この記事について
こんにちは、東京大学鈴村研究室で、インフラエンジニアとしてお手伝いさせていただいています、福田と申します。
これまで、クラウド基盤mdxの上でKubernetes環境を構築し、サーバレスWebアプリケーションを開発するための手順や、分散学習を行うための手順について説明してきました。
今回のこの記事では、構築済みのKubernetesクラスタに、後から新しくnodeを追加する方法について説明したいと思います。
この方法を学ぶことで、既存のnodeではリソースが不足してきた場合に、後からnodeを追加し、リソースを補填することが可能です。
前提条件
以下の記事の手順に従い、mdx仮想マシン上にKubernetesクラスタが構築されていること
mdx仮想マシンのデプロイ
新しくnodeを追加するため、mdx仮想マシンをデプロイします。
方法については、以下の手順を参考にしてください。
なお、このmdx仮想マシンには、踏み台サーバからアクセスするため、グローバルIPアドレスの割り当ては不要です。
ssh-agentを使ってのログインを可能にするため、踏み台サーバと同じssh公開鍵を設定します。
inventory.iniの修正
ここでは、前の手順でデプロイしたmdx仮想マシンをKubernetesクラスタとして認識させるための情報をinventory.iniに記載していきます。
基本的な手順については、以下で説明してある通りです。
CPUノードの場合、[kube_node]のセクションに、GPUノードの場合、[kube_gpu]のセクションに、IPアドレスの情報と、RoCEのIPアドレスを記載していきます。
inventory.iniのサンプルは以下の通りです。
なお、ここに記載されているipアドレスや、ネットワークインターフェース名は適当ですので、ご自身の環境に合わせて適切なものを使用するようにしてください。
[bastion_host:vars]
ansible_python_interpreter=/home/mdxuser/k8s-configs/.venv/bin/python
