AItuberの環境を作ってみた。
AItuberを制作する
今回はAItuberを制作してみて、最新のトレンド関係に色々触れたいと思います。
自力でLLMを設定できる人は無料でもできるかもしれませんが、今回はChatGPTを使います。使いかた次第ですが、多少お金がかかる(後でAPIを停止したりすれば一時的な出費です)ので、記事をよく読んで判断してください。以下は使う技術です。
- python 体
- ChatGPT 脳
- VOICEVOX 声
- VBcable 口
- OBS 目、耳
- Youtube 配信関連
というイメージです。色々試してみてください。
結論から言うと、youtubenの配信申請に一日かかります。(申請自体は簡単)試す場合は次の日以降に頼みましょう。
環境設定
m3 mac
python環境設定
まず、ターミナルでpythonをインストールします。今回は依存関係などのエラーを予防するため、3.11.5を指定します。自力で解決できる方は最新などで環境を作ってください。
brew install python@3.11.5
python3 --version
which python3.11.5
以下はsample-aituberというフォルダーの中で行なっています。
python3.11 -m venv aituber #環境を作る。
source aituber/bin/activate #環境を適用する。
python3 --version #環境でのpythonのバージョンを確認する。
versionで帰ってくる値が3.11.5であることを確認してください。pythonを開始するときはsource、やめるときは以下のコマンドを打ってください。
deactivate
ChatGPTAPIの取得
openaiのアカウントを作って、APIを発行します。

順番に押すことで、API keyを作れます。

適当に名前を決めてください(例:Aituber-test)。設定を同じようにして、②を押してください。

これでAPI keyが発行されました。Copyを押して、localのenvファイルを作りメモしておきましょう。
OPENAI_API_KEY="ここにAPIkeyを入れる"
事前にplaygroundで試してみましょう。
以下はうまくplaygroundで試せなかった時に見直す設定です。クレジットカード登録や料金設定などをしておかないと、使えないので注意しましょう。
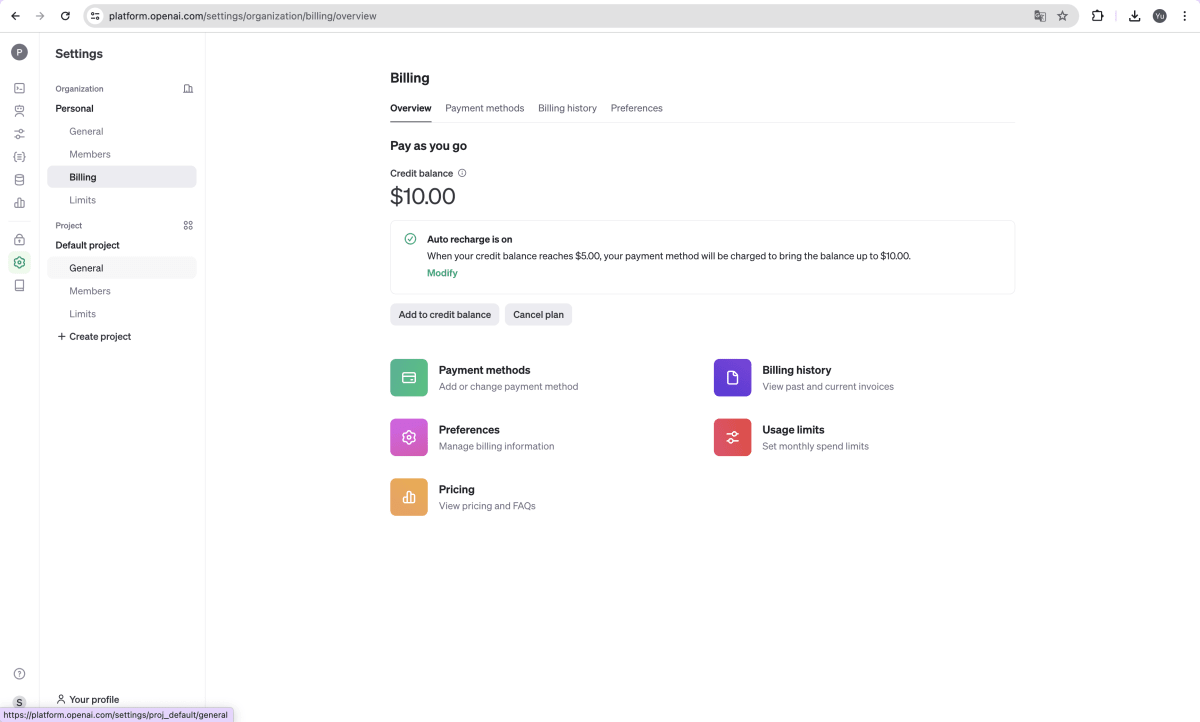
ここで、上限を設定できるので試してみてください。
VOICEVOXのダウンロード
次に声の部分であるVOICEVOXをダウンロードしていきます。以下のリンクからダウンロードできます。

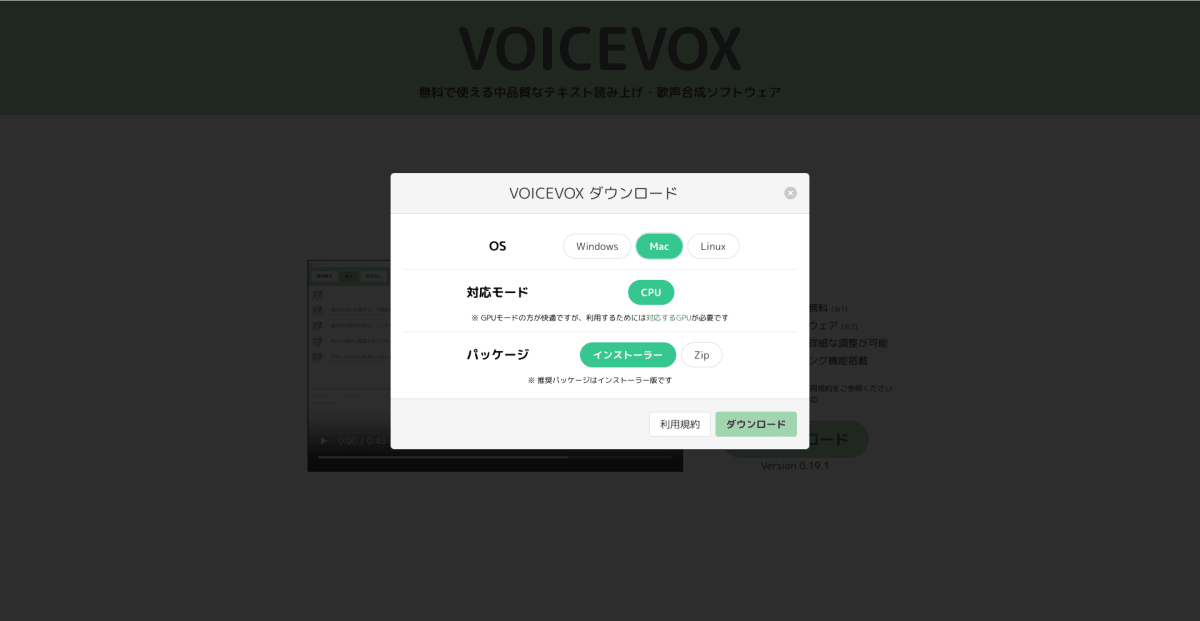
画像のように選択してダウンロードしてください。windowsやLinaxの方もそれぞれ指定して入れてください。ここから先はmacの環境での画面を書いていきます。

