麻雀AIをさらに勉強してみた。



ニューラルネットワークの入出力
読み解いてみたところ、「自分の手牌から、自分の手牌が何の役になっているかを判定する。」
というAIでした。
結論
- 入力:自分の今の手牌
- 出力:今の手配の役
要するに。自分があがったときに「この役だよ!」ということを教えてくれるだけですね笑。それでも自分からしたらすごいです。
自分が想定したいのは、自分の手配から、どんな役になるかを予測するAIでした。
さらに、役は不定形も多いので、判定しやすい形だけ、かつ門前役(鳴かないであがる)は抜いた役に絞って判定しています。そのため、元の記事ではかなりの正答率を誇っています。
知らない人向け簡単な麻雀解説
麻雀は1〜9の萬子(🀇🀈🀉🀊🀋🀌🀍🀎🀏)、索子(🀐🀑🀒🀓🀔🀕🀖🀗🀘)、筒子(🀙🀚🀛🀜🀝🀞🀟🀠🀡)の数牌と東南西北(🀀🀁🀂🀃)、白中發(🀄🀅🀆)の字牌が4つずつあり、14個の自分のランダム牌から、一個山から拾って、一個捨てるを順番に繰り返して、できた役の点数で勝敗を決めるゲームである。
役は、3つで1セット(面子)を4個作り、2個同じ絵柄を1セット(頭、対子ともいう)を作って上がれます。
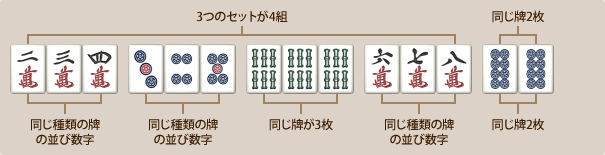
ちなみに
面子の種類は
- 順子(シュンツ)
- 萬子の1、2、3(🀇🀈🀉)ような順番に揃えること。
- 同じ種類でないといけない。
- 刻子(コーツ)
- 筒子の5、5、5(🀝🀝🀝)のような同じ数字で揃えること。
- 同じ種類でないといけない。
- また、字牌は3つ揃えるとき、これしかできない。(🀀🀁🀂🀃🀄🀅🀆)
- 槓子(カンツ)
- 索子の4、4、4、4(🀓🀓🀓🀓)のように4つ揃えること。
- これをすると新たに、山から一個ひける+ランダムボーナス(ドラ)が一個新たに出現する。
鳴きという概念もありますが、今回はメインで使うことはないので、省力します。
今回指定する役
麻雀の役は通常ルールで45種類あります。
この中で、形が決まって役17役に絞っています。
判定できるように学習させる役は、
利用する役
yakuuse_str = [
# //// 一飜
"断幺九",
"役牌 白","役牌 發","役牌 中",
# //// 二飜
"混全帯幺九","一気通貫","三色同順",
"三色同刻","三槓子","対々和","三暗刻","小三元","混老頭",
# //// 三飜
"二盃口","純全帯幺九","混一色",
# //// 六飜
"清一色",]
以下に、指定された役の具体例を示します。
一飜
-
断幺九
- 例: 🀈🀉🀊 🀒🀓🀔 🀕🀖🀗 🀛🀜🀝 🀁🀁
- 条件: 萬子、筒子、索子で1と9を含まない。
-
役牌 白
- 例: 🀇🀈🀉 🀋🀌🀍 🀎🀎🀎 🀆🀆🀆 🀃🀃
- 条件:何も書いてない字牌「白」を3枚揃える。
-
役牌 發
- 例: 🀍🀍🀍 🀛🀜🀝 🀟🀠🀡 🀅🀅🀅 🀇🀇
- 条件: 読みづらい漢字字牌「發」を3枚揃える。
-
役牌 中
- 例: 🀋🀌🀍 🀛🀜🀝 🀟🀠🀡 🀄🀄🀄 🀈🀈
- 条件: 字牌で唯一読める漢字「中」を3枚揃える。
二飜
-
混全帯幺九
- 例: 🀇🀈🀉 🀏🀏🀏 🀟🀠🀡 🀂🀂🀂 🀄🀄
- 条件: 面子で1と9を含んだおよび字牌だけで揃える。
-
一気通貫
- 例: 🀇🀈🀉 🀊🀋🀌 🀍🀎🀏 🀛🀜🀝 🀂🀂
- 条件: 萬子、筒子、索子の1種類で1から9までの順子で揃える。
-
三色同順
- 例: 🀇🀈🀉 🀙🀚🀛 🀐🀑🀒 🀖🀖🀖 🀅🀅
- 条件: 萬子、筒子、索子の各種で同じ数字の順子を揃える。
-
三色同刻
- 例: 🀋🀋🀋 🀝🀝🀝 🀔🀔🀔 🀖🀗🀘 🀀🀀
- 条件: 萬子、筒子、索子で同じ数字の刻子を揃える。
-
三槓子
- 例: 🀇🀇🀇🀇 🀌🀌🀌🀌 🀍🀎🀏 🀑🀑🀑🀑 🀅🀅
- 条件: どの牌でもいいので、3つの槓子を揃える。
-
対々和
- 例: 🀇🀇🀇 🀋🀋🀋 🀎🀎🀎 🀛🀛🀛 🀄🀄
- 条件: 鳴いていいので、全て刻子で構成。
-
三暗刻
- 例: 🀇🀇🀇 🀋🀋🀋 🀛🀛🀛 🀞🀟🀠 🀅🀅
- 条件: 自分で山から引いた牌だけで3つの暗刻を揃える。
-
小三元
- 例: 🀇🀈🀉 🀓🀔🀕 🀄🀄🀄 🀅🀅🀅 🀆🀆
- 条件: 中、發、白のうち2つを刻子、1つを対子で揃える。
-
混老頭
- 例: 🀇🀇🀇 🀏🀏🀏 🀐🀐🀐 🀀🀀🀀 🀄🀄
- 条件: 萬子、筒子、索子どれでもいいので1と9および字牌だけで揃える。
三飜
-
二盃口
- 例: 🀋🀋🀌🀌🀍🀍 🀚🀚🀛🀛🀜🀜 🀁🀁
- 条件: 同じ順子のセットを2組揃える。
-
純全帯幺九
- 例: 🀇🀇🀇 🀍🀎🀏 🀐🀑🀒 🀡🀡🀡 🀙🀙
- 条件: 萬子、筒子、索子どれでもいいので全ての面子と対子を1と9が関連した刻子、順子だけで揃える。
-
混一色
- 例: 🀇🀇🀇 🀈🀉🀊 🀌🀍🀎 🀀🀀🀀 🀁🀁
- 条件: 同じ種類の牌だけで構成。
六飜
-
清一色
- 例: 🀇🀇🀇 🀈🀉🀊 🀋🀋🀋 🀌🀍🀎 🀎🀎
- 条件: 同じ色の数牌だけで構成。
データの形式
最終目標は、「手配の役が何なのか把握すること」です。ので、そのためのデータを抜き出す準備をします。
AGARIデータの読み込み
天鳳xmlデータからAGARIデータだけを抽出
folder_path = "/content/tenho_2019/2019/"
files = os.listdir(folder_path)
agari_df = pd.DataFrame()
for file in tqdm.tqdm(files):
test = ET.parse(os.path.join(folder_path, file))
root = test.getroot()
for child in root:
if child.tag=="AGARI":
agari = pd.DataFrame(data = child.attrib, index=[0])
