はじめに
弊社では ecforce というシステムをSaaSという形でサービスを提供しています。
ecforceの導入を希望されるクライアント様には、大きく2パターンがあります。
-
新規でECを立ち上げたいというクライアント様 - 別のカートシステムを現在使っており、ecforceに乗り換えたいというクライアント様
後者につきまして、当然ながら顧客や注文データをリセットするわけにもいかないので、 既存データも引き継ぎたい という要望をいただくことが大多数です。
ただ他社のカートシステムとecforceではデータ構造が異なるので、データを抽出してそのままecforceのデータベースにインポートできるわけではありません。
この後者の要望を叶えるためにはデータを
- 抽出し
- 加工した上で
- ecforceのデータベースにインポートする
という手順を踏む必要があります。
これを社内では 移行業務 と呼んでおり、弊社にはこの移行業務を行う専門チームがあります。
本題
ここまでの章で、移行業務における データの加工 と インポート についての仕組みづくりに関してを述べました。
ここから更にエンジニアの属人化を解消したり、画面操作で移行業務ができるようにするために、UIの実装やAWSを用いたインフラ実装が必要になりました。
- CSVを整理できる
- 移行元CSVのデータチェックができる
- テスト環境をボタン1つで構築できる
- レシピを作成、編集できる
- レシピを実行できる
- データベースへのインポートを実行できる
- DBのダンプを作成できる
