この記事について
こんにちは。私はプリンストン大学で、宇宙論の研究をしています、山本と申します。私は現在研究の傍ら東京大学鈴村研究室で、データサイエンティストとして、AI(人工知能)を用いた気象予測・気候変動予測のリサーチをお手伝いしています。
前回の記事では、気象予測と気候変動予測についての基本についてと、ClimaXのモデルについてお話ししましたが、本記事ではもっと踏み込んで、実際にClimaXを使用した、気象予測・気候変動予測の仕方について紹介していきたいと思います。
前提
以下紹介するClimaXの動かし方に関して、私が使用したマシンはNVIDIA RTX3090もしくは、H100になります。使用マシンによっては、Pythonパッケージのバージョンなど変わることが想定されます。パッケージのインストール方法やpretraining/finetuningの方法などはこちらを参考にしています。
環境設定
まず、ClimaX(Github)を走らせるための環境をanacondaで作っていきます。
# Downlaod Miniconda
wget https://github.com/conda-forge/miniforge/releases/download/24.11.2-1/Miniforge3-24.11.2-1-Linux-x86_64.sh
bash Miniforge3-24.11.2-1-Linux-x86_64.sh
そしたら、ClimaXのGithubをクローンし、リポジトリの中にある、環境設定用のファイルを使って、他のパッケージをインストールし、環境を作っていきます。
# Clone ClimaX repo
git clone https://github.com/microsoft/ClimaX
cd ClimaX
# Create climax environment
conda env create --file docker/environment.yml [-n env | -p (your directory)]
conda activate env
pip install -e .
pip install snakemake
pip install pulp==2.7.0 # (need this version of pulp)
環境設定が終わりましたら、conda activate envで環境を組み立てます。
*上記環境だと、RTX3090では動くのですが、H100ではPyTorchが古くて動かないので、PyTorchをv2.0.0に、CUDAをv11.8にアップデートし、追加で別のパッケージをインストールすることで、H100でも動くようになります。
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 torchdata=0.6.0 pytorch-cuda=11.8 -c pytorch -c nvidia # バージョンを上書きインストール
pip install -U rich # 追加で必要
**Jupyter Notebookでコードを動かす際は、以下のようにして、新しいパッケージをインストールします。
conda install ipykernel
python -m ipykernel install –-user --name env --display-name env
Pretrainされたモデル
ClimaXはpretrainされたモデル(チェックポイント)を公開していますので、今回はそちらをダウンロードします。こちらのサイトから5.625度のモデル(5.625deg.ckpt)と1.40625度(1.40625deg.ckpt)のモデルがダウンロードできます。
タスク1:全球(グローバル)気象予測
まずは、5.625度の解像度で、全球での気象予測について見て行きます。こちらのタスクのfinetuningには、NVIDIA H100マシンを4 GPUs使用しました。
ステップ1:Finetuning用のデータをダウンロードする
前回の記事で紹介したように、気象予測のタスクには、ERA5のデータが使われています。こちらから5.625度用のデータをdata/weatherbench/のディレクトリにダウンロードします。
wget "https://dataserv.ub.tum.de/s/m1524895/download?path=%2F5.625deg&files=all_5.625deg.zip" -O all_5.625deg.zip
そして、ダウンロードしたデータの前処理を行います。
python src/data_preprocessing/nc2np_equally_era5.py \
--root_dir data/weatherbench/5.625deg \
--save_dir data/weatherbench/5.625deg_npz \
--start_train_year 1979 --start_val_year 2016 \
--start_test_year 2017 --end_year 2019 --num_shards 8
このプロセスにより、netcdfのファイルタイプからnumpyの形にし、データをノーマライズするための数値を計算し、トレーニングやテストデータ用に分割します。これらのデータは、data/weatherbench/5.625deg_npzのディレクトリに作られています。
