ディープラーニングで音楽を学んでみた
きっかけ
友達と音楽作成AIで遊んでいたら、仕組みが気になったので勉強してみました。
環境は、Google ColaboratoryでPythonで学習します。
導入
下記のgithubに入り、<>codeからDownlowd ZIPでコードをダウンロードしましょう。その中の
data/choralesを開くと、midiファイルが大量に入っています。これを利用します。
google driveのマイドライブを開いて、
下記の画像のように、chorales/midiというファイルを作り、その中に、.midファイルをアップロードします。

次にgoogle Colaboratoryノートブックを開いて、左端のどるだアイコンより、下記の画像のようにクリックしていき、自分のGoogleドライブをマウントします。

それぞれの大分類で、別々のColaboratoryノートブックを作ることを推奨します。
音楽データをpythonで読み書きしてみる。
試しにMIDIファイルをいじってみる。
MIDIファイルの読み書きをするためにpretty_midiというライブラリを入れます。
また、MIDIファイルを再生して音を確認するためにうMIDIデータをオーディオに変換する必要があり、midi2audioとFluidSynthを用います。
インストール
# PrettyMIDIインストール
!pip install pretty_midi
# midi2audioとFluidSynthをインストール
!pip install midi2audio
!apt install fluidsynth
試しに、一つのMIDIファイルを読み込んでみます。
MIDIファイルを読み込む
import pretty_midi
# MIDIデータを読み込む
midi = pretty_midi.PrettyMIDI("drive/MyDrive/chorales/midi/000101b_.mid")
# 先頭の楽器パートの音符列を取り出す
notes = midi.instruments[0].notes
# 取り出した音符列を画面出力する
print(notes)
以下に例として、出力結果を表示してみます。
[Note(start=51.724125, end=53.793090, pitch=65, velocity=96), Note(start=53.793090, end=55.862055, pitch=72, velocity=96), Note(start=55.862055, end=57.931020, pitch=69, velocity=96), ...]
実際には、3点リーダーの後に、続きます。
midiファイルの中にはmidiファイル(曲)、instruments(楽器)、notes(音符)の情報を持っていて、以下のようになっています。
- midiファイル
- instruments[0]
- Note[0]
- start (音符の開始時刻)
- end (音符の終了時刻)
- pitch (音符のピッチ(音の高さ))
- velocity (音の強さ)
- Note[1]
- 音符の数だけ続く
- Note[0]
- instruments[1]
- Note[0]
- Note[1]
- 音符の数だけ続く
- 楽器の要素だけ数がある。
- instruments[0]
一つのinstrumentsは、一つの楽器を表し、一つのnotesは一音を表します。
この読み込んだ視覚的に表したものを描画してみます。
読み込んだMIDIファイルの楽譜を描画してみる
import matplotlib.pyplot as plt
# さきほど読み込んだMIDIデータの楽譜を取得する
pianoroll = midi.get_piano_roll()
# 取得した楽譜の一部を描画する
plt.matshow(pianoroll[:, 10000:10400])
結果が以下となります。
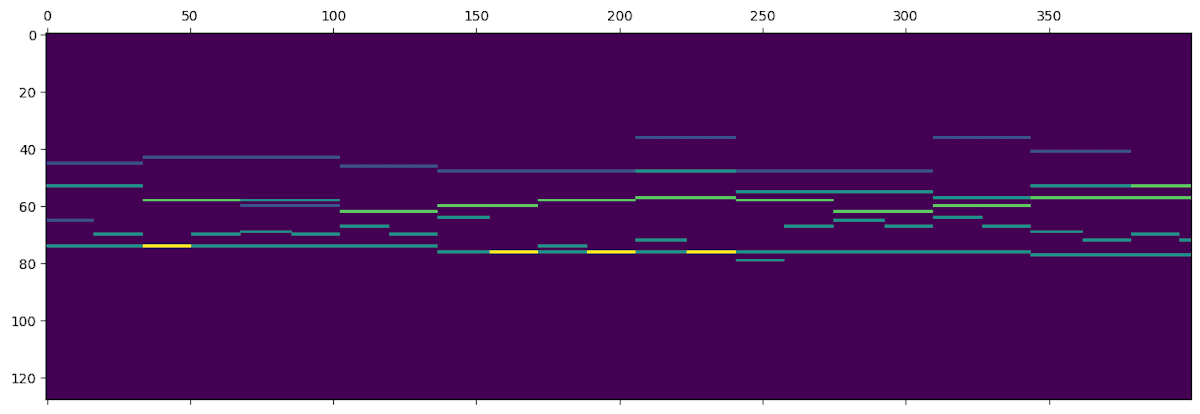
横軸は時刻。縦軸は音の高さです。色の明るさは音の重なりを表しており、色が明るいほど、同じ音が重なっていることを表しています。
MIDIファイルを読み込む関数を作成する。
ここで、MIDIファイルを読み込んで楽譜2値行列を返す部分を関数を定義します。
- MIDIファイルを以下の条件の場合、楽譜を機械学習や解析などで扱いやすい2値行列として返します。
- 条件1:楽譜を取得した時、その時間軸方向の要素数が指定したseqlen以上
- 条件2:調の変化が一回以下
- 条件3:テンポの変化が1回以下
- ハ長調またはハ短調に移調し、指定範囲のピッチと時間のデータだけを抽出して、解析しやすくしています。
MIDIファイルを読み込んで楽譜2値行列を返す部分を関数にしておきます。また、曲ごとにハ長調またはハ短調への移調も行っておきます。
ずらした方が、解析的にあっている気がするしますが、音楽の概念が理解できなかったため、ChatGPTによる回答を載せておきます。
MIDIファイルを読み込む関数を定義
import pretty_midi
import numpy as np
# 例外オブジェクトを作るためのクラスを定義
# 読み込んだMIDIファイルが本書が定める条件に合わない場合に
# このクラスによって定義される例外が投げられる
class UnsupportedMidiFileException(Exception):
"Unsupported MIDI File"
# 与えられたMIDIデータをハ長調またはハ短調に移調
# key_number: 調を表す整数(0--11: 長調、12--23: 短調)
def transpose_to_c(midi, key_number):
for instr in midi.instruments:
if not instr.is_drum:
for note in instr.notes:
note.pitch -= key_number % 12