agari_df = pd.concat([agari_df, agari], ignore_index=True)
天鳳の読み込んだデータの中身はxmlファイルになっています。
詳しくは、下記のようになっています。
この中のAGARIタグの要素だけを抽出してきます。そうすると、最初5行の要素は以下のようになります。
| ba | hai | m | machi | ten | yaku | doraHai | who | fromWho | sc | doraHaiUra | owari | yakuman | paoWho | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0,0 | 55,59,61,74,75,104,105,106,132,133,135 | 52263 | 135 | 40,2000,0 | 20,1 | 79 | 0 | 2 | 250,20,250,0,250,-20,250,0 | NaN | NaN | NaN | NaN |
| 1 | 1,2 | 1,2,24,31,34,60,61,62,85,89,95,98,103,107 | NaN | 107 | 30,4000,0 | 1,1,0,1,53,1 | 115 | 3 | 3 | 260,-21,250,-11,230,-11,240,63 | 102 | NaN | NaN | NaN |
| 2 | 0,0 | 38,40,47,75,77,83,128,129,132,133,134 | 11849 | 47 | 40,1500,0 | 20,1 | 118 | 3 | 3 | 239,-4,239,-7,219,-4,303,15 | NaN | NaN | NaN | NaN |
| 3 | 0,1 | 8,9,11,36,37,38,112,113,114,124,126 | 40490 | 114 | 50,8000,1 | 29,2,28,2 | 49 | 1 | 1 | 225,-20,232,90,215,-40,318,-20 | NaN | NaN | NaN | NaN |
| 4 | 0,1 | 19,22,27,60,66,68,74,78,81,96,101,107,113,114 | NaN | 107 | 40,1300,0 | 1,1,53,0 | 44 | 0 | 2 | 195,23,322,0,175,-13,298,0 | 88 | NaN | NaN | NaN |
この情報だけではわかりづらいため、わかりやすいようにデータを整形していきます。
約数と翻数表示
合計半数を抽出します。
例
| ba | hai | m | machi | ten | yaku | doraHai | who | fromWho | sc | doraHaiUra | owari | yakuman | paoWho | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0,0 | 55,59,61,74,75,104,105,106,132,133,135 | 52263 | 135 | 40,2000,0 | 20,1 | 79 | 0 | 2 | 250,20,250,0,250,-20,250,0 | NaN | NaN | NaN | NaN |
| 1 | 1,2 | 1,2,24,31,34,60,61,62,85,89,95,98,103,107 | NaN | 107 | 30,4000,0 | 1,1,0,1,53,1 | 115 | 3 | 3 | 260,-21,250,-11,230,-11,240,63 | 102 | NaN | NaN | NaN |
yaku_append :約数と翻数表示
def yaku_append(x):
han = 0
yaku_normal = x[0].split(",")
yakulist_normal = []
if len(yaku_normal) > 1:
yaku_normal = [yaku_normal[i:i + 2] for i in range(0, len(yaku_normal), 2)]
yakulist_normal = [i[0] for i in yaku_normal if i[1]!=0]
han = sum([int(i[1]) for i in yaku_normal if i[1]!=0])
yakulist = yakulist_normal + x[1].split(",")
yakulist = [int(i) for i in yakulist if i!="nan"]
return yakulist, han
このリストのyakuは、[20,1]と書いてあります。上記のリンクから、詳しくみると、21目の「""役牌 中""」で「一翻」ですよ。というふうに読み取れます。
1番目の列のyakuは、[1,1,0,1,53,1]と書いてあります。上記のリンクから、詳しくみると、1番目の「""立直""」で「一翻」、0番目の「""門前清自摸和""」で「一翻」、53番目の「""裏ドラ""」で「一翻」、ですよ。というふうに読み取れます。
よって、yaku_appendを投げると「yaku」から、2つずつセットで情報を抜き出してきて、
yakulisit:[20]
han:1
を返します。
今回判別したい役リストの指定とone-hot化
yaku_label :今回判別したい役リストの指定とone-hot化
def yaku_label(yaku_list):
yaku = [
# //// 一飜
"門前清自摸和","立直","一発","槍槓","嶺上開花",