[bastion_host]
bastion ansible_host=127.0.0.1
[kube_master]
kube-master ansible_host=192.168.11.3
[kube_node]
kube-node1 ansible_host=192.168.11.5 roce_host=172.17.11.1 # 元からあるnode
kube-node2 ansible_host=192.168.11.6 roce_host=172.17.11.2 # 今回新規追加したnode
[kube_worker:children]
kube_node
[kube_cluster:children]
kube_master
kube_worker
[kube_master:vars]
roce_netif = ens991 # このネットワークインターフェース名は適当です
[kube_gpu:vars]
roce_netif = ens891 # このネットワークインターフェース名は適当です
全nodeの起動
これからansibleコマンドを実行していきますが、ansibleコマンドを使って、Kubernetesクラスターを構築するためには、あらかじめKubernetesに存在する全ての既存のworkerノード、masterノードが起動していることが必要になります。
よって、mdx管理画面上で全ワーカーノードの電源をONにします。
この方法については難しくないと思いますが、念のため手順を記しておきます。
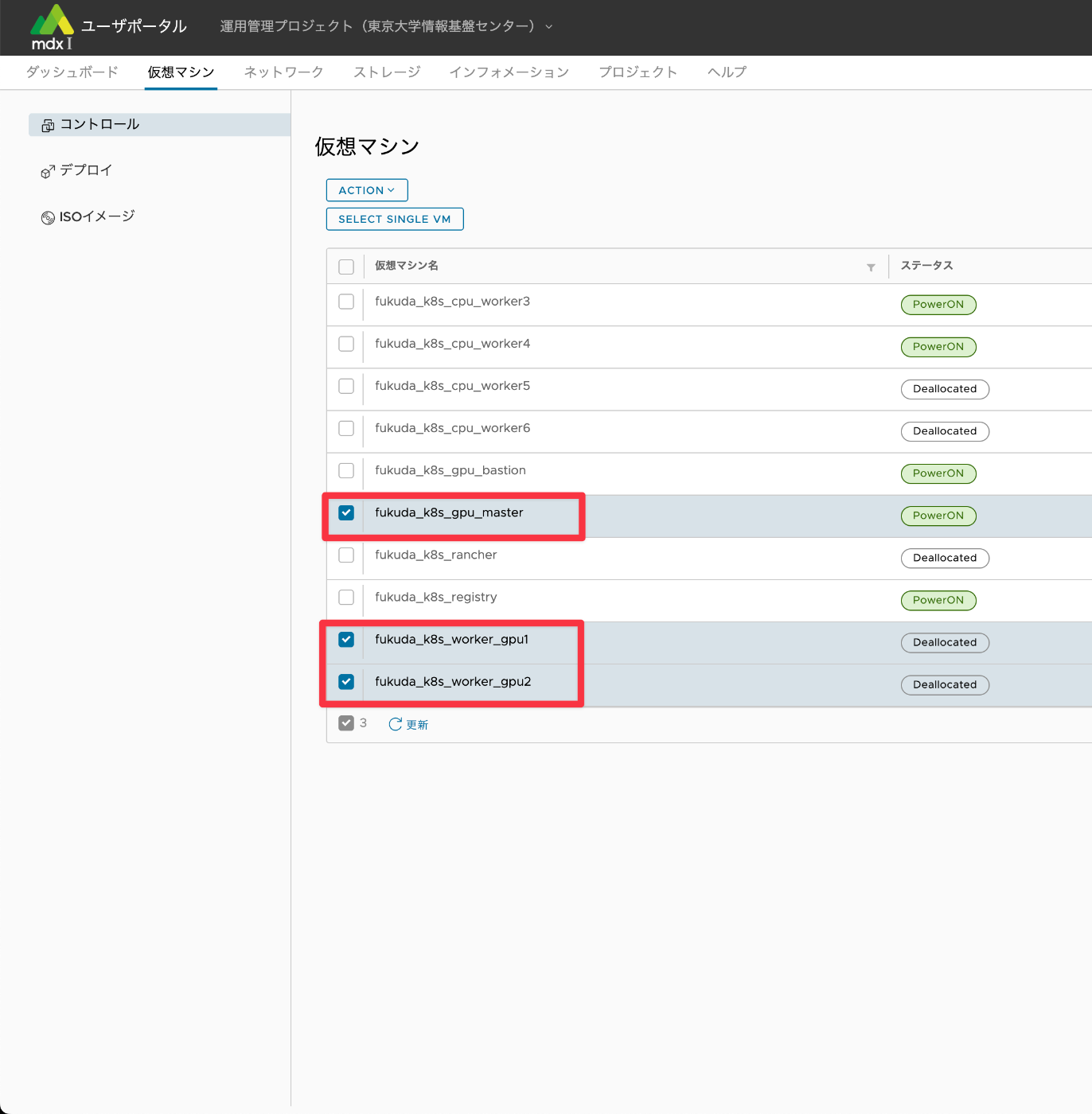
添付の画像の通り、番号順で選択していきます。

Kubernetesクラスタ内の全workerノードのチェックボックスにチェックを入れます。
もちろんmasterノードの起動も必要なので、masterノードが起動していない場合は合わせてチェックを入れます。
