DBのデータをCDNにキャッシュしつつEdgeから使いやすく PrismaAccelerate を試してみる
PrismaAccelerate はサーバーレスやEdgeランタイムなどからDBを触りたい時に便利なプラットフォームです
現在はEarlyAccessとなっていますが、応募してみたら当たってしまったのでいち早く試してみようと思います
2023/10/11 追記
現在はEarlyAccessが外れ、誰でも使用可能となっています
また、公式からわかりやすいドキュメントが出ているため、こちらを先に見るとイメージをつかみやすいかもしれません
現状のEdgeの課題
CloudflareWorkersしかやったことないのでその話をしますが、Workersを触っていると一番最初に当たる壁としてNode.jsと同じノリでDBに接続できないという課題があります
公式ドキュメントを見ても、通常のMySQLやPostgreSQLのクライアントを使う場合はCloudflareTunnelを使えと書いてありますし、他にもPrismaなどのページを参照してみてもPrismaDataplatformを使うような指示がしてあります
これはEdgeFunctionという環境+無限に世界中からスケールする特殊な条件が要因で、特に後者は世界中からのリクエスト1つに対して必ずDBコネクションが1つ張られてしまう(よね?)ということもあり、とてもじゃないですがDBのコネクション数が足りません
現状でも解決方法は各ツールで様々あって、例えばPrismaDataplatformはDBコネクション自体をプロキシしてリクエスト1=DBコネクション1とならないようにしています
もう1つはPlanetscaleのようなアプローチで、自社のDBに対してのクエリをHTTPにしコネクションを気にせずEdgeから叩きやすいようにしています
Prismaが使いたい……!
やはりTypeScriptを使っている以上はPrismaを使って開発したい気持ちは皆さんかなり大きいと思います