"海底摸月","河底撈魚","平和","断幺九","一盃口",
"自風 東","自風 南","自風 西","自風 北",
"場風 東","場風 南","場風 西","場風 北",
"役牌 白","役牌 發","役牌 中",
# //// 二飜
"両立直","七対子","混全帯幺九","一気通貫","三色同順",
"三色同刻","三槓子","対々和","三暗刻","小三元","混老頭",
# //// 三飜
"二盃口","純全帯幺九","混一色",
# //// 六飜
"清一色",
# //// 満貫
"人和",
# //// 役満
"天和","地和","大三元","四暗刻","四暗刻単騎","字一色",
"緑一色","清老頭","九蓮宝燈","純正九蓮宝燈","国士無双",
"国士無双13面","大四喜","小四喜","四槓子",
# //// 懸賞役
"ドラ","裏ドラ","赤ドラ"]
yaku_label_dic = dict(zip(yaku, range(len(yaku))))
label_yaku_dic = dict(zip(range(len(yaku)), yaku))
# 利用する役
yakuuse = [
# //// 一飜
"断幺九",
"役牌 白","役牌 發","役牌 中",
# //// 二飜
"混全帯幺九","一気通貫","三色同順",
"三色同刻","三槓子","対々和","三暗刻","小三元","混老頭",
# //// 三飜
"二盃口","純全帯幺九","混一色",
# //// 六飜
"清一色",]
yakuuse_label_dic = dict(zip(yakuuse, range(len(yakuuse))))
label_yakuuse_dic = dict(zip(range(len(yakuuse)), yakuuse))
yaku_str_list = [label_yaku_dic[i] for i in yaku_list] # あがり役名リスト
yakuuse_str_list = list(set(yaku_str_list) & set(yakuuse)) # ラベルに使うあがり役名リスト
label_num = len(yakuuse)
yaku_label = [0]*label_num
yakuuse_id_list = [yakuuse_label_dic[yakuuse_str] for yakuuse_str in yakuuse_str_list]
for yakuuse_id in yakuuse_id_list:
yaku_label[yakuuse_id] = 1
return yaku_label, yakuuse_str_list
機械学習モデルが適切にデータを扱えるように、今回使う役をリスト化→one-hotコーディングして、何番目の役に該当するかとその役の名前を返してくれるようにします。
具体的には、今回は以下のようになっています。
例:役牌 中
yaku_label:[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]= [
"断幺九",
"役牌 白","役牌 發","役牌 中",
"混全帯幺九","一気通貫","三色同順",
"三色同刻","三槓子","対々和","三暗刻","小三元","混老頭",
"二盃口","純全帯幺九","混一色",
"清一色"]
yaku_name:["役牌 中"]
「鳴き」と「牌の文字」の処理
天鳳は全ての牌にIDが振られることで、管理しています。例えば[0,1,2,3]=[一萬,一萬,一萬,一萬]です。人間が文字だけ見て、上り手牌がわかりやすいように、文字情報に起こしてあげます。
また、今回は、鳴いてもいい上がり方でけ指定しているので、これが、あってもなくても変わらないですが、特に、白發中は鳴枯れることが多いので、処理してあげます。こちらは、麻雀としての処理です。
naki_treatment :文字情報への変換
def hai_convert_str(id):
id_int = int(id)
hai = ["一", "二", "三", "四", "五", "六", "七", "八", "九", #萬子
"①", "②", "③", "④", "⑤", "⑥", "⑦", "⑧", "⑨", #筒子
"1", "2", "3", "4", "5", "6", "7", "8", "9", #索子
"東", "南", "西", "北", "白", "發", "中"]
return hai[id_int >> 2]
これは、ビットシフト演算というのを用いて、idが4で割った時のあまりでどの牌かを判別し、文字情報に変換しています。
naki_treatment :鳴きの情報処理
def naki_treatment(x):
if isinstance(x, str):
furo_hai_id = [furo_to_hai(i) for i in x.split(",")]
furo_hai_str = [[hai_convert_str(j) for j in i] for i in furo_hai_id]
return sum(furo_hai_id, []), sum(furo_hai_str, [])
else:
return [], []
こちらは、AGARIデータのmという数字に、何でもいいので、数字が入っていたら、「鳴いています」。で、牌を文字情報に変換して手配のセットとして、くっつけてあげます。Nanだったら「鳴いていない」と判定されます。
人間に見やすいように絵柄表現に変更
ここは、特に解説しません。入力としては、haiの0~135で表されるhaiIDを使用しています。
id_convert_image :絵柄への変換