# 与えられたMIDIデータから楽譜2値行列を取得
# nn_from: 音高の下限値(この値を含む)
# nn_thru: 音高の上限値(この値を含まない)
# seqlen: 読み込む長さ(時間軸方向の要素数、八分音符単位)
# tempo: テンポ
def get_pianoroll(midi, nn_from, nn_thru, seqlen, tempo):
pianoroll = midi.get_piano_roll(fs=2*tempo/60)
if pianoroll.shape[1] < seqlen:
raise UnsupportedMidiFileException
pianoroll = pianoroll[nn_from:nn_thru, 0:seqlen]
pianoroll = np.heaviside(pianoroll, 0)
return np.transpose(pianoroll)
# 指定されたMIDIファイルを読み込んで楽譜2値行列を返却
# filename: 読み込むファイル名
# sop_alto: ソプラノパートとアルトパートを別々に読み込む場合にTrue
# seqlen: 読み込む長さ(時間軸方向の要素数、八分音符単位)
def read_midi(filename, sop_alto, seqlen):
# MIDIファイルを読み込む
midi = pretty_midi.PrettyMIDI(filename)
# 途中で転調がある場合は対象外として例外を投げる
if len(midi.key_signature_changes) != 1:
raise UnsupportedMidiFileException
# ハ長調またはハ短調に移調する
key_number = midi.key_signature_changes[0].key_number
transpose_to_c(midi, key_number)
# 長調(keymode=0)か短調(keynode=1)かを取得する
keymode = np.array([int(key_number / 12)])
# 途中でテンポが変わる場合は対象外として例外を投げる
tempo_time, tempo = midi.get_tempo_changes()
if len(tempo) != 1:
raise UnsupportedMidiFileException
if sop_alto:
# パート数が2未満の場合は対象外として例外を投げる
if len(midi.instruments) < 2:
raise UnsupportedMidiFileException
# ソプラノ(1パート目)とアルト(2パート目)のそれぞれに対して
# 楽譜2値行列を取得する
pr_s = get_pianoroll(midi.instruments[0], 36, 84,
seqlen, tempo[0])
pr_a = get_pianoroll(midi.instruments[1], 36, 84,
seqlen, tempo[0])
return pr_s, pr_a, keymode
else:
# 全パートを1つにした楽譜を取得する
pr = get_pianoroll(midi, 36, 84, seqlen, tempo[0])
return pr, keymode
入力として、
-
filename(str):MIDIファイルのファイル名を指定します。 -
sop_alto(bool):ソプラノとアルトのパートを別々に読み込むかどうか(trueかfalse) -
seqlen(int):読み込む長さ(時間軸方向の要素)
returnとして、
- アルト、ソプラノの情報がある場合(パートが2つ以上)
-
pr_s:ソプラノパートの楽譜2値行列 -
pr_a:アルトパートの楽譜2値行列 -
keymode:長調(0)か短調(1)かを表す1要素の配列
-
- アルト情報がない時(パートが一つしかない時)
-
pr:全パートの楽譜2値行列 -
keymode:長調(0)か短調(1)かを表す1要素の配列
を返します。
-
試しに、上記の関数を使って、midiファイルの冒頭発症節分を表示してみます。
MIDIファイルを連続で読み込んで楽譜を描画してみる
import glob
import matplotlib.pyplot as plt
import numpy as np
dir = "drive/MyDrive/chorales/midi/"
files = []
for f in glob.glob(dir + "/*.mid"):
try:
print(f)
pianoroll, keymode = read_midi(f, False, 64)
plt.matshow(np.transpose(pianoroll))
plt.show()
except UnsupportedMidiFileException:
print("skip")
実行結果としての例

楽譜2値行列からMIDIデータを書き出す。
楽譜の2値行列からMIDIデータを生成し、ファイルとして保存する関数を作ります。
MIDIデータを書き出す関数を定義
import pretty_midi
# 与えられた楽譜2値行列からMIDIデータを生成し、ファイルに保存
# pianorolls: 楽譜2値行列(複数可)を格納した配列
# filename: 保存する際のファイル名
def make_midi(pianorolls, filename):
midi = pretty_midi.PrettyMIDI(resolution=480)
for pianoroll in pianorolls:
instr = pretty_midi.Instrument(program=1)
for i in range(pianoroll.shape[0]):
for j in range(pianoroll.shape[1]):
# 楽譜2値行列の各要素の値が0.5より大きいときに、
# その時刻にその音高の音を挿入する
if pianoroll[i][j] > 0.5:
