MeCab + neologd 辞書環境でユーザ辞書を追加する
Python で MeCab を使い始めて neologd を入れました。ゆーても足りない単語がいくつかあったのですが、ユーザ辞書の登録でクソほど時間が掛かったので書きました 🥺
この記事で書かないこと
- MeCab, neologd の入れ方
- システム辞書の変更方法
環境
- MacOS Catalina
- MeCab インストール済み
- mecab-ipadic-neologd インストール済み
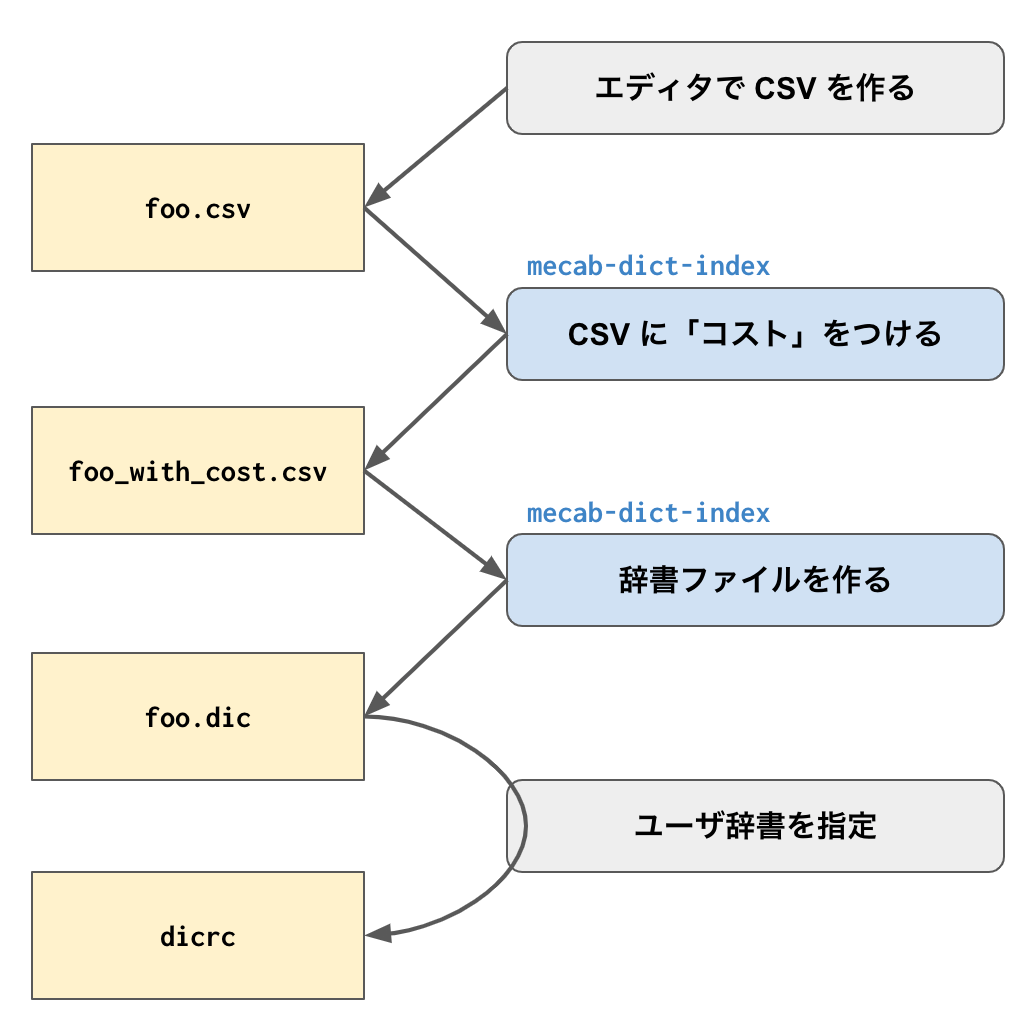
作業の大まかな流れ
くわしくは別のセクションで説明しますが、こんな感じで作業をするよ。
エディタで CSV を書いた後は、 mecab-dict-index を使って辞書にコストをつけて、 .dic ファイルを作る。さいごに、neologd のディレクトリにある dicrc というファイルを編集してユーザ辞書を指定する。
知っておくと楽になること
自分みたいに MeCab を始めたばかりの場合はこのへんを知っておくとデバッグがしやすくなるかも。
システム辞書の変更とユーザ辞書の変更
ソース: http://taku910.github.io/mecab/dic.html
「システム辞書」とは ipadic とか neologd とかどこかからインストールしてきた辞書。「ユーザ辞書」はうちらが定義する辞書。
で、「MeCab に自分が定義した単語を追加したい」というときは、
- システム辞書を直接いじる方法と、
- ユーザ辞書を追加する方法
の2つがある。ユーザ辞書を追加する方が遅くなるけど、今回は MeCab に慣れてないので取り返しがつきそうなユーザ辞書の変更にした。
システム辞書とユーザ辞書の関係
ソース: http://taku910.github.io/mecab/dic.html (「ユーザ辞書への追加」の部分) + やってみた
システム辞書とユーザ辞書の関係、つまり MeCab で使う辞書を指定した場合どのユーザ辞書を参照するかはこう↓
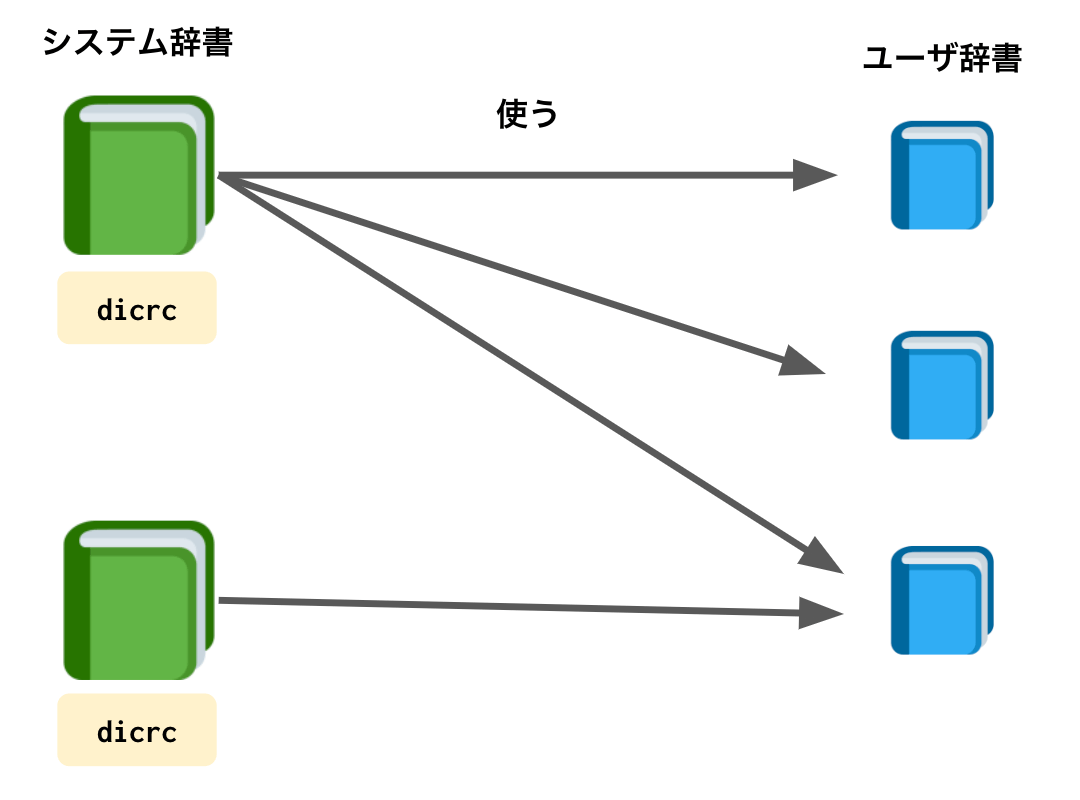
たとえば、mecab-ipadic-neologd で foo.dic (後述するけどこれがユーザ辞書) を使いたいときは、
- mecab-ipadic-neologd のディレクトリ内に
dicrcがあって - その
dicrcの中にfoo.dicへのフルパスが記述されてる
この設定が書いてあれば、Python で MeCab を使うときは -d コマンドでシステム辞書だけ指定すれば -u でユーザ辞書を指定しなくてもok
mecab-ipadic-neologd だけではユーザ辞書を登録できない
ソース: http://taku910.github.io/mecab/dic.html, https://blog.apar.jp/linux/2796/#toc8
ユーザ辞書を作るためには、こういうコマンドを走らせる。この -m オプションが neologd ではネックになっていて、-m には .model 拡張子の「モデルファイル」を渡す。ipadic ではモデルファイルが提供されているけど、neologd ではなさそう。(neologd だけでユーザ辞書を作っている記事が見つからなかった & neologd のモデルファイルがなさそうだった)
# https://blog.apar.jp/linux/2796/#toc8 を編集
mecab-dict-index \
-m <モデルファイル>
-d <辞書が入っているディレクトリ> \
-u <コスト推定済のCSVファイルの保存先>
-f utf8 -t utf8 \
-a <作成した追加単語のCSVファイル(コスト無し)>
辞書には文字コードがある
mecab-ipadic-neologd の README にも書いてあるように、辞書には文字コードの概念がある。
ソースコードからインストールするときは以下の手順で文字コードを UTF-8 インストールして下さい