def id_convert_image(id_list):
# unicode
n_unique_tiles = 34
min_tile_code_point = 126976
zihai = list(range(min_tile_code_point, min_tile_code_point+4)) + [126982, 126981, 126980]
manzu = list(range(126983, 126983+9))
souzu = list(range(126992, 126992+9))
pinzu = list(range(127001, 127001+9))
image_id_list = manzu + pinzu + souzu +zihai
# 天鳳
tenho_id_list = list(range(0, n_unique_tiles))
tenho_image_dic = dict(zip(tenho_id_list, image_id_list))
return "".join([chr(tenho_image_dic[i]) for i in id_list])
例えば[0,1,2,3]=[🀇,🀇,🀇,🀇]を返します。
鳴き情報の処理
ここは、麻雀処理です。鳴いた牌を簡単にいきます。
naki_treatmentで鳴いた時の牌をIDで判別していきます。鳴いたやつが中や發だった場合、それだけで上がることができるので。
furo_to_hai(furo) :鳴きをIDへ変換
def furo_to_hai(furo):
furo = int(furo)
if (furo & 0x0004): # 順子の場合
pattern = (furo & 0xFC00)>>10;
pattern = int(pattern / 3);
color_id = int(pattern / 7);
number = pattern % 7 + 1;
mentsu_num = [number, number+1, number+2];
soezi = [(furo & 0x0018)>>3, (furo & 0x0060)>>5, (furo & 0x0180)>>7]; # 牌添字1〜3を取得
mentsu = [color_id*9*4+(i-1)*4 + j for i, j in zip(mentsu_num, soezi)]
elif (furo & 0x0018): # 刻子、加槓の場合
pattern = (furo & 0xFE00)>>9;
pattern = int(pattern / 3);
color_id = int(pattern / 9);
number = pattern % 9 + 1;
soezi = [0, 1, 2, 3]
if (furo & 0x0008): # 刻子
mentsu_num = [number, number, number];
soezi_exclude = (furo & 0x0060)>>5
soezi.remove(soezi_exclude)
mentsu = [color_id*9*4+(i-1)*4 + j for i, j in zip(mentsu_num, soezi)]
else: # 加槓
mentsu_num = [number, number, number, number];
mentsu = [color_id*9*4+(i-1)*4 + j for i, j in zip(mentsu_num, soezi)]
else: # 暗槓、大明槓の場合
pattern = (furo & 0xFF00)>>8;
pattern = int(pattern / 4);
color_id = int(pattern / 9);
number = pattern % 9 + 1;
soezi = [0, 1, 2, 3]
mentsu_num = [number, number, number, number];
if (furo & 0x0003): # 大明槓
mentsu = [color_id*9*4+(i-1)*4 + j for i, j in zip(mentsu_num, soezi)]
else: # 暗槓
mentsu = [color_id*9*4+(i-1)*4 + j for i, j in zip(mentsu_num, soezi)]
mentsu_str = [str(i) for i in mentsu]
return mentsu_str;
データの加工(機械学習に適した形への処理)
これで、機械学習に使うデータの処理が終わりました。
今回
機械学習への入力は
yaku_labelが1以上の時のtehai_c_intです。
正解ラベルは
yaku_labelになります。
naki_treatment :鳴きの情報処理
# データ型の変換:数値→文字
agari_df["yaku"] = agari_df.yaku.astype('str')
agari_df["yakuman"] = agari_df.yakuman.astype('str')
# haiの情報をベクトル情報に変換
agari_df["hai"] = agari_df.hai.apply(lambda x: x.split(","))
# 自分の手牌を整数リストと文字列リストに変換
agari_df["menzen_int"] = agari_df.hai.apply(lambda x: [int(i) for i in x])
agari_df["menzen_str"] = agari_df.hai.apply(lambda x: [hai_convert_str(i) for i in x])