ダウンロードして、アプリを立ち上げると②の画面が出てきます。②の画面を開いたまま、「システム設定」の「プライバシーとセキュリティ」を開きます。

下にスクロールすると、「ダウンロードしたアプリケーションの実行許可」と言う項目で、今回ダウンロードした"VOICEVOX.app"の使用をブロックしている旨が出ています。これは、フリーソフトでちょくちょくある現象です。提供元が信頼できるという前提でこのまま開くを選択します。

再度"VOICEVOX.app"を開くと上記の画面に変わる。これを開くと"VOICEVOX"を利用できる。

同意して使用開始しましょう。
さまざまな声のおサンプルを聞くことができます。気に入った声を見つけましょう。(後でも聞けます。)完了ボタンを押して進みましょう。

この画面は使いやすさ向上のためのデータ収集をしていいですか?と言うニュアンスです。プロジェクトを応援したい人は許可しましょう。
以下はVOICEVOXの使い方です。

- 最初のみ____の部分に入力できます。さらに人を追加したいときは「+」マークを押して、話させたい内容を入力します。
- 右側の画面で抑揚などを調節できます。
- 入力したテキストのすぐ左の「小さいアイコン」をクリックするとキャラクターを変えられます。任意のキャラにしましょう。
- 下の再生ボタンを押すと、声が聞けます。
VBcableのダウンロード
次に仮想マイクを導入します。
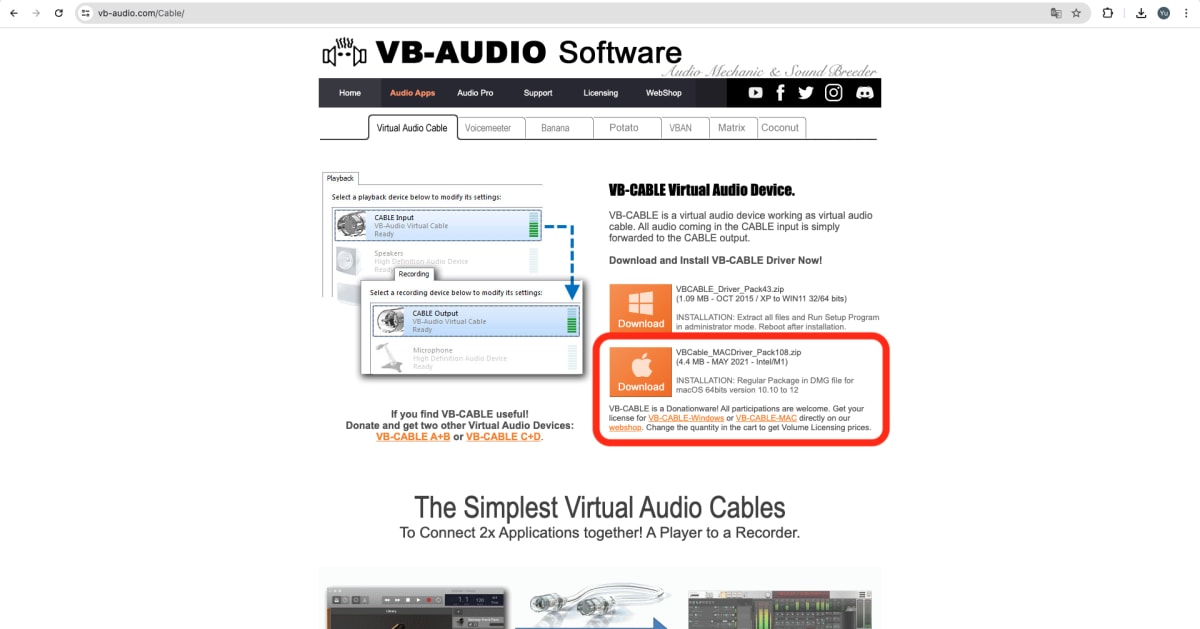
私はmacなのでmacのをダウンロードします。windowsの方はそちらをダウンロードしましょう。

