この記事について
こんにちは、東京大学鈴村研究室で、インフラエンジニアとしてお手伝いさせていただいています、福田と申します。
これまで、クラウド基盤mdxの上でKubernetes環境を構築し、サーバレスWebアプリケーションを開発するための手順や、分散学習を行うための手順について説明してきました。
今回は、NVIDIAのH100、A100、A30などの高性能なGPUに実装されている機能である、Multi-Instance GPU(MIG)という機能を用いて、1つのGPUを仮想的に複数に分割した上で、LLMを推論させるための方法について解説していきます。
このMulti-Instance GPUを使うことで、mdxのGPU仮想マシンにあるNVIDIA A100を、4つに分割することができるので、複数のLLMを実行させるなど、GPUをより効率的・効果的に使うことができるようになります。
前提
この記事ではクラウド基盤mdxの上に、Kubernetesクラスタが構築されていることを前提とするため、mdxの上で仮想マシンを構築する方法や、Kubernetesクラスタ自体の構築方法については説明しません。
これらの手順を知りたい場合は、以下の過去記事を参照ください。
KubernetesでMulti-Instance GPUを使う設定
まず、Kubernetesクラスタを管理するツールLensを開き、左側の一覧から、Nodesを開きます。
次に、右側のnode一覧から、nodeを1つ選びます。
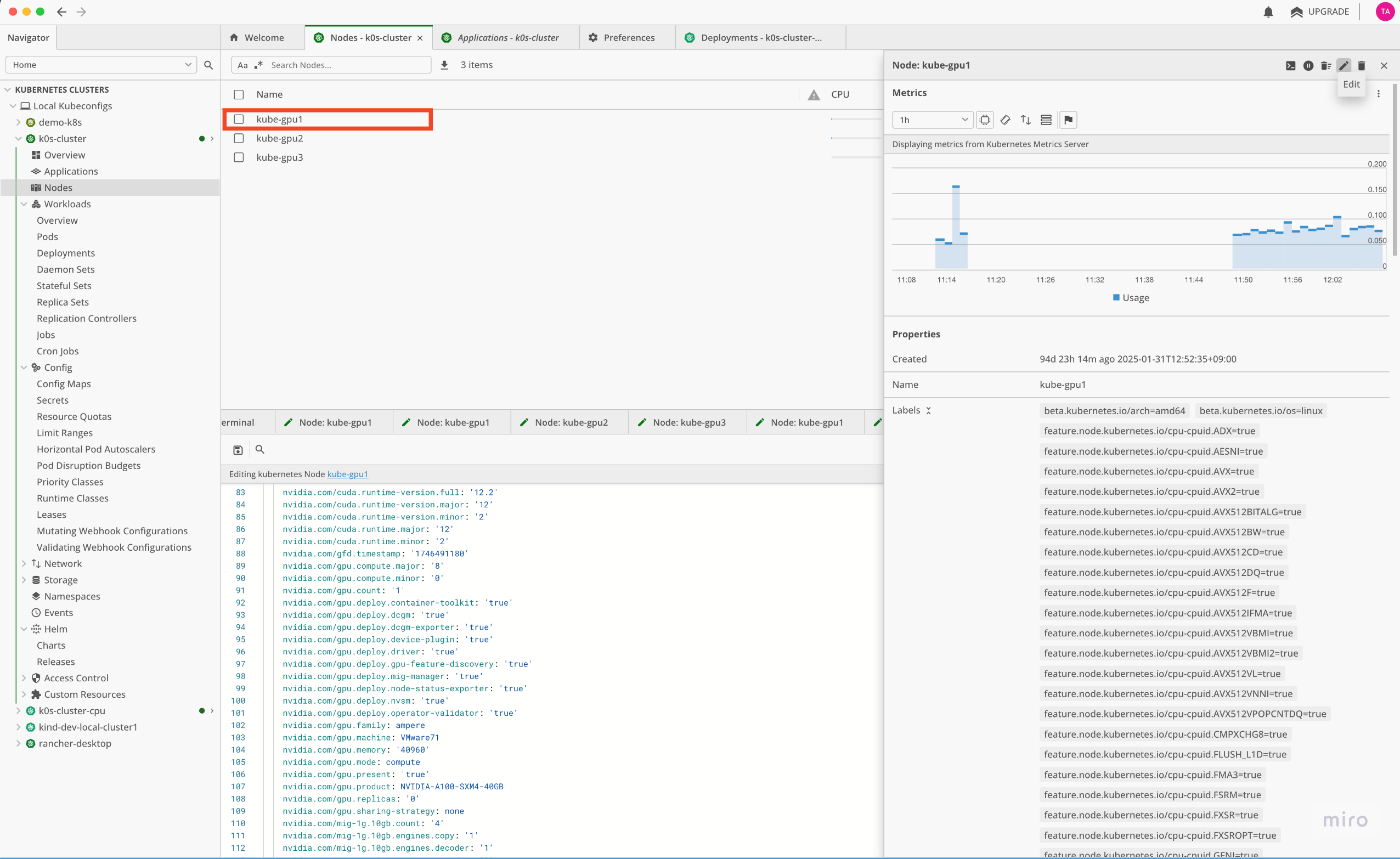
右側に表示される、各nodeの詳細画面から、鉛筆マークのEditボタンを押下します。

すると、画面下部に、nodeのconfigの編集画面が開きます。
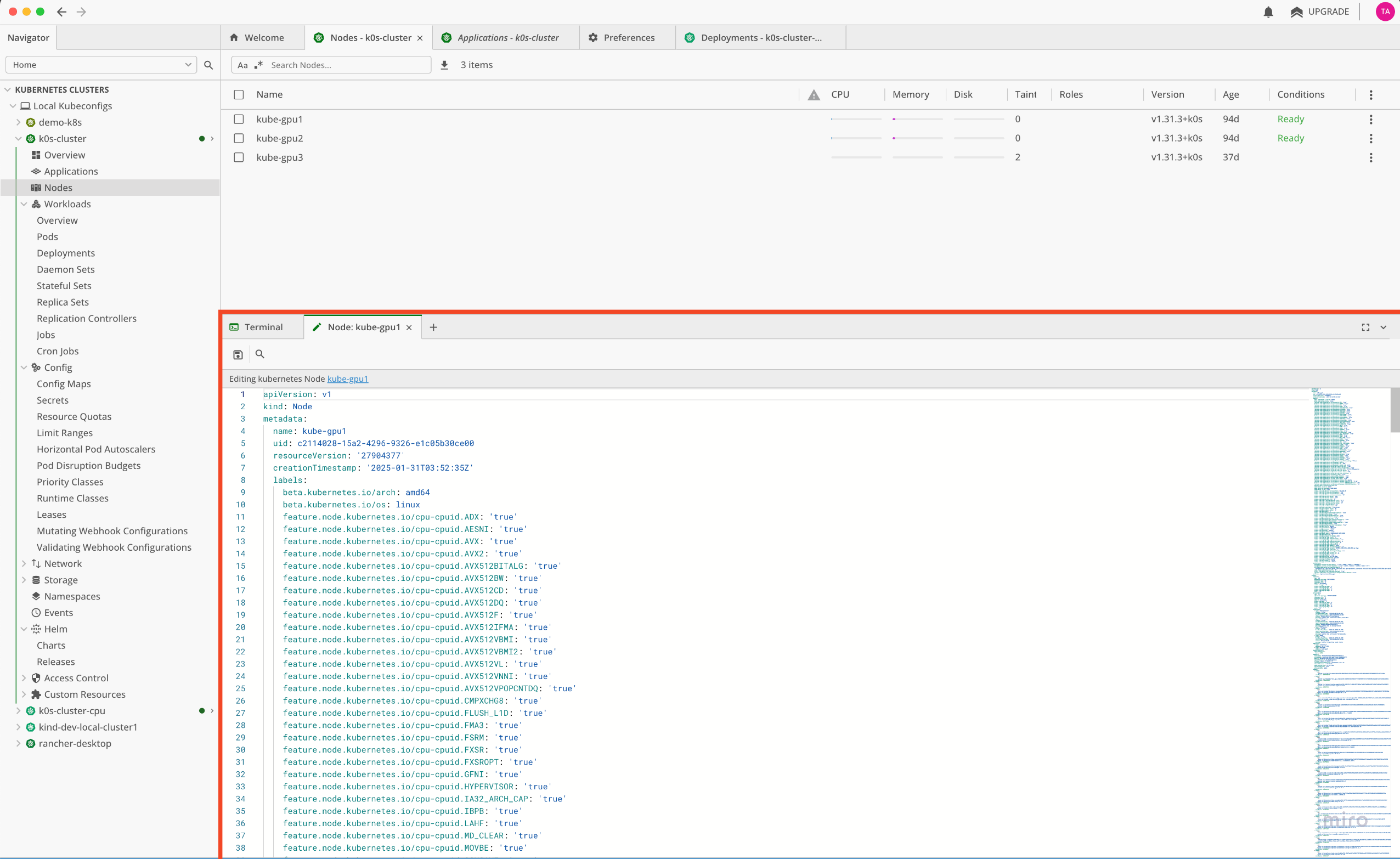
configの編集画面にて、nvidia.com/mig.config:という項目を検索します。
このとき、Command + F で、文字列で検索することも可能です。

この項目について、初期状態では、all-disabledが設定されていますが、ここに、all-1g.10gbを設定します。

設定後、左上のSaveボタンから保存を行います。

なお、このall-1g.10gbの意味ですが、1Unitあたり10GBのGPUメモリを持つGPUパーティションに分割するという意味になります。
mdxのGPUインスタンスには、NVIDIA A100-SXM4-40GBが搭載されており、GPUメモリは40GBとなるため、10GBのGPUメモリを持つパーティションが4つ作成されることになります。
ざっくり言うと、1つのA100 GPUから、10GBのGPUメモリを持つGPUが4つ作れることになります。
しばらく経つと、MIGの設定が反映されます。
実際に反映されたことを確認するため、KubernetesのGPUノードに接続し、nvidia-smiコマンドを実行します。
すると、以下の通りに、A100 GPUが4つに分割されていることを確認できます。
nvidia-smi
Sat May 10 08:55:27 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.216.03 Driver Version: 535.216.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A100-SXM4-40GB On | 00000000:03:00.0 Off | On |