mecab-ipadic-neologd の場合、辞書が UTF-8 だけど、ユーザ辞書を使うときに生成する ipadic は加工しないと EUC-JP。なので、ipadic を EUC-JP から UTF-8 に変換する手順が必要。
手順
(入っていなければ) nkf コマンドをインストール
以降の作業で文字コードを確認・変換する作業があるのでいれる。
インストール方法は省略します🙏
作業用ディレクトリを作る
場所はどこでもいいけど、これから CSV ファイルを2つと、最終的にシステム辞書が参照するユーザ辞書ファイル (.dic) を保存するので、そのための場所が必要。
$ mkdir mecab-working-dir
$ cd mecab-working-dir
作業用ディレクトリで CSV を作る
ソース: http://taku910.github.io/mecab/dic.html (「エントリのフォーマット (活用しない語)」)
登録したい辞書をこの形式↓で書く。文字コードはUTF-8で保存する。
# http://taku910.github.io/mecab/dic.html を編集
表層形,,,,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音,追加エントリ
# 例
ユーザ設定,,,,名詞,一般,*,*,*,*,ユーザ設定,ユーザセッテイ,ユーザセッテイ,追加エントリ
$ cd mecab-working-dir # 作業ディレクトリに移動
$ touch foo.csv # 名前はなんでも
$ vim foo.csv # vim じゃなくてもOK
# 辞書を入力する
$ nkf -g
# UTF-8 なのを確認できればOK
なお、MeCab 公式に書いてある形式は
表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音
だけど、「左文脈ID」「右文脈ID」「コスト」は後のステップで自動で入るので入力しなくていい。
ipadic 辞書のダウンロードと設定
ソース: https://blog.apar.jp/linux/2796/#toc5, https://qiita.com/DisneyAladdin/items/67d986fdb402f3b1c350, https://github.com/neologd/mecab-ipadic-neologd/blob/master/README.ja.md#動作に必要なもの
次のステップで ipadic 辞書と .model のモデルファイルを使うので、それぞれダウンロードする。
(1) まず、ipadic 辞書本体の方は、https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM から圧縮ファイルを落とす。その後、このファイルを作業用ディレクトリに移動して解凍する。
$ cd mecab-working-dir
# tar.gz は移動済みとする
$ tar xvzf mecab-ipadic-2.7.0-20070801.tar.gz # 解凍
(2) 次に、文字コードを EUC-JP から UTF-8 に変換する。「辞書には文字コードがある」のセクションにも書いたけど、neologd は UTF-8 なので互換性を持たせるため ipadic を EUC-JP から UTF-8 に変換する。
$ nkf --overwrite -Ew mecab-ipadic-2.7.0-20070801/*
(3) ipadic の dicrc を編集する
dicrc は辞書の設定ファイルみたいなもので、10行目に文字コードが書いてあるのでそれを編集する。
$ cd mecab-working-dir
$ ls
# mecab-ipadic のディレクトリを確認
$ cd mecab-ipadic-2.7.0-20070801
$ ls
# dicrc があることを確認
$ vim dicrc # エディタはなんでもOK
9 unk-eval-size = 4