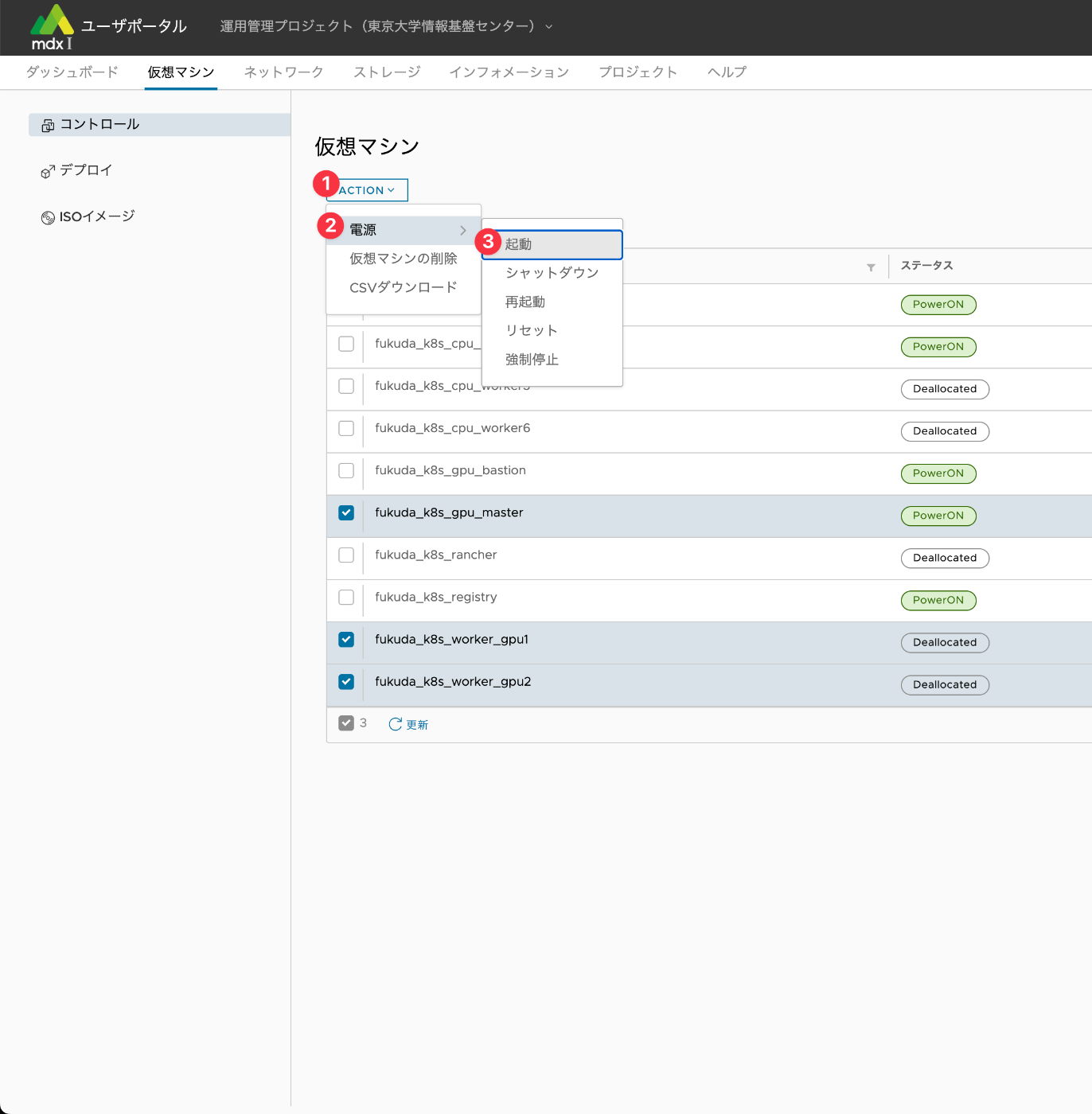
電源をオンにするため、添付の画像の番号の通りに選択していきます。
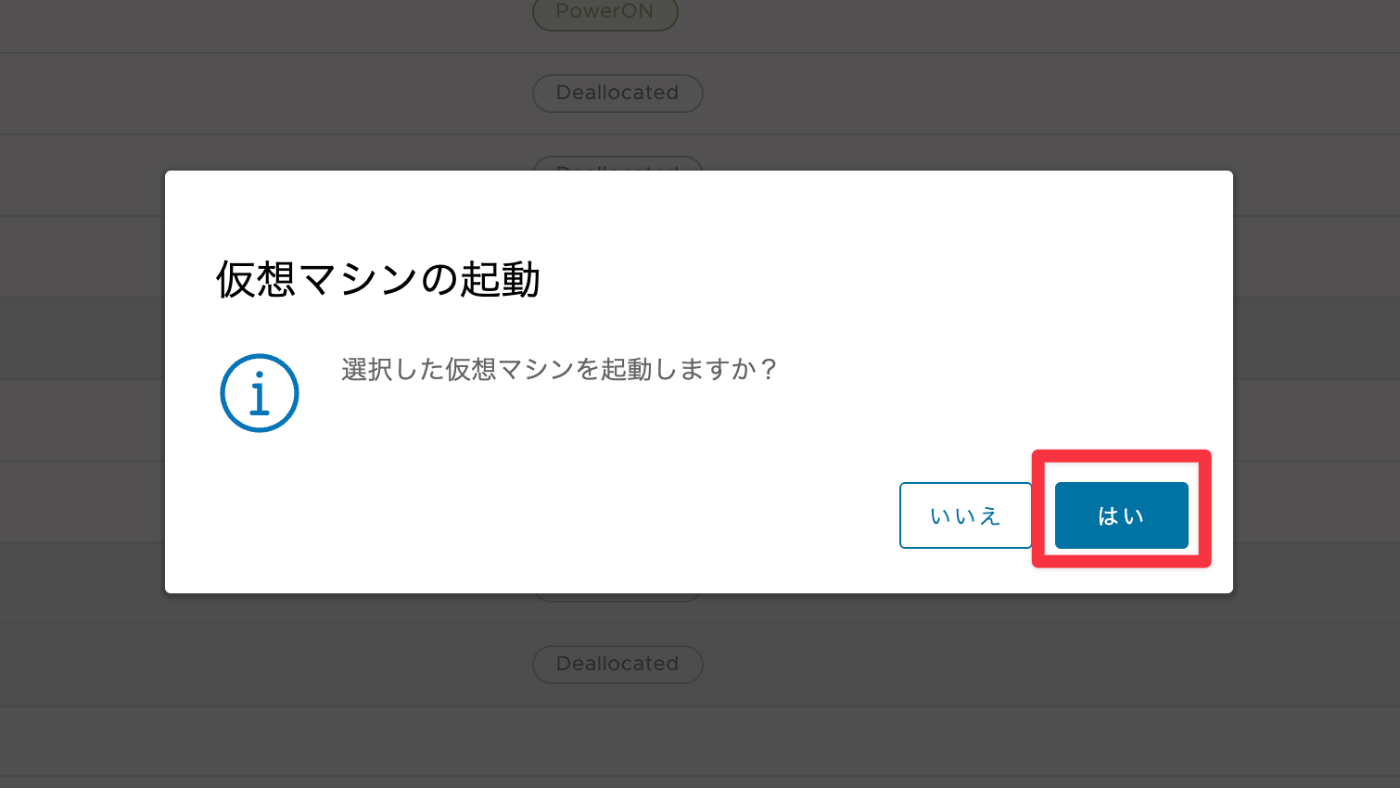
以下のダイアログが表示されるので、はいをクリックします。
全ノードについて電源が起動し、IPアドレスがアサインされるのを待ちます。
IPアドレスがアサインされるまで約5分ほどかかります。
念のため、Lensを起動し、全workerノードがReadyになっていることも確認します。

ansibleコマンドの実行
次に、新規でKubernetesクラスタを構築したときと同様、以下のコマンドを実行して、新しく定義したnodeのKubernetes環境へのデプロイを行います。
uv run ansible-playbook -i inventory.ini site.yaml --tags common --ask-vault-pass
uv run ansible-playbook -i inventory.ini site.yaml --tags k8s_base --ask-vault-pass
uv run ansible-playbook -i inventory.ini site.yaml --tags k8s_worker --ask-vault-pass
GPU workerノードの追加の場合は、合わせて以下のコマンドを実行します。
uv run ansible-playbook -i inventory.ini site.yaml --tags k8s_gpu --ask-vault-pass
ここでパスワードの入力が求められますが、vault.yamlの作成の時に使用した、暗号化実施時のパスワードを入力します。
少し余談ですが、ansibleは冪等性が保証されており、同じコマンドを何度繰り返し行っても、結果が変わらない仕組みが備わっているので、kube-node1が重複して作成されたり、不整合が起きることはありません。