instr.notes.append(pretty_midi.Note(start=0.50*i,
end=0.50*(i+1),
pitch=36+j,
velocity=100))
midi.instruments.append(instr)
midi.write(filename)
楽譜2値行列の各要素の値が0.5より大きいときとは、音符はその音がなっていない(0)となっている(1)で表現されているが、0.5以上とすることで、連続の1拍を480分割した秒数で、なっているか、なっていないかの境目を見分けます。
次に、これを視覚的に表現してみます。
MIDIデータを再生して楽譜を描画する関数を定義
import matplotlib.pyplot as plt
import IPython.display as ipd
import pretty_midi
from midi2audio import FluidSynth
# 与えられた楽譜2値行列からMIDIデータを作るのに加え、
# 楽譜2値行列を描画したり、再生できるようにする
def show_and_play_midi(pianorolls, filename):
# 楽譜2値行列を描画する
for pr in pianorolls:
plt.matshow(np.transpose(pr))
plt.show()
# MIDIデータを生成してファイルに保存する
make_midi(pianorolls, filename)
# MIDIデータをwavに変換してブラウザ上で聴けるようにする
fs = FluidSynth(sound_font="/usr/share/sounds/sf2/FluidR3_GM.sf2")
fs.midi_to_audio(filename, "output.wav")
ipd.display(ipd.Audio("output.wav"))
実際に、楽譜2値行列から、MIDIファイルを書き出せているか、視覚的にはどうか?を試してみる。
read_midi関数とshow_and_play_midi関数を使ってみる
filename = "drive/MyDrive/chorales/midi/011106b_.mid"
sop, alto, keymode = read_midi(filename, True, 64)
show_and_play_midi([sop, alto], "output.mid")

このような形で、それぞれのパートと、音声ファイルが出力されています。
メロディが長調か短調か判定してみる。
このプログラムの目的は、メインで扱うのは「メロディが与えられ」それが、「長調か短調か」を判定するニューラルネットワーク()です。
よって、
- 入力:楽譜2値行列
- 出力:長調
0、短調1
とします。
今回は、長調と短調を見分けます。

概念を知らない方は(私も含めて)、簡単に
- 長調:明るい印象
- 対応鍵盤:1,3,5,6,8,10,12
- 短調:暗い印象
- 対応鍵盤:1,3,4,6,8,9,11
を感じます。例として、youtubeで見てみましょう。
これを12種類あるので、12次元ベクトルで表現しましょう。
準備
ライブラインストール
PrettyMIDI、midi2audio、FluidSynthをインストール
!pip install pretty_midi
!pip install midi2audio
!apt install fluidsynth
前述のMIDIファイルを楽譜2値行列に変える関数を載せる。
MIDIファイルを読み込む関数を定義(前述済み)
import pretty_midi
import numpy as np
# 例外オブジェクトを作るためのクラスを定義
# 読み込んだMIDIファイルが定める条件に合わない場合に
# このクラスによって定義される例外が投げられる
class UnsupportedMidiFileException(Exception):
"Unsupported MIDI File"
# 与えられたMIDIデータをハ長調またはハ短調に移調
# key_number: 調を表す整数(0--11: 長調、12--23: 短調)
def transpose_to_c(midi, key_number):
for instr in midi.instruments:
if not instr.is_drum:
for note in instr.notes:
note.pitch -= key_number % 12
# 与えられたMIDIデータから楽譜2値行列を取得
# nn_from: 音高の下限値(この値を含む)
# nn_thru: 音高の上限値(この値を含まない)
# seqlen: 読み込む長さ(時間軸方向の要素数、八分音符単位)
# tempo: テンポ
def get_pianoroll(midi, nn_from, nn_thru, seqlen, tempo):
pianoroll = midi.get_piano_roll(fs=2*tempo/60)
if pianoroll.shape[1] < seqlen:
raise UnsupportedMidiFileException
pianoroll = pianoroll[nn_from:nn_thru, 0:seqlen]
pianoroll = np.heaviside(pianoroll, 0)
return np.transpose(pianoroll)
# 指定されたMIDIファイルを読み込んで楽譜2値行列を返却
# filename: 読み込むファイル名
# sop_alto: ソプラノパートとアルトパートを別々に読み込む場合にTrue
# seqlen: 読み込む長さ(時間軸方向の要素数、八分音符単位)
def read_midi(filename, sop_alto, seqlen):
# MIDIファイルを読み込む
midi = pretty_midi.PrettyMIDI(filename)