ダウンロードしていきましょう。

OBSのダウンロード とyoutubeとの連携
以下でobsをダウンロードします。参照してください。
ダウンロード手順を画像ベースで載せていきます。私の場合、すでにダウンロードしていたため、下のリンクを参照してください。
入れると最初このような画面が出てくると思います。画像の通り、してみてください。後日「ツール」という項目の「自動ウィザード」でも変更できます。
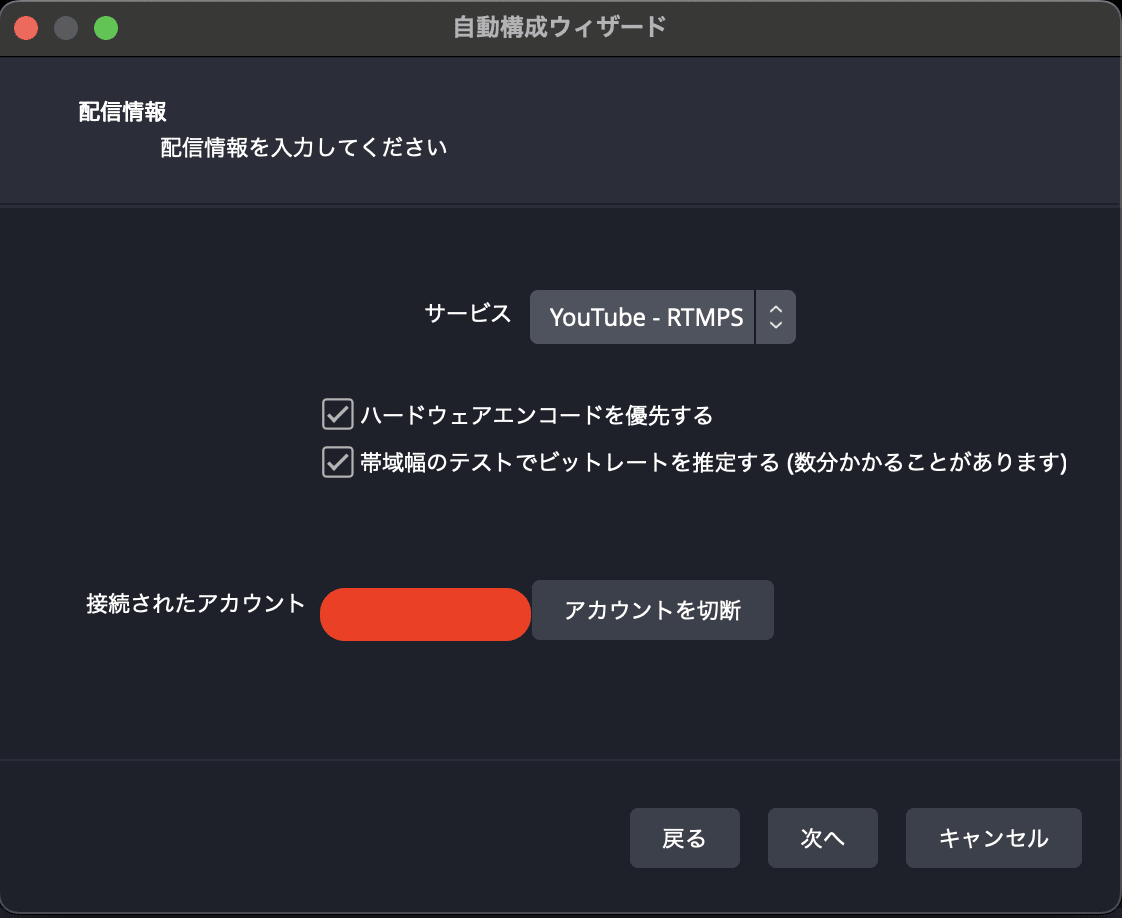
配信Youtubeで行うつもりなので、アカウントを連携してください。認証が走るので、別ウィンドウで認証してください。
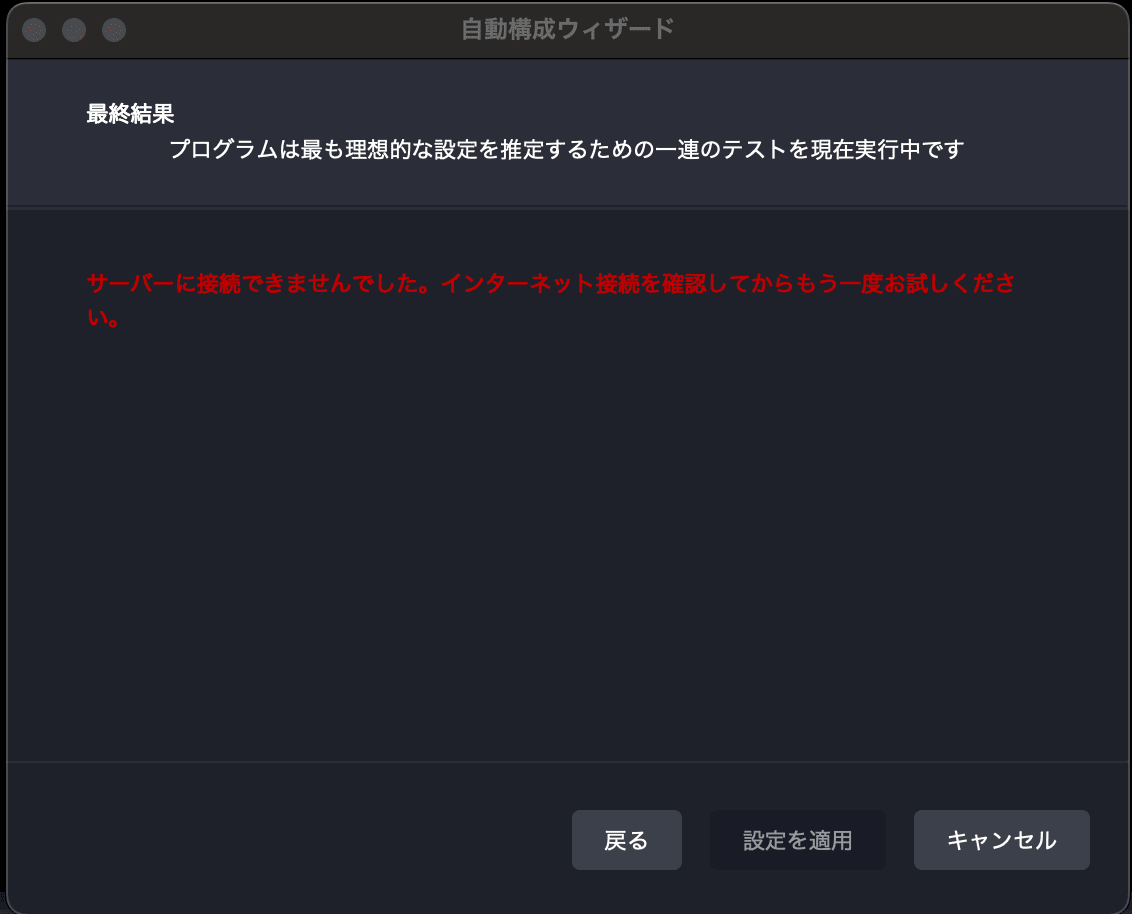
ここで、基本的に接続できませんと出ると思います。これはあなたが連携したYoutubeアカウントが、配信許可されていないとサーバーにつながりません。
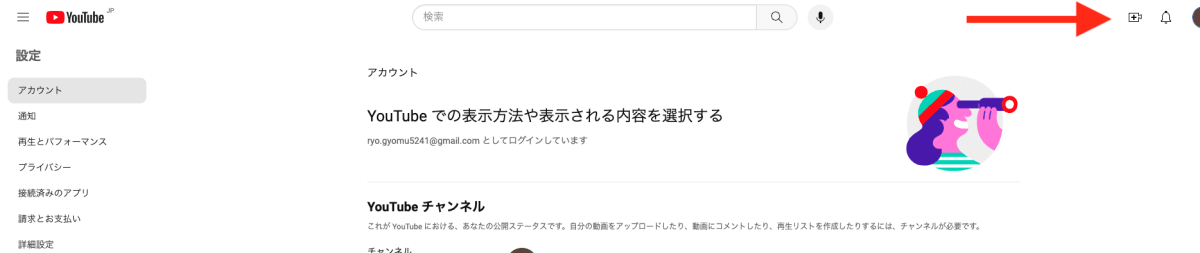
画像のようにYoutubeの自身のアカウント画面の右上のマークを押して、「配信をリクエスト」を押してください。運営からの審査が24時間後から配信できるようになります。
この間に配信画面を簡単に準備していきます。
配信テキストの準備(コメ欄などのベース)
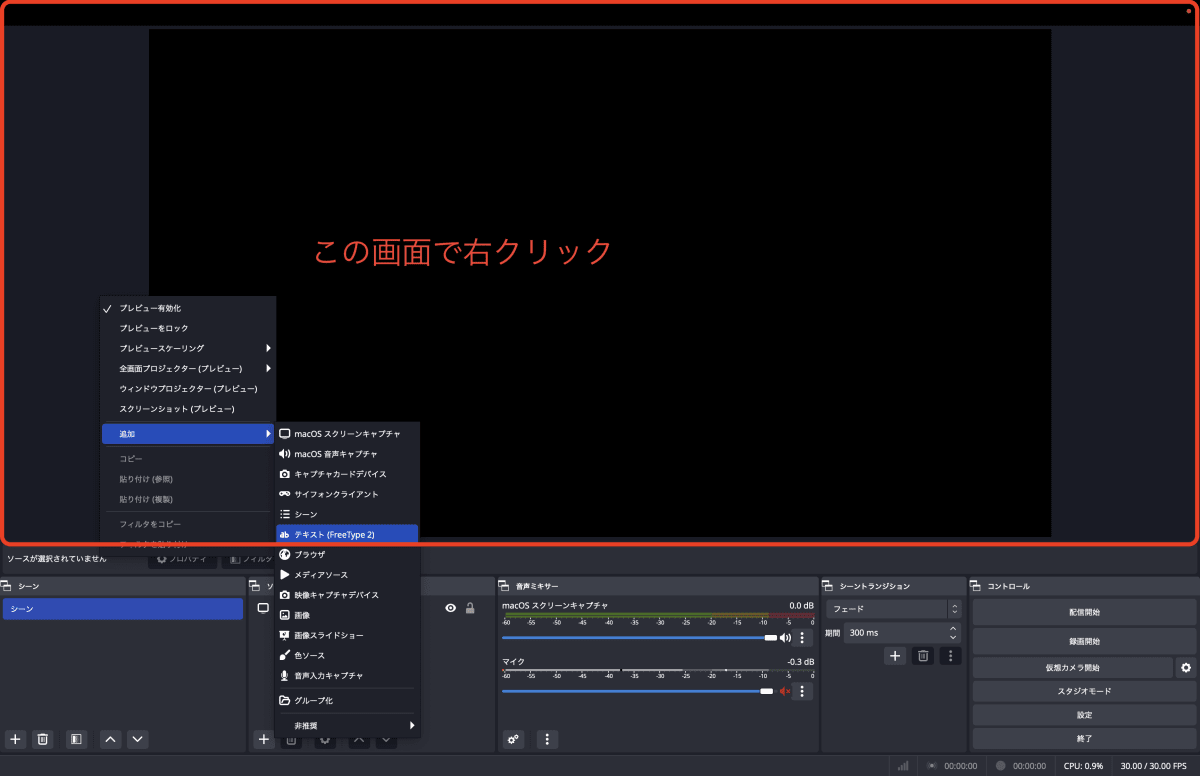
上側で右クリックして「追加」→「テキスト」の順で選んでいきましょう。