# なきの牌を整数リストと文字列リストに変換
agari_df["furo_int"] = agari_df.m.apply(lambda x: [int(i) for i in naki_treatment(x)[0]])
agari_df["furo_str"] = agari_df.m.apply(lambda x: naki_treatment(x)[1])
#役の情報処理
# 全ての役から、どの情報にあってるか?
agari_df["yaku_all"] = agari_df[["yaku", "yakuman"]].apply(lambda x: yaku_append(x)[0], axis=1)
# 今回使う役の中に該当するか?
agari_df["yaku_label"] = agari_df.yaku_all.apply(lambda x: yaku_label(x)[0]) # 役(対象のみ)のone-hot
# 今回使う役を文字情報に変換?
agari_df["yaku_label_str"] = agari_df.yaku_all.apply(lambda x: yaku_label(x)[1]) # 役(対象のみ)
# それは何個役に該当してるか?
agari_df["yaku_label_num"] = agari_df.yaku_label_str.apply(len) # 役の数
# 組み合わせた手牌の整数リストと文字列リストと絵柄情報に変換
agari_df["tehai_int"] = agari_df[["menzen_int", "furo_int"]].apply(lambda x: sorted([int(i) for i in x[1]+x[0]]), axis=1)
agari_df["tehai_str"] = agari_df.tehai_int.apply(lambda x: [hai_convert_str(i) for i in x])
agari_df["tehai_c_int"] = agari_df.tehai_int.apply(lambda x: sorted([id_int >> 2 for id_int in x]))
agari_df["tehai_im"] = agari_df.tehai_c_int.apply(lambda x: id_convert_image(x))
表示例
| yaku_label | yaku_label_str | tehai_str | tehai_c_int | tehai_im | |
|---|---|---|---|---|---|
| 0 | [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] | [役牌 白] | [三, 四, 五, 六, 七, 八, 九, 九, ④, ⑤, ⑥, 白, 白, 白] | [2, 3, 4, 5, 6, 7, 8, 8, 12, 13, 14, 31, 31, 31] | 🀉🀊🀋🀌🀍🀎🀏🀏🀜🀝🀞🀆🀆🀆 |
| 1 | [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] | [役牌 中] | [三, 三, 三, 五, 六, 七, 2, 2, 6, 7, 8, 中, 中, 中] | [2, 2, 2, 4, 5, 6, 19, 19, 23, 24, 25, 33, 33, 33] | 🀉🀉🀉🀋🀌🀍🀑🀑🀕🀖🀗🀄🀄🀄 |
| 2 | [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] | [役牌 發] | [③, ④, ⑤, ⑤, ⑤, 2, 3, 4, 西, 西, 西, 發, 發, 發] | [11, 12, 13, 13, 13, 19, 20, 21, 29, 29, 29, 32, 32, 32] | 🀛🀜🀝🀝🀝🀑🀒🀓🀂🀂🀂🀅🀅🀅 |
| 3 | [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] | [役牌 中] | [八, 八, ①, ②, ③, 7, 8, 9, 南, 南, 南, 中, 中, 中] | [7, 7, 9, 10, 11, 24, 25, 26, 28, 28, 28, 33, 33, 33] | 🀎🀎🀙🀚🀛🀖🀗🀘🀁🀁🀁🀄🀄🀄 |
| 4 | [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] | [断幺九] | [五, 六, 七, ②, ③, ④, ⑧, ⑧, 3, 3, 3, 4, 4, 4] | [4, 5, 6, 10, 11, 12, 16, 16, 20, 20, 20, 21, 21, 21] | 🀋🀌🀍🀚🀛🀜🀠🀠🀒🀒🀒🀓🀓🀓 |
ここで、注意してほしいのは、tehai_strやtehai_imはあくまで人間様が見た時に見やすくしただけで、機械的には、別に見やすくもわかりやすくもなっていない点です。機械が学べるようにtehai_c_intを何の種類かを数字で表現しています。
機械学習をようやっとやる。
ここまでは、プロローグでした。ここからが機械学習の本番です。
引用元さんのアイデアで、上がった手配を分析しやすいように二次元情報にすることによって、正確性をあげようとしています。素晴らしい発想ですね。

機械学習のベースに関しては、このページがかなりわかりやすいです。
class MyDataset :データーローダで処理しやすい形に変換する。
class MyDataset(torch.utils.data.Dataset):
#入力データと正解ラベルを取得。
def __init__(self, agari_df):
self.tehai_list = agari_df["tehai_c_int"].tolist()