| N/A 29C P0 91W / 400W | 50MiB / 40960MiB | N/A Default |
| | | Enabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| MIG devices: |
+------------------+--------------------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG |
| | | ECC| |
|==================+================================+===========+=======================|
| 0 3 0 0 | 12MiB / 9856MiB | 14 0 | 1 0 1 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 0 4 0 1 | 12MiB / 9856MiB | 14 0 | 1 0 1 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 0 5 0 2 | 12MiB / 9856MiB | 14 0 | 1 0 1 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 0 6 0 3 | 12MiB / 9856MiB | 14 0 | 1 0 1 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
MIGを使用したKNativeでのLLM Webサービスの構築
次に、設定したMIGを使って、KNativeでLLM Webサービスのデプロイを行います。
今回はvLLMの提供する、OpenAI互換のAPIを構築できるDocker imageを使用します。
このDocker Imageの詳しい使い方は以下のURLを参照ください。
デプロイのためのyamlは以下の通りとなりますが、ポイントは、resources.limitsにて、nvidia.com/mig-1g.10gb: 1を設定する点です。
こうすることで、MIGをGPUリソースとして使うことを明示的に指定できます。
他には、クライアントからアクセスするための認証キーとして、--api-keyに任意のpassphaseを設定します。
第三者から推測されにくい文字列を設定することをお勧めします。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: llm-jp-3-18b-instruct
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/minScale: "1" # 最低でも1Podは起動させる
autoscaling.knative.dev/maxScale: "10" # スケールアウト時の最大Pod数は10とする
autoscaling.knative.dev/target: "3" # 1Podあたり同時接続数3を超えると、Podが増える