では先程話したPrismaDataplatformを使えばいいんじゃないか?という話になりますが、これがまたデータセンターがそもそも日本から遠すぎるという問題があり、実用に耐えられるような応答速度が出ません
コネクションプールをプロキシして管理しようとしてもデータセンターの物理的な距離の差が出てしまいます
それを解決しようというのがPrismaAccelerateです
PrismaAccelerateの概要
PrismaAccelerateではプロキシ先に設定したDBのデータをCDNに撒いて、そこから優先して配信するという機能が付いています
通常のDBのように問い合わせるとCDNのキャッシュが優先して返却されるためそもそもDBにリクエストが到達しないというアプローチですね
一応コネクションプーリングの管理もしてるみたいな記述が公式HPには書いてありますが、この辺りは詳しくはわかりませんでした
やってみよう
では実際の使い心地はどうなのか、サンプルコードも交えて紹介します
今回は以前作ったPlanescaleのDBを繋いでCloudflareWorkers(Wrangler)からデータを問い合わせてみたいと思います
PrismaAccelerateにDBを登録する

PrismaAccelerateの画面に飛ぶと早速新規作成画面が出たのでここから登録していきます
EarlyAccessということもあってか非常にシンプルです
プロジェクトの名前とConnectionStringを入れて確定します
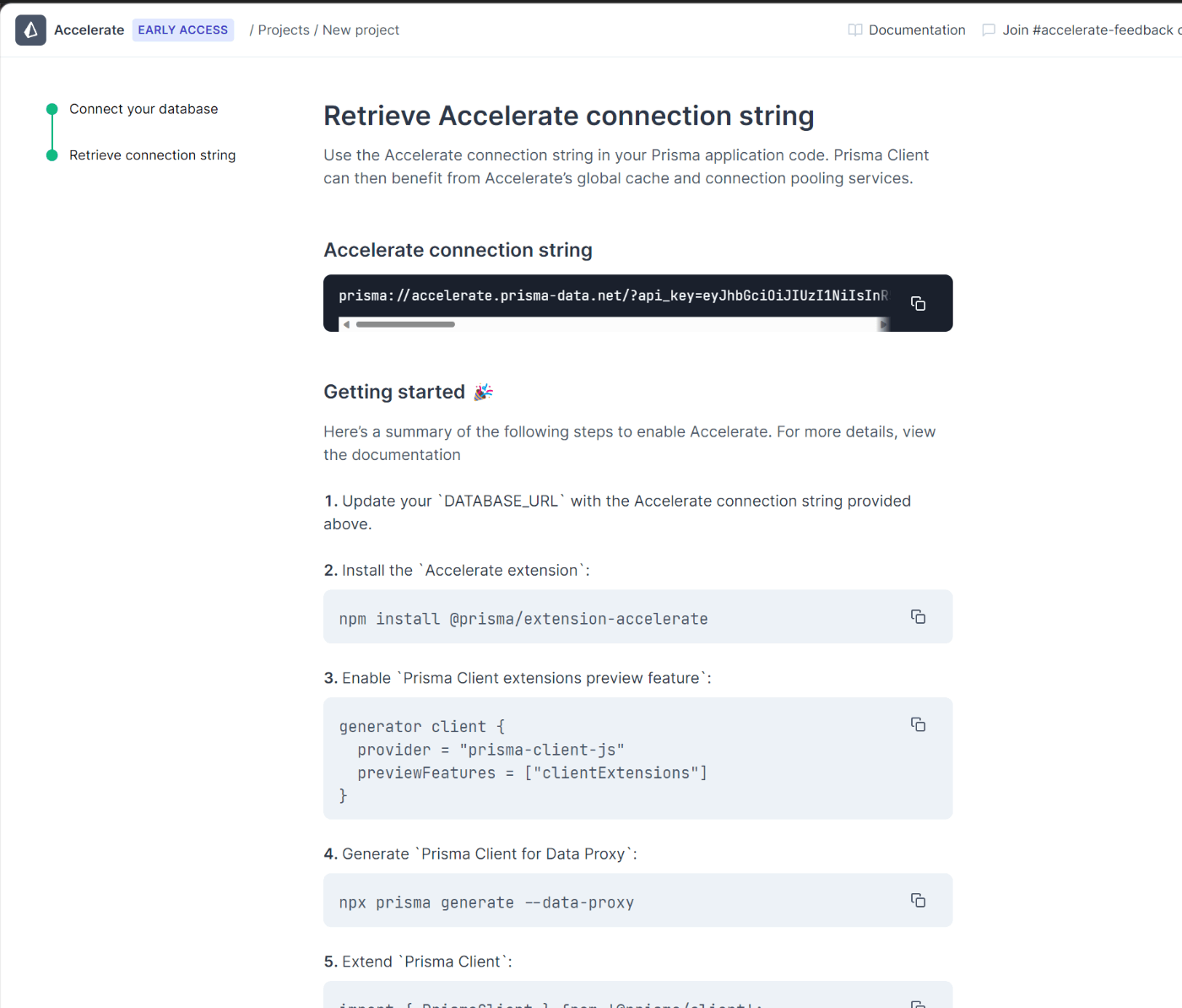
作成が完了するとこんな感じの画面が出ます このアクセス文字列がこの画面でしか出ないっぽいので絶対にメモしておきます
DBの登録はこれだけで完了です
Wranglerのセットアップ
~/Desktop
❯ wrangler init prisma-accelerate
⛅️ wrangler 2.12.2
--------------------
Using npm as package manager.