10 - config-charset = EUC-JP
10 + config-charset = UTF-8
(4) configure する
mecab-ipadic にディレクトリにある configure を走らせます。
# 同じディレクトリにいれば cd はいらない
$ cd mecab-working-dir
$ cd mecab-ipadic-2.7.0-20070801
$ /usr/local/Cellar/mecab/0.996/libexec/mecab/mecab-dict-index -f utf-8 -t utf-8
$ ./configure --with-charset=utf8
これで ipadic の UTF-8 版のインストールは終わり。
ipadic のモデルファイルをダウンロードする
ソース: https://taku910.github.io/mecab/dic.html 「コストの自動推定機能」, https://blog.apar.jp/linux/2796/#toc5, https://mathcommunication.hatenablog.com/entry/2017/08/14/005952
(1) モデルファイルのダウンロード
ここ から .bz2 ファイルを落とす。公式の「コストの自動推定機能」の
mecab-ipadicのモデルファイルはこちらよりダウンロード可能です
のとこにリンクがある。
$ cd mecab-working-dir
# bz2 ファイルは移動済みとする
$ bzip2 -d mecab-ipadic-2.7.0-20070801.model.bz2
# .model ファイルができる
(2) モデルファイルを UTF-8 に変換
辞書と同様に、モデルファイルも EUC-JP から UTF-8に変換する。
$ cd mecab-working-dir
$ nkf --overwrite -Ew mecab-ipadic-2.7.0-20070801.model
(3) モデルファイルを編集
モデルファイルも文字コードが指定してあるので書き換える (6行目)
$ cd mecab-working-dir
$ vim mecab-ipadic-2.7.0-20070801.model
5 unk-eval-size: 4
6 -charset: EUC-JP
6 +charset: UTF-8
CSV にコストを付与する
ソース: http://taku910.github.io/mecab/dic.html 「コストの自動推定機能」
まず、 mecab-dict-index というやつがどこにあるか確認する。これは前のステップで作った CSV に「コスト」をつけたり、辞書ファイルを生成したりできる executable。これのパスが環境によって異なるので mecab-config コマンドを使って探す。mecab-config 自体は MeCab がインストールされていれば入ってるので追加のインストールはいらない。
$ mecab-config --libexecdir
/usr/local/Cellar/mecab/0.996/libexec/mecab # ここは環境による
$ cd /usr/local/Cellar/mecab/0.996/libexec/mecab
$ ls
# mecab-dict-index があるのを確認
以降の例では /usr/local/Cellar/mecab/0.996/libexec/mecab を mecab-dict-index のディレクトリとして記述しますが、適宜自分の環境に合わせて変えてください。
CSV にコストをつけるコマンドはこう↓
$ /usr/local/Cellar/mecab/0.996/libexec/mecab/mecab-dict-index \
-m <モデルファイル>
-d <ipadic 辞書のディレクトリ> \
-u <コストのついた CSV につけたいファイル> # このコマンドで作られるので名前を指定
-f utf-8
-t utf-8
