clustering.py # クラスタリング処理スクリプト
├── 2_data/
│ └── sample.csv # 分析用データ
├── 3_output/ # 出力先(画像・CSV)
📌環境
python3.x
📌コード解説(clustering.py)
#============================================
# 0. ライブラリと変数設定
#============================================
import pandas as pd
import numpy as np
import os
import sys
import subprocess # 追加
from scipy.cluster.hierarchy import linkage, dendrogram, fcluster
import matplotlib.pyplot as plt
# 変数設定
INPUT_FOLDER = "2_data"
INPUT_FILE = 'sample.csv'
OUTPUT_FOLDER = "3_output"
SAVE_NAME ='clustering.png'
threshold_distance = 800 # クラスタを切る高さ(距離)の閾値(y軸閾値)
criter = 6 # クラスタ数の指定
ID = "顧客ID" # 処理データのIDを変数化
#======================================
# 1.パス設定
#======================================
current_dpath = os.getcwd()
parent_dpath = os.path.dirname(current_dpath)
input_path = os.path.join(parent_dpath, INPUT_FOLDER, INPUT_FILE)
output_path = os.path.join(parent_dpath, OUTPUT_FOLDER)
os.makedirs(output_path, exist_ok=True)
save_path = os.path.join(output_path, SAVE_NAME)
# CSV読み込み(エンコード判定)
try:
df = pd.read_csv(input_path, encoding="utf-8")
except UnicodeDecodeError:
df = pd.read_csv(input_path, encoding="cp932")
0. ライブラリと変数設定
-
pandas / numpy:データ処理用 -
os / sys / subprocess:ファイル操作や外部コマンド用 -
scipy.cluster.hierarchy:階層クラスタリング用関数(linkage,dendrogram,fcluster) -
matplotlib.pyplot:デンドログラムなどグラフ描画用
変数
-
INPUT_FOLDER / INPUT_FILE:入力データのフォルダ・ファイル名 -
OUTPUT_FOLDER / SAVE_NAME:出力先フォルダ・ファイル名 -
threshold_distance:クラスタを切る高さ(y軸閾値) -
criter:クラスタ数を指定する場合の値 -
ID:顧客ID列名を変数化
1. パス設定
-
os.getcwd()/os.path.dirname():現在の作業ディレクトリと親ディレクトリを取得 -
os.path.join(...):入力ファイルや出力フォルダのフルパスを作成 -
os.makedirs(..., exist_ok=True):出力フォルダがなければ自動作成
CSV読み込み
-
pd.read_csv()でデータを読み込む - 文字コードがUTF-8でエラーになる場合は CP932 で再読み込み
→ Windows環境でも安定して読み込み可能
#======================================
# 2. linkage計算
#======================================
Z = linkage(df.iloc[:, 1:4], method='ward')
#======================================
# 3. デンドログラム描画
#======================================
dendro = dendrogram(Z, labels=df[ID].values)
plt.axhline(y=threshold_distance, color='red', linestyle='--')
plt.rcParams["font.size"] = 10
plt.savefig(save_path)
plt.show()
#======================================
# 4. ①閾値で分割
#======================================
labels_distance = fcluster(Z, t=threshold_distance, criterion='distance')
df_distance = df.copy()
df_distance["cluster"] = labels_distance
ordered_df_distance = df_distance.iloc[dendro["leaves"]].reset_index(drop=True)
ordered_df_distance.to_csv(
os.path.join(output_path, f"clustering_distance_{threshold_distance}.csv"),