✨ Created prisma-accelerate/wrangler.toml
✔ Would you like to use git to manage this Worker? … no
✔ No package.json found. Would you like to create one? … yes
✨ Created prisma-accelerate/package.json
✔ Would you like to use TypeScript? … yes
✨ Created prisma-accelerate/tsconfig.json
✔ Would you like to create a Worker at prisma-accelerate/src/index.ts? › Fetch handler
✨ Created prisma-accelerate/src/index.ts
✔ Would you like us to write your first test with Vitest? … no
~/Desktop/prisma-accelerate
❯ rm -rf package-lock.json
~/Desktop/prisma-accelerate
❯ yarn set version stable
~/Desktop/prisma-accelerate
❯ echo "nodeLinker: node-modules" >> .yarnrc.yml
~/Desktop/prisma-accelerate
❯ yarn
~/Desktop/prisma-accelerate
❯ yarn wrangler dev
⛅️ wrangler 2.12.2 (update available 2.13.0)
-------------------------------------------------------
⬣ Listening at http://0.0.0.0:8787
- http://127.0.0.1:8787
- http://172.22.224.157:8787
Total Upload: 0.19 KiB / gzip: 0.16 KiB
別のターミナルを開いてcurlを叩いてみます
~
❯ curl http://localhost:8787
Hello World!
Wranglerのセットアップは以上です
Prismaのセットアップ
Prismaのインストールやスキーマの準備などをしていきます
~/Desktop/prisma-accelerate
❯ yarn add prisma
~/Desktop/prisma-accelerate 35s
❯ yarn prisma init
✔ Your Prisma schema was created at prisma/schema.prisma
You can now open it in your favorite editor.
Next steps:
1. Set the DATABASE_URL in the .env file to point to your existing database. If your database has no tables yet, read https://pris.ly/d/getting-started
2. Set the provider of the datasource block in schema.prisma to match your database: postgresql, mysql, sqlite, sqlserver, mongodb or cockroachdb.
3. Run yarn prisma db pull to turn your database schema into a Prisma schema.
4. Run yarn prisma generate to generate the Prisma Client. You can then start querying your database.
More information in our documentation:
https://pris.ly/d/getting-started
これで基本的なPrismaのファイルができるので、先程PrismaAccelerateの画面から取得した接続情報に .env を変えておきます
DATABASE_URL="prisma://accelerate.prisma-data.net/?api_key=***"
schema.prisma を編集します 今回は以前から使っているDBに接続するのでそのスキーマにしました
DiscordのリマインダーBotのデータを保存しています
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model Reminder {
id Int @id @default(autoincrement())
created_at DateTime @default(now())
updated_at DateTime @default(now()) @updatedAt
message String
member_id String
channel_id String
guild_id String
remind_date DateTime
}
新規にDBを作った人はここでマイグレーションしておいてください
$ prisma migrate dev --name init
次に、Accelerateを使うためのパッケージを入れておきます
~/Desktop/prisma-accelerate
❯ yarn add @prisma/extension-accelerate
schema.prisma も編集します
generator client {
provider = "prisma-client-js"
+ previewFeatures = ["clientExtensions"]
}
@prisma/client のコードを生成します この時にDataplatform用のオプションを一緒に入れます
~/Desktop/prisma-accelerate 15s
❯ yarn prisma generate --data-proxy
これでPrsimaのセットアップは完了です
データを取得し返却するAPIを書く
ここからコードを書いていきます
Wranglerは src/index.ts でエクスポートされた fetch 関数を実行するので、そこに簡単なデータ取得処理を書きます
その前にWranglerでは環境変数を .env ではなく .dev.vars から取得するので、こちらにも DATABASE_URL を追加します
DATABASE_URL="prisma://accelerate.prisma-data.net/?api_key=***"
コードの全文は以下です
// Edgeランタイムで使う時は、 `/edge` を入れる