autoscaling.knative.dev/metric: "concurrency" # オートスケールのメトリックスとしてconcurrency(同時接続数)を使用する
spec:
containers:
- image: vllm/vllm-openai:latest # vLLMのOpenAI Compatible API Imageを使用
args:
- "--model"
- "llm-jp/llm-jp-3-1.8b-instruct3"
- "--host"
- "0.0.0.0"
- "--port"
- "8000"
- "--download-dir"
- "/large"
- "--api-key"
- "XXXXXXXXXXXXXXXXXXXXXXX" # ここは任意のpassphraseを設定
ports:
- containerPort: 8000
resources:
limits:
nvidia.com/mig-1g.10gb: 1 # ここがポイント
volumeMounts:
- mountPath: /large
name: pvc-large-volume
volumes:
- name: pvc-large-volume
persistentVolumeClaim:
claimName: hostpath-pvc-large
なお、KNativeにはオートスケールに関する設定が備わっており、このサンプルでは、この設定も行っています。
具体的には以下の部分です。
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/minScale: "1" # 最低でも1Podは起動させる
autoscaling.knative.dev/maxScale: "10" # スケールアウト時の最大Pod数は10とする
autoscaling.knative.dev/target: "3" # 1Podあたり同時接続数3を超えると、Podが増える
autoscaling.knative.dev/metric: "concurrency" # オートスケールのメトリックスとしてconcurrency(同時接続数)を使用する
各々の設定項目の説明は以下の通りです。
| キー名 | 説明 |
|---|---|
| autoscaling.knative.dev/minScale | Pod の最小スケール数(最小インスタンス数)を指定 トラフィックがないときでも最低限この数の Pod を常に稼働させておきたい場合に使用 |
| autoscaling.knative.dev/maxScale | Pod の最大スケール数(最大インスタンス数)を指定 突発的な高負荷でも、Pod をこの数以上には増やしたくないときに使用 |
| autoscaling.knative.dev/target | スケーリング判断に使うメトリクスの目標値を指定。 1Pod あたりにどのくらいの負荷を許容するかを設定する。 指標には、以下の 2 種類がある concurrency(デフォルト): 1 Pod あたりの同時リクエスト数 rps: 1 Pod あたりのリクエスト毎秒数 |
作成したyamlファイルを以下のコマンドを使ってデプロイします。
kubectl apply -f (yamlファイルへのpath)
Lensを使って、サービスが立ち上がっていることを確認します。

