ChatGPTとLangChainを活用したアプリ開発
はじめに
今回はChatGPTを利用した開発におけるアシスタントのやり方とLangChainを活用した実装方法を具体的なアプリ開発を例に解説していきます。
LangChainの実装方法について、Python未経験の自分でもサクッと実装できたので、初心者でも理解できるように解説をしていきます。
この記事で学べること
- ChatGPTを使って要件定義、設計、開発などをアシストする活用例が分かる
- アプリ開発においてLangChainの活用方法を学べる
前半でビジネスサイド(いわゆる要件定義、設計)などの解説をし、後半で具体的な開発例を解説する構成になっています。
LangChainにおける開発では具体的に下記の機能を実装します。
【URLを入力】
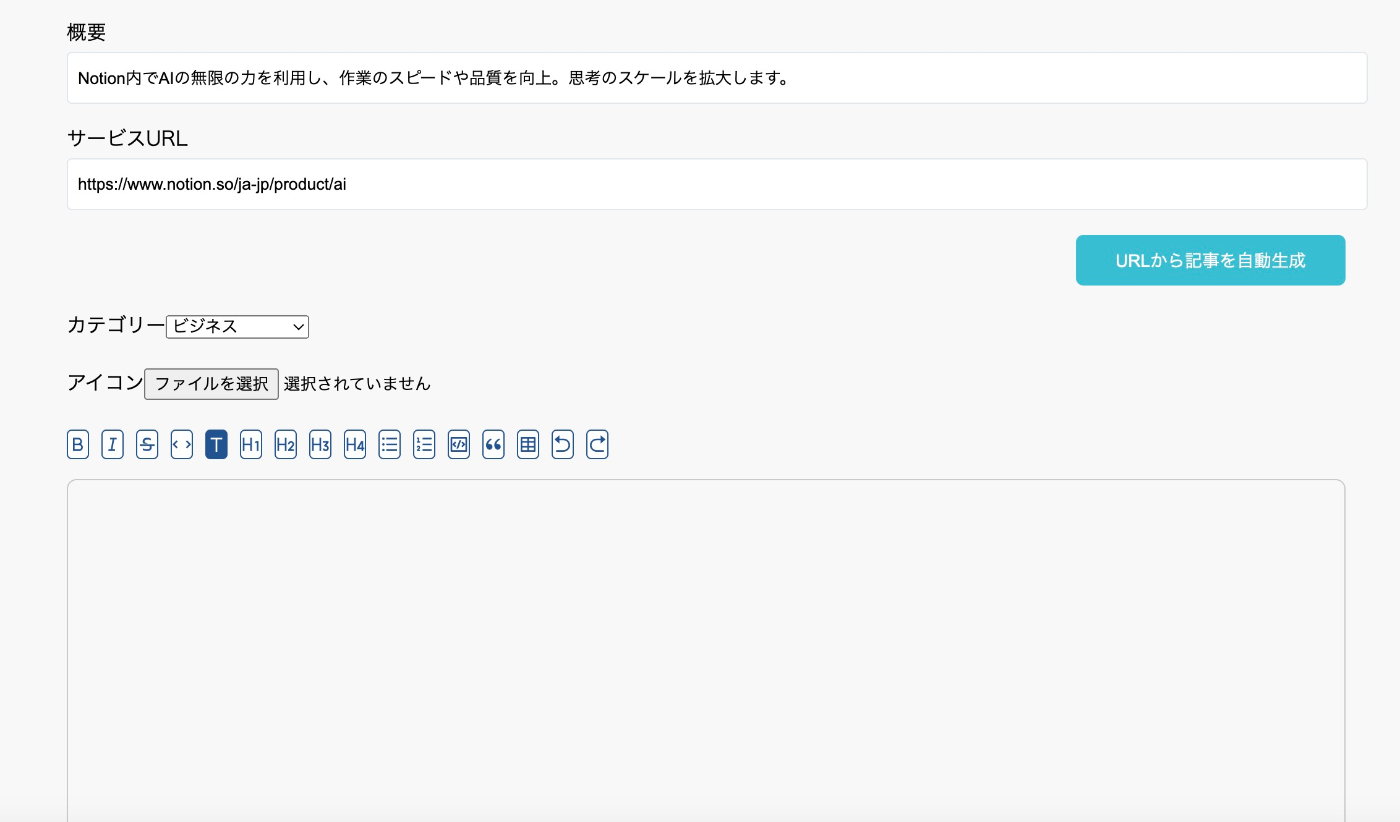
【URL先のコンテンツを解析】
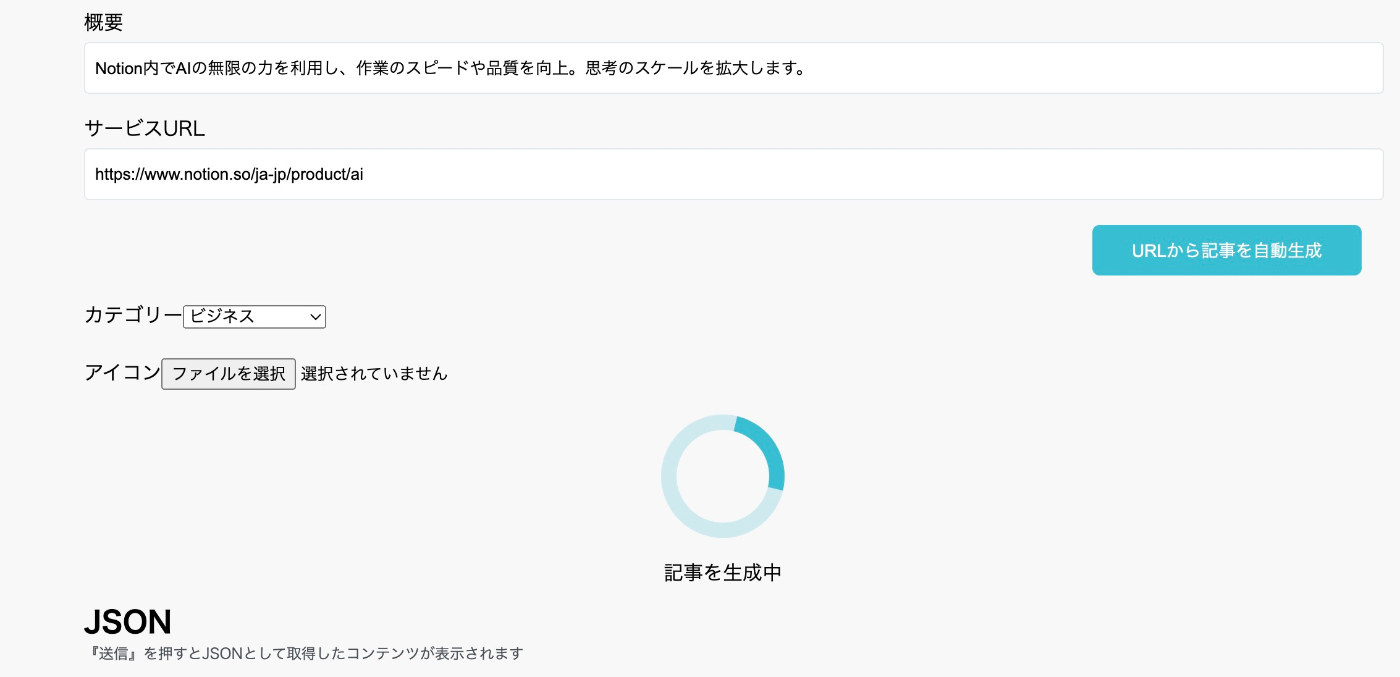
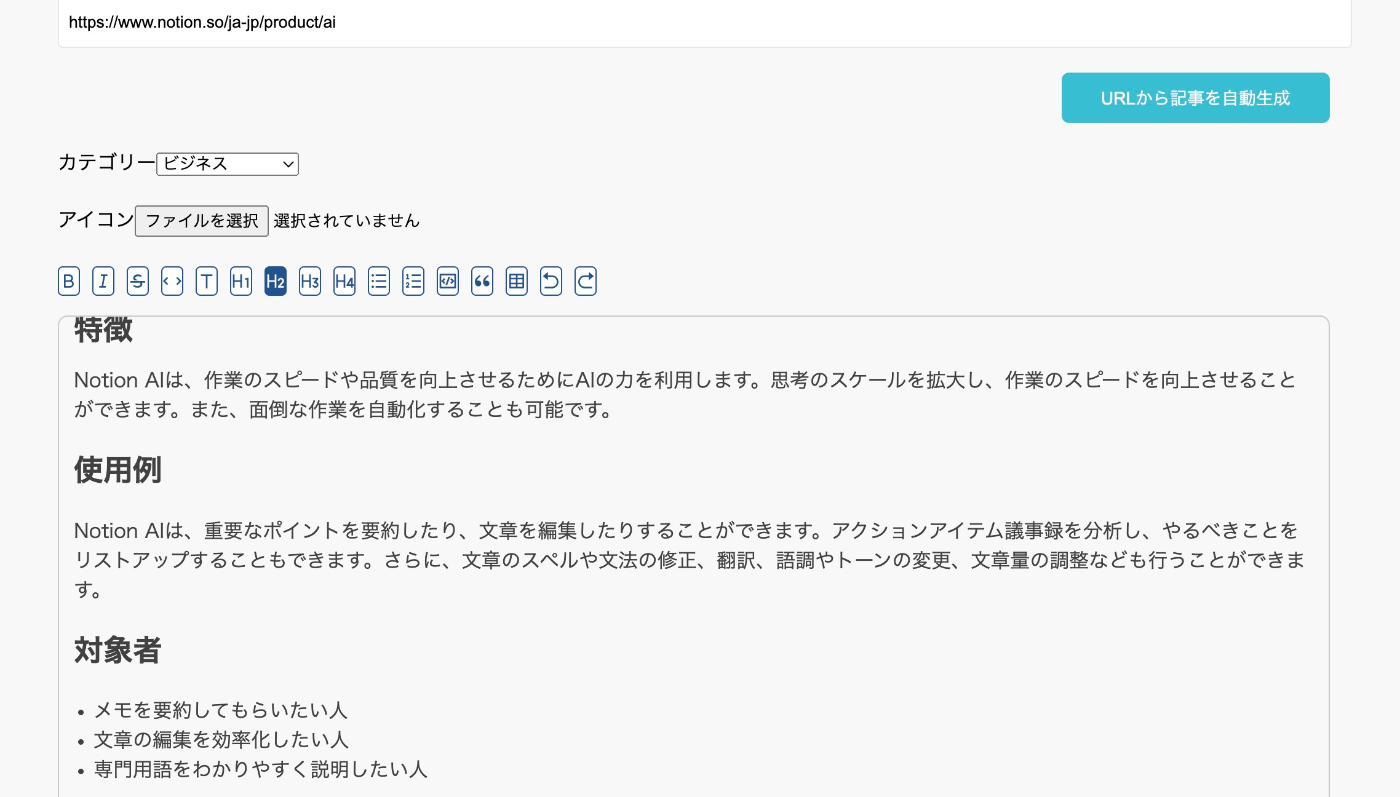
【解析をしたデータを元に文章を生成】
前提
- あくまで活用例を紹介する記事なので、技術的な細かい内容は公式サイトを添付しています
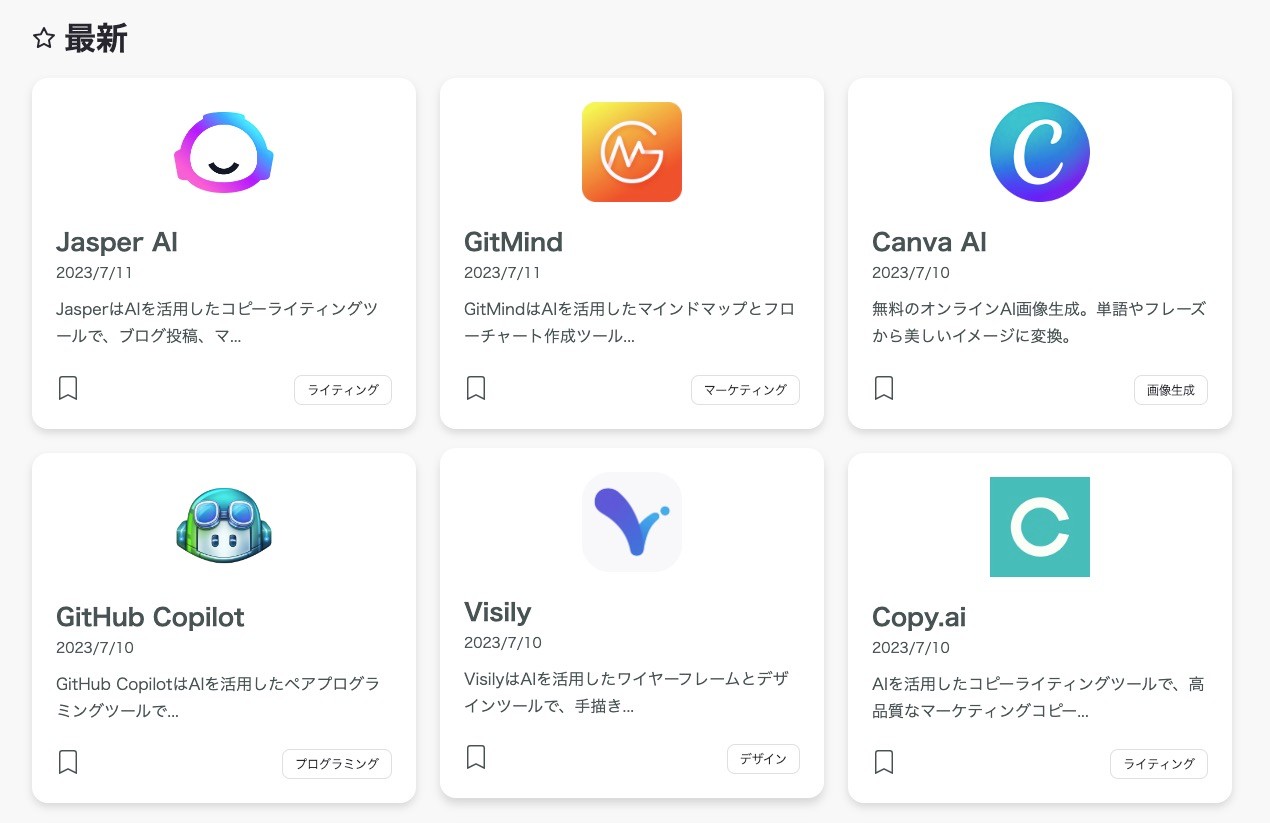
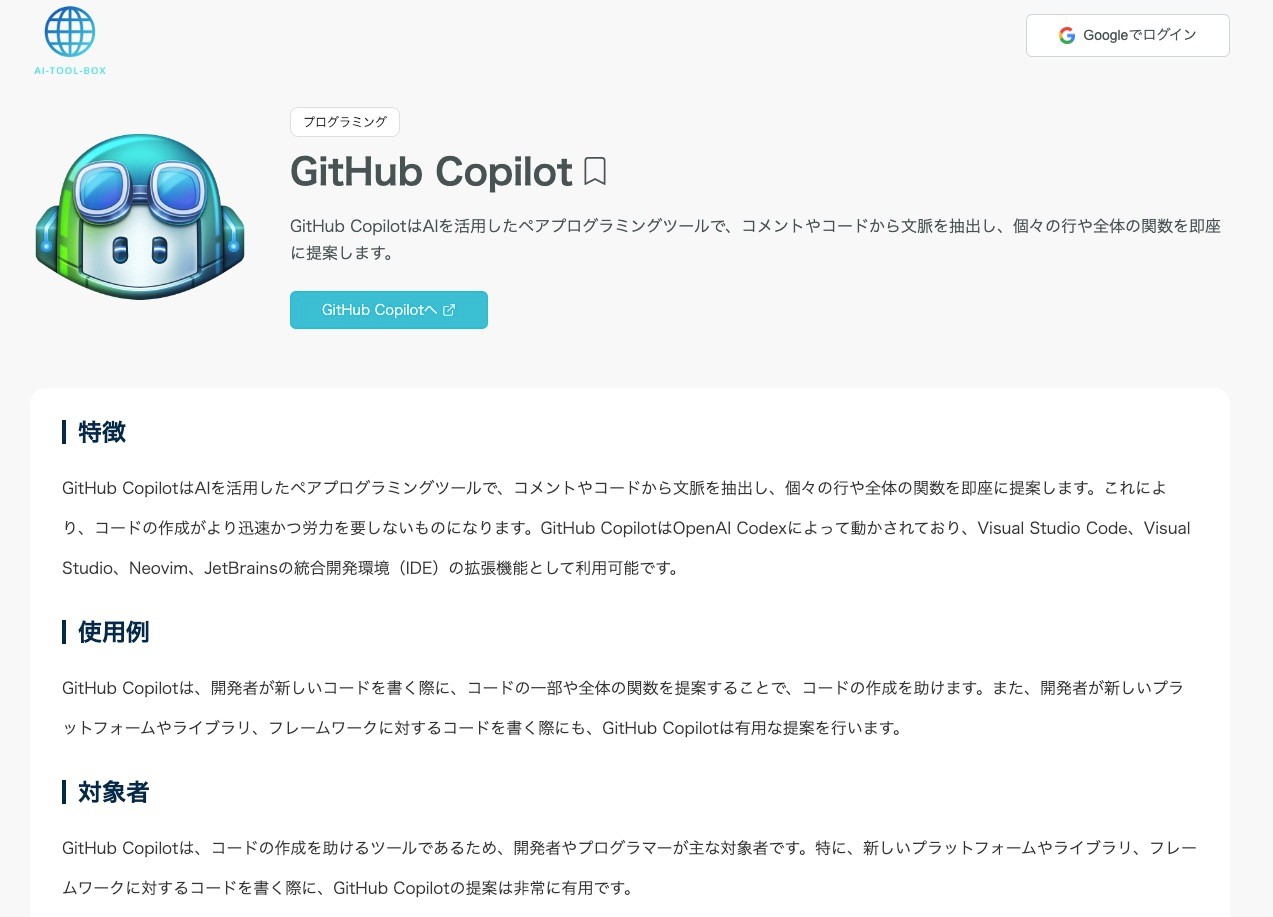
開発したアプリ
最新のAIツールやChatGPTのプラグインをまとめたサービスです。
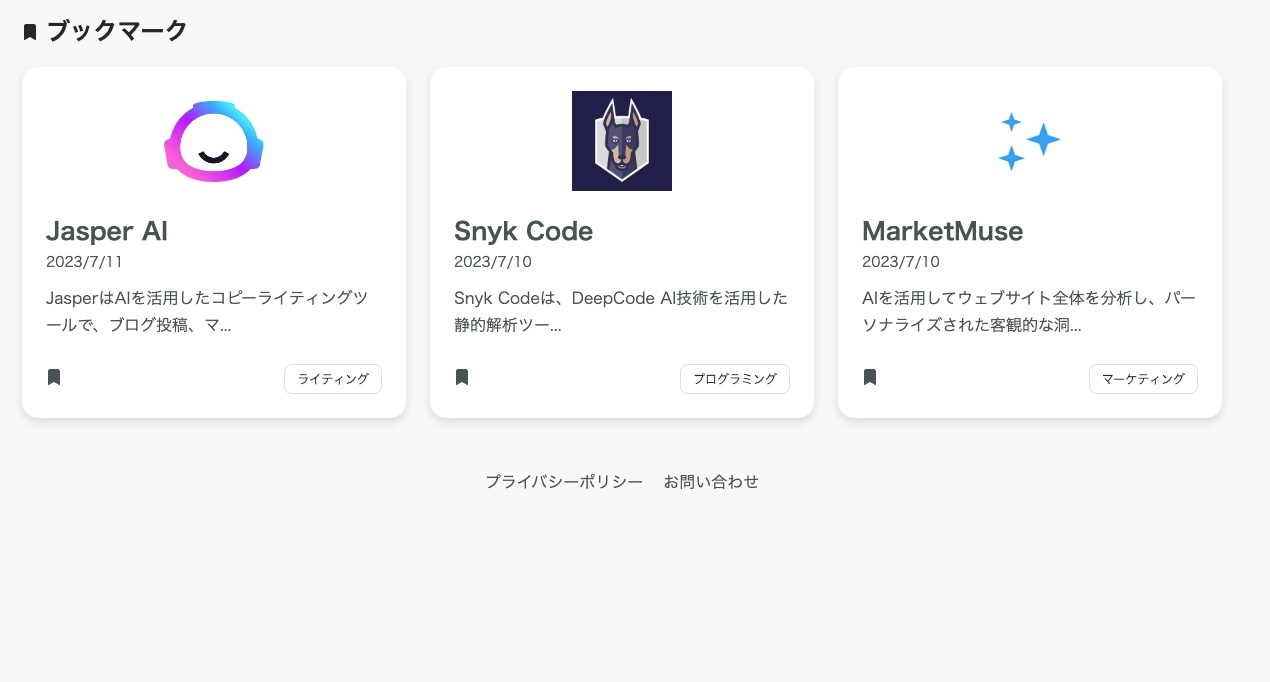
機能一覧
| 記事一覧 | 記事詳細 |
|---|---|
 |
 |
| カテゴリー | ブックマーク |
|---|---|
 |
 |
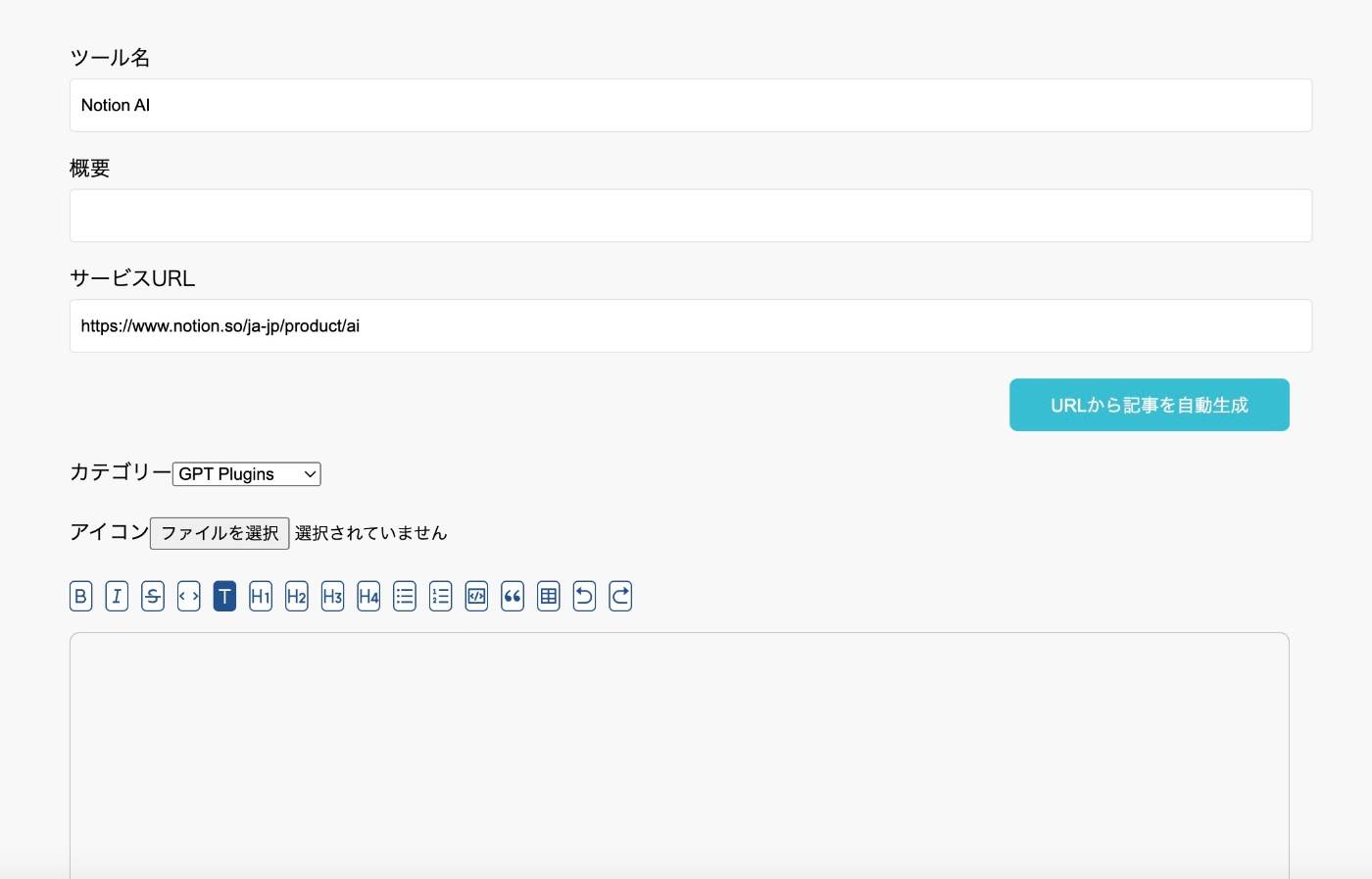
| 管理画面 |
|---|
 |
開発のきっかけ
AIツールボックスを開発しようと思った理由は下記の2点です。
- いつでも見返せるような「ストック型」の最新AIツールまとめが欲しかった
- 海外のAIツールも抵抗なく使いたい
いつでも見返せるような「ストック型」の最新AIツールまとめが欲しい
近年、AI技術の急速な進展により、最新のAIツールやプロダクト情報を追いつくのが難しくなっています。
TwitterなどのSNSでは日々新しいAIツールが紹介されていますが、これらは「フロー型」のアプリケーションで、大半の情報は瞬く間に流れてしまいます。
多くの場合、私たちは気になる情報を「いいね」やブックマークで保存しますが、情報の流れは速く、結果としてほとんどの情報を見直すことができません。
そういった中で、「ストック型」のAIツール紹介サービスがあれば便利だと考え、開発を始めました。
海外のAIツールも抵抗なく使いたい
AIツールの大部分は海外製で、英語が苦手な人にとってはなかなか利用しにくいのが現実です。
この問題に対処するため、ツールの機能や使用方法、特性などを日本語で紹介し、より多くの人が海外のAIサービスを抵抗なく活用できるようにすることを目指しました。
ChatGPTを使った開発アシスタント
まずはじめにChatGPTを使ってどのように開発アシスタントをしたのかを具体的なプロンプトと共に紹介していきます。
開発をする上での前提
時間の制約があったため、「1週間以内に開発をしてリリースをする」という目標のもとで開発を進めていきました。
一般的なシステム開発のフェーズ
一般的なシステム開発の流れは下記のようになっているかと思います。
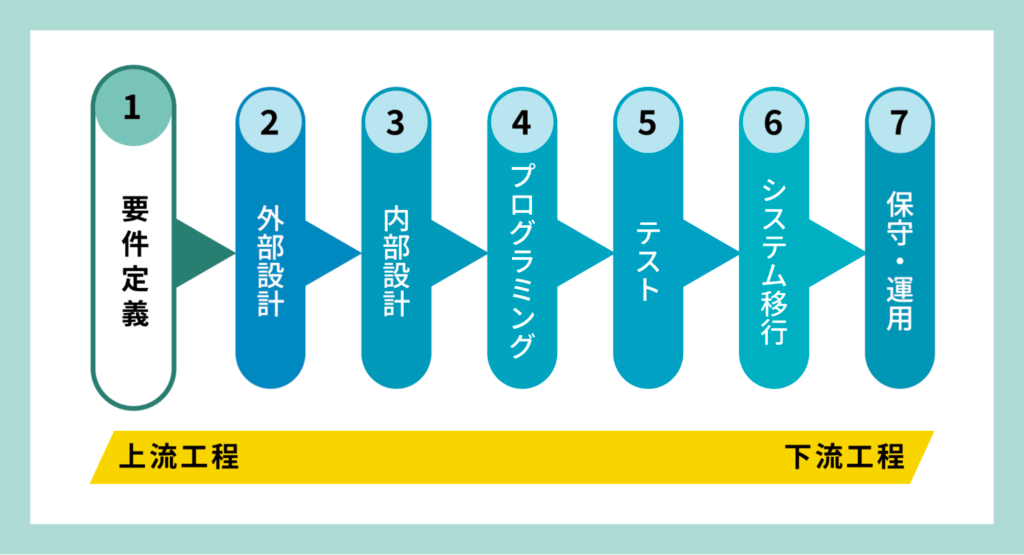
今回はこのフェーズの中の上流工程である要件定義、設計をChatGPTを利用して進めました。
要件定義
要件定義フェーズにおける成果物は下記を設定しました。
- 現状の課題と目標
- それに基づいた機能要件
- 非機能要件
現状の課題と目標
これに関しては自分の方で下記のように作成しました。
- フロー型ではなくストック型のAIツールまとめサービスが欲しい
- 用途別(カテゴリー別)でツールを探せるようしたい
- メインターゲットであるクリエイターがAIツールを使って生産性をより上げられるようにする
上記の課題と目標を前提としChatGPTに機能要件と非機能要件を洗い出してもらいます。
それに基づいた機能要件
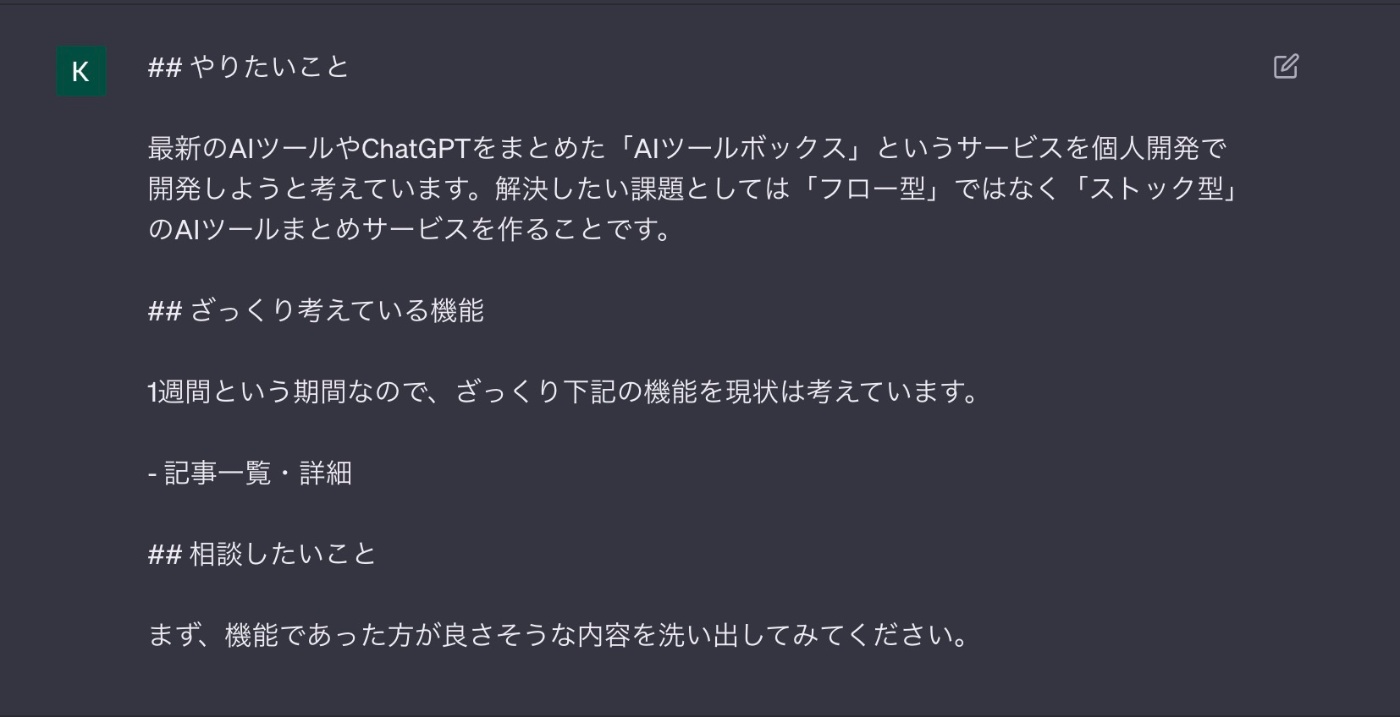
機能要件を洗い出してもらうために下記のようなプロンプトを準備しました。
【プロンプト】
## やりたいこと
最新のAIツールやChatGPTをまとめた「AIツールボックス」というサービスを個人開発で開発しようと考えています。解決したい課題としては「フロー型」ではなく「ストック型」のAIツールまとめサービスを作ることです。
## ざっくり考えている機能
1週間という期間なので、ざっくり下記の機能を現状は考えています。
- 記事一覧・詳細
## 相談したいこと
まず、機能であった方が良さそうな内容を洗い出してみてください。