- テスト環境にDBのダンプを適用できる
- インポート後に異常データのチェックができる
- インポート後に ecforceの管理画面でデータを閲覧できる
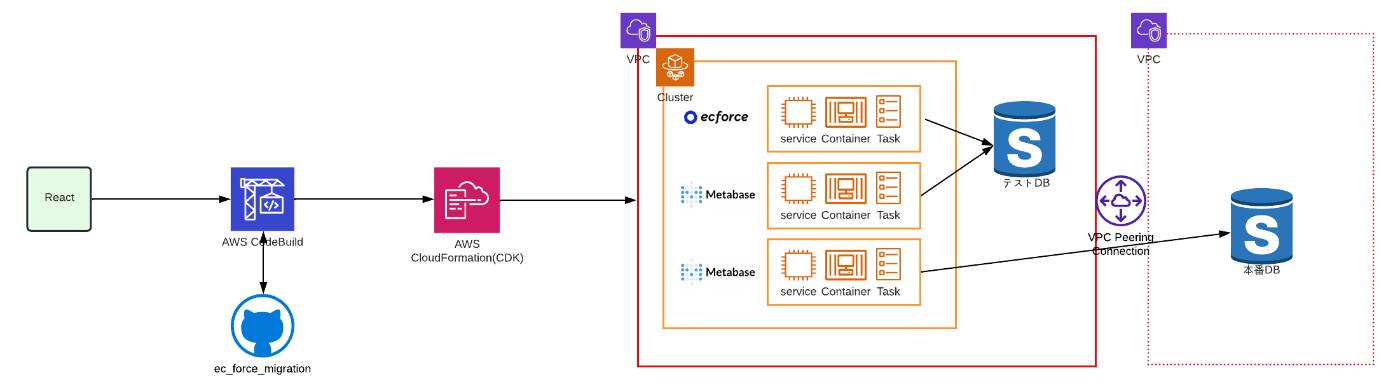
その結果出来上がったのが、データ移行自動化システム ecforce data transfer です。
UIやシステムの構成図を以下に示します。
システム構成図
CSVを整理できる
CSVを整理するにあたって、AWSの Event Bridge と Lambda を使用しています。
手順としては以下の通りです。
- 他社カートから出力されたCSVを置く
- EventBridgeが検知する
- LambdaがCSVをUTF-8に変換する
- 別のEventBridgeが検知する
- Athenaを使ってCSVの中身が見られるので、CSVをparquet形式に変換する

これによって、他社カートから出力されたCSVを置くだけでCSVの配置が完了します。
移行元CSVのデータチェックができる
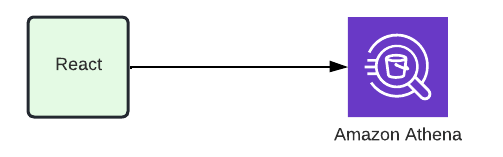
移行元CSVのデータチェックをするにあたり、AWSの Athena を使用しています。
フロントからAthenaのクエリを実行し、CSVのデータチェックができます。
先程変換したparquet形式のファイルは列指向なので、件数が多くても数秒で結果が返ってきます。
インポート後にデータの確認ができる