ステップ2:PretrainされたモデルをFinetuneする
データは用意できたので、finetuningをして行きましょう。ClimaXはPyTorchのLightning Moduleを使用しており、コマンドからconfigurationを指定して、finetuningを行います。Configurationのファイルは、climax/configs/global_forecast_climax.yamlにあり、finetuningを走らせる前にこのファイルを少し編集する必要があります。編集が必要な箇所は、
- Finetuneされた結果を保存するディレクトリ先の変更
- Finetuning用のデータが保存されているディレクトリ先の変更
- Pretrainされたモデルが保存されているディレクトリ先の変更
となります。以上の変更が終わったら、以下のコマンドでfinetuningを実行します。
python src/climax/global_forecast/train.py --config configs/global_forecast_climax.yaml --trainer.strategy=ddp --trainer.devices=4 --trainer.max_epochs=1 --data.root_dir=data/weatherbench/5.625deg_npz --data.predict_range=72 --data.batch_size=8 --model.pretrained_path="data/pretrained/5.625deg.ckpt" --model.lr=5e-7 --model.beta_1="0.9" --model.beta_2="0.99" --model.weight_decay=1e-5
NVIDIA H100のマシン(4 GPU)で、39 epoch目でトレーニングが終了し、トータルの所要時間は660分でした。Finetuningの結果は、ClimaX/exps/global_forecast_climax/checkpointsに保存されています。
*--data.batch_size=16にすると、1 epochあたりの、トレーニング時間の短縮が見られた(17分→11分)が、最終的なモデルの精度は少し下がった(0.8958→0.8742)。
ステップ3:テストデータを使用して気象予測をする
最後のステップは、トレーニングされたモデルをベースに予測(inference)を行うことです。この記事では、Jupyter Notebookを使用して、予測を走らせますが、こちらのモジュールに追加でpredict_step(例はこちら)を追加し、train.pyを参考にして、L33-37の代わりに、predictions=cli.trainer.predict(cli.model, datamodule=cli.datamodule)を書くことによっても、予測は可能です。
まずは、必要なパッケージをインポートしましょう。
import torch
from torch import nn
import os,sys
import climax
from climax.arch import ClimaX
from pytorch_lightning.cli import LightningCLI
from pytorch_lightning import LightningModule
from torch.utils.data import DataLoader
from climax.utils.metrics import mse, lat_weighted_nrmse, lat_weighted_rmse, lat_weighted_acc, lat_weighted_mse
from torchvision.transforms import transforms
import yaml
import numpy as np
from climax.pretrain.datamodule import collate_fn
from tqdm import tqdm
from climax.global_forecast.datamodule import GlobalForecastDataModule
from climax.global_forecast.module import GlobalForecastModule
そしたら、finetuneされたモデルをロードします。(* configurationファイルのdata.root_dirが正しいことを確認して下さい。)
cpt_path = 'finetune.ckpt'
cfg_path = 'ClimaX/configs/global_forecast_climax.yaml'
# configurationファイルを開けます。
with open(cfg_path) as f:
config = yaml.safe_load(f)
model = GlobalForecastModule(ClimaX(config['data'['variables']), pretrained_path=cpt_path)
model.eval()