self.yaku_label_list = agari_df["yaku_label"].tolist()
# データセットの総サンプル数を返す。
def __len__(self):
return len(self.tehai_list)
# 指定されたインデックスのデータを取得する。
def __getitem__(self, index):
tehai, yaku_label = self.pull_item(index)
return tehai, yaku_label
# 手配を2次元の配列に変換する。
def tehai_2d(self, tehai):
c = collections.Counter(tehai)
tehai_ar = np.zeros(4*9*4)
for i in c.items():
hai_id = i[0] # 牌の種類 0index
hai_times = i[1] # 枚数
hai_id_list = [hai_id*4+i for i in range(hai_times)]
for j in hai_id_list:
tehai_ar[j] = 1
tehai_m = tehai_ar[0:9*1*4].copy().reshape([-1, 4])
tehai_p = tehai_ar[9*1*4:9*2*4].copy().reshape([-1, 4])
tehai_s = tehai_ar[9*2*4:9*3*4].copy().reshape([-1, 4])
tehai_z = tehai_ar[9*3*4:].copy().reshape([-1, 4])
tehai_ar = np.concatenate([tehai_m, tehai_p, tehai_s, tehai_z], 1)
return tehai_ar
# 指定されたインデックスのデータを取得して、tehai_2dを用いて2次元配列に変換して、PyTorchのをテンソルを返す。
def pull_item(self, index):
tehai = self.tehai_list[index]
yaku_label = self.yaku_label_list[index]
tehai_all = torch.tensor(np.array([self.tehai_2d(tehai)]),
dtype=torch.float32, device=DEVICE)
yaku_label = torch.tensor(np.array(yaku_label), dtype=torch.float32, device=DEVICE)
return tehai_all, yaku_label
データを分割し、訓練、検証、テストのデータセットを作詞
ここは、機械学習をする上で、訓練をするデータ。途中での正解率を検証するデータ。実際にテスト本番のデータに分けています。
今まで、出てきた問題が出てくるともちろん解けますが、それは当たり前なので、今まで見たことないデータを使うことで、ちゃんと学習できたかな?と見ています。
(今回。参考にしたコードでは。ユニークな値を用いてないので、ユニークのデータセットを見るのが本来正しいです。)
ただし、10をかけることは、小数値を出さないために、あえて、バッチサイズの倍数に調整して整合性を維ことを意味しています。
データセットの作成
BATCH_SIZE = 1024
TRAIN_SIZE = int(len(agari_df)//(BATCH_SIZE*10)*(BATCH_SIZE*10)*0.6)
VALID_SIZE = int(len(agari_df)//(BATCH_SIZE*10)*(BATCH_SIZE*10)*0.3)
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
df_train, df_val = train_test_split(agari_df, train_size=TRAIN_SIZE)
df_val, df_test = train_test_split(df_val, train_size=VALID_SIZE)
train_dataset = MyDataset(df_train)
val_dataset = MyDataset(df_val)
test_dataset = MyDataset(df_test)
データローダを作成
データローダはデータの取り扱いを簡単にするコンポーネントです。
今回はバッチのデータ処理とシャッフル機能を用いています。
こいつを呼び出すことで、より効率的なデータの読み込みを実現しています。
データローダを定義
# データローダーの作成
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=BATCH_SIZE, shuffle=True,)
val_dataloader = torch.utils.data.DataLoader(
val_dataset, batch_size=BATCH_SIZE, shuffle=False,)
test_dataloader = torch.utils.data.DataLoader(
test_dataset, batch_size=BATCH_SIZE, shuffle=False,)
畳み込みニューラルネットワークを用いた機械学習
再度、こちらを見て、基礎を確認していきましょう。多少、コードが変わっていますが、基礎的な要素は変わりません。
今回は、100回学習して、その中間結果ごとに、正確性と誤差を検証して、保存しています。
畳み込みニューラルネットワークを用いた機械学習