実際にGPTに送ります。
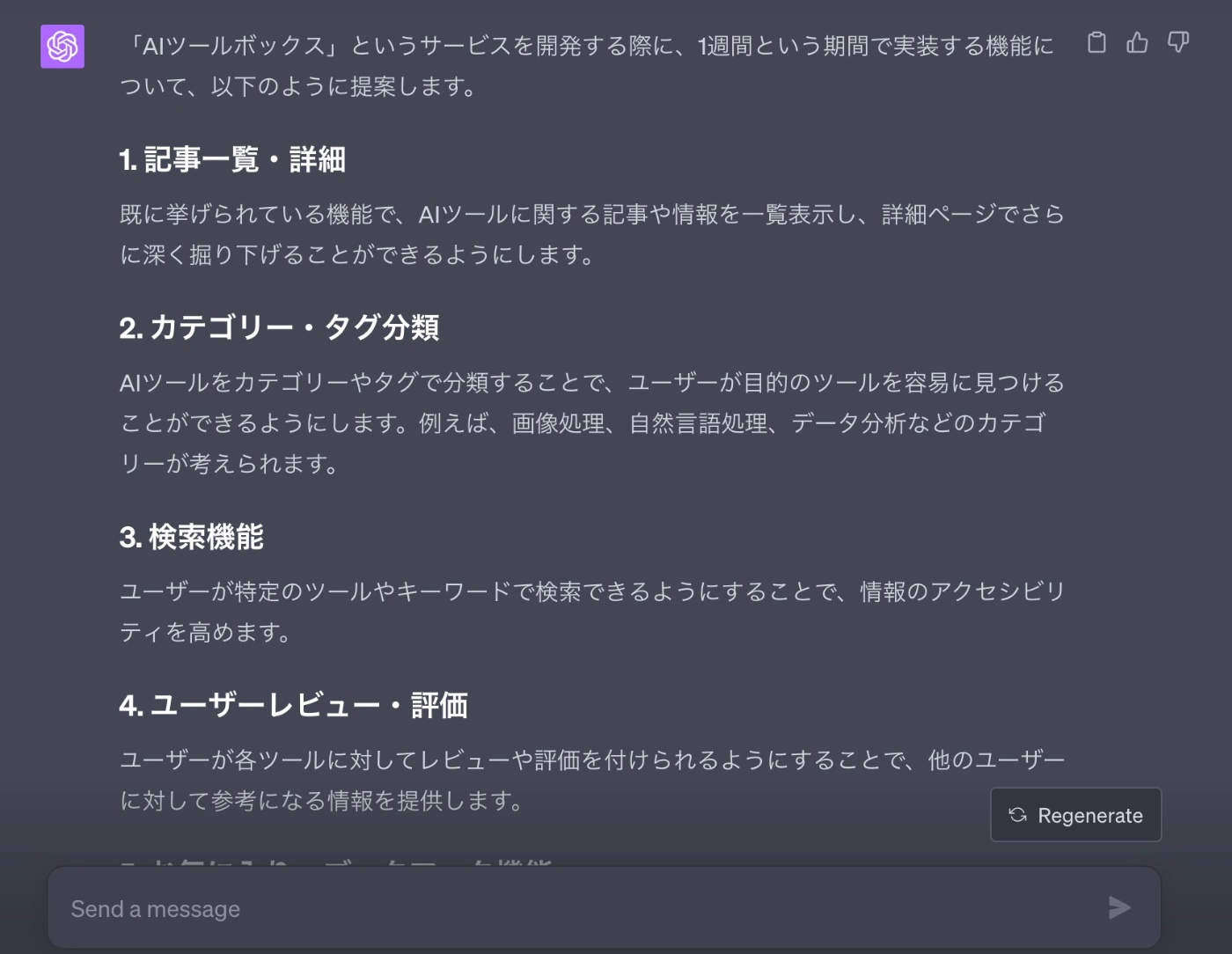
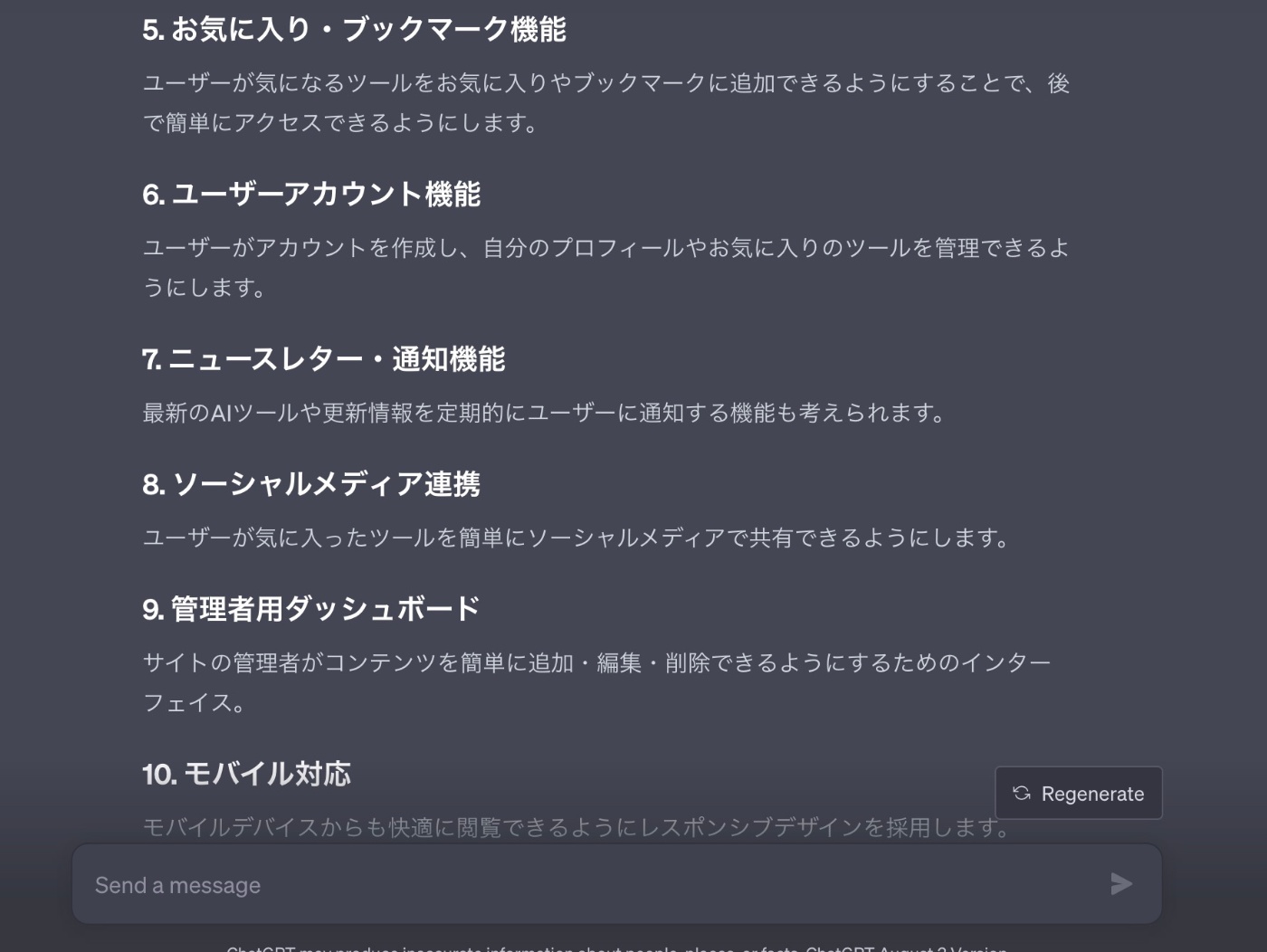
【回答】
下記のように10個ほど機能を洗い出してくれました。
1週間で開発をするという前提条件があるので、下記機能の優先度と工数をテーブル形式で出してもらいます。
【プロンプト】
開発期間が1週間ということとユーザーの利便性を考慮し、今出してくれた10個の機能それぞれに、ID、機能名、優先度、開発工数をテーブル形式でまとめてください。
【回答】
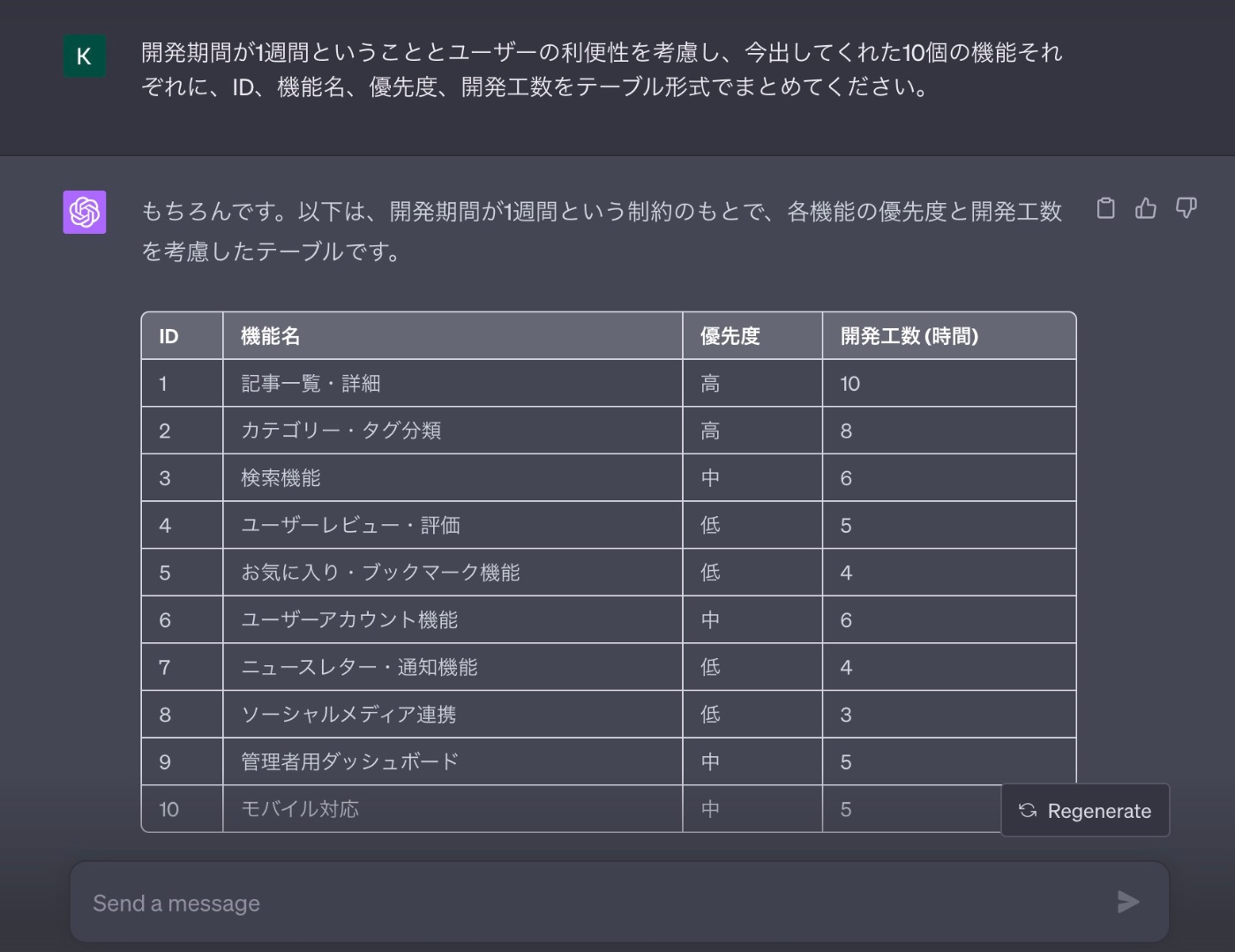
優先度と工数を元に1次フェーズでは下記の機能に絞りました。
- 記事一覧・詳細
- ユーザー認証
- カテゴリー・タグ分類
- ブックマーク機能
- ユーザーアカウント機能
- モバイル対応
非機能要件
次に非機能要件を洗い出します。
【プロンプト】
優先度をもとに、1次フェーズでは下記の機能で開発をすることにします。
- 記事一覧・詳細
- カテゴリー・タグ分類
- ブックマーク機能 → ユーザー登録をしてもらうため
- ユーザーアカウント機能
- モバイル対応
また、1次フェーズで対応できるかは分かりませんが、非機能要件も洗い出してください

【回答】
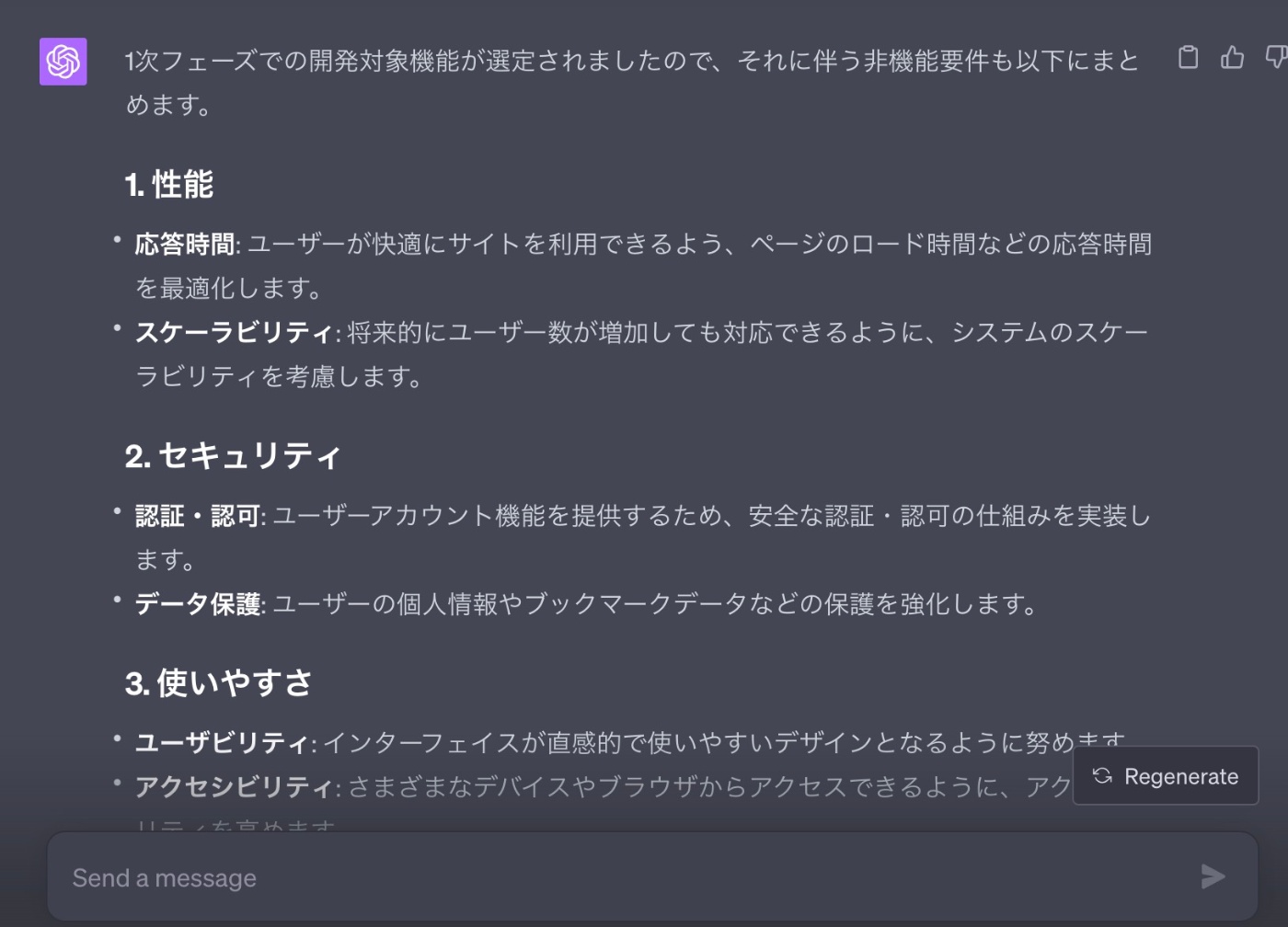

回答を元に1週間という前提があるので非機能要件としては下記を採用しました。
- 性能要件を考慮
- Next.jsのISRやSSRを採用する
- セキュリティーを考慮
- Google認証のみにし、パスワードはDB側には保存しない
- ユーザビリティ
- 直感的な操作性をするためにカードUIにする想定
- SP版にも対応する
- 法規準拠
- ユーザー情報を取り扱うのいでプライバシーポリシーの作成
最後にこれらの内容を見やすくするためにChatGPTにテーブル形式でまとめてもらいます。
【プロンプト】
優先度を考慮し、非機能要件は下記で対応します。
-
- 性能要件を考慮
- Next.jsのISRやSSRを採用する
- セキュリティーを考慮
- Google認証のみにし、パスワードはDB側には保存しない
- ユーザビリティ
- 直感的な操作性をするためにカードUIにする想定
- SP版にも対応する
- 法規準拠
- ユーザー情報を取り扱うのいでプライバシーポリシーの作成
現状の要件定義の機能・非機能をテーブル形式でわかりやすくまとめてください
【回答】
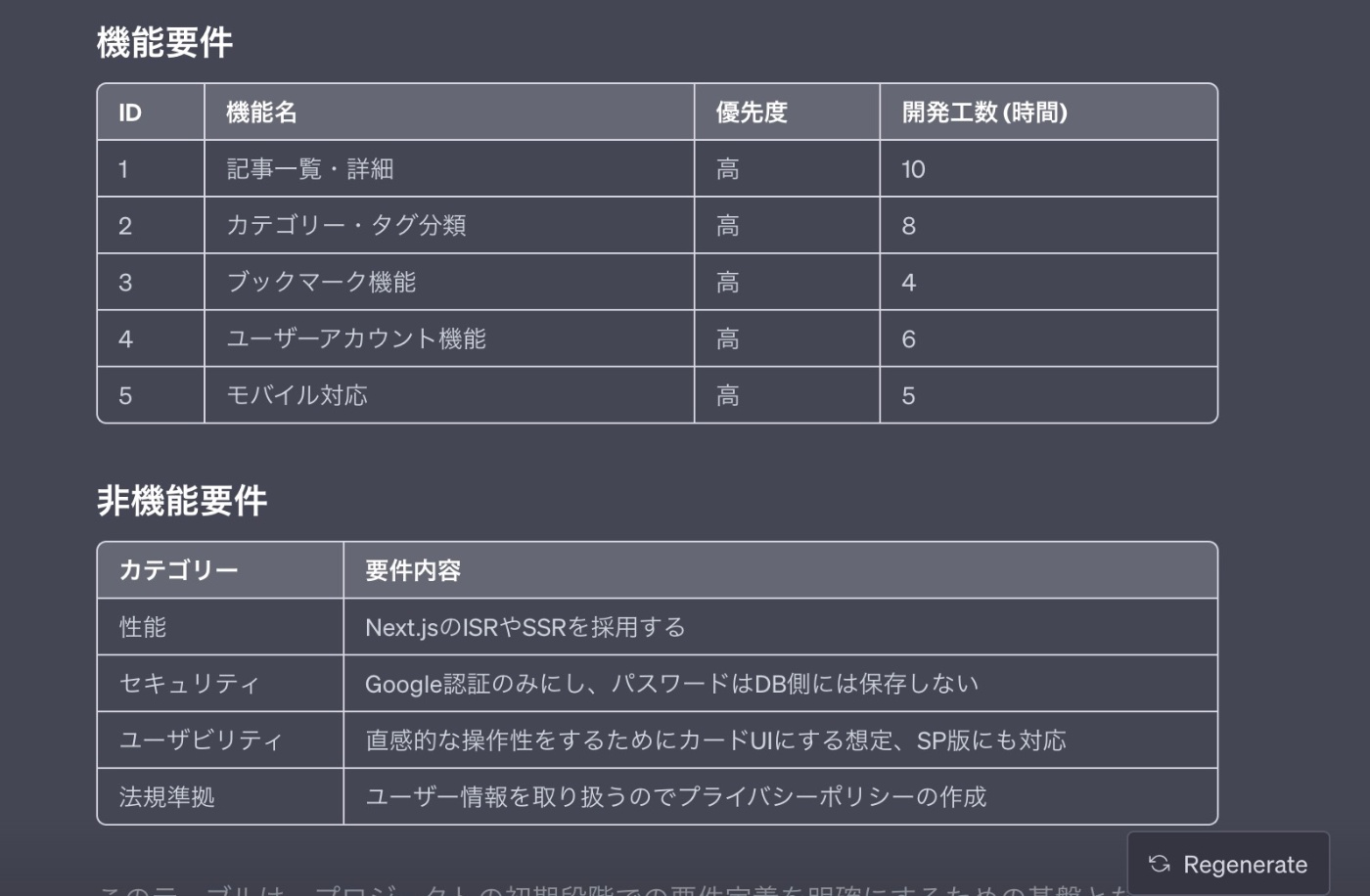
これで要件定義フェーズは完了です。
なお要件定義についてより詳しいやり方を学びたい人は下記の記事を参考にしてみてください。
設計
設計フェーズにおける成果物は下記を設定しました。
- データベース設計
- ER図
- API設計
- 画面設計
- 技術選定・システム構成
なお今回は1週間で開発するという前提条件があったので技術選定・システム構成に関してはChatGPTは使わず自分の得意な技術を選定しました。 (後述)
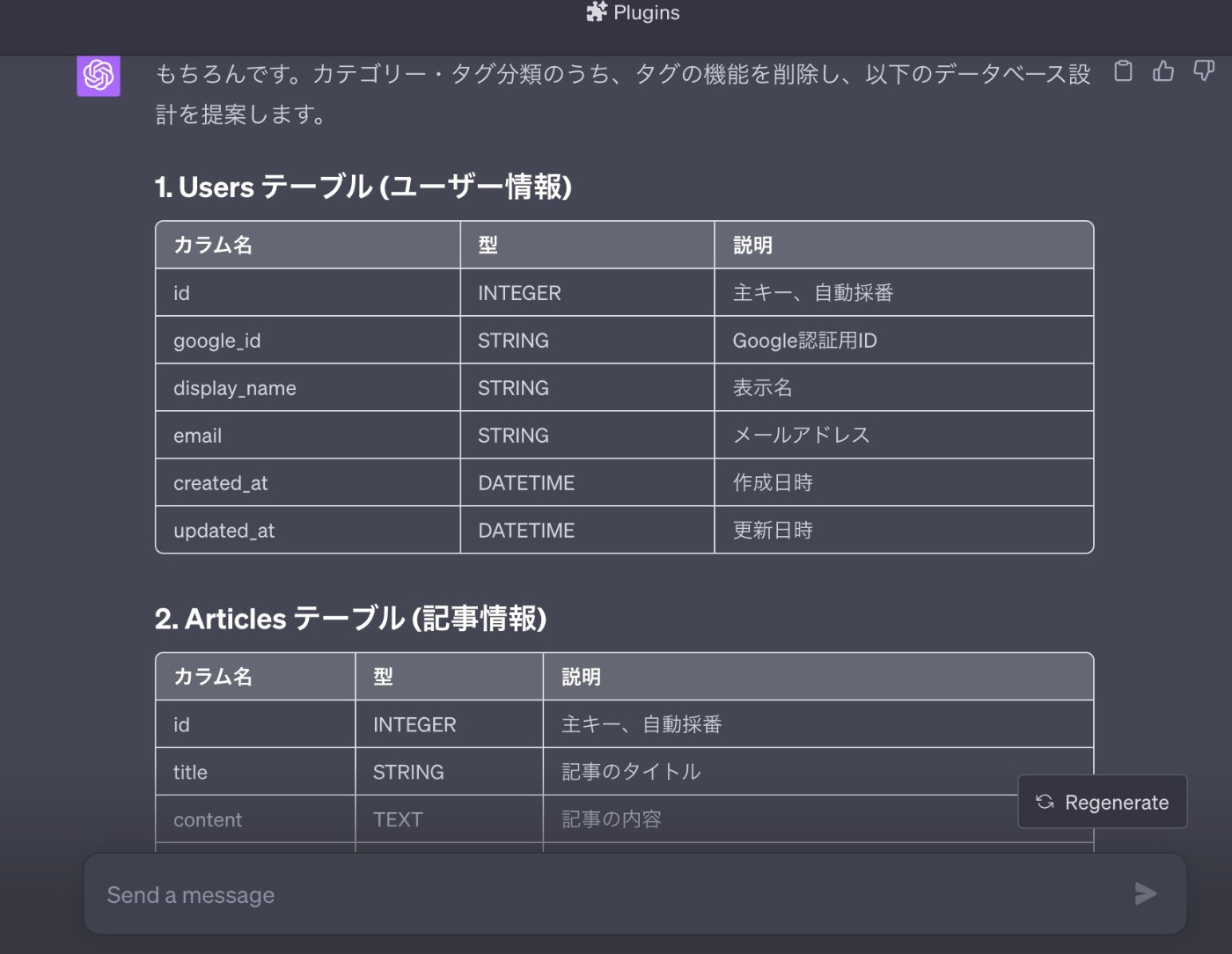
データベース設計
【プロンプト】
ありがとうございます。
次は設計フェーズです。
## 最終成果物として欲しいもの
- データベース設計・ER図
- 画面設計
## 最初の相談内容
まず初めに上記で洗い出した機能要件をもとにデータベース設計をしてください。
テーブル形式で各カラムとその型も出して欲しいです。
なお開発工数を考慮してタグの機能はなくしました

【回答】

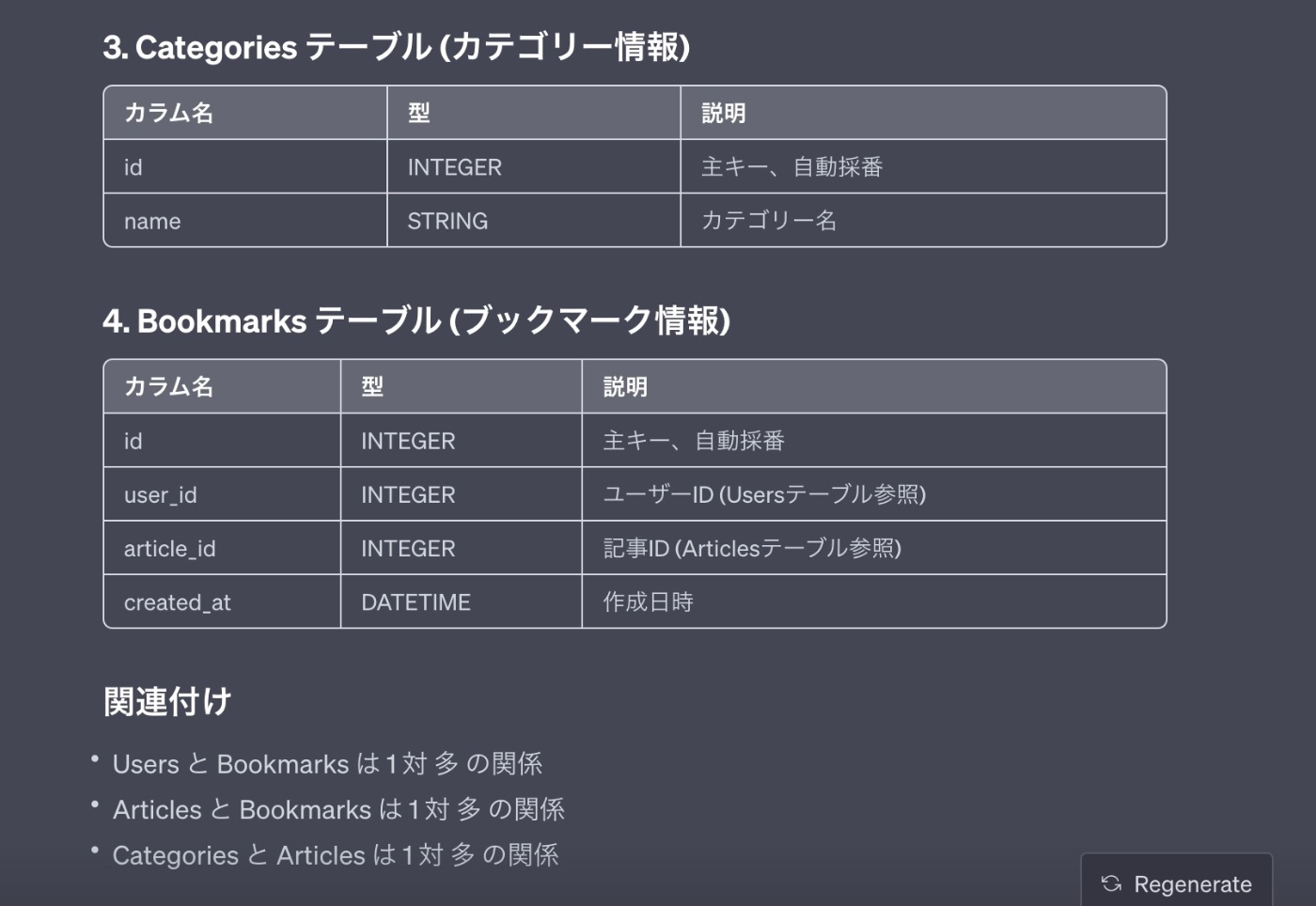
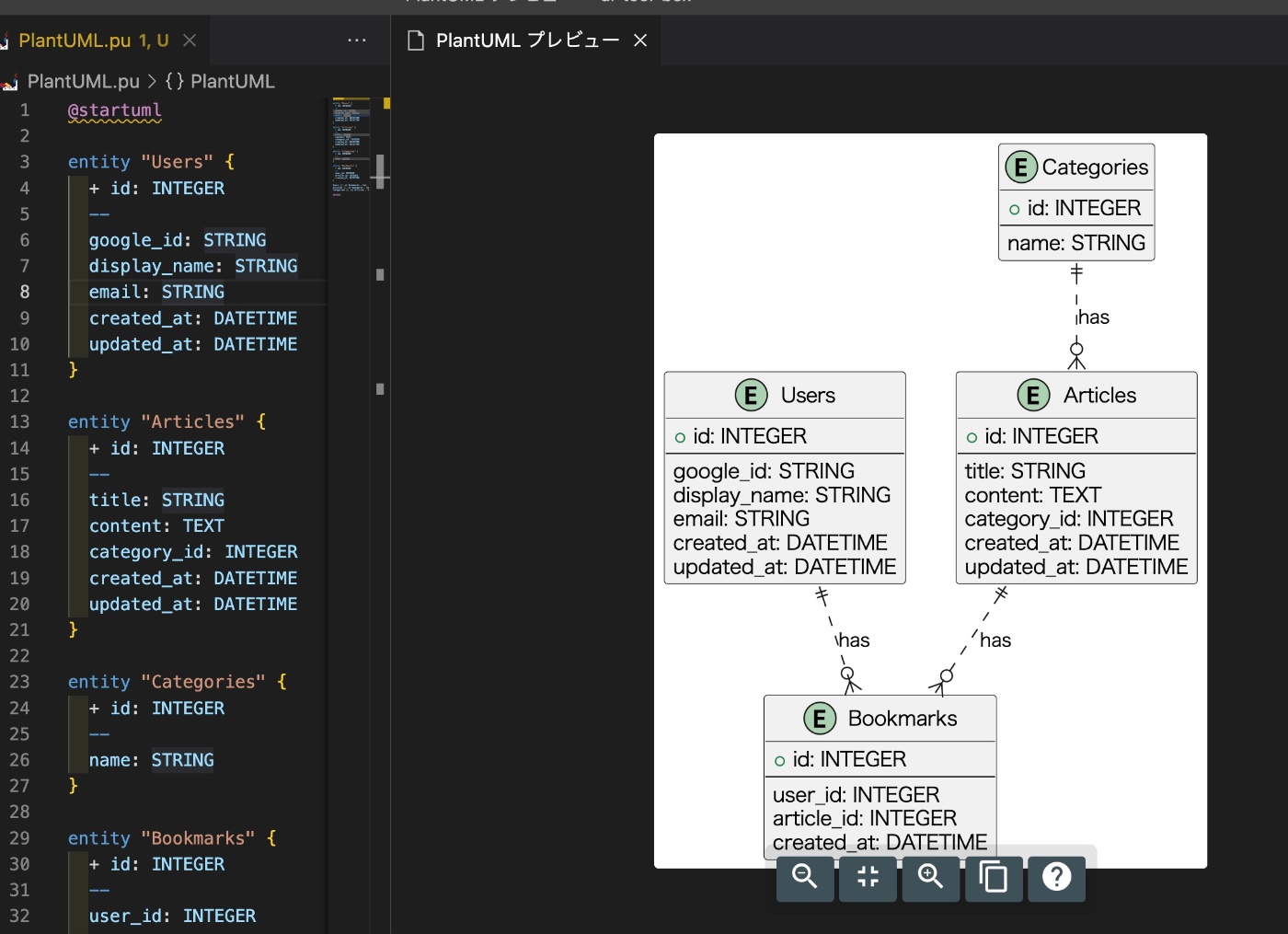
ER図
テーブル設計を元に各テーブルのリレーションを見やすくするためにER図を作成していきます。
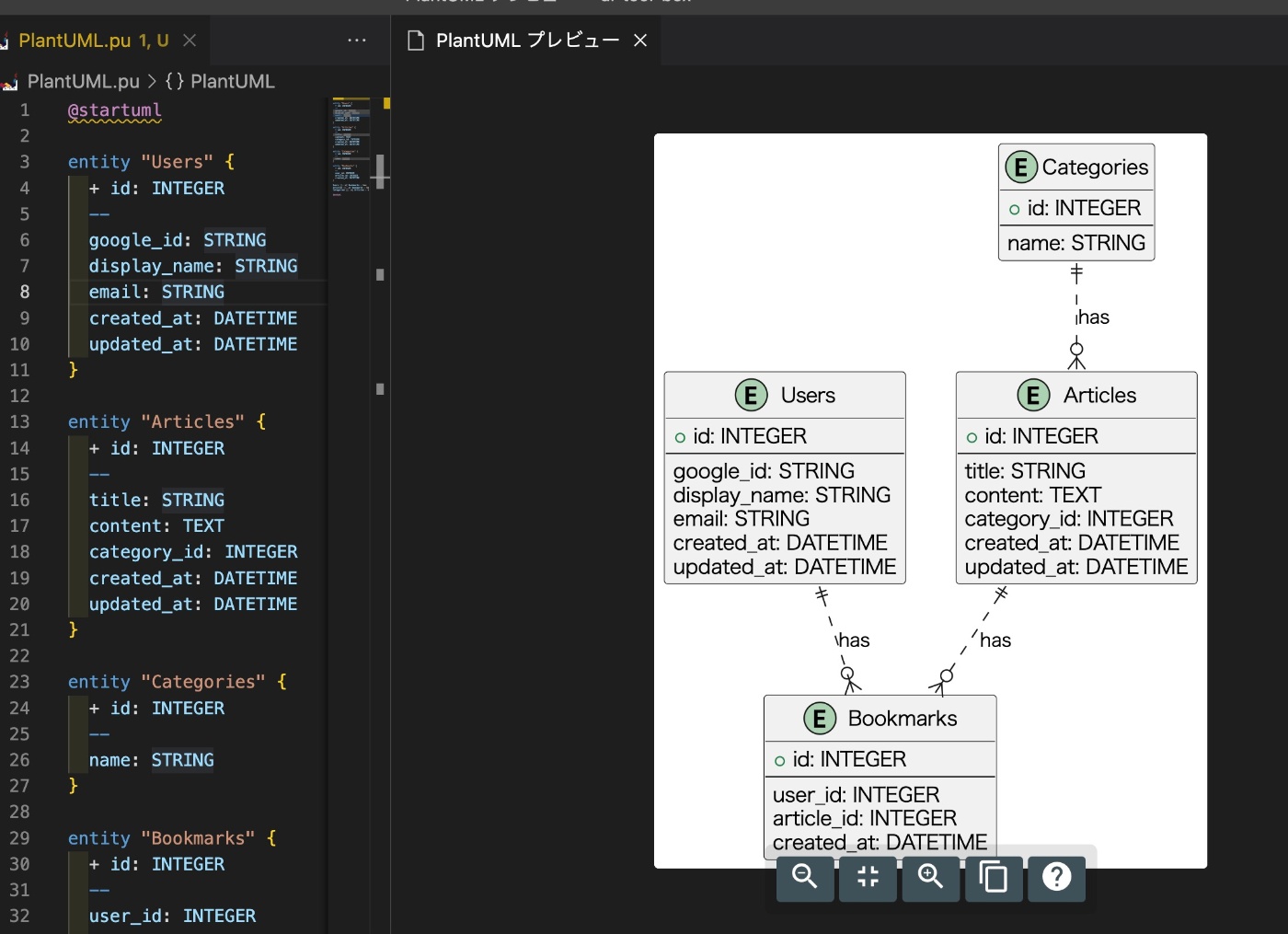
VsCodeでプレビューしやすいように、PlantUML形式で出力してもらいます。
【プロンプト】
上記のテーブルをER図を「PlantUML形式」で出力してください
【回答】
VSCodeを利用して下記のようにプレビューを確認することができます。
API設計
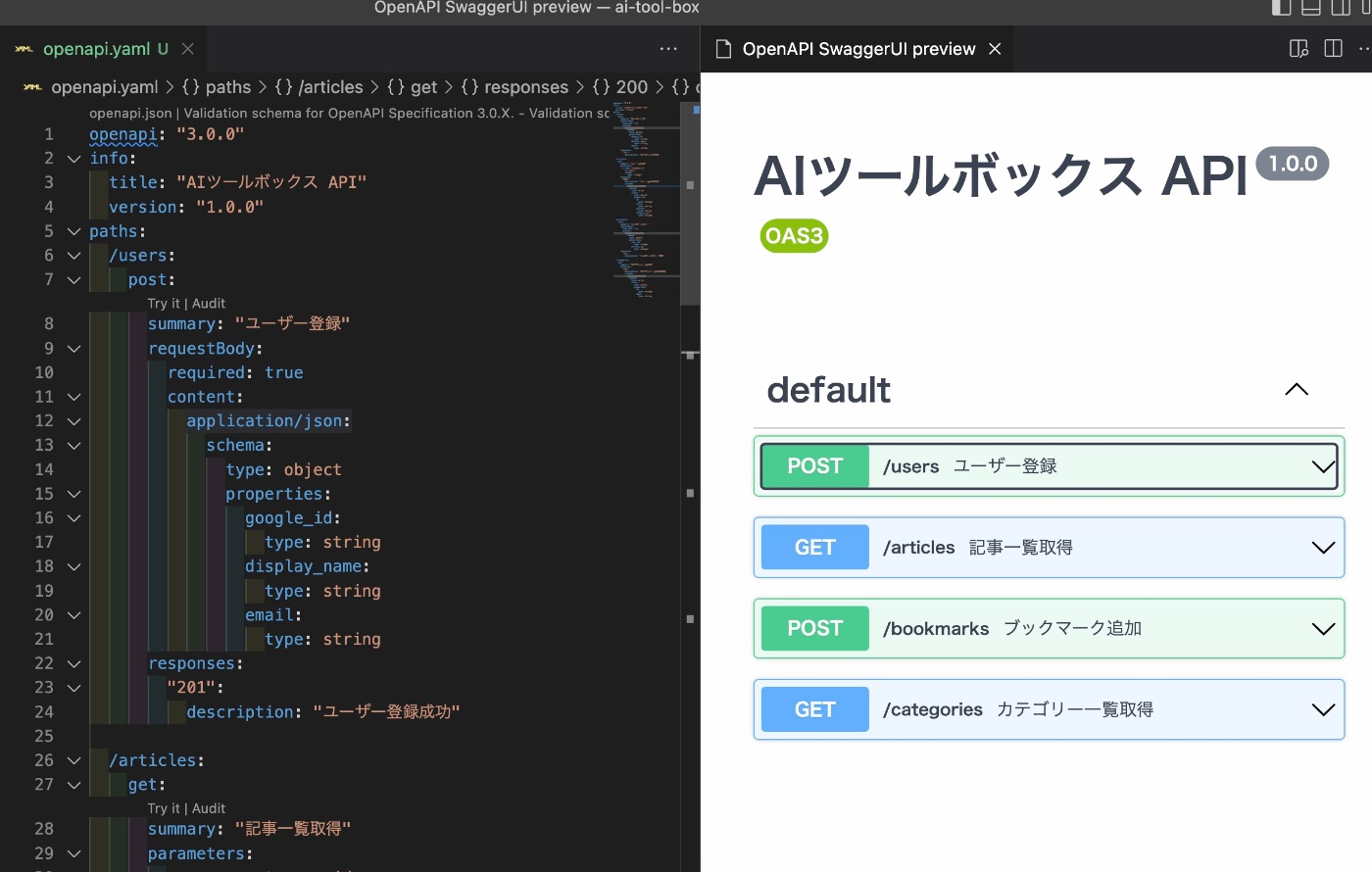
次にAPI設計書を作成します。
【プロンプト】
上記をもとに、API仕様書用のopenAPI.yamlを作成してください
【回答】
VSCodeを使って下記のようにプレビューをすることができます。
なお今回採用したOpenAPIやAPI設計については下記の記事を参考にしてみてください。
画面設計
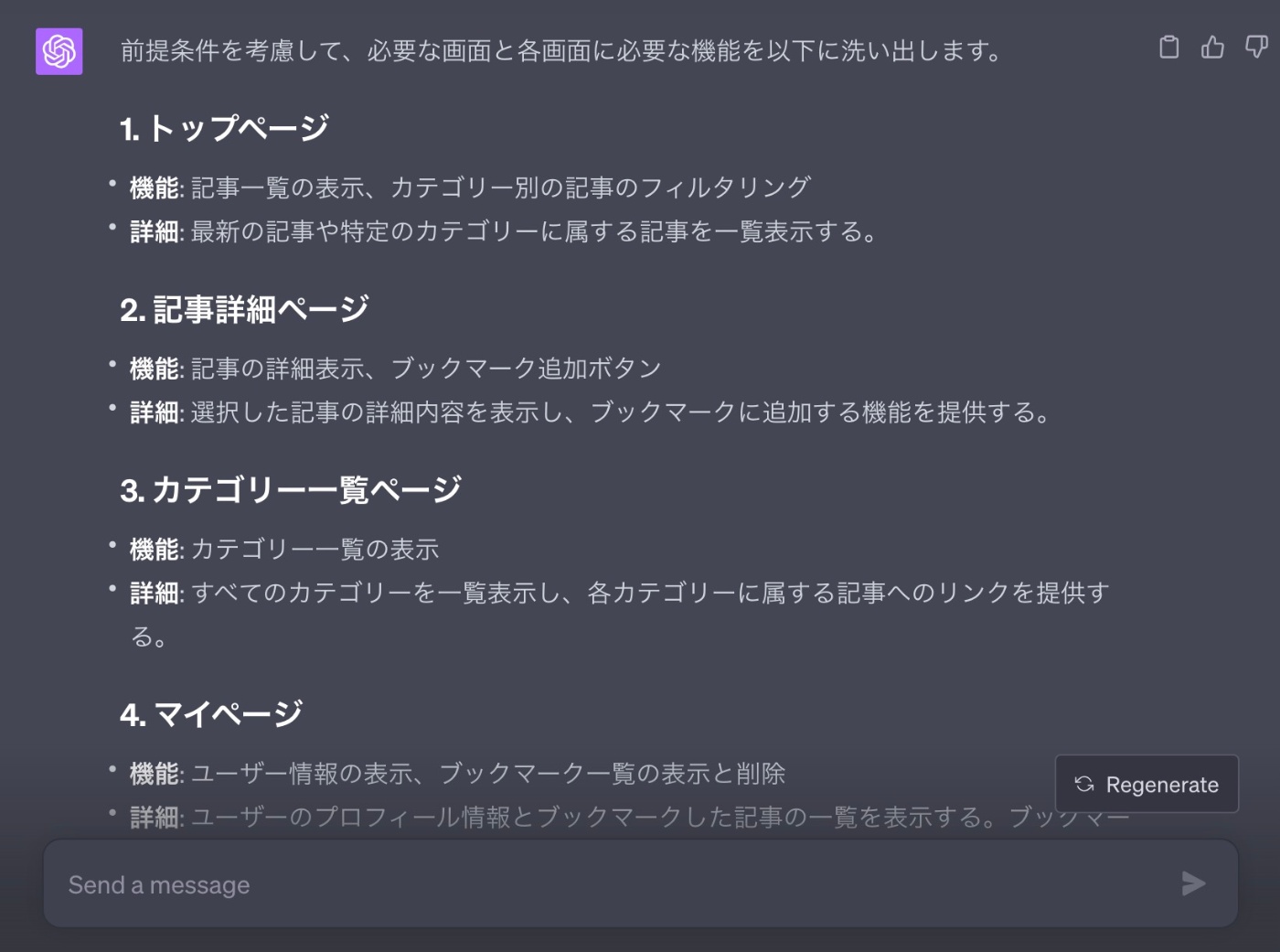
最後に画面設計を行います。
必要な画面とその画面の機能を洗い出してもらいます。
【プロンプト】
