Learning Python, 5th edition 読んでみたログ
はじめに
本はこれ
また読むところが増えたら追記します
なんで読んだか
趣味で Python をさわるけどちょくちょくわからないことが出てくるので整理したい
読んでどうなりたいか
- ふわっと Python に詳しくなりたい
1ヶ月後も覚えておきたいこと
-
fromとimportの使い方 - module import の流れ
- search path のしくみ
- ...
topics
modules と import
前提として、Python のプログラムは statements が書かれているテキストファイルから構成されていて、1つの top-level ファイルと0個以上の module からなる。module は top-level ファイルに使用される「ツール」で、プログラムを module に分割するのが Python の特徴のひとつ (modular programming)。module に分割すると、コードを再利用できる・名前空間を分けられるというメリットがある。
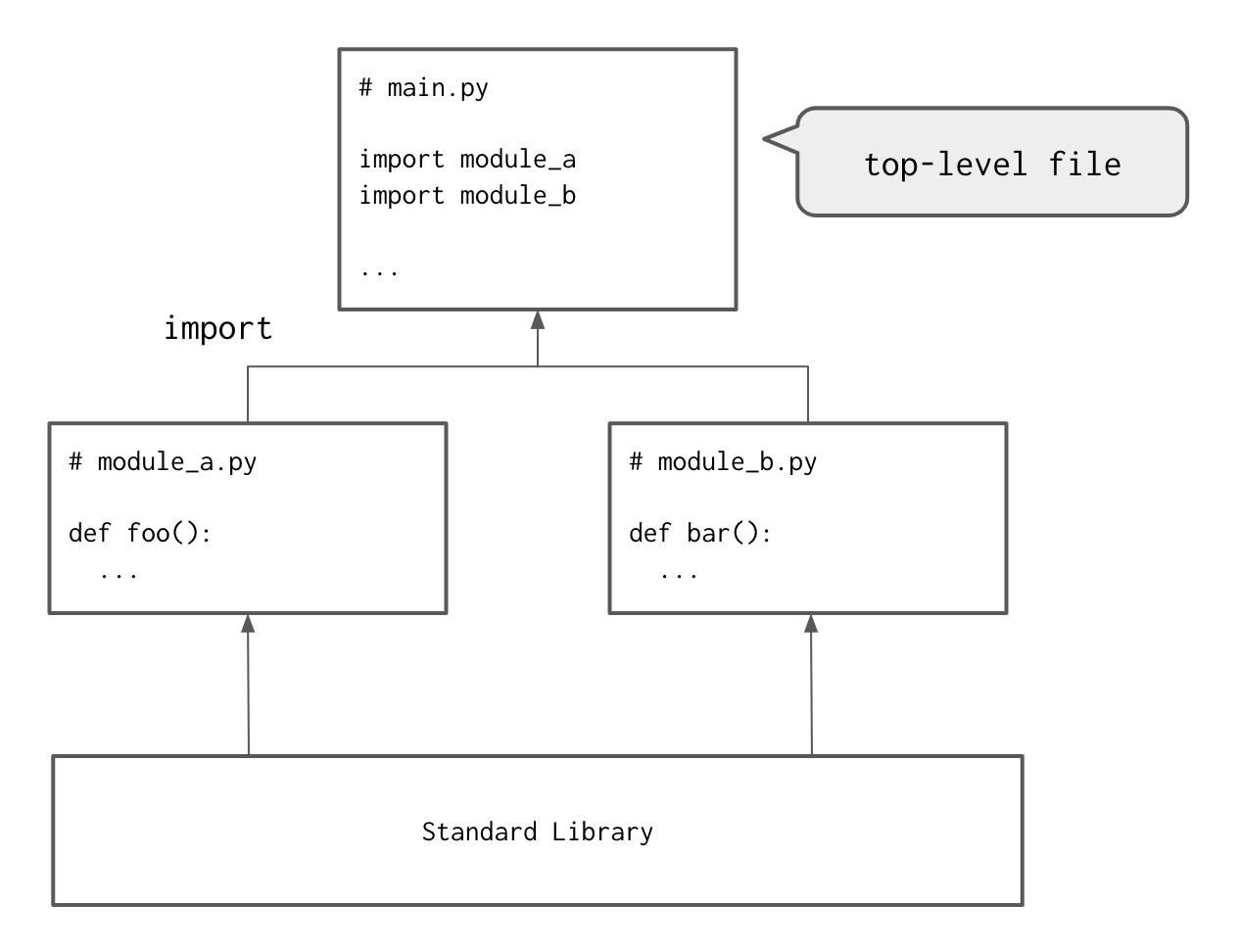
module は同時に名前空間 (namespace) でもあり、ある module A で定義された foo という name は module B では使えない。name とは変数または変数で、何もしないと top-level ファイルで他の module の関数とか変数を使えない。ここで、import が出てきて、import を通して他の module の name を使える ようになる。
# my_module.py
BAR = 999 # BAR という名前
def foo(): # foo という名前
print('foo')
from と import の使い方
-
import: module 全体を使えるようにする -
from: module の特定の name を使えるようにする
import Math # Math module を使うよ
print(Math.PI) # PI という name は Math. をつけて使う
from Math import PI # Math module の PI という name を使うよ
print(PI) # Math. はいらない
import したファイルと object の関係
import Math と書くと、PI定数を使うためには Math.PI のように object.attribute と同じ記法をする。これは偶然ではなくて、import では
- module のファイルを特定する
- module に書かれた name を attribute に持つ object をロードする
- この object の名前を決める
(i.e. Math module の中身を Math という名前の object にアサインする)
ということをしている。
ちなみに本文だとこういう表現だった↓
module file's global scope morphs into the module object's attribute namespace when it is imported (Chapter 22, p.691)
A file imports a module to gain access to the tools it defines, which are known as its attributes -- variable names attached to objects such as functions (Chapter 22, p.692)
