この記事について
こんにちは、東京大学鈴村研究室で、インフラエンジニアとしてお手伝いさせていただいています、福田と申します。
今回のこの記事では、vLLMとFastAPIを使ってLLMをWebサービス化し、そのDocker imageをDocker Hubにpushし、そのコンテナイメージを使用して、Knative上にWebアプリケーションとしてデプロイして公開することを行います。
この手順によって、Hugging Faceにある好きなLLMを、Webサービスとしてデプロイして、公開することができるようになります。
それ以外のコンテンツについては、以下の記事一覧を参照ください。
前提
この記事では、Kubernetesクラスタに、Knativeがインストールされていることを前提とするため、クラウド基盤mdxの仮想マシンの構築方法や、Kubernetesクラスタ自体の構築方法、Knativeの構築方法などについては説明しません。
これらの方法について知りたい場合は、上述の記事一覧を参照ください。
アーキテクチャ全体像
今回構築する、LLM Webサービスのアーキテクチャ全体像は以下の通りです。
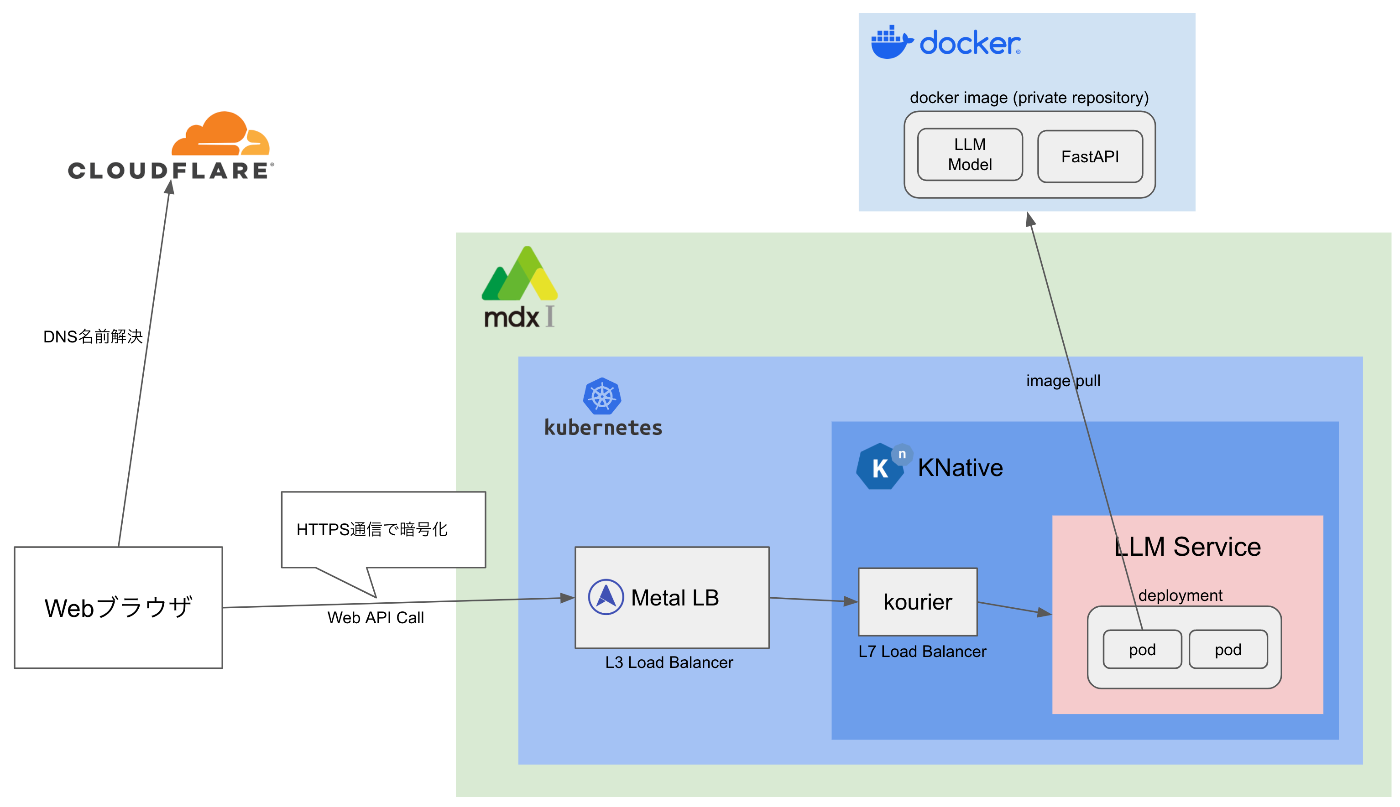
まずは、vLLMとFastAPIを使用して、Webアプリケーションを構築し、Docker Imageを作成します。
次に、このDocker ImageをDocker Hubのprivate repositoryにpushします。
その後、このDocker Imageを使用して、KnativeにサーバレスWebアプリケーションとしてデプロイ & 公開します。
事前設定
KNativeのScale to zeroの無効化設定
KNativeのデフォルト設定では。アクセスがない場合に、自動的にPodを削除し、全くアクセスが無いと、Pod数がゼロになるまで削減します。
ただ、LLMのサービスはロードに長い時間が掛かるので、この設定が入っていると、動作が不安定になりやすくなります。
これを避けるために、ConfigMapである、config-autoscalerに対して、enable-scale-to-zeroをfalseに設定し、全くアクセスがない場合でも最低1つのPodは立ち上がっておくようにします。
以下のコマンドを実行し、configmapの編集モードに入ります。
kubectl edit configmap config-autoscaler -n knative-serving
dataの配下に、enable-scale-to-zero: "false" を追記し、編集を完了します。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
enable-scale-to-zero: "false" # この設定を追加
GPUマシンの作成とログイン
vLLMを使うためにはGPUマシンが必要になるので、まずは、mdxなどで、GPUの搭載された仮想マシンを立ち上げます。
仮想マシンの立ち上げ方法はこちらの手順書を参照してください。
なお、立ち上げた仮想マシンにはグローバルIPアドレスは割り当てる必要はなく、踏み台サーバと同じssh公開鍵を設定し、踏み台サーバにssh-agentでアクセスすれば、認証情報を入れることなく、sshログインできるようになるので、その方法がお勧めです。
次に踏み台サーバにssh-agentを有効にしてログインします。
eval `ssh-agent`
ssh-add ~/.ssh/mdx_access_key
ssh -A mdxuser@(踏み台サーバのIPアドレス)
この踏み台サーバから、起動したGPUサーバにsshログインします。
ここからしばらくは、このGPUサーバでの作業が続きます。
Dockerのインストール
以下の手順に従って、Dockerをインストールします。
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
# install docker and docker compose
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudoなしでDockerが実行出来るように、以下のコマンドを実行します。