これでモデルがロードされました。次に初期条件としてのデータをロードします。
data_input = GlobalForecastDataModule(config['data']['root_dir'], config['data']['variables'], config['data']['buffer_size'], out_variables=config['data']['out_variables'])
data_input.prepare_data()
data_input.setup()
lat = data_input.get_lat_lon()[0]
normalization = data_input.output_transforms
# PyTorchのDataLoaderのクラスを使います。
test_loader = DataLoader(data_input.data_test, batch_size=1, num_workers=1,
pin_memory=False, shuffle=False, drop_last=False, collate_fn=collate_fn)
データが準備できたら、予測を回して行きます。
# それぞれのインデックスには、ERA5のデータが1時間毎に入っているので、forループを回すことで、すべてのデータに対して、予測をかけて行きます。モデルの予測精度を測る際に有効です。
for x, y, lead_times, variables, out_variables in tqdm(test_loader):
loss, pred = model.net.forward(
x, y, # xは予測の初期条件、yは予測値と比べる真の値。
lead_times, # 予測時間(デフォルトは6時間。)
config['data']['variables'],
config['data']['out_variables'],
metric=[lat_weighted_mse],
lat=lat
)
loss, predがモデルの精度(この例ではMSEを使用。metricで定義できる。)と予測値を表しています。予測時間であるlead_timesは、GlobalForecastDataModule(predict_range=config['data']['predict_range'])で調整することができます。
ループを1度回した結果を見てみましょう。Configurationファイルの中で指定した、それぞれのアウトプットが予測され、精度が計算されています。
loss =
[{'geopotential_500': tensor(0.0020),
'temperature_850': tensor(0.0079),
'2m_temperature': tensor(0.0076),
'10m_u_component_of_wind': tensor(0.0952),
'10m_v_component_of_wind': tensor(0.1632),
'loss': tensor(0.0552, grad_fn=<MeanBackward0>)}]
predには、予測結果がtorch.tensorとして、入っており、上記の例ではtorch.Size([1, 5, 32, 64])となっています。この形は、[予測回数、アウトプット変数の数、画像の縦サイズ、画像の横サイズ]となっています。
予測の結果は、ステップ4で見てみましょう。
この例では、予測には論文にも用いられたテストデータ(ERA5の2017~2018年データ)を用いていますが、他のデータを予測に使用したい際は、こちらに従い、データをClimaXが使いやすいフォーマットにします。
ステップ4:テスト結果を可視化する
ステップ3で行った予測の結果を可視化して行きましょう。以下のパッケージを使います。
import xarray as xr
import cartopy.crs as ccrs
import matplotlib
from matplotlib import pyplot as plt
import seaborn as sns
ステップ3で行った予測は、ローデータをノーマライゼーションをして行われていますので、予測結果を元のデータの単位にするには、ノーマライゼーションのステップを元に戻さなければいけません。
normalization = data_input.output_transforms
mean_norm, std_norm = normalization.mean, normalization.std
mean_denorm, std_denorm = -mean_norm / std_norm, 1 / std_norm
transform_denorm = transforms.Normalize(mean_denorm, std_denorm)
pred_ = transform_denorm(pred)
y_ = transform_denorm(y)
ノーマライゼーションのステップが終わったら、以下のようにして、可視化します。
with sns.plotting_context("talk"):
fig = plt.figure(figsize=(24, 8))
plt.subplot(231, projection=proj)