次に画面設計をするために、必要な画面と各画面に必要な機能を洗い出してください。
なお下記の前提を考慮してください
- 投稿画面は管理画面側で行い、投稿記事の削除と更新は画面ではできないものとする(DBから直接行う想定)
- 認証に関してはNext Authを利用するので画面は不要
- ブックマーク一覧を確認するためのマイページも作成する
【回答】


画面設計において、本来ならばこれを元にワイヤーフレームを作成しますが今回は割愛します。
成果物まとめ
設計フェーズで出した成果物をまとめます。
| テーブル設計 | ER図 |
|---|---|
 |
 |
| API仕様書 | 画面設計 |
|---|---|
 |
 |
技術選定・システム構成
技術選定・システム構成に関しては1週間で完成させる前提があるので自分の方で下記の構成で作成しました。
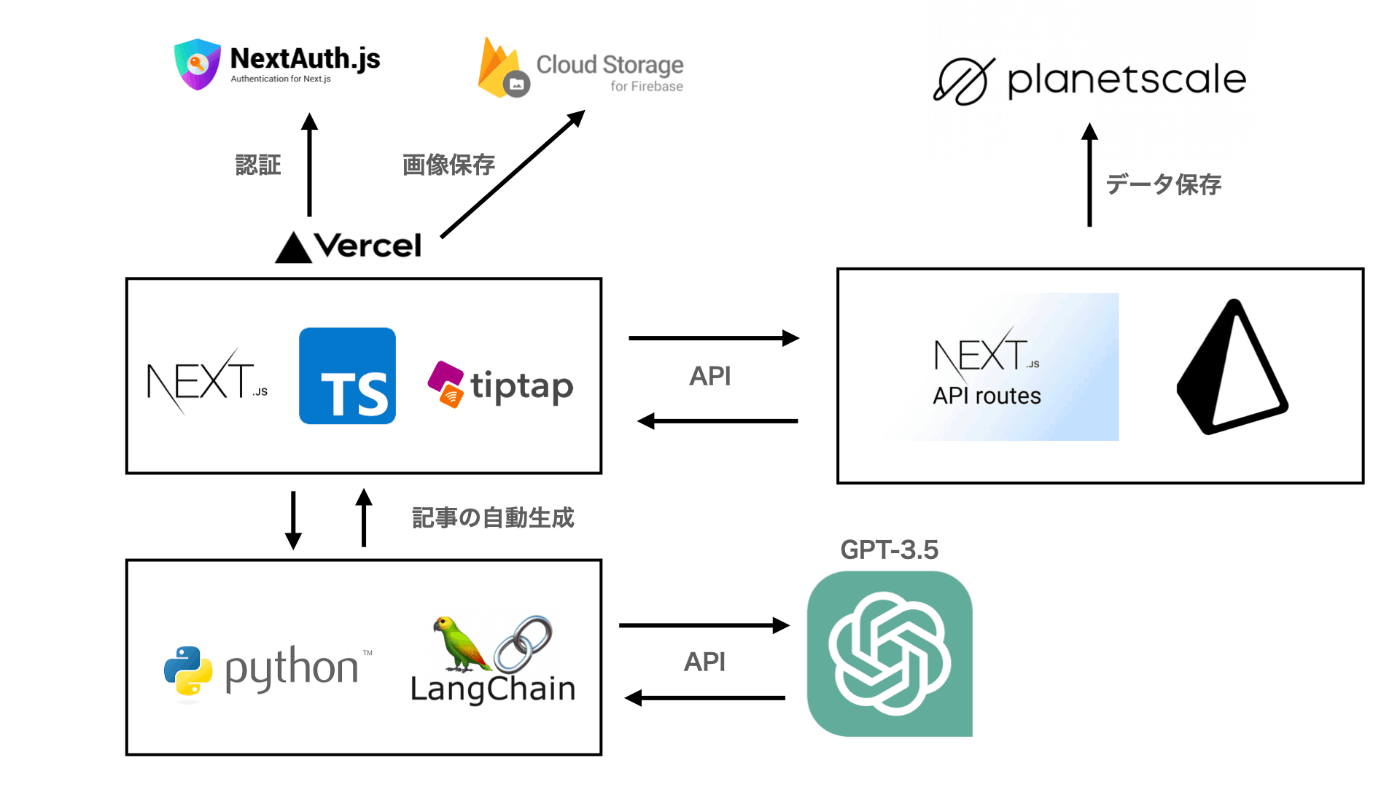
フロントエンド
- Next.js
- TypeScript
- tiptap
サーバーサイド(API)
記事の自動生成 (次の章で詳しく解説)
認証
画像保存
データベース
ホスティング
- Vercel
LangChainを使った機能追加
ここからはLangChainを利用して具体的に機能開発を行ってきます。
LangChainの概要
LangChainは、GPT-3のような大規模言語モデル(Large Language Model: LLM)を利用してサービスの開発をしたいときに便利に使えるライブラリです。
LangChainを利用することで、言語系モデルの機能拡張を効率的に行うことができます。
LangChainの機能
LangChainには下記の6つの機能があります。
- Models
- Prompt
- Indexes
- Chains
- Agents
- Memory
それぞれの機能の概要を説明していきます。
あくまで本記事ではLangChainを使うことを主題にしているので、LangChainに関するより詳しい説明は公式ドキュメントを参照していください。
Models
OpenAIをはじめとしたさまざまなサービスが提供しているモデルを簡単に切り替えたり、組み合わせたりすることができる。
LangChainでは下記の3つのモデルを利用できます。
- LLMs:
- GPT3.5のモデルであるtext-davinci-003等
- Chat Models
- ChatGPTで使われているgpt-3.5-turboやgpt-4
- Text Embedding Models
- 自然言語の文章を空間ベクトルに変換するモデル
今回の開発ではChat Modelsを利用します。(後述)
Prompt
Promptはプロンプトの管理や最適化、シリアル化をすることができる。
Promptは下記の3つの機能があります。
- Prompt Template:
- プロンプトをテンプレート化し、プログラミングによるプロンプトを生成する
- Example Selectors
- 大量の教師データからプロンプトに入力するデータを選択するための機能
- Output Parsers
- 出力のデータ形式を指定するための機能
今回の開発ではPrompt Templateを利用します。(後述)
Indexes
IndexesはPDFやURLなどの外部データを用いて回答を生成することができます。
Indexesは下記の4つの機能があります。
- Document Loaders
- PDFや外武URLなどのデータを読み込む
- Text Splitters
- 文章データを分割する
- Vectorstores
- ベクトル化されたデータを管理する
- Retrievers
- ドキュメント検索をする
Chains
Chainsを使うことで複数のプロンプト入力を実行することができます。
具体的には、Aというプロンプトの出力とBというプロンプトの出力の2つの出力を入力としたプロンプトを実行することができます。
Chainsには下記の3つの機能があります。
- Simple Chain
- 複数のchainを繋げていく上で最小単位となるChain
- Sequential Chain
- 複数のChainを繋げたChain
- Custom Chain
- 自由にChainを繋ぎ合わせることができるオリジナルのChain
Agents
Agentsは、言語モデルに渡されたツールを用いてモデル自体が次にどのようなアクションを取るかを決定、実行、観測し完了まで繰り返します。
Agentsには下記の4つの機能があります。
- Tools
- Agentというロボットが外界とやり取りをするための機能
- Agents
- プロンプトの内容に応じてツールを使い分け、自動で解法を生成してくれる
- Toolkits
- 特定のユースケースに応じて、ツールを初期搭載したAgentの機能
- Agent Executor
- Agentの行動を実行するための機能
Memory
MemoryはChainsやAgentsの内部における状態保持をする機能。