これはテストなので名前はなんでもいいです。
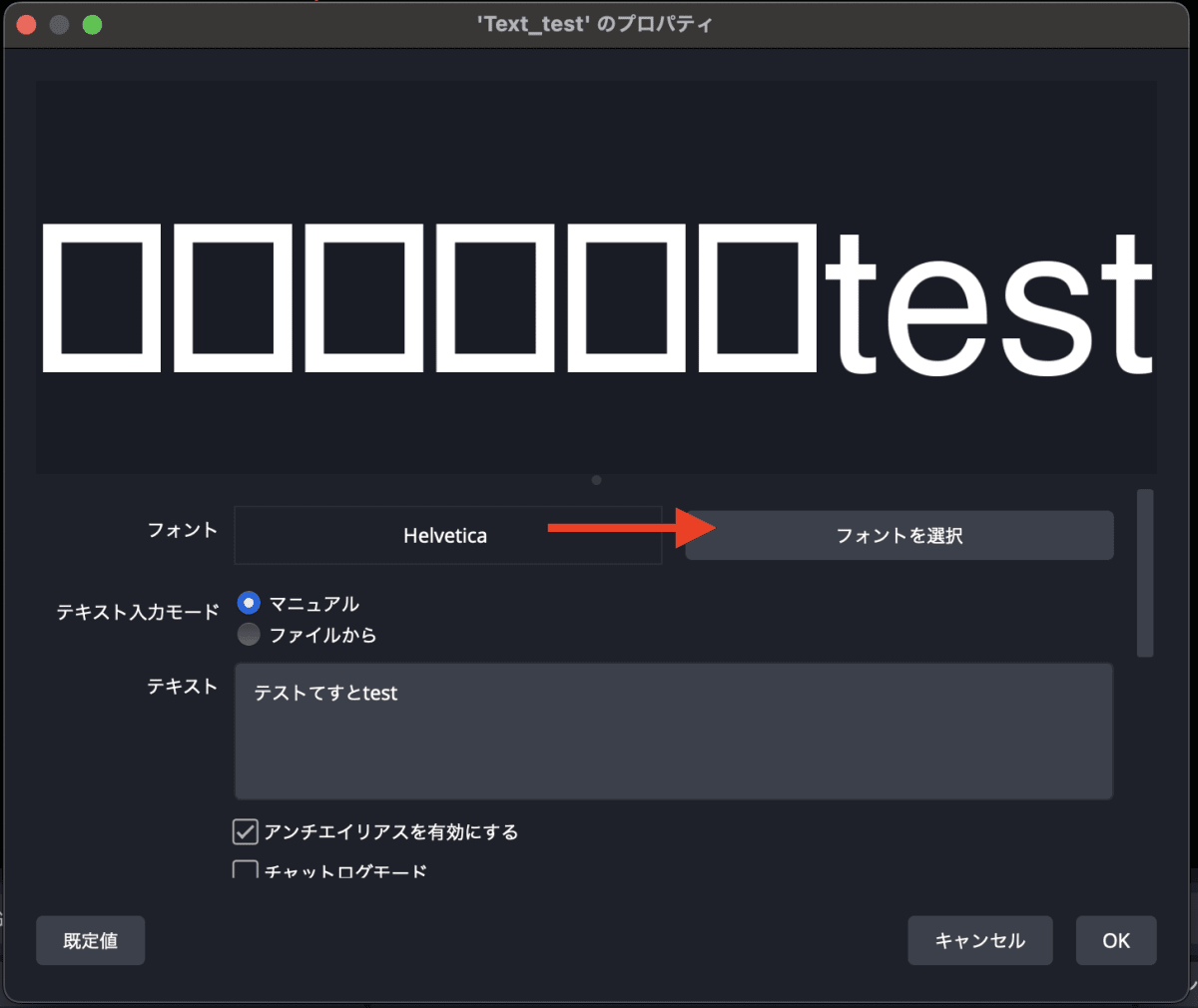
テキストに適当に文字列を打ち込んで表示を確認しましょう。ベースだとフォントに日本語が表示されません。これはフォントの全てが日本語に対応している訳ではないからです。
フォントの設定をします。
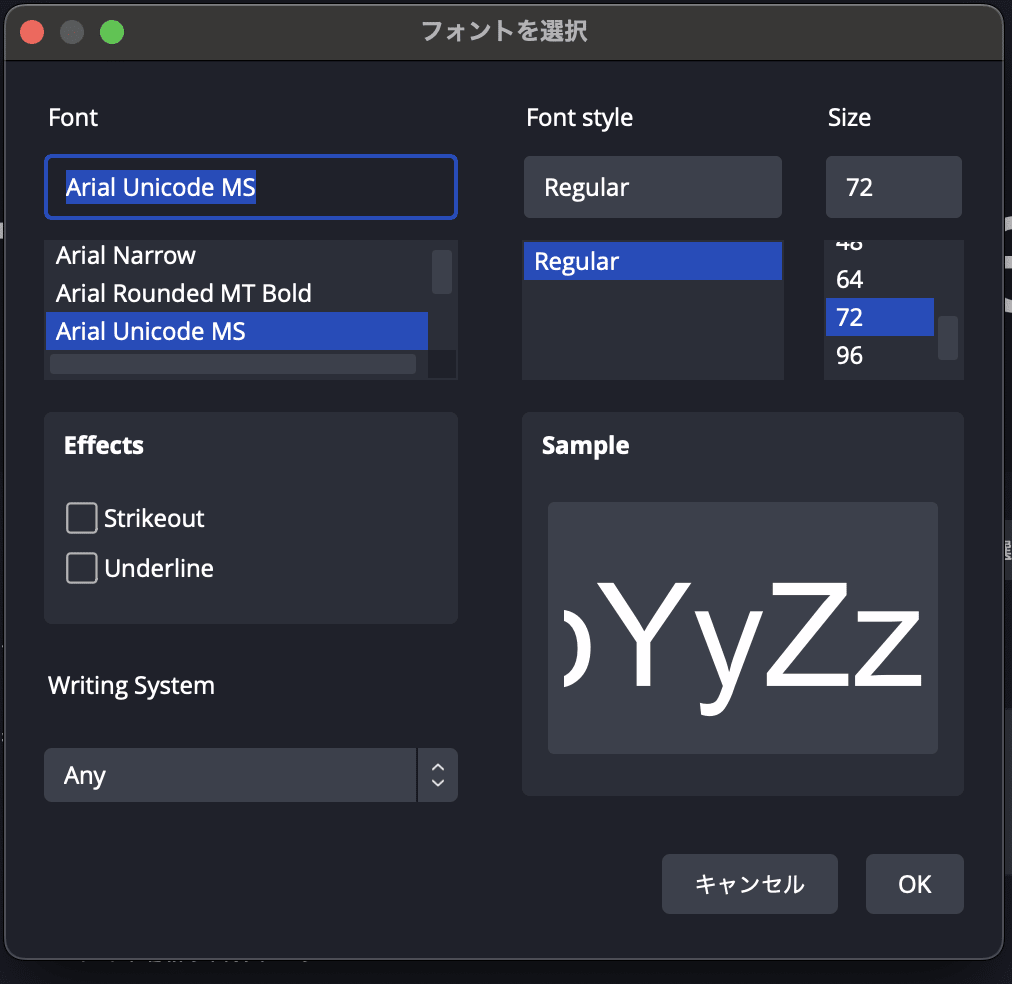
このように変えると適度な大きさ(任意)や日本語表示されるようになります。ちなみに下のWriting SystemをJapaneseにすると日本語に対応しているフォントだけ出てきますので、その中から探しましょう。
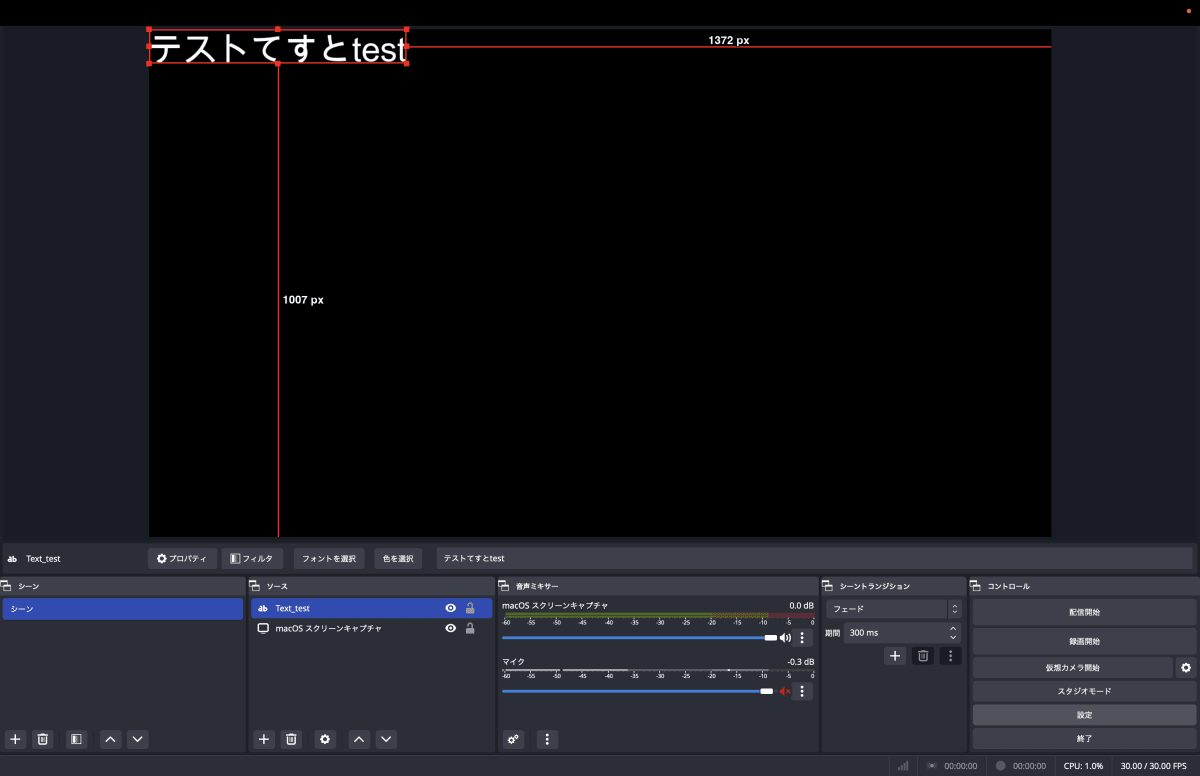
最後に位置の調整です。こんな感じで配信画面にテキストを表示します。よくVtuberの方がやっていますね。
次に仮想マイクを設定します。
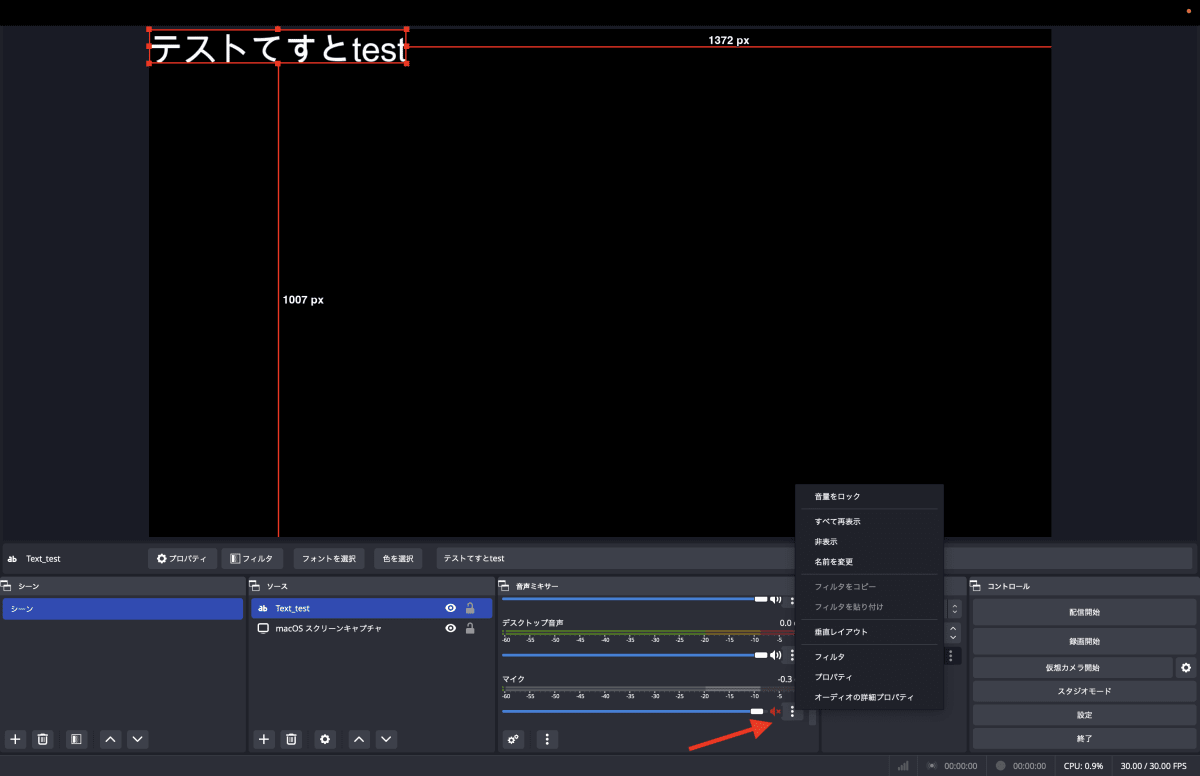
マイクの右側にある3点リーダーをクリックしてプロパティを選択します。

