【解説】Azure Synapse Link for Azure Cosmos DB
本記事では、Azure Synapse Link for Azure Cosmos DBに関するMicrosoft公式ドキュメント(https://learn.microsoft.com/ja-jp/azure/cosmos-db/synapse-link/)
をかみ砕いて詳しく説明します。
はじめに:Azure Synapse Analytics とは?
本題に入る前に、まずは用語説明として "Azure Synapse Analytics" について説明します。
Azure Synapse Analytics は、データウェアハウス機能 + データ分析機能 を統合した
クラウドネイティブなデータ分析プラットフォームです。
データの
収集 → 蓄積 → 抽出・加工 → 分析 → 可視化
といった一連の流れを 1つのサービス内で完結 できます。
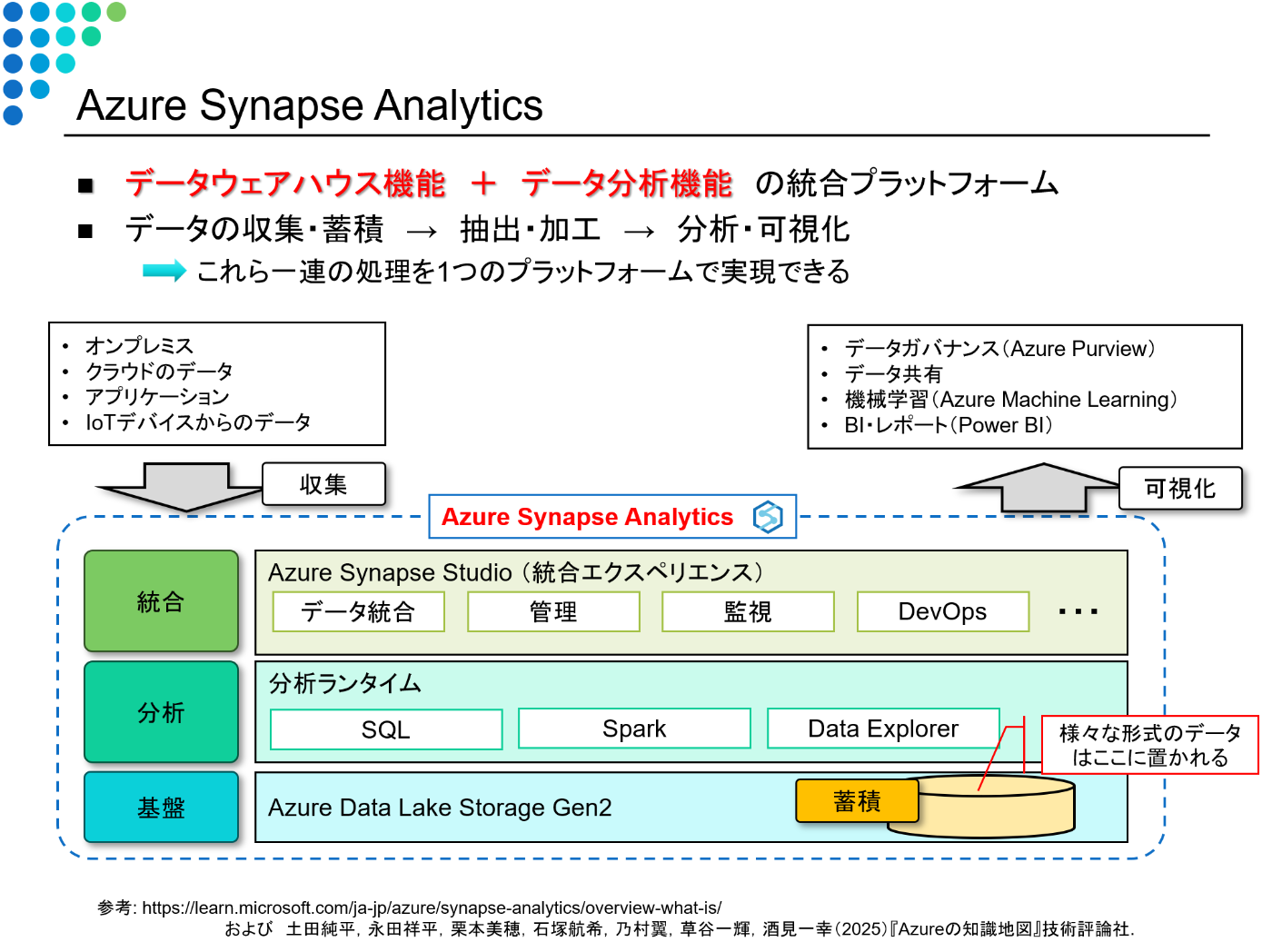
図:Azure Synapse Analytics の構成イメージ
この図のように、Synapse Analytics は大きく3つのレイヤーで構成されています。
| レイヤー | 役割 | 主な構成要素 |
|---|---|---|
| 基盤層(Storage Layer) | データを蓄積するレイヤー | Azure Data Lake Storage Gen2 |
| 分析ランタイム層(Compute Layer) | 大規模データを処理・分析するレイヤー | SQL / Spark / Data Explorer |
| 統合レイヤー(Integration Layer) | データ統合・監視・DevOps・ガバナンスを行うレイヤー | Synapse Studio, Pipelines, Monitor, Purview |
さらに上位には Power BI や Azure Machine Learning などのサービスと連携し、
可視化・機械学習・データ共有などをシームレスに実現します。
🚩Synapse が目指す姿
従来は、
- DWH(分析用)とETLツール、
- データレイク、
- 可視化ツール、
などを別々に構築・運用する必要がありました。
Synapse はこれらを「統合エクスペリエンス(Synapse Studio)」でまとめ、
“収集から分析までワンストップ” を実現しています。
1.Azure Synapse Link for Azure Cosmos DB とは
Azure Synapse Link for Azure Cosmos DB は、
Cosmos DB の運用データを追加のETL処理なしで分析できるようにする機能です。
いわゆる HTAP(Hybrid Transactional / Analytical Processing) を実現します。

図:Cosmos DB の運用データをリアルタイム分析に活用
上図のように、
- アプリケーションが日々扱う「オペレーショナルデータ」が Cosmos DB に保存され、
- その変更が 自動同期(auto-sync) により「分析ストア」に反映され、
- Synapse Analytics から SQL や Spark でリアルタイム分析 が可能になります。
これにより、運用DBと分析基盤をつなぐETLレスなデータ分析 が実現します。
2.なぜ必要なのか
従来は次のような手間がありました:
- Cosmos DB(運用DB)からデータを抽出(E)
- データを整形・変換(T)
- データウェアハウスやSynapseにロード(L)
- そこからPower BIなどで可視化
これらを毎回バッチで動かす必要があり、リアルタイム性が損なわれる のが課題でした。
👉 Synapse Linkを使えば、自動・即時に同期された分析用ストアを通じて、最新データを直接分析できます。
3.仕組みの概要
2種類のストア
| 種類 | 目的 | 特徴 |
|---|---|---|
| Transactional Store | 通常の読み書き処理(アプリ用) | JSON形式、低遅延、スループット重視 |
| Analytical Store | 分析クエリ向け | 列志向、ETL不要、クエリ最適化済み |