sudo groupadd docker
sudo gpasswd -a $USER docker
新しいgroupが有効になるように、一度sshログアウトし、再度ログインします。
以下のコマンドがsudoなしで正常に動くか確認します。
docker run hello-world
今回、Docker Hubのprivate repositoryにpushすることを想定しているので、下記のコマンドでdockerにログインしておきます。
docker login
実行すると、以下のようにユーザー名とパスワードの入力を求められます。
Username: <Docker Hub のユーザー名>
Password: <パスワード>
認証に成功すると、以下のメッセージが表示されます。
Login Succeeded
nvidia-container-toolkitのインストール
続いて、Dockerで、GPUが使えるように、nvidia-container-toolkitのインストールを行います。
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo systemctl restart docker
uvのインストール
GPUサーバ上で、Pythonのパッケージマネージャーとして、uvをインストールします。
curl -LsSf https://astral.sh/uv/install.sh | sh
vLLM + FastAPIでのWebアプリケーション作成
PythonでのWebアプリケーションの作成
さて、必要なライブラリのインストールが終わったので、次に、今回のアプリケーションを作成するファイル群を格納する適当なディレクトリを作成し、そのディレクトリに移動します。
mkdir fastapi_llm
cd fastapi_llm
uv環境を初期化します。
uv init
uv環境にvllmをインストールします。
uv pip install vllm
Webアプリケーションフレームワークである、FastAPI、uvicornをインストールします。
uv add fastapi uvicorn
次に、FastAPIのPythonのコードを書いていきます。
ファイル名をmain.pyなどとして、以下のコードを作成します。
from fastapi import FastAPI, HTTPException, Security
from fastapi.security import HTTPBearer, HTTPAuthorizationCredentials
from pydantic import BaseModel, Field
from vllm import LLM, SamplingParams
from huggingface_hub import login
import os
# # Hugging Faceのアクセストークン。
# Hugging Faceで利用規約への同意が必要なモデルの場合、
# 同意した後、アクセストークンを指定する
if os.getenv("HF_TOKEN"):
login(token=os.getenv("HF_TOKEN"))
app = FastAPI()
model_name = os.environ["MODEL_NAME"] # 使用するモデル名を環境変数で指定
# tensor_parallel_sizeはGPU数に応じて変更する
llm = LLM(model=model_name, tensor_parallel_size=1)
# postリクエストのスキーマ定義
class TextRequest(BaseModel):
prompt: str # 入力プロンプト
temperature: float = Field(default=0.1, ge=0, le=1) # 出力のランダム性を制御するパラメータ。 値が低いほど画一的な回答が返ってくる
max_tokens: int = Field(default=4000, ge=1) # 最大トークン数
@app.post("/llm")