以下のコマンドでサービスにアクセスするためのURLを確認します。
% kubectl get ksvc
NAME URL LATESTCREATED LATESTREADY READY REASON
llm-jp-3-18b-instruct https://llm-jp-3-18b-instruct.default.example.com llm-jp-3-18b-instruct-00001 llm-jp-3-18b-instruct-00001 True
OpenAI Clientでのアクセス
今回デプロイしたLLM Webサービスは OpenAIのAPIに準拠していますので、PythonのOpenAIクライアントをアクセス元のPCなどにインストールします。
pip install openai
uvなどのパッケージマネージャーを使用している場合は、以下のコマンドインストールしてください。
uv add openai
次に、アクセスするためのスクリプトを作成します。
ここで、api_keyには、KNativeのWebサービス定義のyamlに定義した、api_keyの値と一致させます。
またアクセスするためのURLとしては、kubectl get ksvc で得られたURLの末尾に、/v1を付与したものを使用するようにします。
if __name__ == '__main__':
from openai import OpenAI
client = OpenAI(
base_url="https://llm-jp-3-18b-instruct.default.example.com/v1", # URLの末尾には/v1を付与する
api_key="xxxxxxxxxxxxx", # KNativeのapi_keyの値と一致させる。
)
completion = client.chat.completions.create(
model="llm-jp/llm-jp-3-1.8b-instruct", # KNativeの--modelの引数に指定した値を設定する
temperature=0.1,
messages=[
{"role": "user", "content": "富士山について教えてください。"}
]
)
print(completion.choices[0].message.content)
上記のコードを実行すると、以下のような結果が得られます。
富士山は、日本の象徴的な山で、その美しい姿と豊かな自然環境から多くの人々に愛されています。以下に主な特徴をいくつか挙げます。
1. **標高**: 富士山の最高点は3,776メートルで、これは世界で最も高い山の一つです。
2. **形状**: 富士山は円錐形の山で、頂上部が平らで広がっています。これは、火山活動によって形成された特徴的な形状です。
3. **文化的意義**: 富士山は日本の文化や信仰において重要な位置を占めています。特に、富士山信仰は古くから存在し、山頂への参拝や登山が行われてきました。
4. **自然環境**: 富士山は豊かな森林と清らかな水を有しており、その周辺には多くの国立公園や自然保護区があります。
5. **観光**: 富士山は国内外から多くの観光客を惹きつける人気の観光地です。特に、夏には登山シーズンとなり、多くの人々が山頂を目指します。