# 途中で転調がある場合は対象外として例外を投げる
if len(midi.key_signature_changes) != 1:
raise UnsupportedMidiFileException
# ハ長調またはハ短調に移調する
key_number = midi.key_signature_changes[0].key_number
transpose_to_c(midi, key_number)
# 長調(keymode=0)か短調(keynode=1)かを取得する
keymode = np.array([int(key_number / 12)])
# 途中でテンポが変わる場合は対象外として例外を投げる
tempo_time, tempo = midi.get_tempo_changes()
if len(tempo) != 1:
raise UnsupportedMidiFileException
if sop_alto:
# パート数が2未満の場合は対象外として例外を投げる
if len(midi.instruments) < 2:
raise UnsupportedMidiFileException
# ソプラノ(1パート目)とアルト(2パート目)のそれぞれに対して
# 楽譜2値行列を取得する
pr_s = get_pianoroll(midi.instruments[0], 36, 84,
seqlen, tempo[0])
pr_a = get_pianoroll(midi.instruments[1], 36, 84,
seqlen, tempo[0])
return pr_s, pr_a, keymode
else:
# 全パートを1つにした楽譜を取得する
pr = get_pianoroll(midi, 36, 84, seqlen, tempo[0])
return pr, keymode
入力データと出力データの形を整える。
i番目のオクターブに関して、各音の出現回数を計算し、12次元ベクトルの該当箇所に足していって、出現回数を算出して、正規化を行う。
戻り値として、x(各音の出現頻度)とy(音楽が短調か長調か)を返す。
入力データと出力データを求める関数を定義
# 入力データ(12次元ベクトル)、出力データ(0:長調、1:短調)を作成する
# pianoroll: 楽譜2値行列
# keymode: 長調・短調を表す整数(0:長調、1:短調)
def calc_xy(pianoroll, keymode):
# 12次元ベクトルを作って0で初期化する
x = np.zeros(12)
# i番目のオクターブに関して、各音名の出現回数を計算し、xに足し算
# これをくりかえして、オクターブを区別しない各音名の出現回数を計算
for i in range(int(pianoroll.shape[1] / 12)):
x += np.sum(pianoroll[:, i*12 : (i+1)*12], axis=0)
# xの合計値が1.0になるように正規化
if np.max(x) > 0:
x = x / np.sum(x)
y = keymode
return x, y
MIDIがファイルを読み込んで入力データ(各音階の出現割合)と出力データ(長調0と短調1)の組を作れたら、すべてのMIDIファイルを読み込んで、得られたデータをどんどん配列に格納していく。
MIDIファイルを読み込んでデータを配列に格納
import glob
# MIDIファイルを保存してあるフォルダへのパス
dir = "drive/MyDrive/chorales/midi/"
x_all = [] # 入力データを格納する配列
y_all = [] # 出力データを格納する配列
files = [] # 読み込んだMIDIファイルのファイル名を格納する配列
# 指定されたフォルダにある全MIDIファイルに対して
# 次の処理を繰り返す
for f in glob.glob(dir + "/*.mid"):
print(f)
try:
# MIDIファイルを読み込む
# pr_s:ソプラノパートの楽譜2値行列
# pr_a:アルトパートの楽譜2値行列
# keymode:調(長調:0、短調:1)
pr_s, pr_a, keymode = read_midi(f, True, 64)
# ニューラルネットワークに渡す入力・出力データに整える
x, y = calc_xy(pr_s, keymode)
# 入力データx、出力データy、ファイル名fを各配列に追加する
x_all.append(x)
y_all.append(y)
files.append(f)
# 要件を満たさないMIDIファイルの場合はskipと出力して次に進む
except UnsupportedMidiFileException:
print("skip")
# あとで扱いやすいように、x_allとy_allをNumPy配列に変換する
x_all = np.array(x_all)
y_all = np.array(y_all)
入力と出力のデータを確認します。
入力データと出力データの構造を確認する
print(x_all.shape)
print(y_all.shape)
出力結果としては、以下のようになります。
(269, 12)
(269, 1)
xに関しては269個の曲に対して、12次元のベクトルで表現されています。また、yに関しても同様に、1次元ベクトルと表現されています。
ニューラルネットワーク構築
これでようやく、ニューラルネットを構築します。
まず学習用の入力データと出力データ,1:1に分けます。
学習データとテストデータを分割する
from sklearn.model_selection import train_test_split
# 学習データとテストデータを1:1の割合で割り当てる
# i_train:学習データの添え字、i_test:テストデータの添え字
i_train, i_test = train_test_split(range(len(x_all)),