# パラメータの定義
WEIGHT_DECAY = 0.005
LEARNING_RATE = 0.01
EPOCH = 100 #学習回数
LABEL_NUM = len(agari_df.yaku_label[0]) 出力の数
# ニューラルネットワークの定義。
class Net(nn.Module):
# ニューラルネットワークの構成を定義。()
def __init__(self):
super(Net, self).__init__()
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2, stride=2)
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=2, padding=1) # 第1引数はその入力のチャネル数,第2引数は畳み込み後のチャネル数,第3引数は畳み込みをするための正方形フィルタ(カーネルとも言う)の1辺のサイズ
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=2, padding=1)
self.fc1 = nn.Linear(6336, 120) # ここのin_featuresはここまでのカーネルサイズなどに左右される(カーネルサイズにより9*16の画像が11*18の行列になっている。それが32の出力層で出力される)
self.fc2 = nn.Linear(120, LABEL_NUM)
# 次のニューラルネットワークの層に出力する際の処理
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = x.view(x.size()[0], -1)
# print(x.size()) # fc1のin_featuresを調べる
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# モデルの予測結果を0と1に変換し、実際のラベルと比較して精度を計算
def pred_acc(original, predicted):
label_predicted = (predicted > 0).int()
return label_predicted.eq(original).sum().numpy()/len(original)
# 機械学習のトレーニングと評価方法を設定する。
net = Net()
net = net.to(DEVICE)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.SGD(net.parameters(), lr=LEARNING_RATE, momentum=0.9, weight_decay=WEIGHT_DECAY)
#以下が実際のトレーニング(100回)の処理と各トレーニングの正確性の評価、
train_loss_value=[] #trainingのlossを保持するlist
train_acc_value=[] #trainingのaccuracyを保持するlist
test_loss_value=[] #testのlossを保持するlist
test_acc_value=[] #testのaccuracyを保持するlist
for epoch in range(EPOCH):
print('epoch', epoch+1) #epoch数の出力
for (inputs, labels) in train_dataloader:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss = []
running_acc = []
#train dataを使ってテストをする(パラメータ更新がないようになっている)
for (inputs, labels) in train_dataloader:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
outputs = net(inputs)
acc_ = []
for j, d in enumerate(outputs): # ミニバッチの中の一個を呼び出してる
acc = pred_acc(torch.Tensor.cpu(labels[j]), torch.Tensor.cpu(d))
acc_.append(acc)
loss = criterion(outputs, labels)
running_loss.append(loss.item()) #tensorを普通の値に
running_acc.append(np.asarray(acc_).mean())
total_batch_loss = np.asarray(running_loss).mean()
total_batch_acc = np.asarray(running_acc).mean()
print("train mean loss={}, accuracy={}"
.format(total_batch_loss, total_batch_acc)) #lossとaccuracy出力
train_loss_value.append(total_batch_loss) #traindataのlossをグラフ描画のためにlistに保持
train_acc_value.append(total_batch_acc) #traindataのaccuracyをグラフ描画のためにlistに保持
running_loss_test = []
running_acc_test = []
#valid dataを使ってテストをする
for (inputs, labels) in val_dataloader:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