6. **環境問題**: 最近では、富士山の環境保護が重要な課題となっています。特に、登山者の増加による環境負荷や、廃棄物の問題などが挙げられます。
これらの情報は、富士山の全体像を理解するための一部ですが、詳細についてはさらに調査が必要かもしれません。
オートスケールの確認
今回はオートスケールの設定も入れているので、多数の同時アクセスがあった時にオートスケールが本当に効くのかの実験もしてみたいと思います。
複数の同時アクセスをシミュレーションするため、Pythonのlocustというライブラリを使用することにします。
まず、locustをインストールします。
pip install locust
次に、locustで負荷テストを行うためのPythonスクリプトを書いていきます。
ここで、@taskが付いている部分が、locustで同時並列で実行されるタスクの実体となっています。
ファイル名は、locustfile.pyとして保存します。
from locust import HttpUser, task, between
from openai import OpenAI
class MyUser(HttpUser):
wait_time = between(1, 3) # 各クライアントから1~3秒おきにランダムにリクエストを投げるという意味
host = "https://llm-jp-3-18b-instruct.default.example.com/v1" # リクエスト先のURLを設定
api_key = "xxxxxxxxxxxxx" # KNativeのデプロイyamlで設定したapi_keyを指定
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.client = OpenAI(
base_url=self.host,
api_key=self.api_key,
)
def _headers(self):
headers = {
"Content-Type": "application/json"
}
return headers
@task # locsutから並列で実行されるタスクの実体
def llm(self):
completion = self.client.chat.completions.create(
model="llm-jp/llm-jp-3-1.8b-instruct3",
messages=[
{"role": "user", "content": "フーリエ変換について教えてください。"}
]
)
print(completion.choices[0].message)
locustfile.pyの置かれているディレクトリに移動して、locustというコマンドを実行します。
cd (locustfile.pyの置かれているディレクトリへのpath)
locust
すると以下のような起動ログが得られます。
[2025-05-11 08:49:39,162] gg402096-005/INFO/locust.main: Starting Locust 2.33.2
[2025-05-11 08:49:39,163] gg402096-005/INFO/locust.main: Starting web interface at http://0.0.0.0:8089, press enter to open your default browser.