test_size=int(len(x_all)/2),
shuffle=False)
x_train = x_all[i_train]
x_test = x_all[i_test]
y_train = y_all[i_train]
y_test = y_all[i_test]
次に、TensorFlowを用いて、ニューラルネットワークを構築します。
- 入力:12次元の音階の出現頻度
- 出力:1次元の判定(0か1)
中間層は1層で、6つのニューロンで構成されています。
モデルを構築
import tensorflow as tf
# 空のモデルを作る
model = tf.keras.Sequential()
# 中間層を作って空のモデルに追加する(入力層は勝手にできる)
model.add(tf.keras.layers.Dense(6, input_dim=12,
use_bias=True,
activation="sigmoid"))
# 出力層を作ってモデルに追加する
model.add(tf.keras.layers.Dense(1, use_bias=True,
activation="sigmoid"))
# 最後の設定を行う
model.compile(optimizer="adam", loss="binary_crossentropy",
metrics=["binary_accuracy"])
# モデルの構造を画面出力する
model.summary()
- 学習の結果: モデルが x_train の各要素を入力すると、y_train の各要素(0または1)が正確に予測されるように、モデルのパラメータが最適化されます。
- 精度の向上: 学習を繰り返すことで、モデルは x_train と y_train の対応関係をより正確に学習し、新しいデータに対しても適切に予測できるようになります。
モデルを学習
# x_trainの各要素を入力したらy_trainの各要素が出力されるように
# モデルを学習する(モデルのパラメータの値を決める)
model.fit(x_train, y_train, batch_size=32, epochs=1000)
バッチサイズを32にすることで、1度に32個のサンプルを使ってモデルのパラメータの更新します。
また、学習の反復回数を指定します。モデルがデータセット全体を1000回繰り返して学習します。
モデルを先ほど分けた評価データを使って精度を確認します。
モデルの精度を評価
# テストデータを与えてモデルを評価する
# x_test:テスト用入力データ、y_test:テスト用正解出力データ
model.evaluate(x_test, y_test)
実行例
[0.06447028368711472, 0.9838709831237793]
一つ目のは、損失値、二つ目の数値は精度でモデルがかなり正確であることが確認できます。
実際に試してみる。
ランダムなテストデータから、ニューラルネットワークの結果と実際にMIDIデータを聞いてみて聴き比べてみる。
テストデータの入力データをモデルに与えて実行してみます。
# モデルにテストデータを与えて出力データを予測(計算)する
y_pred = model.predict(x_test)
ニューラルネットワークの出力を確認する
import random
import IPython.display as ipd
from midi2audio import FluidSynth
# ランダムに1つテストデータを選ぶ
k = random.randint(0, len(i_test))
print("melody id: ", k)
print("correct: ", y_test[k]) # 正解データ(0:長調、1:短調)
print("prediction: ", y_pred[k]) # 出力(予測)データ
# 音を合成するためのオブジェクトを生成する
fs = FluidSynth(sound_font="/usr/share/sounds/sf2/FluidR3_GM.sf2")
# MIDIデータをwavに変換する
fs.midi_to_audio(files[i_test[k]], "output.wav")
# ブラウザ上でwavデータを再生する部品を表示する
ipd.display(ipd.Audio("output.wav"))
私の結果としては、以下のようになりました。確かに悲しい曲でした。(zennに音楽ファイルが載せられないのが残念です。)

ハモリをAIで作ってみる。
今回は、メロディが与えられて、それにハモリパートをつけるという問題を扱います。様々なパートをつけると大変なので、「ソプラノパートにアルトパートでハモる。」ということにします。
前回の内容を踏襲して、
- 入力:ソプラノ楽譜2値行列
- 出力:アルト楽譜2値行列
とします。ただし、全てを作ってしまうと大変なので、簡単化のために最初の8小節のみを使うことにします。(そのため、それより短い場合は使わないこととします。)
入力の構造としては、リカレントニューラルネットワークを用いて、(n-1)番目の音符がの情報が、n番目の音符の情報ぬ影響を与えられるように設計します。
具体的には、
n番目のソプラノパートの音高ベクトルXnから、中間層Znを経由して、n番目の音高ベクトルYnを決めます。ここに、中間層Zn-1を入力することで、直前の音を考慮しつつ、決定することができます。
具体的には、以下のような図になります。
入出力をいじる
現在の楽譜入力と出力の条件を決めていきます
- わかりやすくするために8分音符ごとに区切られているとします。
- メロディの長さも曲によりますが、8小節までを生成する(8小節未満は楽曲を使わない)こととします。
- ソプラノ、アルトどちらもパート内で複数の音が同時にならないこととします。
以上が入出力の制限です。
加えて、入出力データをone-hotベクトルに変換していきます。
