本記事について(Abstract)
こんにちは。私はプリンストン大学で、宇宙論の研究をしています、山本と申します。私は現在研究の傍ら東京大学鈴村研究室で、データサイエンティストとして、AI(人工知能)を用いた気象予測・気候変動予測のリサーチをお手伝いしています。
前回の記事では、気象予測と気候変動予測についての基本についてお話ししましたが、本記事では少し踏み込んで、一つのAIを用いた気象基盤モデル(i.e., ClimaX)について紹介していきたいと思います。こちらで紹介する事項は、ClimaXの論文から取られたものです。
次の回では、実際にClimaXの使い方について紹介して行きたいと思います。
ClimaXについて(Introduction)
ClimaXが他の機械学習を用いた気象モデルと違う点は、ClimaXが基盤モデル(foundation model)で"task specific"なモデルでは無いという点です。基盤モデルの良い点は、大量のデータセットからモデルを"pretrain"し、行いたいタスクに合わせてpretrainされたモデルを"finetune"するという転移学習(transfer learning)を利用することで、モデルの汎用性が高く、それぞれのタスクに対する学習時間を少なくすることができるという点です。
ClimaXがこの論文の中で行なったタスクは、
- 地球全体の気象予測(短期〜中期 -- 6 hours to 12 days)
- 特定の地域での気象予測(短期〜中期 -- 6 hours to 12 days)
- 中長期の地球全体の気象予測(2 weeks to 2 months)
- 地球全体の気候変動予測
- データの格子粒度をpretrainedされたモデルより上げた気象予測
です。以下で紹介するCMIP6のデータセットを使用して、モデルをpretrainし、それぞれのタスクに合わせた別のデータセットを使ってfinetuneし、予測を立てています。
データについて(Data)
Pretrain用のデータ
ClimaXはpretrain用のデータとして、The Coupled Model Intercomparison Project 6 (CMIP6)を使用しています。CMIP6とは、全世界の気象モデルのグループがそれぞれの気象モデルを走らせて作られたシミュレーションデータを集めたものです。ClimaXではここからいくつかシミュレーションを選別して、pretrain用のデータセットとして使用しています。以下に、データセットの名前、変数、データの粒度、時間の範囲についてまとめました。
- データセット(dataset): MPI, Tai, AWI, HAMMOZ, CMCC
- 格子粒度(resolution): 100km, 250km
- 変数(variables): 気温(temperature), 風速(wind speed), ジオポテンシャル(geopotential), 湿度(humidity)
- 時間の範囲(temporal coverage): 1850-2015(6時間の時間粒度)
CMIP6についての情報はこちらで確認でき、データもここからダウンロードできます。
Finetune用のデータ
Finetune用のデータセットは、行いたいタスクによって変わりますので、以下に気象予測のタスク(上記リストの1,2,3,5)、気候変動予測(上記リストの4)のタスクに分けて2つのデータセットを紹介します。
気象予測のタスク用