下記の3つの概念がある。
- Chat Message History
- Chatの履歴データを管理する
- Simple Memory
- Chain上で最初に設定できる共有メモリ機能
- Buffer Memory
- ChainsやAgents間で履歴データを共有するためのメモリ機能
今回採用した機能
上記で紹介した機能のうち、今回採用したのは下記の3つです。
- 様々な言語モデルを使える (Models)
- プロンプトをテンプレート化できる (Prompt)
- 少数の教師データを入れる (few-shot learning)
- PDFやURLなど外部データを使える (Indexes)
LangChainを利用した機能
AIツールのサービ紹介URLを入れてボタンを押すと、URL先のコンテンツを読み取り記事を自動生成してくれる機能を実装しました。
【URLを入力】
【URL先のコンテンツを解析】
【解析をしたデータを元に文章を生成】
Pythonの環境構築
Pythonの環境構築は本記事はされている前提です。
ターミナルを開いて下記のコマンドが実行できていれば大丈夫です。
python
環境構築がまだの人は下記を参考に進めてください。
完成コード
先に結論のコードです。
各コードの詳しい処理はこの後解説をしていきます。
# 環境変数やAPI
from fastapi import FastAPI
from pydantic import BaseModel
import os
from dotenv import load_dotenv
from urllib.parse import urlparse
# langchain
from langchain import PromptTemplate, FewShotPromptTemplate, OpenAI
from langchain.document_loaders import SeleniumURLLoader
# CORS対応のためのミドルウェアをインポート
from fastapi.middleware.cors import CORSMiddleware
# FastAPIのインスタンスを作成
app = FastAPI()
# CORSの設定を追加
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 環境変数の読み込み
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
model_name = "gpt-3.5-turbo" # モデル名を指定
# OpenAIのモデルを作成
llm = OpenAI(model_name=model_name, openai_api_key=openai_api_key)
# FewShotプロンプト準備 (開始)
## 教師データ
examples = [
{
"name": "Notion",
"feature": "- オールインワークスペース: ノート、タスク、データベース、カレンダーなどを1つのプラットフォームで提供。\n- カスタマイズ可能: ページの自由なデザインや、必要なブロックの追加が可能。\n- 協力作業: チームメンバーとの共同編集やコメント、タスクの割り当て機能を持つ。",
"examples": "- 知識ベースの作成: チームのナレッジやガイドラインを中央で管理。\n- タスク管理: プロジェクトのタスクや進捗をトラック。\n- 個人のノート取り: アイディアやリサーチのメモを整理。",
"target_audience": "プロジェクトマネージャー、デザイナー、エンジニア、学生、教育者など", # 対象者
"tool_description": "Notionは、ノート、タスク、データベースなどの機能を統合したオールインワンの作業スペースを提供するツールです。" # ツールの説明
},
]
## 教師データのフォーマット
tool_formatter_template = """
## ツール名
{name}
## 特徴
{feature}
## 使用例
{examples}
## 対象者
{target_audience}
## ツール説明
{tool_description}
"""
## PromptTemplateのインスタンスを作成
tool_prompt_template = PromptTemplate(
template=tool_formatter_template,
input_variables=["name", "feature", "examples", "target_audience", "tool_description"]
)
## FewShotPromptTemplateのインスタンスを作成
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=tool_prompt_template,
prefix="下記の出力形式を元に、",
suffix="下記のツール紹介文も同様にマークダウン形式かつ日本語で出力してください {input}",
