はじめに
SUPER STUDIOでは ecforce というEC構築システムをSaaSという形で提供しています。
ecforceの導入を希望されるクライアント様には、大きく2つのパターンがあります。
- 新規でECを立ち上げたいクライアント様
- 元々別のカートシステムを使っており、ecforceに移行したいクライアント様
後者については、当然ながら既に蓄積されている顧客データや注文データをリセットするわけにはいかないので、 既存データも引き継ぎたい という要望をいただくことが大多数です。
しかし、他社のカートシステムとecforceではデータの構造が異なるので、抽出したデータをそのままecforceのデータベースにインポートできるわけではありません。
既存のデータを引き継ぐためには、
- データを抽出し
- 加工した上で
- ecforceのデータベースにインポートする
という手順を踏む必要があります。
これを社内では 移行業務 と呼んでおり、SUPER STUDIOにはこの移行業務を担う専門チームが存在します。
本題
顧客情報が載ったCSVを取り扱う上での課題
顧客情報が載ったCSVを取り扱う上での課題は以下3つが挙げられます。
- 膨大な顧客情報のデータを高速で検索する
- 新規参画メンバーのハードルを下げる
- CSV内の欠損データや処理できない文字をクライアント様に共有する
膨大な顧客情報のデータを高速で検索する
クライアント様によっては、膨大なデータ量を取り扱っているケースがあります。そのため、ローカルでCSVを開くと画面が固まってしまうことも稀ではありません。
新規参画メンバーのハードルを下げる
移行業務では覚えることがたくさんあるので、新規参画メンバーの学習コストをなるべく最小限に留めることが必要です。
CSV内の欠損データや処理できない文字をクライアント様に共有する
欠損データや処理できない文字が含まれていた場合、対象データをクライアント様へ共有する必要があります。
課題解決
SUPER STUDIOでは、これらの課題を解決するために Amazon Athena を使っています。
Amazon Athenaは、AWSのデータ分析サービスの一つで、Amazon S3に格納されているデータを直接分析し、操作することができます。
Amazon Athenaの導入により、主に以下の点が実現できるようになりました。
膨大な顧客情報のデータを高速で検索できる
Amazon Athenaを使用し、CSVを parquet 形式に変換することで、より高速に顧客情報のデータを検索できます。
高速化できる理由については、後ほど改めて説明します。
SQLと同じように検索できる
生SQLのなかでも特にSELECT文さえ習得しておけば、エンジニアだけでなく非エンジニアの方でもCSVを検索することができます。
以下のようにWHEREでの絞り込みもできますし、