async def summarize_text(request: TextRequest, credentials: HTTPAuthorizationCredentials = Security(HTTPBearer())):
# 外部から不用意にAPIを叩かれるのを避けるため、トークンでの認証を行う
auth_token = os.environ["AUTH_TOKEN"]
if credentials.credentials != auth_token:
raise HTTPException(status_code=404, detail="Not Found")
# ここからがLLM呼び出しの本体部分
sampling_params = SamplingParams(temperature=request.temperature, max_tokens=request.max_tokens, top_p=0.9)
output = llm.generate([request.prompt], sampling_params)
result = output[0].outputs[0].text.strip()
return {"result": result}
Docker image作成のための準備
次に、Docker image作成のための設定を行って行きます。
まず、pip installを行うための、requirements.txtを生成します。
uv pip freeze > requirements.txt
次にDockerfileを作成します。ファイル名はDockerfileとしてください。
作成場所は、main.pyと同じ場所でOKです
FROM python:3.11-slim
WORKDIR /app
# 依存関係をコピーしてインストール
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# アプリのコードをコピー
COPY . .
# FastAPI の実行コマンド (Uvicornを使用)
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
ここで、ここまで作成したPythonのコードや、Dockerfileが正しく動作することを確認するために、docker composeを使って確認をしていきます。
そのため、まずは以下のcompose.yamlファイルを作成します。
作成場所は、main.pyやDockerfileと同じディレクトリ内でOKです。
services:
app:
build: .
ports:
- "8000:8000"
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [ gpu ]
environment:
AUTH_TOKEN: password
NVIDIA_VISIBLE_DEVICES: all
NVIDIA_DRIVER_CAPABILITIES: compute,utility
MODEL_NAME: "llm-jp/llm-jp-3-7.2b-instruct3"
なお、MODEL_NAMEについて、今回は、以下のllm-jpのllm-jp-3-7.2b-instruct3というモデルを使用することにします。
モデル名の指定の仕方ですが、まず、Hugging Faceのサイトに行きます。
ここで使いたいモデルを選び、そのモデル名の隣にある、コピーアイコンをクリックして、値をクリップボードにコピーします。
ここでコピーされた値を、MODEL_NAMEとして指定します。
AUTH_TOKENについては、Kubernetesにデプロイする時は、インターネットからアクセスできるようになるため、推測されにくいものにする必要がありますが、今回はローカルのテスト用なので、適当な値を設定します。
compose.yamlを作成したら、以下のコマンドで、docker composeでWebアプリケーションを起動します。
docker compose up
モデルのダウンロードなどに時間を要しますが、しばらく経つと以下のメッセージが表示されます。
...