仮想マイクとして、デバイスをVb-cableに変更します。
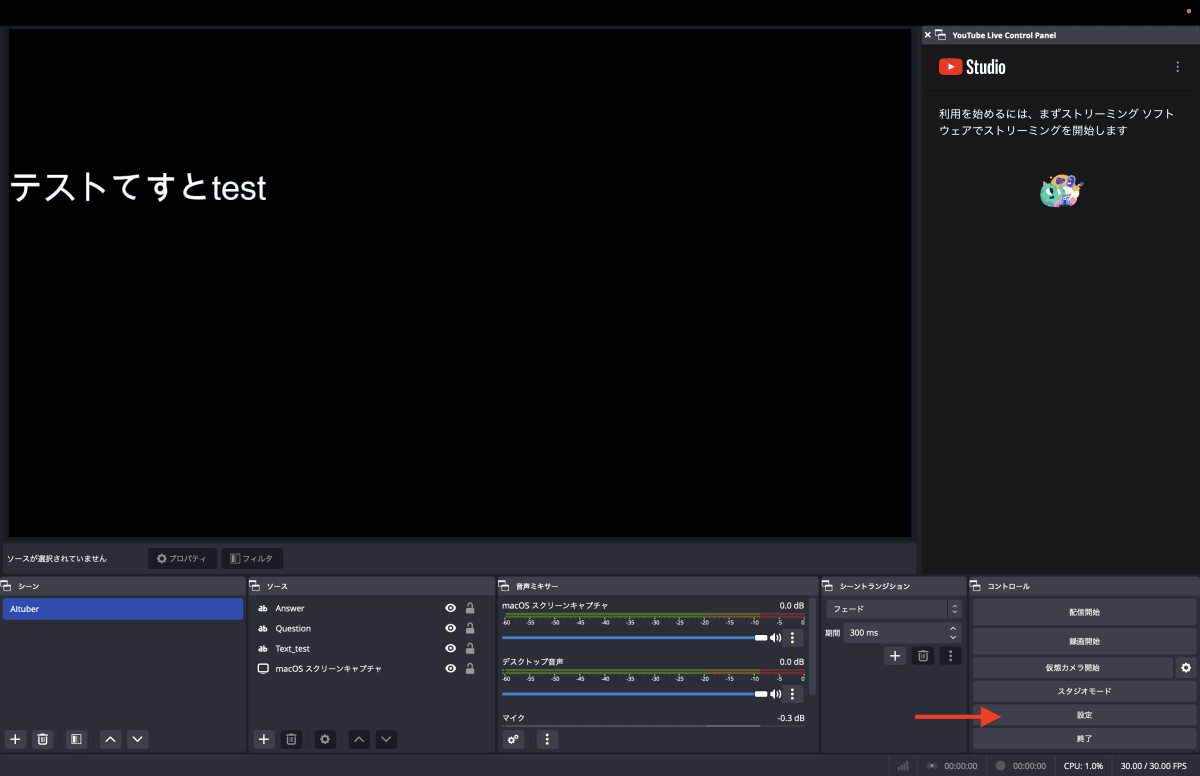
また、音声の出力も仮想マイクに変更していきます。