同じコマンドを実行しても、正しく、kube-node2だけが追加されます。
ansibleコマンド実行中にエラーが発生した場合
ssh接続エラー
コマンドを実行しているときに、以下のエラーが出ることがあります。
[SSH] kube-gpu2: retrying aborted
not connected: client connect: can't connect: ssh: handshake failed: host key mismatch: knownhosts: key mismatch
その時には以下のコマンドを入力して、known_hostsの該当エントリーを削除し、 再度ansibleコマンドを実行します。
ssh-keygen -R kube-gpu2
drain failedエラー
k8s_baseコマンドを実行中に、以下のnodeをdrainできないというエラーが出る場合があります。
[ssh] kube-node2:22: drain node: command failed:
その場合は以下のコマンドを実行し、手動で対象ノードを強制的にdrainさせます。
kubectl drain kube-node2 --delete-emptydir-data --ignore-daemonsets --force
なお、drainとは、node上で稼働している Podを安全に退避させ、そのnodeをスケジューリング対象から外す操作のことを表しています。
上記のコマンドを実行してnodeをdrainさせた後、再度ansibleコマンドを実行します。
ansibleコマンドが成功した後は以下のコマンドを実行し、drainしたノードをKubernetesクラスターに再び参加させます。
kubectl uncordon kube-node2
全てのコマンドが正常に通ったら、Lensを開いて、新規で追加したnodeがreadyになっていることを確認します。
東京大学鈴村研究室について
Discussion