im = plt.imshow(y_.detach().numpy()[0, 2, :, :], cmap="coolwarm", transform=ccrs.PlateCarree(), vmin=230, vmax=310)
cbar = plt.colorbar(im)
plt.gca().coastlines()
plt.gca().set_title('Truth \n 2m temperature')
plt.subplot(232, projection=proj)
im = plt.imshow(pred_.detach().numpy()[0, 2, :, :], cmap="coolwarm", transform=ccrs.PlateCarree(), vmin=230, vmax=310)
cbar = plt.colorbar(im)
plt.gca().coastlines()
plt.gca().set_title('6hr prediction \n 2m temperature')
plt.subplot(233, projection=proj)
im = plt.imshow(y_.detach().numpy()[0, 2, :, :] - pred_.detach().numpy()[0, 2, :, :], cmap="coolwarm", transform=ccrs.PlateCarree())
cbar = plt.colorbar(im)
plt.gca().coastlines()
plt.gca().set_title('Difference \n 2m temperature')
plt.subplot(234, projection=proj)
im = plt.imshow(y_.detach().numpy()[0, 3, :, :], cmap="coolwarm", transform=ccrs.PlateCarree(), vmin=-15, vmax=15)
cbar = plt.colorbar(im)
plt.gca().coastlines()
plt.gca().set_title('10m u-component wind velocity')
plt.subplot(235, projection=proj)
im = plt.imshow(pred_.detach().numpy()[0, 3, :, :], cmap="coolwarm", transform=ccrs.PlateCarree(), vmin=-15, vmax=15)
cbar = plt.colorbar(im)
plt.gca().coastlines()
plt.gca().set_title('10m u-component wind velocity')
plt.subplot(236, projection=proj)
im = plt.imshow(y_.detach().numpy()[0, 3, :, :] - pred_.detach().numpy()[0, 3, :, :], cmap="coolwarm", transform=ccrs.PlateCarree(),)
cbar = plt.colorbar(im)
plt.gca().coastlines()
plt.gca().set_title('10m u-component wind velocity')
plt.savefig('pred_loss.png', bbox_inches='tight')
可視化した結果がこちらです。
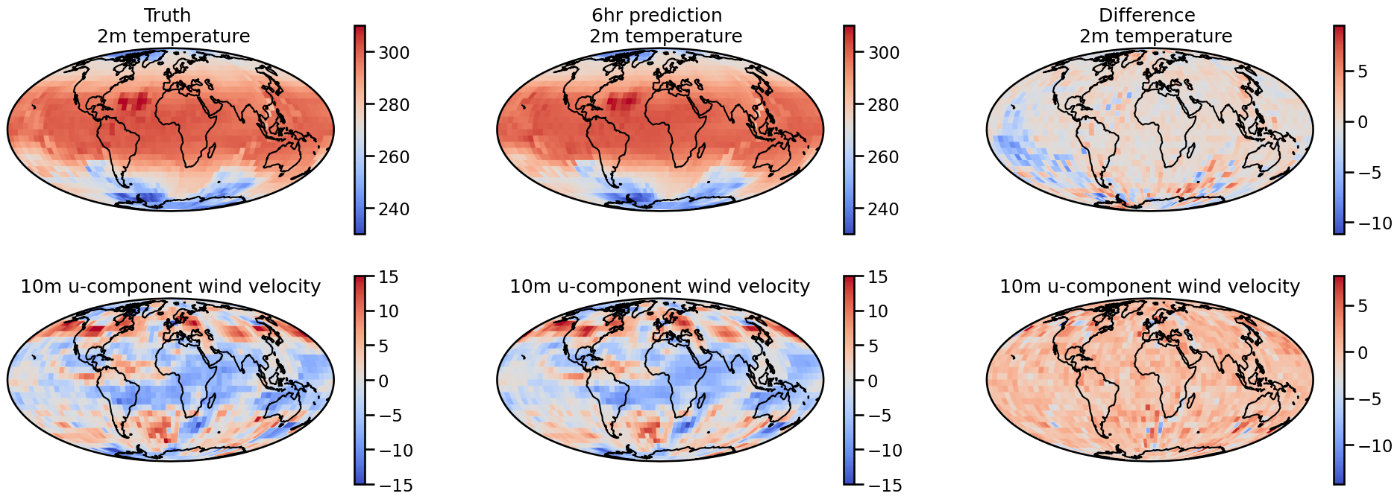
次に、気候変動予測について、詳しく紹介して行きたいと思います。
タスク2:気候変動予測
次に、気候変動予測ですが、こちらに関しては、私はRTX3090のマシンを用いて、5.625度の解像度でfinetuningを行い、予測を走らせました。
ステップ1:Finetuning用のデータをダウンロードする
前回の記事で紹介したように、気候変動予測のタスクには、ClimateBenchのデータが使われています。こちらからtrain_val.tar.gzとtest.tar.gzをdata/climatebench/5.625deg/のディレクトリにダウンロードします。
そしたら、ダウンロードしたデータを5.625度の格子になるようにプロセスします。(* ClimateBenchのそのままの格子粒度でも動きます。)
python src/data_preprocessing/regrid_climatebench.py data/climatebench/5.625deg/train_val --save_path data/climatebench/5.625deg/train_val --ddeg_out 5.625
python src/data_preprocessing/regrid_climatebench.py data/climatebench/5.625deg/test --save_path data/climatebench/5.625deg/test --ddeg_out 5.625