SELECT * FROM "customer" WHERE "顧客番号" = 'TEST123';
JOINで別のCSVとの結合も可能です。
SELECT
"order"."顧客番号"
FROM
"customer"
INNER JOIN
"order"
ON
"customer"."顧客番号" = "order"."顧客番号"
where
"order"."顧客番号" = 'TEST123'
;
また、列のグルーピングや並び替えもできます。
SELECT "注文番号", count(*) FROM "order" GROUP BY "注文番号" HAVING count(*) >= 2 ORDER BY "注文番号" DESC;
クエリ結果をCSVに変換してダウンロードできる
欠損データや処理できない文字が含まれていた場合、Amazon Athenaでクエリを実行し、対象データを絞った上でCSVを出力します。
その結果、クライアント様とのやり取りがスムーズに行えます。
Athenaの料金体系
Amazon Athenaは、実行したクエリで スキャンされたデータ量 に基づいて課金されます。
公式 によると、 1TBあたりのスキャンで$5 (2024年5月現在) となっています。
移行業務における1回あたりのスキャンは多くて数百MBですので、ほとんどコストがかかっていません。
なぜデータ検索を高速化できるのか
行指向と列指向
まずは 行指向 と 列指向 という言葉の意味と、それぞれの特徴について説明します。
行指向とは 行ごとに処理 する方式で、CSVやRDBMSなどが該当します。
一方、列指向は 列ごとに処理 する方式で、今回ご紹介するparquetなどが該当します。
こちらの内容だけではイメージしにくいと思うので、 スキャンする範囲 という観点で例を挙げて説明します。
例えば以下のようなテーブルと、それに対するクエリがあったとします。
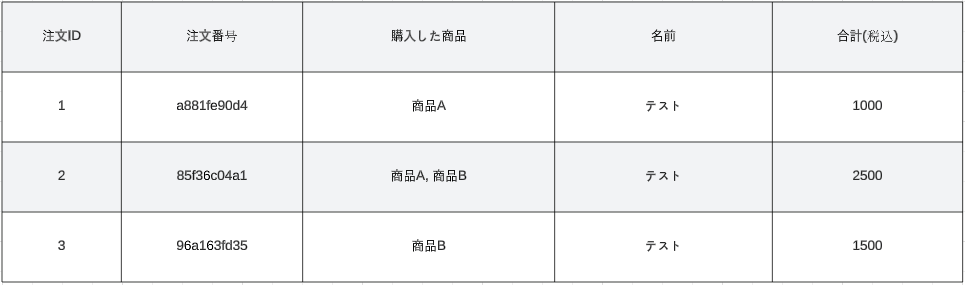
SELECT "注文番号", count(*) FROM "order" GROUP BY "注文番号" HAVING count(*) >= 2
行指向でスキャンされる範囲は、以下の通り全てです。
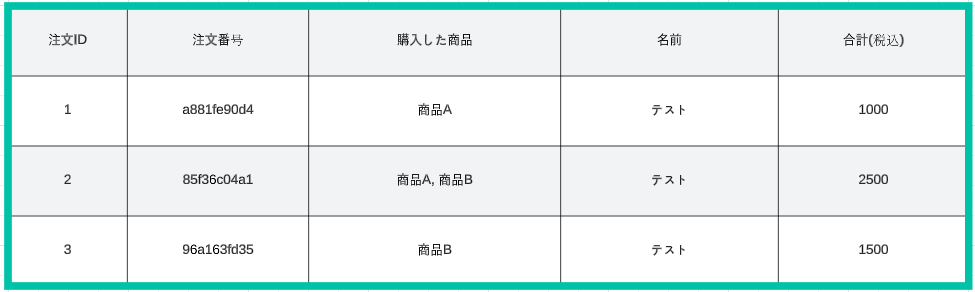
一方で列指向でスキャンされる範囲は、以下の通りグルーピング対象の 注文番号のみ です。
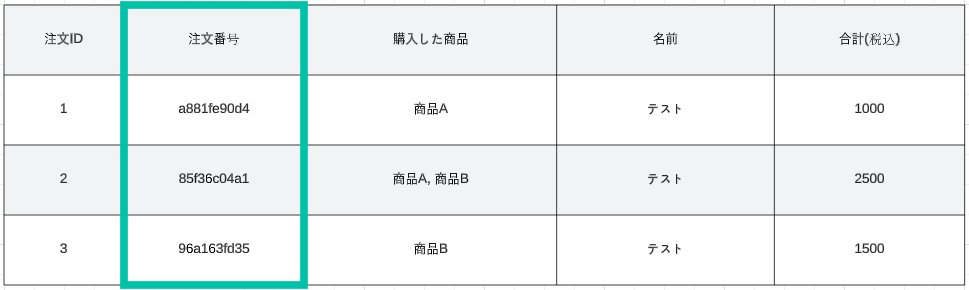
このように、列指向の方が スキャンする範囲 が圧倒的に狭いため、行指向よりも高速で検索することができます。
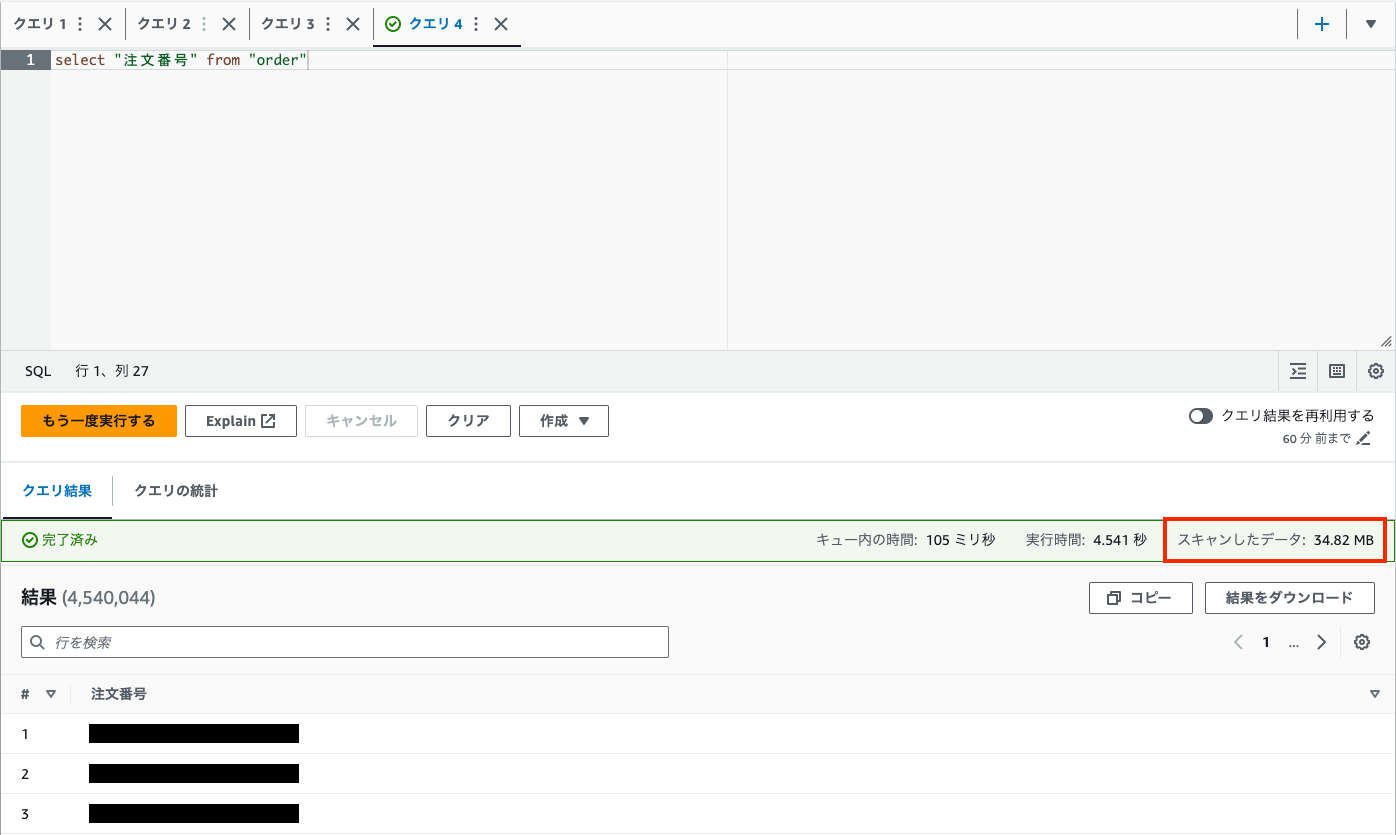