input_variables=["input"],
example_separator="\n\n",
)
# FewShotプロンプト準備 (終了)
# リクエストで送られてきたURLの解析
## URLを受け取るためのクラスを定義
class UrlQuery(BaseModel):
url: str
## URLが有効かどうかをチェックする関数
def validate_url(url):
try:
result = urlparse(url)
return all([result.scheme, result.netloc])
except ValueError:
return False
## 指定されたURLのコンテンツを取得する関数
def get_content(url):
urls = [url]
try:
loader = SeleniumURLLoader(urls=urls)
data = loader.load()
return data
except Exception as e: # ここを修正
print(f"Error occurred: {e}")
return None
# URLを受け取り、その内容を要約するAPIエンドポイントを定義
@app.post("/generate-article")
def summarize(query: UrlQuery):
url = query.url
is_valid_url = validate_url(url)
if not is_valid_url:
return {"error": "Please input valid url"}
content = get_content(url)
if content:
prompt_text = few_shot_prompt.format(input=content)
print("==================")
print(prompt_text)
print("==================")
answer = llm.generate(prompts=[prompt_text])
return {"generate-article": answer.generations[0][0].text.strip()}
else:
return {"error": "something went wrong"}
下記のコマンドを実行します。
uvicorn generate_articles_few_shot:app --reload
※ 各モジュールはpipコマンドでインストールしてください
Postman等のAPIの実行を確認するツールを用いて下記のエンドポンとに対して、Bodyに文章を生成したいサービス紹介のURLを付与してPOSTリクエストを送ります。
http://127.0.0.1:8000/generate-article
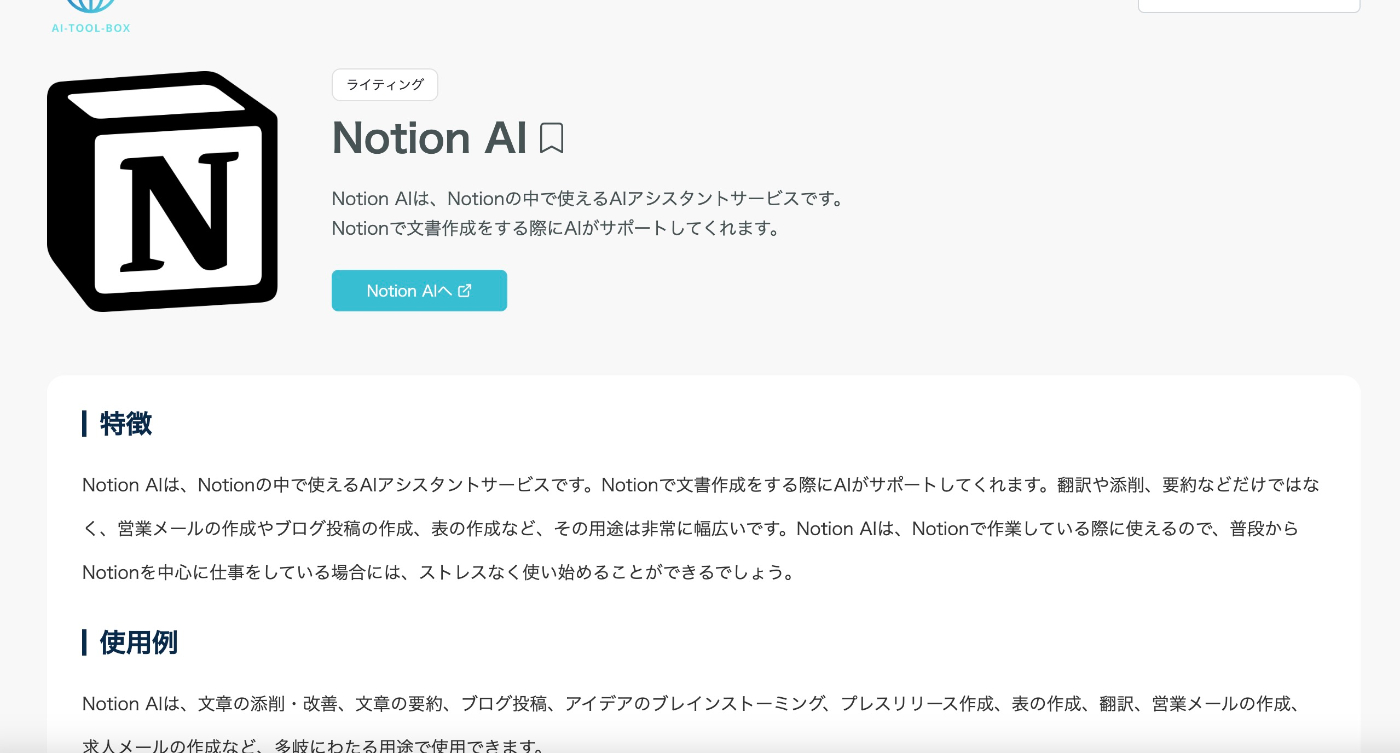
実際に実行すると下記のようにマークダウン形式のデータが返ってくることを確認できます。
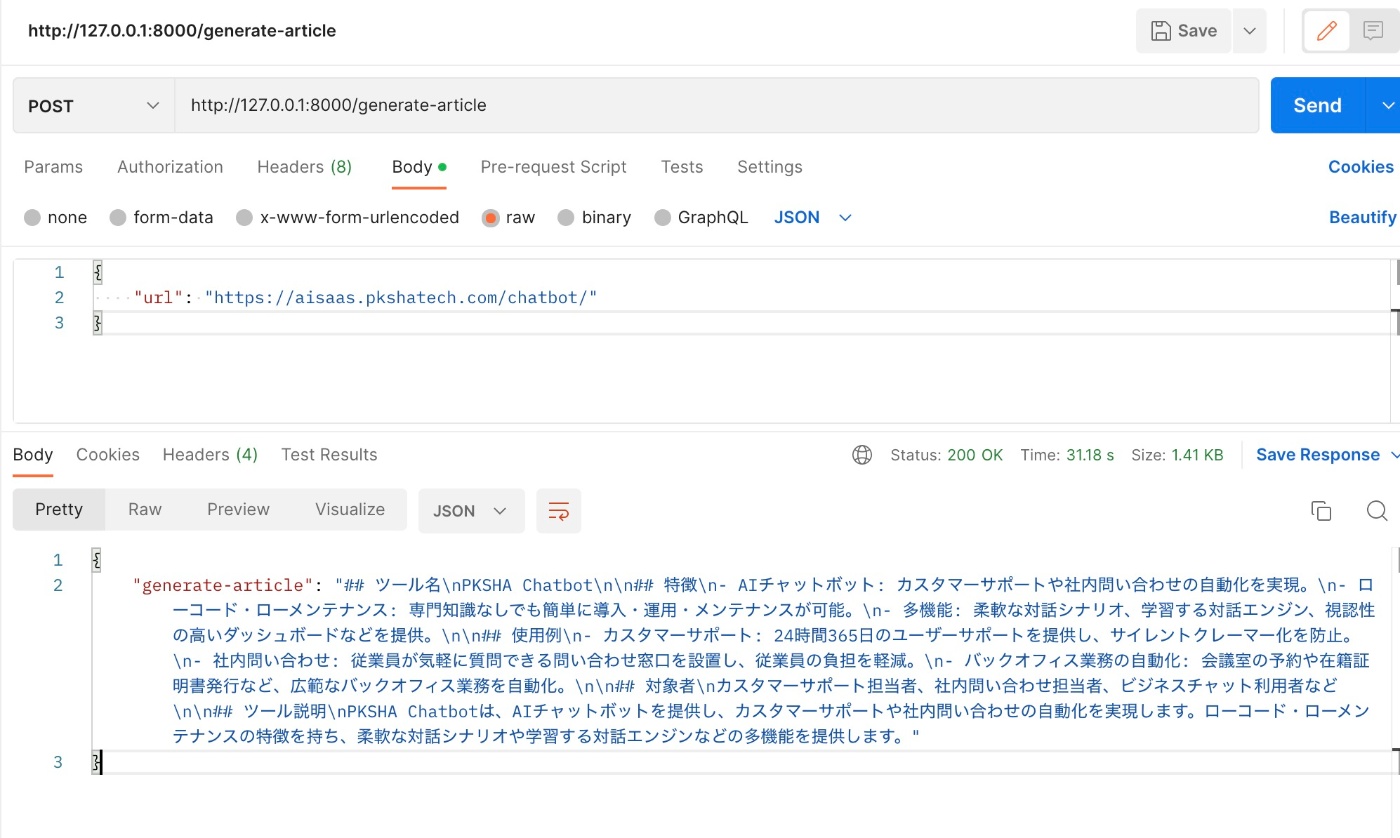
各コードの詳しい解説をしていきます。
必要モジュールのインポート
今回はAPIを利用したかったので、PythonのFastAPIを採用しています。
# 環境変数やAPI
from fastapi import FastAPI
from pydantic import BaseModel
import os
from dotenv import load_dotenv
from urllib.parse import urlparse
# langchain
from langchain import PromptTemplate, FewShotPromptTemplate, OpenAI
from langchain.document_loaders import SeleniumURLLoader
# CORS対応のためのミドルウェアをインポート
from fastapi.middleware.cors import CORSMiddleware
FastAPIの準備とCROSの設定
一旦CROSでは全てのリクエストを許可する設定にしています。本番環境等に公開する場合は随時設定を変更していください。
# FastAPIのインスタンスを作成
app = FastAPI()
# CORSの設定を追加
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
環境変数の管理とmodelの呼び出し
.envにOpenAIから取得したAPIキーを格納します。(自分で取得して入れてください)
OPENAI_API_KEY="xxxxxxx"
その上で環境変数からAPIキーを読み取り、OpenAIインスタンスを作成します。
# 環境変数の読み込み
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