次にWebブラウザを開き、 http://localhost:8089 にアクセスします。
すると以下のような画面が表示されます。
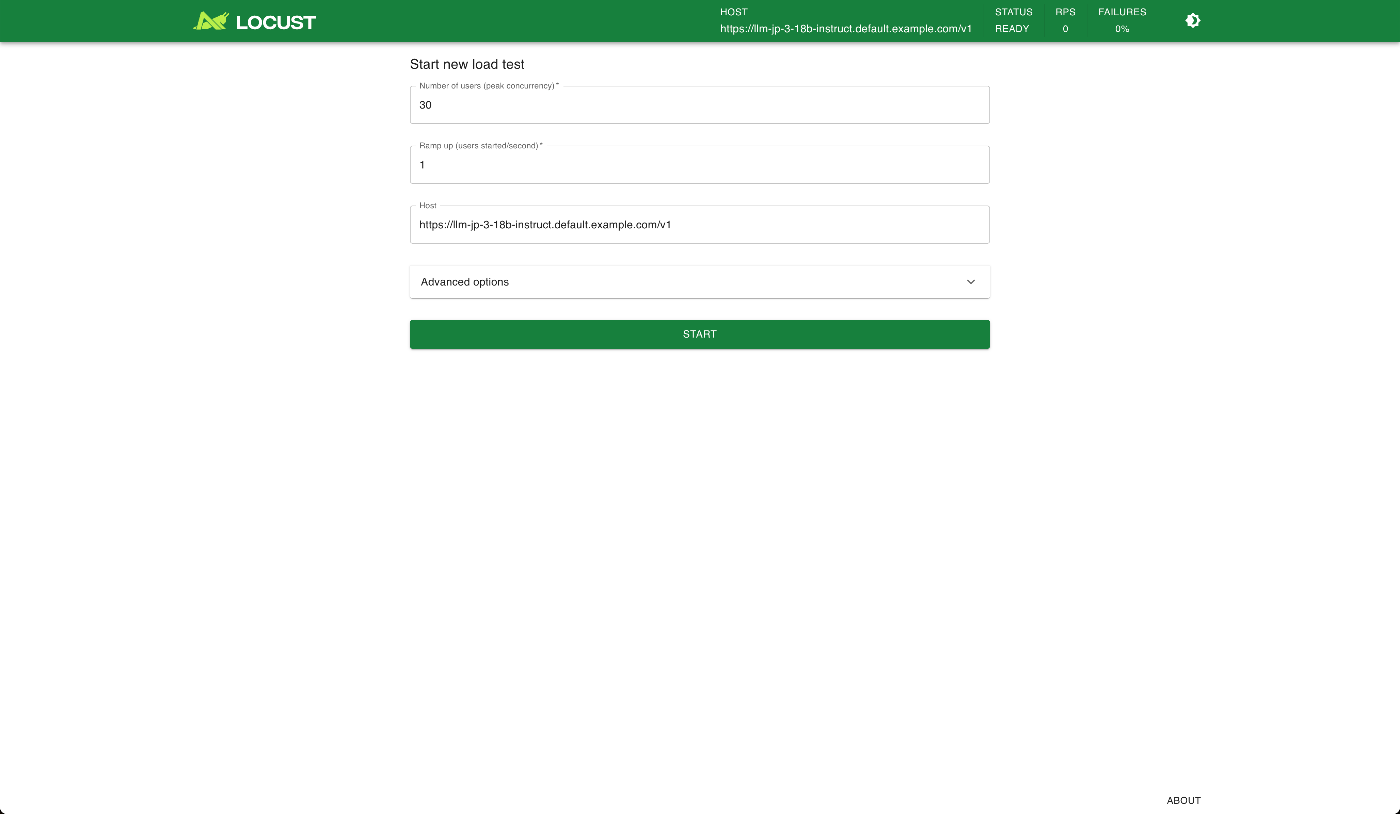
この画面の各項目の意味は以下の通りです。
| 項目名 | 説明 |
|---|---|
| Number of users (peak concurrency) | 仮想ユーザー数の最大値(同時にアクセスするユーザー数)。例:30 に設定すると、最終的に30人の仮想ユーザーが同時にターゲットにリクエストを送るようになる。 |