トランザクショナルストアの更新は、自動的に分析ストアへ同期されます。
この同期はほぼリアルタイム(数秒〜数十秒程度の遅延)で行われます。
4.どうやって分析するの?
Synapse Linkを有効化すると、Synapse Analytics 側から分析ストアを読み取れるようになります。
主なアクセス方法
| 分析手段 | 利用技術 | 用途 |
|---|---|---|
| Serverless SQL Pool | T-SQL | Power BIなどで直接クエリ |
| Apache Spark Pool | PySpark / Scala / SQL | 機械学習・ETL・データ探索 |
どちらを使っても、Cosmos DBの運用負荷に影響せず、安全に分析できます。
5.導入手順(概要)
-
Cosmos DB アカウントで Synapse Link を有効化
- Azure Portal または CLI から設定
- 一度有効化すると無効化は制限あり(要注意)
-
分析ストアを有効化したコンテナを作成
- 新規または既存コンテナで「Analytical store」を ON に設定
-
analytical TTL(保持期間)を設定可能
-
Synapse ワークスペースと接続
- Synapse Studio → 「Data」→「Connect external data」→ Cosmos DB を選択
-
クエリ実行
- Serverless SQL →
SELECT * FROM cosmosdb.container - Spark →
spark.read.format("cosmos.olap").load()
- Serverless SQL →
6.利用シナリオ例
| シナリオ | 内容 |
|---|---|
| リアルタイムBI | 最新のアプリ利用データを Power BI で可視化 |
| 異常検知 | IoTデータを Cosmos DB に格納し、Sparkでリアルタイム分析 |
| 顧客分析 | トランザクションデータを即時に集計・スコアリング |
| データサイエンス | Sparkで特徴量抽出し、そのままMLモデル学習に利用 |
7.注意点・制限事項
- 対応API:NoSQL (Core) / MongoDB API
- Cassandra / Table / Gremlin は一部非対応またはプレビュー
- Dedicated SQL Pool では直接クエリ不可(Serverless/Sparkのみ)
- 分析ストアは読み取り専用(書き込みはTransactional Storeのみ)
- バックアップ対象外(削除すると再同期が必要)
- 初期同期には時間がかかる場合あり(データ量依存)
- 課金は独立(分析ストア容量・読み込み量に応じて課金)
8.コストとチューニングのポイント
-
課金ポイント
- 分析ストアのストレージ使用量
- Synapse でのクエリスキャン量(Serverless SQL の場合)
-
パフォーマンス最適化
- パーティションキーを適切に設計
- 小さすぎるファイルを避ける
- クエリ時は必要列・パーティションに絞る
9.セキュリティ・ネットワーク
- Private Endpoint に対応
- Azure AD / RBAC / Managed Identity でアクセス制御
- データ暗号化:Cosmos DB 側のエンクリプションが適用
- VNet 統合で閉域運用可能
10.まとめ
| ポイント | 内容 |
|---|---|
| 目的 | 運用データをリアルタイム分析に活用 |
| 特徴 | ETL不要・低遅延・分離クエリ |
| 活用領域 | BI, IoT, AI, データサイエンス |
| 対応API | NoSQL / MongoDB |
| 分析側 | Synapse (Serverless SQL / Spark) |
✅ データ移動レスのリアルタイム分析基盤を実現するキーサービス
🔗 参考リンク
- Azure Synapse Link for Azure Cosmos DB とは
- Synapse Link の設定ガイド
- Azure Synapse Analytics の概要
- Azure Cosmos DB の価格
もしこの記事が参考になったら、💙リアクション or コメント いただけると嬉しいです!
Discussion