理由としては、今の楽譜2値行列は、音がなっていない場所は0、音がなっている場所は1となっている。この時、休符などの全く音がなっていないところが学習の効率を下げてしまう。
具体的には、
- 楽譜ベクトル:
[0,0,0,0,0,0,0,0]=[ド,レ,ミ,ファ,ソ,ラ,シ,ド] - one-hotベクトル:
[0,0,0,0,0,0,0,0,1]=[ド,レ,ミ,ファ,ソ,ラ,シ,ド,休符]
としたときに、one-hotベクトルの特徴として、
- 利点1:データが欠損した状態(またはデータがない状態)と休符の状態を見分けられる。
- 利点2;全てのデータを
0としないことで勾配消失を回避する。
そのため、入手力データをone-hotベクトルにしています。
準備
実際に、作っていきます。
PrettyMIDI、midi2audio、PluidSynthをインストール
!pip install pretty_midi
!pip install midi2audio
!apt install fluidsynth
MIDIファイルを読み込む関数を定義する(前述済み)
import pretty_midi
import numpy as np
# 例外オブジェクトを作るためのクラスを定義
# 読み込んだMIDIファイルが本書が定める条件に合わない場合に
# このクラスによって定義される例外が投げられる
class UnsupportedMidiFileException(Exception):
"Unsupported MIDI File"
# 与えられたMIDIデータをハ長調またはハ短調に移調
# key_number: 調を表す整数(0--11: 長調、12--23: 短調)
def transpose_to_c(midi, key_number):
for instr in midi.instruments:
if not instr.is_drum:
for note in instr.notes:
note.pitch -= key_number % 12
# 与えられたMIDIデータから楽譜2値行列を取得
# nn_from: 音高の下限値(この値を含む)
# nn_thru: 音高の上限値(この値を含まない)
# seqlen: 読み込む長さ(時間軸方向の要素数、八分音符単位)
# tempo: テンポ
def get_pianoroll(midi, nn_from, nn_thru, seqlen, tempo):
pianoroll = midi.get_piano_roll(fs=2*tempo/60)
if pianoroll.shape[1] < seqlen:
raise UnsupportedMidiFileException
pianoroll = pianoroll[nn_from:nn_thru, 0:seqlen]
pianoroll = np.heaviside(pianoroll, 0)
return np.transpose(pianoroll)
# 指定されたMIDIファイルを読み込んで楽譜2値行列を返却
# filename: 読み込むファイル名
# sop_alto: ソプラノパートとアルトパートを別々に読み込む場合にTrue
# seqlen: 読み込む長さ(時間軸方向の要素数、八分音符単位)
def read_midi(filename, sop_alto, seqlen):
# MIDIファイルを読み込む
midi = pretty_midi.PrettyMIDI(filename)
# 途中で転調がある場合は対象外として例外を投げる
if len(midi.key_signature_changes) != 1:
raise UnsupportedMidiFileException
# ハ長調またはハ短調に移調する
key_number = midi.key_signature_changes[0].key_number
transpose_to_c(midi, key_number)
# 長調(keymode=0)か短調(keynode=1)かを取得する
keymode = np.array([int(key_number / 12)])
# 途中でテンポが変わる場合は対象外として例外を投げる
tempo_time, tempo = midi.get_tempo_changes()
if len(tempo) != 1:
raise UnsupportedMidiFileException
if sop_alto:
# パート数が2未満の場合は対象外として例外を投げる
if len(midi.instruments) < 2:
raise UnsupportedMidiFileException
# ソプラノ(1パート目)とアルト(2パート目)のそれぞれに対して
# 楽譜2値行列を取得する
pr_s = get_pianoroll(midi.instruments[0], 36, 84,
seqlen, tempo[0])
pr_a = get_pianoroll(midi.instruments[1], 36, 84,
seqlen, tempo[0])
return pr_s, pr_a, keymode
else:
# 全パートを1つにした楽譜を取得する
pr = get_pianoroll(midi, 36, 84, seqlen, tempo[0])
return pr, keymode
MIDIデータを書き出す関数を定義(前述済み)
import pretty_midi
# 与えられた楽譜2値行列からMIDIデータを生成し、ファイルに保存
# pianorolls: 楽譜2値行列(複数可)を格納した配列
# filename: 保存する際のファイル名
def make_midi(pianorolls, filename):
midi = pretty_midi.PrettyMIDI(resolution=480)
for pianoroll in pianorolls:
instr = pretty_midi.Instrument(program=1)