-a <コストのついていない CSV のファイル> # 前のステップで作ったファイル
モデルファイル、ipadic 辞書のディレクトリはそれぞれ前のステップでインストールしたもので、たとえばこういうコマンドになる。
$ cd mecab-working-dir
$ /usr/local/Cellar/mecab/0.996/libexec/mecab/mecab-dict-index \
-m mecab-ipadic-2.7.0-20070801.model \
-d mecab-ipadic-2.7.0-20070801 \
-u foo-cost.csv # このコマンドで作られるので名前を指定
-f utf-8 # CSV の文字コード
-t utf-8 # 辞書の文字コード
-a foo.csv # 前のステップで作ったファイル
mecab-ipadic-2.7.0-20070801.model is not a binary model. reopen it as text mode...
reading foo.csv ...
done!
# done! があれば成功。なければググる🥺
これを走らせた後、foo-cost.csv を開いて「左文脈ID」「右文脈ID」「コスト」が入ってればOK。
# foo.csv
ユーザ設定,,,,名詞,一般,*,*,*,*,ユーザ設定,ユーザセッテイ,ユーザセッテイ,追加エントリ
# foo-cost.csv
ユーザ設定,1342,1847,10,名詞,一般,*,*,*,*,ユーザ設定,ユーザセッテイ,ユーザセッテイ,追加エントリ
コストつきの CSV から辞書ファイルを生成
ソース: https://taku910.github.io/mecab/dic.html 「ユーザ辞書への追加」
コマンドの形式はこう↓
$ /usr/local/Cellar/mecab/0.996/libexec/mecab/mecab-dict-index \
-d <ipadic 辞書のディレクトリ> \
-u <作りたい .dic のファイル名> \ # これから作られるファイル
-f utf-8 \ # CSV の文字コード
-t utf-8 \ # 辞書の文字コード
<コストつきCSV> #
コストつき CSV から mecab-dict-index を使って .dic ファイルを作るイメージで、これまでの例だとこうなる↓
$ /usr/local/Cellar/mecab/0.996/libexec/mecab/mecab-dict-index \
-d mecab-ipadic-2.7.0-20070801 \
-u foo.dic \ # これから作られるファイル
-f utf-8 \ # CSV の文字コード
-t utf-8 \ # 辞書の文字コード
foo-cost.csv #
reading foo-cost.csv ... 16
emitting double-array: 100% |###########################################|
done!
# done! があれば成功
ユーザ辞書を neologd の dicrc で指定する
neologd の辞書の場所がわからない場合、mecab-dict-index と同様に mecab-config で確認できる。
$ mecab-config --dicdir
/usr/local/lib/mecab/dic # 自分の環境だとこうなる
辞書ファイルに移動して dicrc を編集する。
$ cd /usr/local/lib/mecab/dic
$ cd mecab-ipadic-neologd
$ vim dicrc
デフォルトで設定が書いてあるけど、わかりやすい場所に書けばOK。
userdic = <作業用ディレクトリまでのフルパス>/<辞書ファイル>
; 例
userdic = /Users/hogetarou/mecab-working-dir/foo.dic
最後にユーザ辞書が反映されてるか確認されてれば終わり🥳
Discussion