model_name = "gpt-3.5-turbo" # モデル名を指定
# OpenAIのモデルを作成
llm = OpenAI(model_name=model_name, openai_api_key=openai_api_key)
プロンプトテンプレートを作成
最初に簡単な例を用いてテンプレートを解説します。
下記のようなにPromptTemplateを記述することで引数で渡ってきた料理名を元に、用意したテンプレート通りの回答をしてくれます。
カレーと入力するだけ下記のフォーマットに沿って回答を生成してくれます。
- 概要
- 材料
- 手順
- ワンポイン
使い方としてはtemplate を用意し、LangChainのPromptTemplateに引数として渡すだけで利用できます。
from langchain import PromptTemplate
from langchain.llms import OpenAI
from langchain import LLMChain
from fastapi import FastAPI
from langchain import PromptTemplate, OpenAI, LLMChain
app = FastAPI() # FastAPIのインスタンスを作成
# OpenAIのモデルのインスタンスを作成
llm = OpenAI(model_name="text-davinci-003", openai_api_key="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")
# プロンプトのテンプレート文章を定義
template = """
次の料理のレシピを「## 概要」「## 材料」「## 手順」「## ワンポイント」でまとめてください
{sentences_before_check}
"""
# テンプレート文章にあるチェック対象の単語を変数化
prompt = PromptTemplate(
input_variables=["sentences_before_check"],
template=template,
)
# OpenAIのAPIにこのプロンプトを送信するためのチェーンを作成
chain = LLMChain(llm=llm, prompt=prompt,verbose=True)
# チェーンを実行し、結果を表示
print(chain("カレー"))
実際に処理を実行してみます。
uvicorn lang01:app --reload

これと同様に今回生成する記事も下記のようなフォーマットにしたいのでプロンプトテンプレートを利用しました。
- ツール名
- 特徴
- 使用例
- 対象者
- ツール説明
プロンプトテンプレートを用意
# FewShotプロンプト準備 (開始)
## 教師データ
examples = [
{
"name": "Notion",
"feature": "- オールインワークスペース: ノート、タスク、データベース、カレンダーなどを1つのプラットフォームで提供。\n- カスタマイズ可能: ページの自由なデザインや、必要なブロックの追加が可能。\n- 協力作業: チームメンバーとの共同編集やコメント、タスクの割り当て機能を持つ。",
"examples": "- 知識ベースの作成: チームのナレッジやガイドラインを中央で管理。\n- タスク管理: プロジェクトのタスクや進捗をトラック。\n- 個人のノート取り: アイディアやリサーチのメモを整理。",
"target_audience": "プロジェクトマネージャー、デザイナー、エンジニア、学生、教育者など", # 対象者
"tool_description": "Notionは、ノート、タスク、データベースなどの機能を統合したオールインワンの作業スペースを提供するツールです。" # ツールの説明
},
]
## 教師データのフォーマット
tool_formatter_template = """
## ツール名
{name}
## 特徴
{feature}
## 使用例
{examples}
## 対象者
{target_audience}
## ツール説明
{tool_description}
"""
プロンプトテンプレートとFewShotPromptに引数として作成したデータを渡す。
## PromptTemplateのインスタンスを作成
tool_prompt_template = PromptTemplate(
template=tool_formatter_template,
input_variables=["name", "feature", "examples", "target_audience", "tool_description"]
)
## FewShotPromptTemplateのインスタンスを作成
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=tool_prompt_template,