for i in range(pianoroll.shape[0]):
for j in range(pianoroll.shape[1]):
# 楽譜2値行列の各要素の値が0.5より大きいときに、
# その時刻にその音高の音を挿入する
if pianoroll[i][j] > 0.5:
instr.notes.append(pretty_midi.Note(start=0.50*i,
end=0.50*(i+1),
pitch=36+j,
velocity=100))
midi.instruments.append(instr)
midi.write(filename)
MIDIデータを再生して楽譜を描画する関数を定義する(前述済み)
import matplotlib.pyplot as plt
import IPython.display as ipd
import pretty_midi
from midi2audio import FluidSynth
# 与えられた楽譜2値行列からMIDIデータを作るのに加え、
# 楽譜2値行列を描画したり、再生できるようにする
def show_and_play_midi(pianorolls, filename):
# 楽譜2値行列を描画する
for pr in pianorolls:
plt.matshow(np.transpose(pr))
plt.show()
# MIDIデータを生成してファイルに保存する
make_midi(pianorolls, filename)
# MIDIデータをwavに変換してブラウザ上で聴けるようにする
fs = FluidSynth(sound_font="/usr/share/sounds/sf2/FluidR3_GM.sf2")
fs.midi_to_audio(filename, "output.wav")
ipd.display(ipd.Audio("output.wav"))
ここからが新規要素です。楽譜2値行列に対して、休符を表す列おしりに足します。
休符要素を追加する関数を定義
# 楽譜2値行列に休符要素を追加する
def add_rest_nodes(pianoroll):
# 楽譜2値行列の時刻ごとの各音高ベクトルに対して、
# 全要素が0のときに1、そうでないときに0を格納したデータ
# (休符要素系列と呼ぶ)を作る
rests = 1 - np.sum(pianoroll, axis=1)
# 休符要素系列に2次元配列化して行列として扱えるようにする
rests = np.expand_dims(rests, 1)
# 楽譜2値行列と休符要素系列をくっつけた行列を作って返す
return np.concatenate([pianoroll, rests], axis=1)
sum(pianoroll, axis=1)は1行内の要素での合計(1か0)を表しています。(axis=0は1列内で計算)
よって、具体的には、
pianoroll = np.array([
[0, 0, 0, 0, 0, 0, 0, 1], # 1番目の行(8列目の音符が鳴っている)
[0, 0, 0, 0, 0, 0, 0, 0], # 2番目の行(休符)
[1, 0, 0, 0, 0, 0, 0, 0], # 3番目の行(1列目の音符が鳴っている)
[0, 0, 0, 0, 0, 0, 1, 0], # 4番目の行(7列目の音符が鳴っている)
[0, 0, 0, 0, 0, 0, 0, 0], # 5番目の行(休符)
])
の時、
sum(pianoroll, axis=1)=[1,0,1,1,0]
となり、
rests = 1 - np.sum(pianoroll, axis=1)=[0,1,0,0,1]
となります。これで、休符の情報を表せたので、 9列目にくっつけてあげて、
[[0 0 0 0 0 0 0 1 0] # 1行目: 音符があり、休符ではない
[0 0 0 0 0 0 0 0 1] # 2行目: 休符
[1 0 0 0 0 0 0 0 0] # 3行目: 音符があり、休符ではない
[0 0 0 0 0 0 1 0 0] # 4行目: 音符があり、休符ではない
[0 0 0 0 0 0 0 0 1]] # 5行目: 休符
というような形になります。
次に、MIDIファイルから、ソプラノとアルトのデータを冒頭から64個分(8分音符で8小節)で抽出し、one-hotベクトルの形に直して、配列の形で保存していきます。(ここでアルトパートを正解値として扱うために、2パート未満のものは対象外とします。)
MIDIファイルを読み込んでデータを配列に格納する
import glob
# MIDIファイルを保存してあるフォルダへのパス
dir = "drive/MyDrive/chorales/midi/"
x_all = [] # 入力データ(ソプラノメロディ)を格納する配列
y_all = [] # 出力データ(アルトメロディ)を格納する配列
keymodes = [] # 長調か短調かを格納する配列
files = [] # 読み込んだMIDIファイルのファイル名を格納する配列
# 指定されたフォルダにある全MIDIファイルに対して
# 次の処理を繰り返す
for f in glob.glob(dir + "/*.mid"):
print(f)
try:
# MIDIファイルを読み込む
# pr_s:ソプラノパートの楽譜2値行列
# pr_a:アルトパートの楽譜2値行列
# keymode:調(長調:0、短調:1)
pr_s, pr_a, keymode = read_midi(f, True, 64)
# 楽譜2値行列に休符要素を追加する
x = add_rest_nodes(pr_s)
y = add_rest_nodes(pr_a)
# 休符要素を追加した楽譜2値行列などを配列に追加する
x_all.append(x)
y_all.append(y)
keymodes.append(keymode)
files.append(f)