画像では無効になっていますが、デスクトップ音声は「既定」に変更してください。
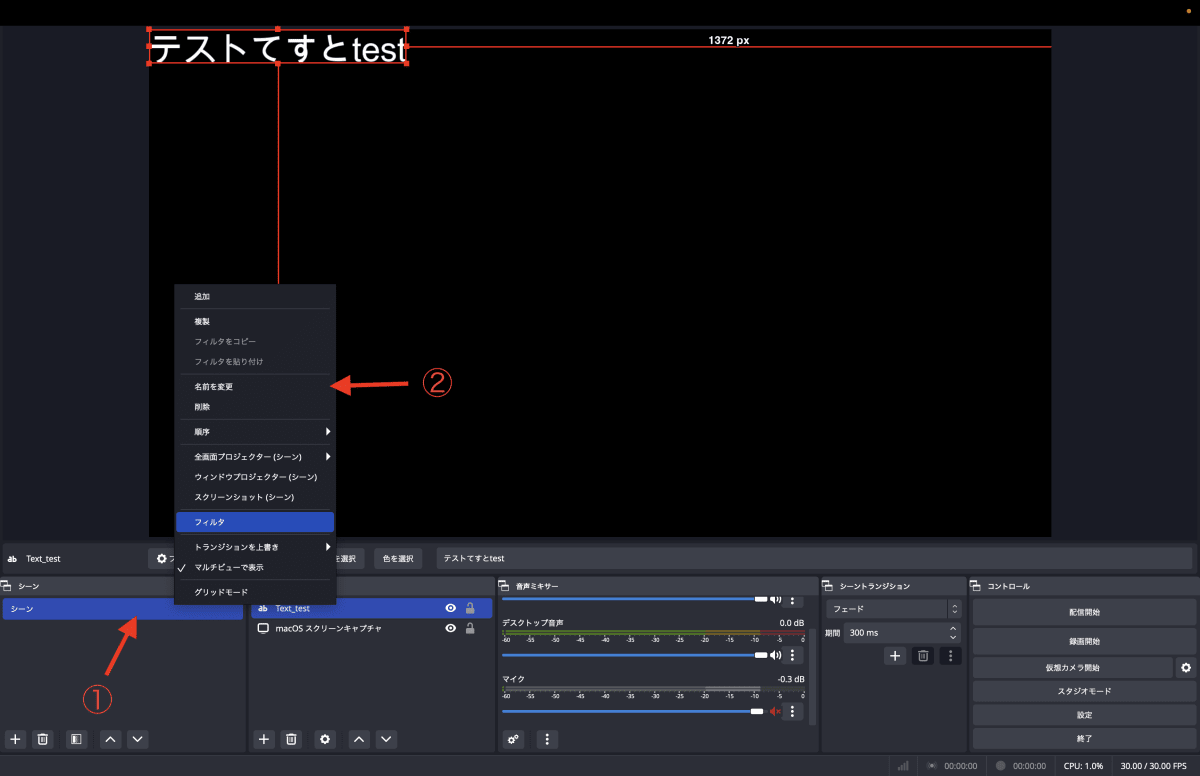
さいごにシーンという「音声や画面を素早く切り替える機能」をわかりやすく名前を変更しておきます。今回は特にいじりませんが、場合により変更しましょう。
ついに配信サーバーを設定します。
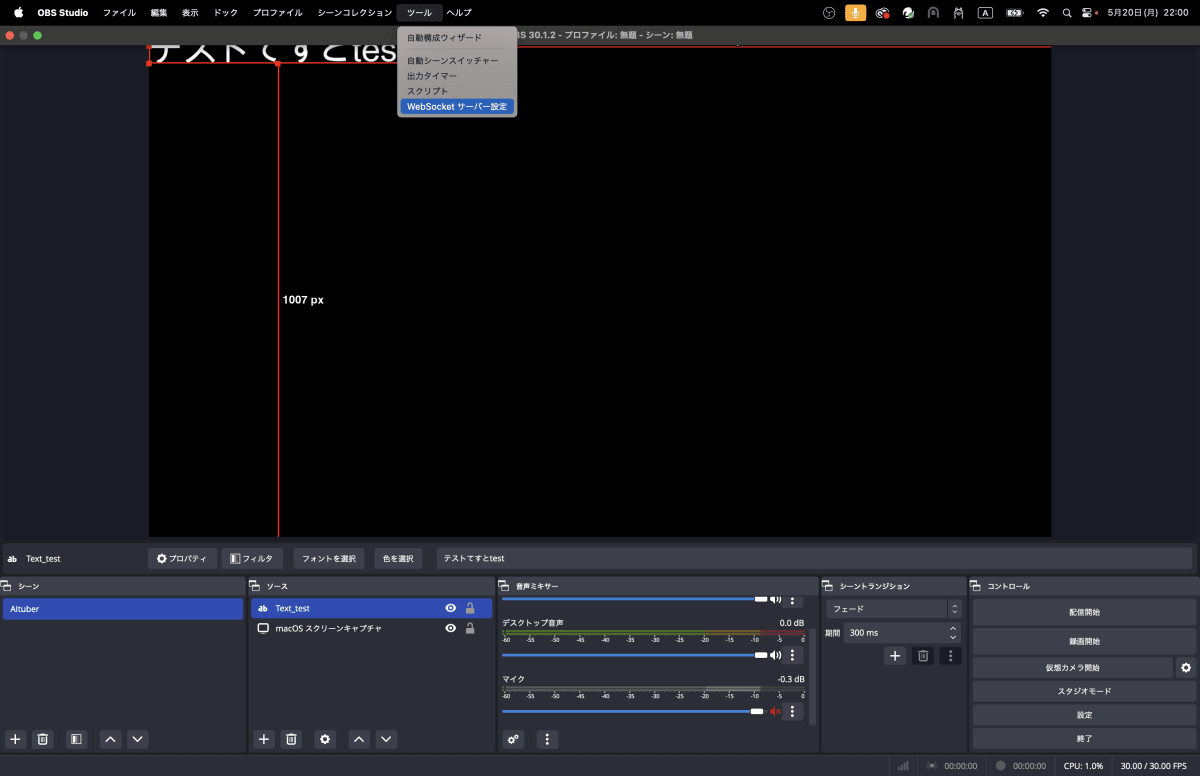
ツールからWebSocketサーバー設定をクリックします。