import { PrismaClient } from "@prisma/client/edge";
// Accelerateのクライアント拡張
import useAccelerate from "@prisma/extension-accelerate";
export interface Env {
DATABASE_URL: string;
}
export default {
async fetch(req: Request, env: Env): Promise<Response> {
try {
// datasourcesで指定しないと process.env.DATABASE_HOSTを見に行ってしまうため手動でConnectionStringを入れる
const prisma = new PrismaClient({
datasources: {
db: {
url: env.DATABASE_URL,
},
},
}).$extends(useAccelerate); // クライアント拡張の適用
// 普通にリクエストする
const data = await prisma.reminder.findMany();
return new Response(JSON.stringify(data), {
headers: {
"Content-Type": "application/json",
},
});
} catch (e) {
console.error(e);
return new Response("error", { status: 500 });
}
},
};
curlしてみます
~
❯ curl http://localhost:8787
[{"id":13,"created_at":"2023-03-23T13:54:01.491Z","updated_at":"2023-03-23T13:54:01.491Z","message":"美容室","member_id":"184308967399227392","channel_id":"1082192048809058377","guild_id":"1073199055825543178","remind_date":"2023-03-25T02:00:00.000Z"}]
無事にDBの内容を取得することができました
キャッシュの期間を設定する
PrismaAccelerateの目玉機能であるCDNでのキャッシュを試してみます
使い方は簡単で、Prismaのリクエストをするときにオプションを指定するだけです
今回は検証用に withAccelerateInfo() も付けてみます
- const data = await prisma.reminder.findMany();
+ const data = await prisma.reminder.findMany({
+ cacheStrategy: { swr: 60, ttl: 60 },
+ }).withAccelerateInfo();
ttl はキャッシュ期間で、 swr はVercelのSWRと同じような意味で revalidate の機能を果たすようです
以下原文です
In the example above, swr: 60 and ttl: 60 means Accelerate will serve cached data for 60s and then another 60s while Accelerate fetches fresh data in the background.
ではキャッシュした場合としてない場合でパフォーマンスの差を見てみましょう
キャッシュでリクエストの時間がどう変わるのか検証
ttl, swr無しでリクエストした場合
~/go/src/github.com/suzu2469/oaiso main
❯ curl -w "total: %{time_total}" -s http://localhost:8787
total: 1.148860
withAccelerateInfo()
{
"cacheStatus": "none",
"lastModified": "2023-03-23T14:08:30.000Z",
"region": "NRT",
"requestId": "7ac73f2ad3d4dfd1-NRT",
"signature": "efa98a4d348e6c0df34bb82f6bc6f9abdfcd1413322f9d1be3f49ce6f93b10e5"
}
ttl, swr有りでリクエストした場合
1回目
~/go/src/github.com/suzu2469/oaiso main 6s
❯ curl -w "total: %{time_total}" -o /dev/null -s http://localhost:8787
total: 1.128289
withAccelerateInfo()
{
"cacheStatus": "miss",
"lastModified": "2023-03-23T14:11:35.000Z",
"region": "NRT",
"requestId": "7ac743a9a67bdfd1-NRT",
"signature": "efa98a4d348e6c0df34bb82f6bc6f9abdfcd1413322f9d1be3f49ce6f93b10e5"
}
2回目
~/go/src/github.com/suzu2469/oaiso main 6s
❯ curl -w "total: %{time_total}" -o /dev/null -s http://localhost:8787
total: 0.047535
withAccelerateInfo()
{
"cacheStatus": "ttl",
"lastModified": "2023-03-23T14:11:35.000Z",
"region": "NRT",
"requestId": "7ac743dcc035dfd1-NRT",
"signature": "efa98a4d348e6c0df34bb82f6bc6f9abdfcd1413322f9d1be3f49ce6f93b10e5"
}
1.2秒ほどかかっていたリクエストが0.05秒ほどになり20倍高速になりました すげぇ……
まとめ
今回のPrismaAccelerate、正式版がリリースされたら世界が変わりそうな気がします
Edgeの話ばかりしていましたが、もちろんEdgeでなくても使えますし、何より全然設定とか難しいことしてないんですよね
CloudflareD1がSQLiteでWorkersからしか使えないのに対して、こちらは既存のアプリケーションにもサッと入れてしまえる強大なコストの低さがあります
DBリードレプリカの戦略に悩んでいる方々に、斜め上からのアプローチでぶっ刺さっていて非常に良いです
(というかDBのデータのキャッシュをCDNにばら撒こうっていう発想が頭悪くて好きです)
正式版のリリースが楽しみですね
Discussion