# 要件を満たさないMIDIファイルの場合はskipと出力して次に進む
except UnsupportedMidiFileException:
print("skip")
# あとで扱いやすいように、x_allとy_allをNumPy配列に変換する
x_all = np.array(x_all)
y_all = np.array(y_all)
データの構造を確認する
print(x_all.shape)
print(y_all.shape)
出力結果としては、以下のようになります。
(495, 64, 49)
(495, 64, 49)
xに関しては495個のシートに、64行49列の行列で表現されています。また、yに関しても同様です。
ここで、495はサンプル数、64は8分音符×8小節の時間、49は12階の音程×4オクターブ分+1つの休符情報を表しています。
リカレントニューラルネットワークを構築
ここからが、本題です。
学習データとテストでーたを1:1の割合で分割する。
学習データとテストデータを分割します。
from sklearn.model_selection import train_test_split
# データを1:1の割合で学習データとテストデータに分割する
x_train, x_test, y_train, y_test = train_test_split(x_all, y_all, test_size=0.5, shuffle=False)
ここで、リカレントニューラルネットワークを構成します。
前のニューラルネットワークと違う点は、中間層が変化します。
具体的には、tf.keras.layers.Denseがtf.keras.layers.SimpleRNNとします。
モデルを構築する
import tensorflow as tf
seq_length = x_train.shape[1] # 時系列の長さ(時間方向の
# 要素数)
input_dim = x_train.shape[2] # 入力の各要素の次元数
output_dim = y_train.shape[2] # 出力の各要素の次元数
# 空のモデルを作る
model = tf.keras.Sequential()
# RNN層を作ってモデルに追加する
model.add(tf.keras.layers.SimpleRNN(
128, input_shape=(seq_length, input_dim), use_bias=True,
activation="tanh", return_sequences=True))
# 出力層を作ってモデルに追加する
model.add(tf.keras.layers.Dense(
output_dim, use_bias=True, activation="softmax"))
# 最後の設定を行う
model.compile(optimizer="adam", loss="categorical_crossentropy",
metrics=["categorical_accuracy"])
# モデルの構造を画面出力する
model.summary()
seq_lengthは、時間の要素数(64)、input_dimは入力の音高数(49)を表しています。
return_sequences=Trueこれにより、RNN層はすべてのタイムステップの出力を次の層に渡します(出力が時系列の形状を保持する)。
出力層で、output_dimを指定することで、出力の音高数(49)に整えています。
32個のデータごとに1000回学習させます。
モデルを学習する
# x_train[i]を入力したらy_train[i]が出力されるように
# モデルを学習する(モデルのパラメータの値を決める)
model.fit(x_train, y_train, batch_size=32, epochs=1000)
モデルの精度を評価する
# テストデータを与えてモデルを評価する
# x_test:テスト用入力データ、y_test:テスト用正解出力データ
model.evaluate(x_test, y_test)
以下は具体的な結果です。
[2.5963213443756104, 0.41872480511665344]
損失値が、約2.6。精度が40%ほどです。
正解との一致率が高くないですが、実際に聞いてみた場合と比べてみてください。
入力データだけを与えてハモリパートを生成する
# モデルにテストデータのソプラノを与えてアルトを予測(生成)する
y_pred = model.predict(x_test)
ハモリパート生成結果を聴いてみる
# # ランダムデータを選択する。(コメントをといて、k=0をコメントアウト)
# import random
# k = random.randint(0, len(x_test))
# 0番目のデータを選択
k =0
# 選択したデータのアルトの生成結果を聴けるようにする
show_and_play_midi([x_test[k, :, 0:-1], y_pred[k, :, 0:-1]],
"output.mid")
ここまで、実装された方は、気づいたかもしれませんが、生成されたハモリパートはそこまで不快感を持つものではなく、むしろある程度ハモっているように聞こえます。
これは、メロディを生成する上で、先に抜き出したアルトパートだけが唯一の正解ではないことが一致率が低いことの要因だと考えられます。
私が投入したデータは一つの答えではありますが、それぞれのソプラノパートにあるアルトのハモリとしての答えは複数存在しています。その中の一つと比較しても、一致率は高くないことが考えられます。
これはAIと音楽の相性として難しい側面ではありますが、かなり面白い特徴です。
要は、AIが「このハモリはあってない」と考えても、人間的には「いい感じじゃん」と感じることもしばしばあるということです。
これからの時代食いっぱぐれないのは音楽家なのかもしれません。
最後に
今回は音楽でAIを試してみました。前回に引き続きかなり勉強になりましたが、まだまだ精進が必要だと感じています。がんばります。
Discussion