app-1 | INFO 03-07 10:57:59 model_runner.py:1562] Graph capturing finished in 10 secs, took 0.85 GiB
app-1 | INFO 03-07 10:57:59 llm_engine.py:431] init engine (profile, create kv cache, warmup model) took 12.68 seconds
app-1 | INFO: Started server process [1]
app-1 | INFO: Waiting for application startup.
app-1 | INFO: Application startup complete.
app-1 | INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Uvicorn running on http://0.0.0.0:8000 というメッセージが表示されたら、Webアプリケーションが正常に起動していますので、CTRL+Cを押下して停止します。
Docker Hubへのimageのpush
次に、作成したDockerfileに基づいて、Docker Imageをbuildし、Docker Hubにpushしていきます。
本手順では、Docker Hubのprivate repositoryにpushすることを想定しているので、Docker Hubにログインし、自分自身のレポジトリ一覧から、Create a repositoryボタンを押します。

レポジトリに任意の名前を設定し、Visimilityをprivateにして、Createボタンを押します。

これで、Docker Hubにpushするためのrepositoryが作成できました。
次に以下のコマンドでDocker imageのbuildと、このrepositoryへのpushを行います。
docker build . -t (作成したレポジトリ名):latest
docker tag fast_api_llm:latest (Docker Hubのアカウント名)/(作成したレポジトリ名):latest
docker push (Docker Hubのアカウント名)/(作成したレポジトリ名):latest
これでKubernetesにデプロイするDocker Imageの作成と、repositoryへのpushが完了しました。
KubernetesへのDocker Hubの認証情報の登録
これまでの手順で作成した、Docker Imageはprivate repositoryにpushしました。
このDocker ImageをKubernetesでpullできるようにするためには、KubernetesにDocker Hubの認証情報の登録が必要です。
このセクションでは、以下の手順に基づいて、KubernetesにDocker Hubの認証情報の登録を行って行きます。
まずは、GPUサーバからログアウトし、踏み台サーバにログインします。
eval `ssh-agent`
ssh-add ~/.ssh/mdx_access_key
ssh -A mdxuser@(踏み台サーバのIPアドレス)
踏み台サーバで、docker loginします。
もし踏み台サーバにDockerがインストールされていない場合は、GPUサーバと同様の手順でインストールを行います。
以下のコマンドを実行すると、ユーザー名とパスワードの入力が求められるので、入力します。
docker login
Dockerはloginに成功すると、認証情報を~/.docker/config.jsonに保存します。
この内容を確認するため、cat ~/.docker/config.jsonを実行します。
cat ~/.docker/config.json
出力には以下のような内容が含まれています。
{
"auths": {
"https://index.docker.io/v1/": {
"auth": "c3R...zE2"
}
}
}
このDockerの認証情報をKubernetesのSecretとして登録していきます。
そのためのコマンドは以下の通りです。
このコマンドの、regcredはSecretのキー名ですが、好きな名前でOKです。
kubectl create secret generic regcred \
--from-file=.dockerconfigjson="${HOME}/.docker/config.json" \
--type=kubernetes.io/dockerconfigjson
作成したSecretは以下のコマンドで確認できます。
kubectl get secret regcred --output=yaml
出力結果は以下のようになります。
apiVersion: v1
kind: Secret
metadata:
...
name: regcred
...