そして、次のステップで予測を行うためには、手動でdata/climatebench/5.625deg/train_val/inputs_historical.ncとdata/climatebench/5.625deg/train_val/outputs_historical.ncをdata/climatebench/5.625deg/testにコピーする必要があります。忘れずにファイルのコピーを行って下さい。
これで、データの前処理が終わりました。次に、これらのデータを使ってfinetuneに入って行きます。
ステップ2:PretrainされたモデルをFinetuneする
データは用意できたので、finetuningをして行きましょう。気候変動予測の場合、configurationのファイルは、climax/configs/climate_projection.yamlにあり、finetuningを走らせる前に、気象予測の時と同様に、このファイルを少し編集しましょう。
ファイルの編集が終わったら、以下のコマンドでfinetuningを実行します。この例では、二酸化炭素や二酸化硫黄などの量をインプットに、気温をアウトプットとして予測するトレーニングをしていますが、他のアウトプットを同時にトレーニングすることも可能です。
python src/climax/climate_projection/train.py --config configs/climate_projection.yaml --trainer.strategy=ddp --trainer.devices=1 --trainer.max_epochs=50 --data.root_dir=data/climatebench/5.625deg/ --data.out_variables="tas" --data.batch_size=4 --model.pretrained_path='data/pretrained/5.625deg.ckpt' --model.lr=5e-4 --model.beta_1="0.9" --model.beta_2="0.99" --model.weight_decay=1e-5
NVIDIA RTX3090のマシン(1 GPU)で、12 epoch目でトレーニングが終了し、トータルの所要時間は20分でした。Finetuningの結果は、ClimaX/exps/climate_projection_climax/checkpointsに保存されています。
ステップ3:テストデータを使用して気候変動予測をする
最後のステップは、トレーニングされたモデルをベースに予測を行うことです。気象予測の時と同様に、まずは必要なパッケージをインポートしましょう。
import torch
from torch import nn
import os,sys
import climax
from climax.arch import ClimaX
from pytorch_lightning.cli import LightningCLI
from pytorch_lightning import LightningModule
from torch.utils.data import DataLoader
from climax.utils.metrics import mse, lat_weighted_nrmse, lat_weighted_rmse, lat_weighted_acc, lat_weighted_mse
from torchvision.transforms import transforms
import yaml
import numpy as np
from climax.pretrain.datamodule import collate_fn
from tqdm import tqdm
from climax.global_forecast.datamodule import GlobalForecastDataModule
from climax.global_forecast.module import GlobalForecastModule
そしたら、finetuningしたモデルをロードします。(* configurationファイルのdata.root_dirが正しいことを確認して下さい。)
cpt_path = 'finetune.ckpt'
cfg_path = 'ClimaX/configs/climate_projection.yaml'
# configurationファイルを開けます。
with open(cfg_path) as f:
config = yaml.safe_load(f)
checkpoint = torch.load(cpt_path)
new_state_dict = {key.replace("net.", ""): value for key, value in checkpoint["state_dict"].items()}
model = ClimaXClimateBench(['CO2', 'SO2', 'CH4', 'BC'], ['tas'], time_history=int(config['data']['history']))
model.load_state_dict(new_state_dict)
model = ClimateProjectionModule(model, pretrained_path=cpt_path)