index=False, encoding='utf-8-sig'
)
#======================================
# 5. ②クラスタ数で分割
#======================================
labels_maxclust = fcluster(Z, t=criter, criterion='maxclust')
df_maxclust = df.copy()
df_maxclust['cluster'] = labels_maxclust
df_maxclust.to_csv(
os.path.join(output_path, f"clustering_maxclust_{criter}.csv"),
index=False, encoding='utf-8-sig'
)
# 保存フォルダを開く
os.startfile(output_dpath)
print('処理完了')
2. linkage計算
-
linkage(df.iloc[:, 1:4], method='ward'): 階層クラスタリングの距離行列を計算 -
method='ward': 年間購入金額、年齢、性別などのデータを使いWard法で階層的クラスタリングを行う
❓Ward法とは❓
Ward法は階層的クラスタリングでよく使われる手法で、クラスタ内のばらつき(分散)が最小になるようにデータをまとめる方法です。
ポイント
- クラスタ間の距離は各クラスタ内の平方和(Sum of Squared Errors)で測定する
-
統合のルール
- 2つのクラスタを結合したときの平方和の増加量が最小になる組み合わせを優先して統合する
- これにより、クラスタ内のデータはなるべく似た値のものが集まる
イメージ
- 年齢と年間購入金額でクラスタリングする場合、
- 20歳前後で購入金額が似ている人同士が自然にまとまる
- 40歳で購入金額が高い人たちは別のクラスタになる
メリット
- クラスタ内のばらつきを小さく保てるため、グループ内の特徴が均質になりやすい
- デンドログラムで見ると、階層的に「似たデータのグループ」がきれいにまとまる
3. デンドログラム描画
-
dendrogram(Z, labels=df[ID].values):クラスタのツリー構造を描画する -
plt.axhline(y=threshold_distance, color='red', linestyle='--'):クラスタ切断用の閾値線を表示 -
plt.rcParams["font.size"] = 10:フォントサイズを設定する -
plt.savefig(save_path)/plt.show():画像として保存し、表示
この時点で、クラスタリングの全体構造を視覚的に確認できます。
dendrogram(Z, labels=df[ID].values):クラスタのツリー構造を描画。
fcluster(Z, t=threshold_distance, criterion='distance'):
指定した距離の閾値でクラスタを切り分けます。
plt.axhline():指定した位置に赤い破線を表示。
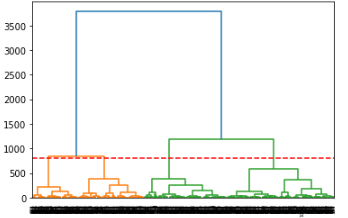
❓デンドログラム描画とは❓
階層クラスタリングの結果を木の枝のように描いた図です。
下から上に向かって、データ同士がまとまり、より大きなグループに結合されていく様子を表します。
ポイント
-
Y軸は「クラスタが結合されるときの距離」
(Ward法の場合は「クラスタ内平方和の増加量」) - **赤い破線(threshold_distance)**は「ここで切るとグループ分けできるよ」という目安
- criter を指定する場合は「欲しいクラスタ数」を直接決められる(例: 6グループ)
イメージ
- 下の葉(leaf)が個々のデータ(顧客など)
- 上に行くほど枝がまとまり、クラスタが大きくなっていく
- 赤い線を引いた位置で「パチン」と切ると、その高さでクラスタが分かれる
4. パターン①:閾値で分割
-
fcluster(Z, t=threshold_distance, criterion='distance'):指定距離でクラスタを切る -df_distance["cluster"] = ...:元のデータフレームにクラスタ番号を追加 -
df_distance.iloc[dendro["leaves"]]:デンドログラムの左から右の順に並び替え - CSVとして保存(
clustering_distance_{threshold_distance}.csv)
df_distance.iloc[dendro["leaves"]].reset_index(drop=True):
元データにクラスタラベルを付け、デンドログラムの表示順に並べ替えて保存

5. パターン②:クラスタ数で分割
-
fcluster(Z, t=criter, criterion='maxclust'):クラスタ数を指定して分割 -
df_distance["cluster"] = ...:元のデータフレームにクラスタ番号を追加 - CSVとして保存(
clustering_maxclust_{criter}.csv)

📌まとめ
階層的クラスタリングを使うことで、ユーザーをいくつかのグループに分けることができました。
この結果を活用して、次のステップとして 決定木などの手法で「どんな特徴を持つグループなのか」 を詳しく分析するとさらに理解が深まります。
こうした流れで分析を進めると、以下のメリットがあります
- データの全体像を把握しやすくなる
- 施策のターゲティングに役立つ
👉 次回は「決定木による分析」について紹介する予定です。
参考リンクについて
GitHubリポジトリ
本記事で紹介したコードやサンプルデータはこちらで公開しています。
Discussion