data:
.dockerconfigjson: eyJodHRwczovL2luZGV4L ... J0QUl6RTIifX0=
type: kubernetes.io/dockerconfigjson
KnativeへのWebアプリケーションのデプロイ
これまでの手順で、以下の事を実施しました。
- LLM WebアプリケーションのDocker Imageの作成
- 作成したDocker ImageのDocker Hub (private repository) へのpush
- Docker Hub認証情報のKubernetesへの登録
このセクションでは、このDocker ImageをKubernetes環境のKnativeにデプロイし、サーバレスWebアプリケーションの構築を行います。
まず、デプロイのためのyamlファイルの作成を行います。
AUTH_TOKENは、クライアントからアクセスする際の認証のPassphraseの役割を果たしますが、Knativeにデプロイするとインターネットからアクセスできるようになるため、第三者からは推測されにくい、ランダムな文字列を設定することを推奨します。
imagePullSecrets.nameには、先の手順で登録した、Docker Hubの認証情報のキー名を設定します。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: fastapi-llm-app # 任意の名前を設定
namespace: default
spec:
template:
spec:
containers:
- image: (Docker Hubのアカウント名)/(作成したレポジトリ名):latest
resources:
limits:
nvidia.com/gpu: 1
env:
- name: NVIDIA_VISIBLE_DEVICES
value: all
- name: NVIDIA_DRIVER_CAPABILITIES
value: compute,utility
- name: AUTH_TOKEN
value: 6Ryyj0RxIskQpLFw # 推測されにくいランダムな文字列を認証トークンとして設定
- name: MODEL_NAME
value: "llm-jp/llm-jp-3-150m-instruct3" # Hugging Faceのモデル名を設定する
ports:
- containerPort: 8000
imagePullSecrets:
- name: regcred # 先の手順で登録した、Docker Hubの認証情報のキー名
yamlファイルを保存し、いつものkubectl applyの手順でデプロイを行います。
kubectl apply -f (作成したyamlファイルのpath)
Lensで対象のDeploymentを選択し、logのアイコンをクリックすると、起動ログを確認できます。

WenアプリケーションのURLを確認するため、以下のコマンドを実行します。
kubectl get ksvc
すると、以下のような結果を得られます。
NAME URL LATESTCREATED LATESTREADY READY REASON
fastapi-llm-app https://fastapi-llm-app.default.example.com fastapi-llm-app-00001 fastapi-llm-app-00001 True
デプロイしたWebサービスへのアクセス
必要なライブラリのインストール
さて遂に、デプロイしたWebサービスに対して、PCからPythonスクリプトでアクセスしてみます。
そのための環境準備を行います。
まず適当なディレクトリを作成します。
mkdir fastapi_web_client
cd fastapi_web_client
uv initを行います。
uv init
Webクライアントの実装のため、requestsパッケージをインストールします。
uv add requests
Webクライアントの実装
次に、PythonでWebクライアントの実装を行って行きます。
ファイル名は、main.py等とします。
if __name__ == '__main__':
import requests
# 認証トークン。 KnativeにデプロイしたyamlのAUTH_TOKENと一致させる
auth_token = '6Ryyj0RxIskQpLFw'
# デプロイされたWebアプリケーションのURLを設定する
base_url = 'https://fastapi-llm-app.default.example.com'
headers = {
"Authorization": f"Bearer {auth_token}",
"Content-Type": "application/json"
}
response = requests.post(f"{base_url}/llm",
headers=headers,
json={'prompt': 'フーリエ変換について教えてください',
'temperature': 0.01,
'max_tokens': 4000
})
print(response.json()["result"])
以下のコマンドで実行します。
uv run main.py
以下のような結果が得られます。
フーリエ変換はコンピュータのハードウェアやソフトウェアの動作を高速化し、データの品質を向上させる技術です。特に、データの高速な取得と処理に使用されます。
### フーリエ変換の基本的な手順
1. **データの取得**: フーリエ変換は、データを周波数成分(周波数)に変換する技術です。
2. **変換**: フーリエ変換を使用して、データを周波数成分に変換します。
3. **変換結果の表示**: 変換結果を表示します。
4. **データの品質向上**: 変換結果を表示し、データの品質を向上させます。
今回のまとめ
今回は、vLLMとFastAPIを使ってLLMをWebサービス化し、そのDocker imageをDocker Hubにpushし、そのコンテナイメージを使用して、Knative上にWebアプリケーションとしてデプロイして公開することを行いました。
東京大学鈴村研究室について
Discussion