prefix="下記の出力形式を元に、",
suffix="下記のツール紹介文も同様にマークダウン形式かつ日本語で出力してください {input}",
input_variables=["input"],
example_separator="\n\n",
)
# FewShotプロンプト準備 (終了)
実際に作成されているプロンプトをprintを利用して確認してみます。
print("==================")
print(prompt_text)
print("==================")

URLの先のコンテンツの読み取り
langchain.document_loaders``のSeleniumURLLoader``を利用してコンテンツを取得します。
SeleniumURLLoaderの引数にurlを渡すだけで、簡単にコンテンツを取得することができます。
## URLを受け取るためのクラスを定義
class UrlQuery(BaseModel):
url: str
## URLが有効かどうかをチェックする関数
def validate_url(url):
try:
result = urlparse(url)
return all([result.scheme, result.netloc])
except ValueError:
return False
## 指定されたURLのコンテンツを取得する関数
def get_content(url):
urls = [url]
try:
loader = SeleniumURLLoader(urls=urls)
data = loader.load()
return data
except Exception as e: # ここを修正
print(f"Error occurred: {e}")
return None

エンドポイントを作成し処理をまとめる
今まで作成してきた処理をまとめて、対象のURL付きのリクエストを投げると処理が実行されるようにします。
# URLを受け取り、その内容を要約するAPIエンドポイントを定義
@app.post("/generate-article")
def summarize(query: UrlQuery):
url = query.url
is_valid_url = validate_url(url)
if not is_valid_url:
return {"error": "Please input valid url"}
# URL先のコンテンツ取得
content = get_content(url)
if content:
# プロンプトテンプレートの中に取得したURL先のコンテンツを格納する
prompt_text = few_shot_prompt.format(input=content)
# プロンプトの確認用
print("==================")
print(prompt_text)
print("==================")
answer = llm.generate(prompts=[prompt_text])
return {"generate-article": answer.generations[0][0].text.strip()}
else:
return {"error": "something went wrong"}
完成コード
改めて完成コードです。
# 環境変数やAPI
from fastapi import FastAPI
from pydantic import BaseModel
import os
from dotenv import load_dotenv
from urllib.parse import urlparse
# langchain
from langchain import PromptTemplate, FewShotPromptTemplate, OpenAI
from langchain.document_loaders import SeleniumURLLoader
# CORS対応のためのミドルウェアをインポート
from fastapi.middleware.cors import CORSMiddleware
# FastAPIのインスタンスを作成
app = FastAPI()
# CORSの設定を追加
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 環境変数の読み込み
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
model_name = "gpt-3.5-turbo" # モデル名を指定
# OpenAIのモデルを作成
llm = OpenAI(model_name=model_name, openai_api_key=openai_api_key)
# FewShotプロンプト準備 (開始)
## 教師データ
examples = [
{