outputs = net(inputs)
acc_ = []
for j, d in enumerate(outputs):
acc = pred_acc(torch.Tensor.cpu(labels[j]), torch.Tensor.cpu(d))
acc_.append(acc)
loss = criterion(outputs, labels)
running_loss_test.append(loss.item()) #lossを足していく
running_acc_test.append(np.asarray(acc_).mean())
total_batch_loss = np.asarray(running_loss_test).mean()
total_batch_acc = np.asarray(running_acc_test).mean()
print("test mean loss={}, accuracy={}"
.format(total_batch_loss, total_batch_acc)) #lossとaccuracy出力
test_loss_value.append(total_batch_loss) #traindataのlossをグラフ描画のためにlistに保持
test_acc_value.append(total_batch_acc) #traindataのaccuracyをグラフ描画のためにlistに保持
注目すべきは、以下の要素です。
# ニューラルネットワークの構成を定義。()
def __init__(self):
super(Net, self).__init__()
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2, stride=2)
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=2, padding=1) # 第1引数はその入力のチャネル数,第2引数は畳み込み後のチャネル数,第3引数は畳み込みをするための正方形フィルタ(カーネルとも言う)の1辺のサイズ
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=2, padding=1)
self.fc1 = nn.Linear(6336, 120) # ここのin_featuresはここまでのカーネルサイズなどに左右される(カーネルサイズにより9*16の画像が11*18の行列になっている。それが32の出力層で出力される)
self.fc2 = nn.Linear(120, LABEL_NUM)
これはニューラルネットワークの構成を定義しています。
これは、中間層が二層を定義しています。
入力=tehao_c_intの要素数14のベクトル
中間層1は16の特徴マップを
中間層2は32の特徴マップを
出力します。
ただし、画像処理として、
そのため、出力層が6336となっています。
# 次のニューラルネットワークの層に出力する際の処理
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = x.view(x.size()[0], -1)
# print(x.size()) # fc1のin_featuresを調べる
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
それぞれの層での出力の処理を表しています、
詳細はこちらで確認しましょう。
conv1、conv2は2次元(画像)の畳み込みです。
中間検証の結果
こんな感じです。正解率高いですが、含まれていない手牌は「含まれていない」と判断できるため、かなり高いです。

最後にone-hotの結果の処理
one-hotで帰ってきた結果の予測結果を実際二何の役かをyaku_label_str_preとして記録します。
実行結果
| yaku_label | yaku_label_str | tehai_str | tehai_im |
|---|---|---|---|
| [役牌 白] | [役牌 白] | [④, ⑤, ⑤, ⑥, ⑥, ⑦, 1, 1, 2, 3, 4, 白, 白, 白] | 🀜🀝🀝🀞🀞🀟🀐🀐🀑🀒🀓🀆🀆🀆 |
| [役牌 白] | [役牌 白] | [五, 六, 七, ⑤, ⑥, ⑦, 1, 2, 3, 白, 白, 白, 中, 中] | 🀋🀌🀍🀝🀞🀟🀐🀑🀒🀆🀆🀆🀄🀄 |
| [役牌 發] | [役牌 發] | [一, 一, 七, 七, 七, ③, ④, ⑤, ⑦, ⑧, ⑨, 發, 發, 發] | 🀇🀇🀍🀍🀍🀛🀜🀝🀟🀠🀡🀅🀅🀅 |
| [断幺九] | [断幺九] | [二, 二, 三, 三, 四, 四, ②, ②, ②, ③, ④, ⑤, ⑥, ⑦] | 🀈🀈🀉🀉🀊🀊🀚🀚🀚🀛🀜🀝🀞🀟 |
| [断幺九] | [断幺九] | [二, 二, 二, 六, 七, 八, ②, ②, ②, ⑧, ⑧, ⑧, 8, 8] | 🀈🀈🀈🀌🀍🀎🀚🀚🀚🀠🀠🀠🀗🀗 |
| [三色同順] | [三色同順] | [一, 二, 三, 六, 六, ①, ②, ③, ⑥, ⑦, ⑧, 1, 2, 3] | 🀇🀈🀉🀌🀌🀙🀚🀛🀞🀟🀠🀐🀑🀒 |
| [清一色] | [混一色] | [一, 一, 二, 二, 三, 三, 三, 四, 五, 五, 六, 七, 九, 九] | 🀇🀇🀈🀈🀉🀉🀉🀊🀋🀋🀌🀍🀏🀏 |
清一色と混一色を混同していますが、素晴らしい精度だと思います。たまたま、間違いを見れたのは幸運でした。
# 最後に
これを用いて、かなりNNについて理解できました。協力してくださった方々ありがとつございます。
Discussion