model.eval()
これでモデルがロードされました。次に初期条件としてのデータをロードします。
data_input = ClimateBenchDataModule(config['data']['root_dir'])
lat = data_input.dataset_test.lat
test_loader = DataLoader(data_input.dataset_test, batch_size=1, num_workers=1, pin_memory=False, shuffle=False, collate_fn=climax.climate_projection.datamodule.collate_fn)
データが準備できたら、予測を回して行きます。
# それぞれのインデックスには、ClimateBenchのSSP245データが2080〜2100年分入っています。
for x, y, lead_times, variables, out_variables in tqdm(test_loader):
loss, pred = model.net(
x, y,
lead_times,
variables,
out_variables,
[mse],
lat=lat
)
loss, predがモデルの精度(この例ではMSEを使用。metricで定義できる。)と予測値を表しています。第一回や第二回でもお話ししたように、気候変動予測は気象予測とは違い、気温上昇などを引き起こすと言われている化学物質の量を元に、地球の平均気温や降水量を予測します。この例では、xがXX年の二酸化炭素、二酸化硫黄、ブラックカーボン、メタンの量、yがXX年の1年の全球表面温度の平均を表しています。ClimaXを使用して予測した結果であるpredと、SSP245のデータセットですでに予測されているyの値を比べることで、予測の精度がわかります。
ループを1度回した結果を見てみましょう。Configurationファイルの中で指定した、それぞれのアウトプットが予測され、精度が計算されています。
loss = [{'tas': tensor(0.2425), 'loss': tensor(0.2425, grad_fn=<MeanBackward0>)}]
predには、予測結果がtorch.tensorとして、入っており、上記の例ではtorch.Size([1, 1, 32, 64])となっています。この形は、[予測年数、アウトプット変数の数、画像の縦サイズ、画像の横サイズ]となっています。
予測の結果は、ステップ4で見てみましょう。
ステップ4:テスト結果を可視化する
ここでは、気象予測の可視化の際に使用したパッケージをそのまま使います。
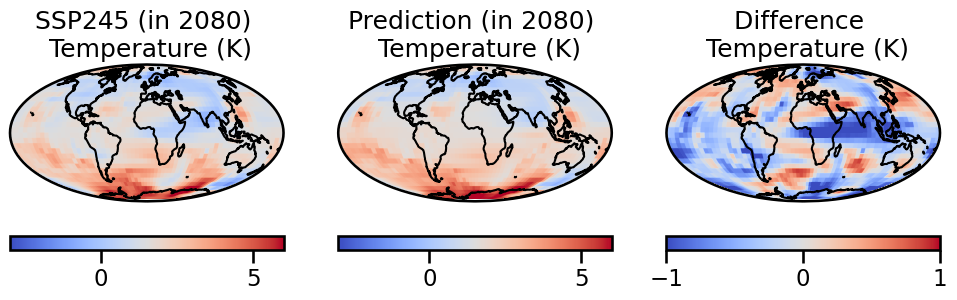
with sns.plotting_context("talk"):
fig = plt.figure(figsize=(12, 3))
plt.subplot(131, projection=proj)
im = plt.imshow(y.detach().numpy()[0, 0, :, :], cmap="coolwarm", transform=ccrs.PlateCarree(), vmin=-3, vmax=6)
cbar = plt.colorbar(im, orientation='horizontal')
plt.gca().coastlines()
plt.gca().set_title('SSP245 (in 2080) \n Temperature (K)')
plt.subplot(132, projection=proj)
im = plt.imshow(pred.detach().numpy()[0, 0, :, :], cmap="coolwarm", transform=ccrs.PlateCarree(), vmin=-3, vmax=6)
cbar = plt.colorbar(im, orientation='horizontal')
plt.gca().coastlines()
plt.gca().set_title('Prediction (in 2080) \n Temperature (K)')
plt.subplot(133, projection=proj)
im = plt.imshow(y.detach().numpy()[0, 0, :, :] - pred.detach().numpy()[0, 0, :, :], cmap="coolwarm", transform=ccrs.PlateCarree(), vmin=-1, vmax=1)
cbar = plt.colorbar(im, orientation='horizontal')
plt.gca().coastlines()
plt.gca().set_title('Difference \n Temperature (K)')
可視化した結果がこちらです。
これで、ClimaXを使用した気象予測と気候変動予測ができました。次の最終回では、どのようにすればClimaXを日本の気象予測や気候変動予測に使うことができるか、モデルのトレーニング時間を元に定性的に考えて行きたいと思います。
Discussion