なので、Math.PI と書くのは "Math module をロードしたオブジェクトの、attribute PI を通して name PI にアクセスする" という意味になる。

import の流れ
ファイルにインポート文があると、Python は
- ファイルを探して、
- まだされてなかったらファイルをコンパイルして、最後に
- ファイルを実行する
1 では sys.path に書かれてるモジュール探索パス (search path) から同じ名前のファイルを探す (import foo とあったら foo.py を探す)。
2 ではバイトコードにファイルをコンパイルするけど、これは既にファイルの最新版がコンパイルされていたらしない。
3 ではバイトコードを走らせて、ファイルに書かれている名前 (def hoge とか) から module object の属性を生成 する。
pycache は何者?
↑で書いた、2の「バイトコードにコンパイルする」のところで、コンパイルしたバイトコードを保存するところが __pycache__/。
Python のバージョンによって多少違いがあるけど、大まかな仕組みとしては .py ファイルのタイムスタンプ と バイトコードに埋め込まれたバージョン を比較して、すでに同じ Python のバージョンでファイルの最新版をコンパイルしたものが __pycache__/ にあれば、再度コンパイルしないようになってる。
search path / モジュール探索パス
こっちにもうちょっと詳しく書きました
- プログラムのホームディレクトリ
- 環境変数 PYTHONPATH
- standard library のディレクトリ
- .pth ファイル
- site-packages (i.e. pip install したときのインストール先)
からモジュールを探索する。
from, import のよい・だめな書き方
from some_module import * はよくない。インポートしている名前が分からないので、自分で変数・関数を定義したときや、別のライブラリをインポートしたときにうっかり名前が重複する可能性があるから。
# これはだめ
from some_module import *
逆に、from foo.bar import hoge はよい書き方。なぜかというと、このディレクトリ構造が変わったときに1つのファイルの変更箇所が1個ですむから。
# よい書き方
# BEFORE: foo/bar/hoge.py
from foo.bar import hoge
# AFTER: foo/bar/baz/hoge.py (もう一個 baz/ ディレクトリを作る)
from foo.bar.baz import hoge # 変更はここだけ
これを import foo としてファイル内で foo.bar.hoge として参照すると、ディレクトリ構造が変わると foo.bar.hoge を全部 foo.bar.baz.hoge に書き換えないといけないので大変。
# あんまりよくない書き方
# BEFORE: foo/bar/hoge.py
import foo
print(foo.bar.hoge.some_func)
# AFTER: foo/bar/baz/hoge.py (もう一個 baz/ ディレクトリを作る)
import foo
print(foo.bar.baz.hoge.some_func) # こういうのを全部書き換えないといけない
tuple って何?
tuple (タプル・テュープル) は配列だけど、list と違ってimmutableな配列。1個しか要素がないものは trailing comma がある
(foo,) # 要素が1個しかない tuple
Discussion