"name": "Notion",
"feature": "- オールインワークスペース: ノート、タスク、データベース、カレンダーなどを1つのプラットフォームで提供。\n- カスタマイズ可能: ページの自由なデザインや、必要なブロックの追加が可能。\n- 協力作業: チームメンバーとの共同編集やコメント、タスクの割り当て機能を持つ。",
"examples": "- 知識ベースの作成: チームのナレッジやガイドラインを中央で管理。\n- タスク管理: プロジェクトのタスクや進捗をトラック。\n- 個人のノート取り: アイディアやリサーチのメモを整理。",
"target_audience": "プロジェクトマネージャー、デザイナー、エンジニア、学生、教育者など", # 対象者
"tool_description": "Notionは、ノート、タスク、データベースなどの機能を統合したオールインワンの作業スペースを提供するツールです。" # ツールの説明
},
]
## 教師データのフォーマット
tool_formatter_template = """
## ツール名
{name}
## 特徴
{feature}
## 使用例
{examples}
## 対象者
{target_audience}
## ツール説明
{tool_description}
"""
## PromptTemplateのインスタンスを作成
tool_prompt_template = PromptTemplate(
template=tool_formatter_template,
input_variables=["name", "feature", "examples", "target_audience", "tool_description"]
)
## FewShotPromptTemplateのインスタンスを作成
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=tool_prompt_template,
prefix="下記の出力形式を元に、",
suffix="下記のツール紹介文も同様にマークダウン形式かつ日本語で出力してください {input}",
input_variables=["input"],
example_separator="\n\n",
)
# FewShotプロンプト準備 (終了)
# リクエストで送られてきたURLの解析
## URLを受け取るためのクラスを定義
class UrlQuery(BaseModel):
url: str
## URLが有効かどうかをチェックする関数
def validate_url(url):
try:
result = urlparse(url)
return all([result.scheme, result.netloc])
except ValueError:
return False
## 指定されたURLのコンテンツを取得する関数
def get_content(url):
urls = [url]
try:
loader = SeleniumURLLoader(urls=urls)
data = loader.load()
return data
except Exception as e: # ここを修正
print(f"Error occurred: {e}")
return None
# URLを受け取り、その内容を要約するAPIエンドポイントを定義
@app.post("/generate-article")
def summarize(query: UrlQuery):
url = query.url
is_valid_url = validate_url(url)
if not is_valid_url:
return {"error": "Please input valid url"}
content = get_content(url)
if content:
prompt_text = few_shot_prompt.format(input=content)
print("==================")
print(prompt_text)
print("==================")
answer = llm.generate(prompts=[prompt_text])
return {"generate-article": answer.generations[0][0].text.strip()}
else:
return {"error": "something went wrong"}
最後に
今回はChatGPTを使った開発アシスタントのやり方とLangChainを利用した記事の自動生成の方法を解説しました。
あくまで今回紹介したLangChainの機能はごく一部なので、公式ドキュメントを元に色々試してみてください。
公式ドキュメントはサンプルコードが掲載されているので学習もしやすいです。
他にも色々な記事を書いているので読んでいただけると嬉しいです。
Discussion