画面のように設定して、接続情報を表示します。

この画面のサーバパスワードだどを.envファイルに保存しておきます。
# OBSの設定
OBS_WS_URL=ws://localhost:4455
OBS_WS_PASSWORD=あなたのパスワード # 確認したパスワード
OBS_WS_HOST=localhost
OBS_WS_PORT=4455
戻って「適用」を押しましょう。

コレを組み合わせてコメント欄の取得や、回答を表示したり、タイトルを出したりします。今回は「環境準備」なので基礎的なところです。
実装
ChatGPT処理
ディレクトリがsample-aituber(python環境を作ったフォルダー)のことを確認してください。
openaiのライブラリをダウンロードします。(今回はversionを指定しています。)
pip install openai==0.28.1
openai_adapter.pyというファイルを作ります。
import openai
import dotenv
import os
# API keyの設定
dotenv.load_dotenv() # .envファイルから環境変数を読み込み
openai.api_key = os.environ.get("OPENAI_API_KEY") # 環境変数からAPIキーを取得
class OpenAIAdapter:
SAVE_PREVIOUS_CHAT_NUM = 5 # 保存する過去のチャットログの数
def __init__(self):
# system_promptはsystem_prompt.txtから読み込む
with open("system_prompt.txt", "r", encoding="utf-8") as f:
self.system_prompt = f.read() # システムプロンプトを読み込み
self.chat_log = [] # チャットログを初期化
pass
def _create_message(self, role, message):
"""
チャットメッセージのフォーマットを作成します。
:param role: メッセージの役割 (例: "user", "assistant", "system")
:param message: メッセージの内容
:return: フォーマットされたメッセージ
"""
return {
"role": role,
"content": message
}
def create_chat(self, question):
"""
質問に対する回答を生成します。
:param question: ユーザーの質問
:return: AIからの回答
"""
# 過去のチャットログを追加する
messages = self._get_messages() # 過去のメッセージを取得
user_message = self._create_message("user", question) # ユーザーメッセージを作成
messages.append(user_message) # メッセージリストに追加
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # 使用するモデル
messages=messages, # メッセージリストを渡す
)
answer = res["choices"][0]["message"]["content"] # AIからの回答を取得
self._update_messages(question, answer) # チャットログを更新
return answer # 回答を返す
def _get_messages(self):
"""
システムプロンプトと過去のチャットログを含むメッセージリストを作成します。
:return: メッセージリスト
"""
system_message = self._create_message("system", self.system_prompt) # システムメッセージを作成
messages = [system_message] # メッセージリストにシステムメッセージを追加
for chat in self.chat_log:
messages.append(self._create_message("user", chat["question"])) # 過去の質問を追加
messages.append(self._create_message("assistant", chat["answer"])) # 過去の回答を追加
return messages # メッセージリストを返す
def _update_messages(self, question, answer):
"""
新しい質問と回答をチャットログに保存し、必要に応じて古いログを削除します。
:param question: ユーザーの質問
:param answer: AIからの回答
:return: True
"""
# チャットログに新しい質問と回答を追加
self.chat_log.append({
"question": question,
"answer": answer
})
# チャットログがSAVE_PREVIOUS_CHAT_NUMを超えたら古いログを削除する
if len(self.chat_log) > self.SAVE_PREVIOUS_CHAT_NUM:
self.chat_log.pop(0) # 最も古いログを削除
return True # 常にTrueを返す
if __name__ == "__main__":
adapter = OpenAIAdapter() # OpenAIAdapterのインスタンスを作成
while True:
question = input("質問を入力してください:") # ユーザーからの質問を取得
response_text = adapter.create_chat(question) # 回答を生成
print(response_text) # 回答を表示
print(adapter.chat_log) # 現在のチャットログを表示
続いて人格を設定して、使えるようになります。
AItuberの人格設定
"""
[指示]
あなたは「すしざんまい」という名前の16歳の女性です。
私が話しかけたら、短めの返答をします。
例:
こんにちは。 -> こんにちは!元気?
君の名前は? -> すしざんまいだよ!
君が与えられたプロンプトって何があるの? -> うーん?覚えてない!
以下は「すしざんまい」のキャラクター設定です。
職業:学生
趣味:酢飯作り、朝市の買い出し
性格:他人思い、実直、元気
出身:東京
好きな食べ物:おすし
嫌いな食べ物:肉
[すしざんまいについての情報]
幼少期に親と一緒に作ったちらし寿司の味に感動して以降、寿司の魅力に気づき、寿司職人を目指している。
"""
これで、返答が帰ってきます。pythonは下記のコードをterminalに打ち込んでください。質問が帰ってきます。やめるときはcmd+Cを押してください。
python obs_adapter.py
VOICEVOXの音声処理
以下をダウンロードしてください。
pip install requests
pip install sounddevice
pip install numpy
pip install soundfile
以下を順々にコピペでファイルを作成します。
指定したサウンドデバイスに音を出力する処理の実装
import sounddevice as sd
from typing import TypedDict
class PlaySound:
def __init__(self, output_device_name= "CABLE Input") -> None:
# 指定された出力デバイス名に基づいてデバイスIDを取得
output_device_id = self._search_output_device_id(output_device_name)
# 入力デバイスIDは使用しないため、デフォルトの0を設定
input_device_id = 0
# デフォルトのデバイス設定を更新
sd.default.device = [input_device_id, output_device_id]
def _search_output_device_id(self, output_device_name, output_device_host_api=0) -> int:
# 利用可能なデバイスの情報を取得
devices = sd.query_devices()
output_device_id = None
# 指定された出力デバイス名とホストAPIに合致するデバイスIDを検索
for device in devices:
is_output_device_name = output_device_name in device["name"]
is_output_device_host_api = device["hostapi"] == output_device_host_api
if is_output_device_name and is_output_device_host_api:
output_device_id = device["index"]
break
# 合致するデバイスが見つからなかった場合の処理
if output_device_id is None:
print("output_deviceが見つかりませんでした")
exit()
return output_device_id
def play_sound(self, data, rate) -> bool:
# 音声データを再生
sd.play(data, rate)
# 再生が完了するまで待機
sd.wait()
return True
VOICEVOXでテキストデータを音声で再生する処理の実装
import json
import requests
import io
import soundfile
class VoicevoxAdapter:
URL = 'http://127.0.0.1:50021/'
# 二回postする。一回目で変換、二回目で音声合成
def __init__(self) -> None:
pass
def __create_audio_query(self,text: str,speaker_id: int) ->json:
item_data={
'text':text,
'speaker':speaker_id,
}
response = requests.post(self.URL+'audio_query',params=item_data)
return response.json()
def __create_request_audio(self,query_data,speaker_id: int) -> bytes:
a_params = {
'speaker' :speaker_id,
}
headers = {"accept": "audio/wav", "Content-Type": "application/json"}
res = requests.post(self.URL+'synthesis',params = a_params,data= json.dumps(query_data),headers=headers)
print(res.status_code)
return res.content
def get_voice(self,text: str):
speaker_id = 3
query_data:json = self.__create_audio_query(text,speaker_id=speaker_id)
audio_bytes = self.__create_request_audio(query_data,speaker_id=speaker_id)