ClimaXは気象予測タスクにおけるfinetune用のデータとして、欧州中期予報センター(ECMWF)により再解析されたERA5というデータを使用しています。ERA5は1979〜2018年の全地球の気象データを再解析し、データ統合・同化のプロセスを踏み、全地球の気象データを1時間おきに、31km
ERA5に関する詳しい情報は以下参照。
様々な変数がありますが、以下はその中からいくつかの変数を可視化したものになります。
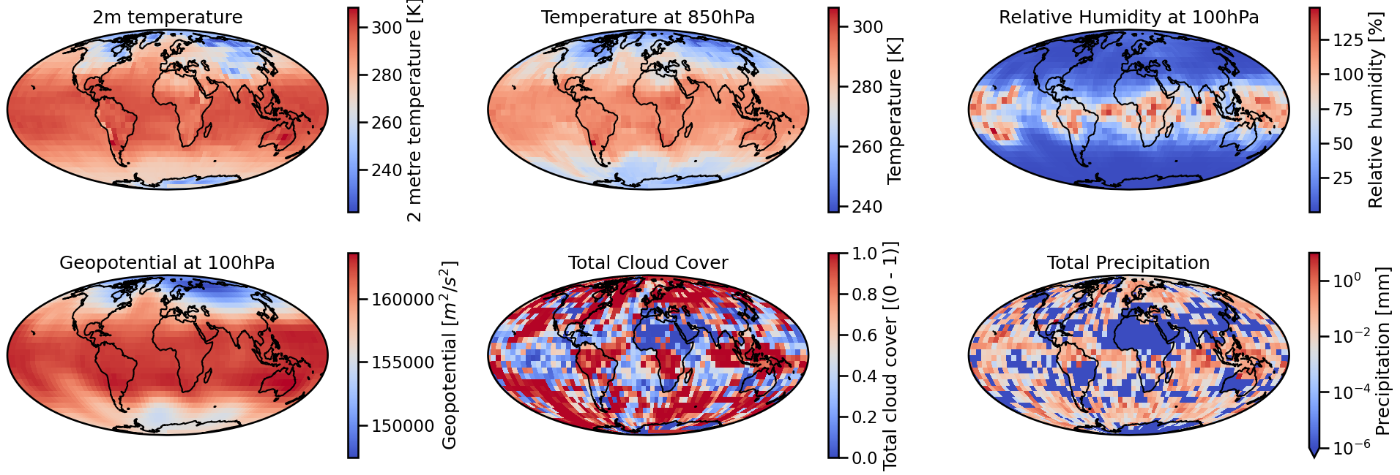
参照資料:
気候変動予測のタスク用
気候変動予測のタスクでは、ClimateBenchと呼ばれるデータセットがfinetune用のデータとして使用されています。ClimateBenchは、CMIP6、ScenarioMIP、DAMIPと呼ばれるデータセットの中から、できるだけ様々な社会経済シナリオ(socio-economic scenario)で複雑な地球システムモデルをシミュレートしたものを集めたものです。社会経済シナリオは、二酸化炭素などの温室効果ガスの量がどのように変化するかを描いたものですので、地球システムモデルの生物的・化学的・物理的な観点から温室効果ガスの変化量に対して、どれくらい気温が上がるかや降水量が増えるかなどが解ります。ClimateBenchのデータセットにおける時間の範囲は様々で、2015〜2100年をシミュレートしているものから、500年間のシミュレーションをしたものまであります。
例として、歴史的な二酸化炭素、二酸化硫黄、ブラックカーボン、メタンの量の推移を1850年〜2014年まで集めたものと、2015年〜2100年まで、あるシナリオに基づき予測したデータセットの中から、二酸化硫黄の量の推移を可視化しました。

以下の図は、上の可視化で用いたデータセットの2100年の化学物質の量に対して、平均気温、1日の気温の幅、降水量、極値降水量を予測したものになります。
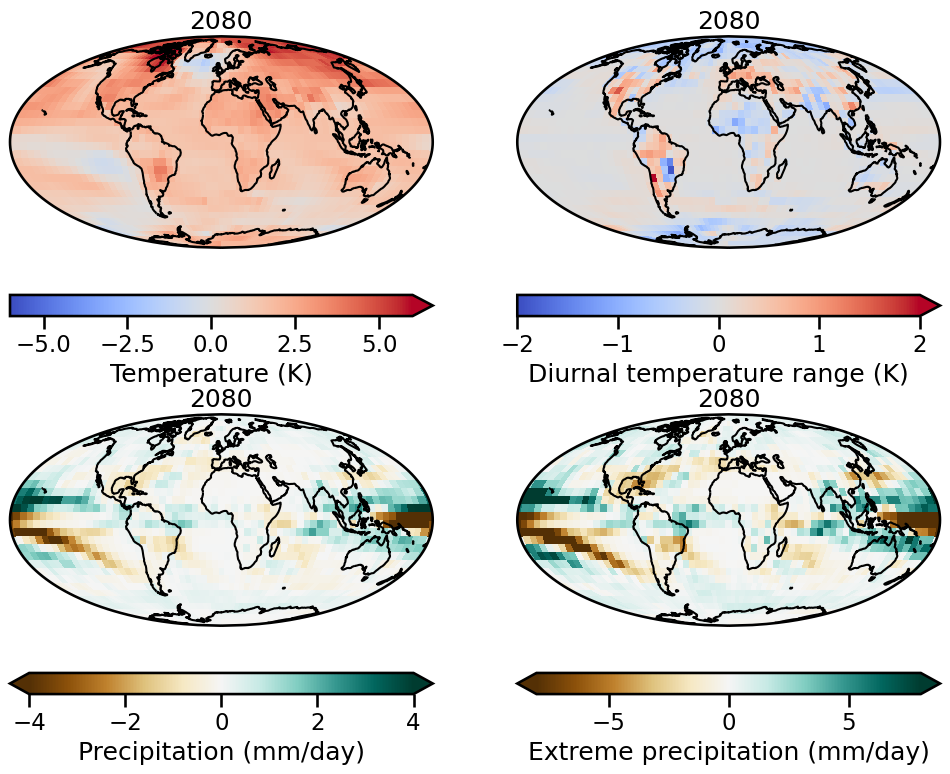
ClimateBenchに関する詳しい情報は以下の論文参照。
参照資料:
アーキテクチャについて(NN Architecture)
ClimaXモデルにおけるニューラルネットワークのアーキテクチャは、柔軟性と拡張性の観点から、ビジョントランスフォーマー(Vision Transformers; ViT)をベースにしており、画像データをインプットとしています。さらに、それぞれのインプット変数をトークン化(variable tokenization)することで、インプット変数の数がデータセットにより違うことに対応し、集合化(variable aggregation)することで、トークン化によるトレーニング時間や必要メモリの増加などを抑えることができます。
トレーニングにかかった時間
| トレーニングステージ | 格子粒度 | 時間 | 使用マシーン |
|---|---|---|---|
| Pretraining | 1.40625 deg, 5.625 deg | 5~7 days, 2~3 days | 80 NVIDIA V100s |
| Finetuning for global weather forecast | 1.40625 deg, 5.625 deg | ~1 day, 15 hrs | 8 V100s |
今回の記事では、ClimaXと呼ばれる気象基盤モデルについて、論文に記載されていることを中心に紹介しましたが、次回では、実用的なClimaXの使い方について紹介して行きたいと思います。
Discussion