以下のように、列指向でスキャンされたデータ量は34.82MBとなっていますが、ファイル全体のデータ量は671.7MBです。
この結果から、いかにスキャンすべき列を絞っているかが分かると思います。
CSVをS3にアップロードし、Amazon Athenaで検索できるまでの流れ
顧客データをS3にアップロードしただけでは、Amazon Athenaでの検索はできません。
顧客データをS3へアップロード後にAmazon Athenaで検索できるまで、どのように処理を自動化させたかについて説明します。
主な流れは以下の通りです。
- CSVをS3にアップロード
- Amazon EventBridgeが変更を検知
- AWS Lambdaが起動(Amazon Athenaのテーブル作成 + CSVをparquet形式に変換)
Eventは以下のように定義しています。
ファイルがアップロードされたのち (= Object Created) というイベントを設定しています。
s3-xxx-create-event:
- eventBridge:
pattern:
source:
- aws.s3
detail-type:
- Object Created
detail:
bucket:
name:
- xxx-xxx-xxx
次にAWS Lambdaの本体コードです。
主に以下3つの処理を1つのfunctionで行っています。
- ファイルエンコーディング
- CSVをparquet形式に変換
- Amazon Athenaのテーブル作成
今後の課題
今後、数千万件ほどの注文データを抱える案件に対処するとなった場合、現状の仕組みでは対応できない可能性があります。
例えば AWS Lambdaの処理時間(15分) の制限に引っかかったり、スペックの調整が必要になることが考えられます。
また、列指向のメリットを活かすために、parquetファイルを適切なサイズに分割する必要があります。
まとめ
いかがでしたでしょうか。
今回は移行業務におけるAmazon Athenaの活用方法から、行指向と列指向の違いやデータ検索の高速化について説明しました。
今回の事例のように処理を自動化させておくことで、CSVのアップロード以外のことを意識せずに済み、大幅に業務を効率化できたと思います。
Amazon Athenaは他にも色々な活用方法があるので、機会があれば使っていきたいと思います。
SUPER STUDIOの採用について
SUPER STUDIOでは、積極的にエンジニアを採用しています。
少しでも興味がありましたら、以下の記事をご覧ください。
また、下記はSUPER STUDIOで年に一度開催されるKICKOFFイベントにて、社内表彰されたエンジニアの受賞インタビューです。SUPER STUDIOのエンジニア組織についてより理解を深められる内容となっておりますので、ぜひご一読ください。

Discussion