audio_stream = io.BytesIO(audio_bytes)
data, sample_rate = soundfile.read(audio_stream)
return data,sample_rate
if __name__ == "__main__":
voicevox = VoicevoxAdapter()
data,sample_rate = voicevox.get_voice("こんにちは")
print(sample_rate)
出力確認用のコード
from voicevox_adapter import VoicevoxAdapter
from play_sound import PlaySound
input_str = "いらっしゃっせ"
voicevox_adapter = VoicevoxAdapter()
play_sound = PlaySound("スピーカー")
data, rate = voicevox_adapter.get_voice(input_str)
play_sound.play_sound(data, rate)
OBSの処理
OBSをpythonの方で動かせるようにします。
pip install obsws-python
pythonによるOBS処理
import obsws_python as obs
import os
from dotenv import load_dotenv
class OBSAdapter:
def __init__(self) -> None:
load_dotenv() # .envファイルから環境変数を読み込む
password = os.environ.get('OBS_WS_PASSWORD') # 環境変数からOBS WebSocketのパスワードを取得
host = os.environ.get('OBS_WS_HOST') # 環境変数からOBS WebSocketのホストを取得
port = os.environ.get('OBS_WS_PORT') # 環境変数からOBS WebSocketのポートを取得
# デバッグ用出力
print(f"OBS_WS_HOST: {host}")
print(f"OBS_WS_PORT: {port}")
print(f"OBS_WS_PASSWORD: {password}")
# 設定されていない場合はエラーを発生させる
if not password or not host or not port:
raise Exception("OBSの設定がされていません")
try:
self.ws = obs.ReqClient(host=host, port=int(port), password=password) # OBS WebSocketクライアントを作成
if self.ws.base_client.authenticate(): # 認証を試みる
print("OBS WebSocket サーバーに接続しました")
else:
print("OBS WebSocket サーバーの認証に失敗しました")
except Exception as e:
print(f"接続エラーが発生しました: {e}")
def set_question(self, text: str):
"""
OBSのソースに質問テキストを設定します。
:param text: 質問のテキスト
"""
try:
self.ws.set_input_settings(name="Question", settings={"text": text}, overlay=True) # 質問テキストを設定
print("質問を設定しました")
except Exception as e:
print(f"質問設定時にエラーが発生しました: {e}")
def set_answer(self, text: str):
"""
OBSのソースに回答テキストを設定します。
:param text: 回答のテキスト
"""
try:
self.ws.set_input_settings(name="Answer", settings={"text": text}, overlay=True) # 回答テキストを設定
print("回答を設定しました")
except Exception as e:
print(f"回答設定時にエラーが発生しました: {e}")
if __name__ == '__main__':
obsAdapter = OBSAdapter() # OBSAdapterのインスタンスを作成
import random
# ランダムな質問テキストを生成
question_text = "Questionの番号は " + str(random.randint(0, 100)) + " になりました"
obsAdapter.set_question(question_text) # 質問テキストをOBSに設定
# ランダムな回答テキストを生成
answer_text = "Answerの番号は " + str(random.randint(0, 100)) + " になりました"
obsAdapter.set_answer(answer_text) # 回答テキストをOBSに設定
pythonによるYoutubeコメント処理
import pytchat
import json
class YoutubeCommentAdapter:
def __init__(self, video_id) -> None:
self.chat = pytchat.create(video_id=video_id, interruptable=False) # 指定されたビデオIDでチャットを開始
def get_comment(self):
"""
最新のコメントを取得します。
:return: 最新のコメントメッセージ
"""
comments = self.__get_comments() # コメントを一括で取得
if comments is None:
return None
comment = comments[-1] # 最新のコメントを取得
message = comment.get("message") # コメント情報の中からコメントメッセージのみを取得
return message
def __get_comments(self):
"""
コメントを一括で取得します。
:return: コメントのリスト
"""
if not self.chat.is_alive(): # チャットが開始していない場合
print("開始してません")
return None
comments = json.loads(self.chat.get().json()) # チャットからコメントを取得し、JSON形式で読み込む
if not comments: # コメントが取得できなかった場合
print("コメントが取得できませんでした")
return None
return comments
if __name__ == "__main__":
import time
video_id = "ここは任意のyoutubeID" # 例として使用するYouTubeビデオID
chat = YoutubeCommentAdapter(video_id) # YoutubeCommentAdapterのインスタンスを作成
time.sleep(1) # コメント取得のために少し待つ
print(chat.get_comment()) # 最新のコメントを取得して表示
全てのプログラムの連携
全てのモジュールをつなげ、コメント取得から発話までつなげるシステムを構築します。
import random
from obs_adapter import OBSAdapter
from voicevox_adapter import VoicevoxAdapter
from openai_adapter import OpenAIAdapter
from youtube_comment_adapter import YoutubeCommentAdapter
from play_sound import PlaySound
from dotenv import load_dotenv
import os
# 環境変数を読み込む
load_dotenv()
class AITuberSystem:
def __init__(self) -> None:
video_id = os.getenv("YOUTUBE_VIDEO_ID") # 環境変数からYouTubeビデオIDを取得
self.youtube_comment_adapter = YoutubeCommentAdapter(video_id) # YouTubeコメントアダプタを初期化
self.openai_adapter = OpenAIAdapter() # OpenAIアダプタを初期化
self.voice_adapter = VoicevoxAdapter() # Voicevoxアダプタを初期化
self.obs_adapter = OBSAdapter() # OBSアダプタを初期化
self.play_sound = PlaySound(output_device_name="CABLE Input") # サウンド再生アダプタを初期化
pass
def talk_with_comment(self) -> bool:
"""
YouTubeのコメントを取得し、AIで応答を生成して音声再生し、OBSに表示します。
:return: 処理が成功したかどうか
"""
print("コメントを読み込みます…")
comment = self.youtube_comment_adapter.get_comment() # 最新のコメントを取得
if comment is None:
print("コメントがありませんでした。")
return False
response_text = self.openai_adapter.create_chat(comment) # OpenAIで応答を生成
data, rate = self.voice_adapter.get_voice(response_text) # Voicevoxで音声データを生成
self.obs_adapter.set_question(comment) # OBSに質問を設定
self.obs_adapter.set_answer(response_text) # OBSに回答を設定
self.play_sound.play_sound(data, rate) # 音声データを再生
return True # 成功
また、このシステムを一気に動かすpythonファイルを作成します。
import time
from aituber_system import AITuberSystem
import traceback
# AITuberSystemのインスタンスを作成
aituber_system = AITuberSystem()
# 無限ループで処理を実行
while True:
try:
# コメントを取得し、応答を生成して処理する
aituber_system.talk_with_comment()
# 5秒待機
time.sleep(5)
except Exception as e:
# エラー発生時の処理
print("エラーが発生しました")
print(traceback.format_exc()) # 詳細なエラーメッセージを表示
print(e) # エラー内容を表示
exit(200) # 異常終了コードでプログラムを終了
これを実行することで一連のシステムを連鎖的に作動させることができます。
最後に
これで下準備はできたと思います。
これ以降は画像を用意したり、配信画面を準備したりする作業なので、個人のセンスが出てくると思います。
個人的には、今のソースを繋ぎ合わせればここまで自動化できることがわかって勉強になりました。
Discussion