| Ramp up (users started/second) | 仮想ユーザーの追加速度。1秒間に何人のユーザーを追加するか。例:1 なら、1秒ごとに1人ずつユーザーを増やし、30人になるまでに30秒かかる。 |
| Host | テスト対象となるホスト(APIやWebサイトのベースURL)。例:https://llm-jp-3-18b-instruct.default.example.com/v1 に向けてテストが実施されます。 |
これらの項目を設定して、STARTボタンを押下すると、設定した内容で負荷テストが開始します。
画面上部のタブから、CHARTを選択すると、リクエストの数、ユーザー数、レスポンスタイム、失敗数がグラフで確認できます。
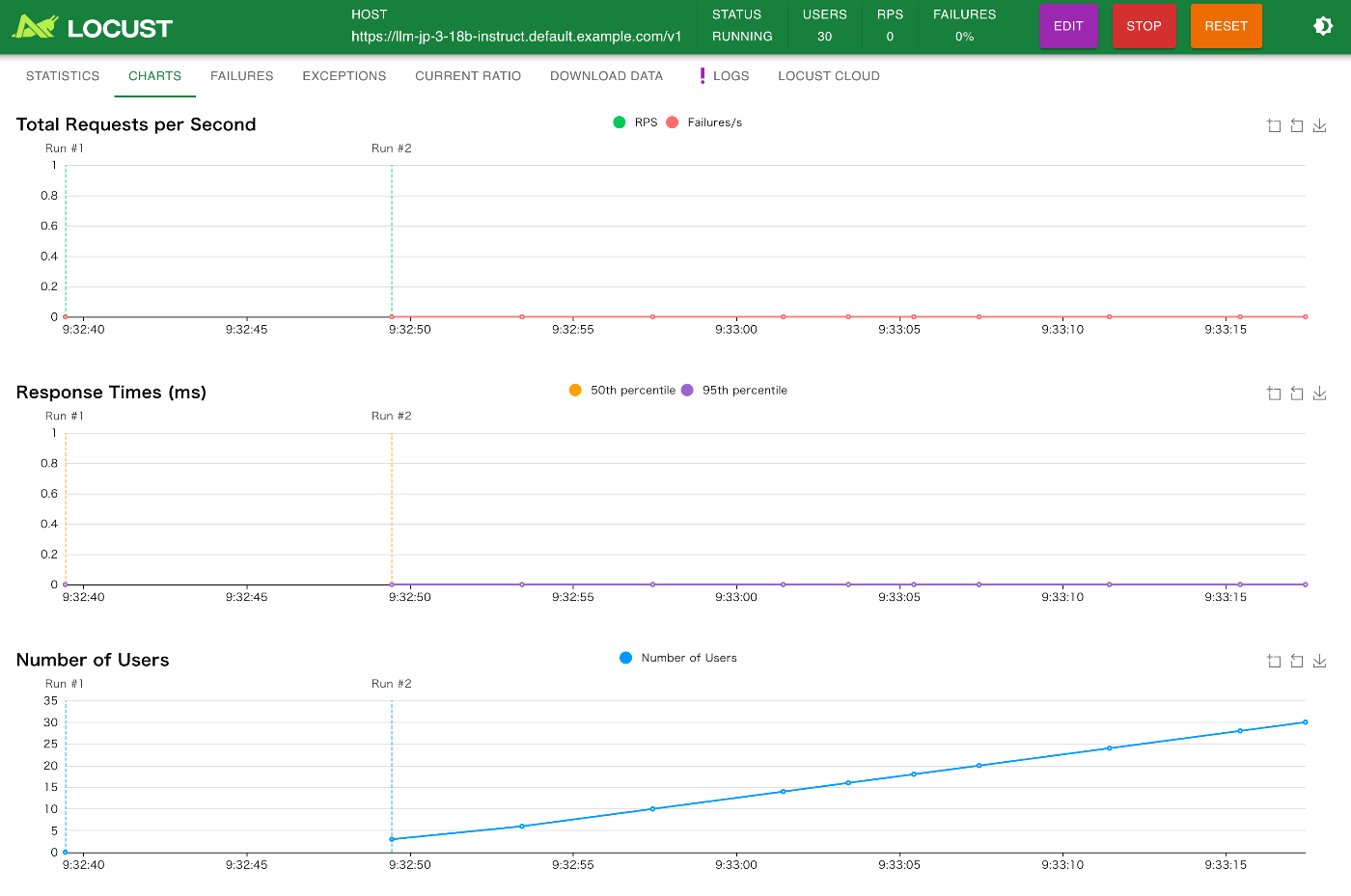
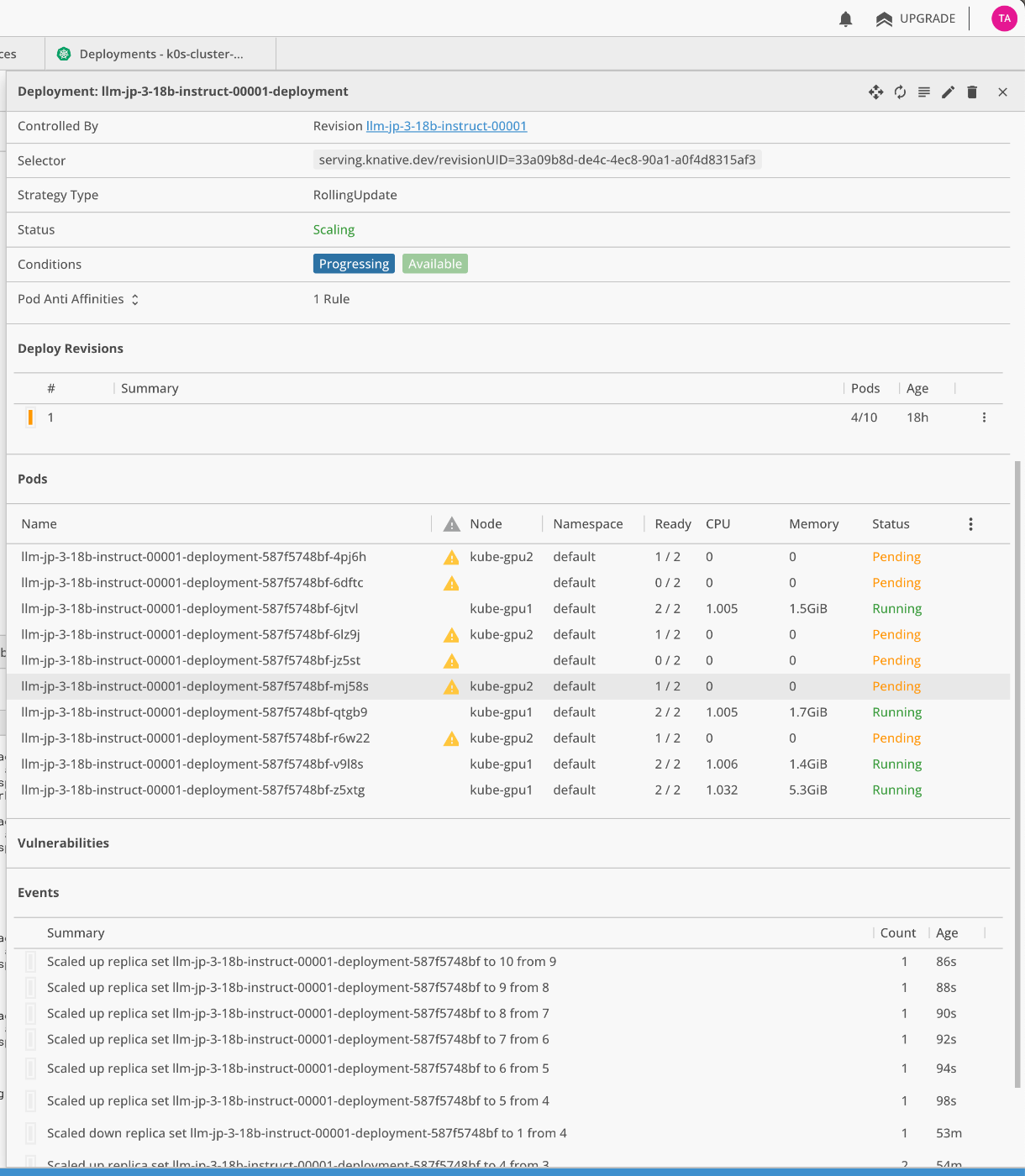
Lensの画面を確認すると、Podが自動で増えていくのが確認できます。
東京大学鈴村研究室について
Discussion