ecforce data transferではインポート後にデータを確認する方法として以下二つが挙げられます。
- ecforce管理画面を開く
- クエリを叩いて、データの異常を検知できる
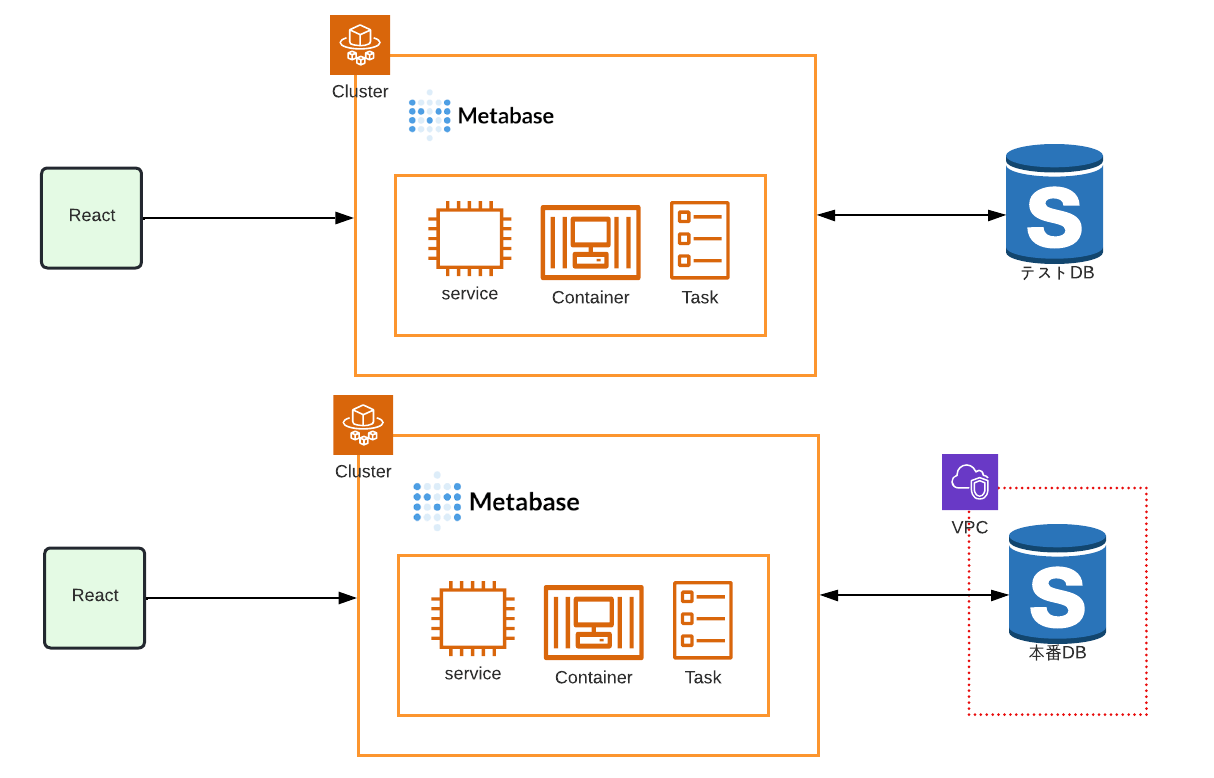
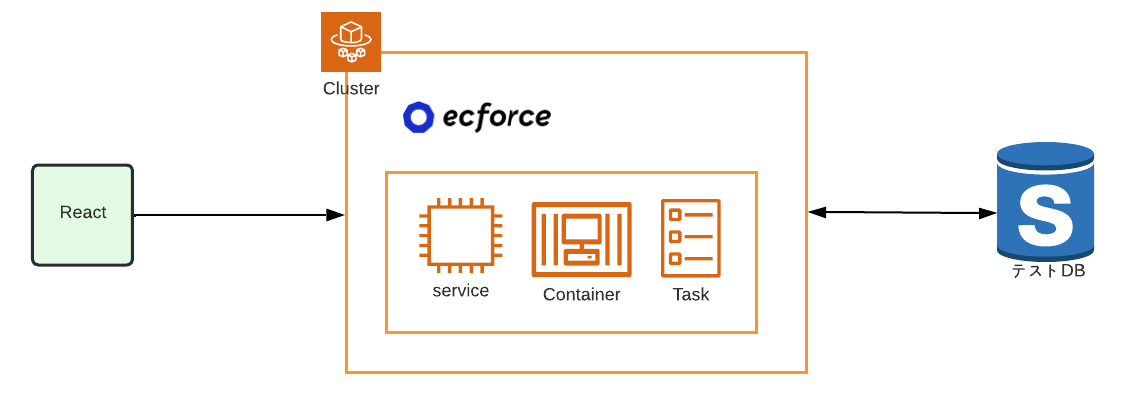
これらは ECS で起動、実行環境は Fargate を採用しています。
さらにこれらをボタン一つで構築できる機能も用意しています。
流れとしては以下の通りです。
- テスト環境作成ボタンを押す
- CodeBuildがリポジトリと連携しており、CDKが実行される
- CloudFormation経由でスタックを作成する
レシピを作成、編集できる
3章 で触れました レシピ を、ecforce data transfer上で作成編集をすることができます。
インフラ構成としてはシンプルで、S3とのやり取りのみです。
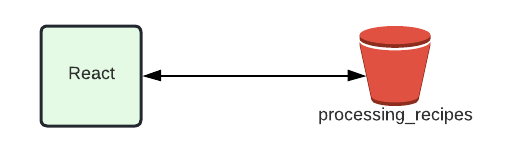
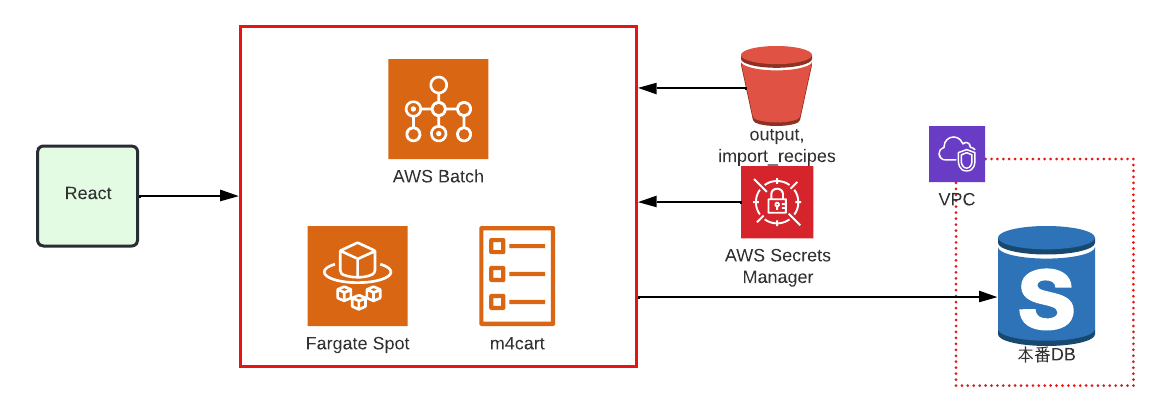
本番DBからダンプを作成できる
本番DBからのダンプ作成は AWS Batch を使用し、コンテナ上でPythonを実行しています。
別のVPCにある本番DBに接続しダンプを取得し、S3へアップロードするという流れです。
また実行環境は Fargate Spot を採用しています。
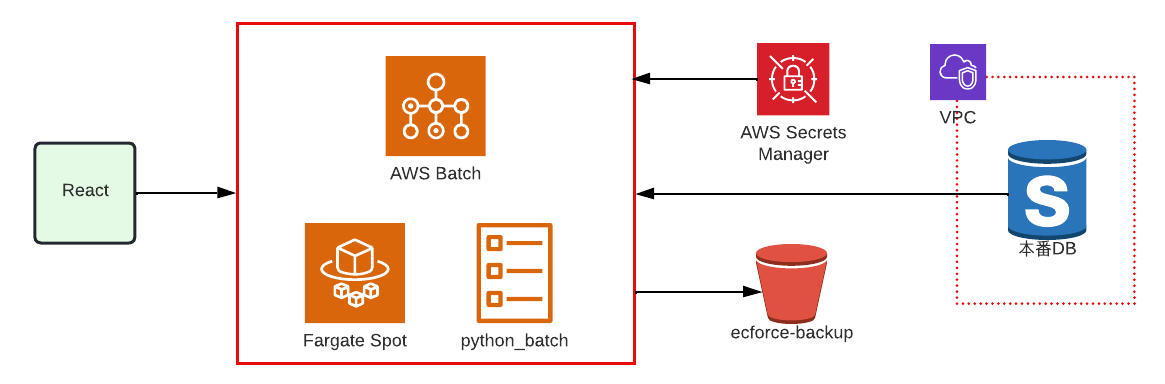
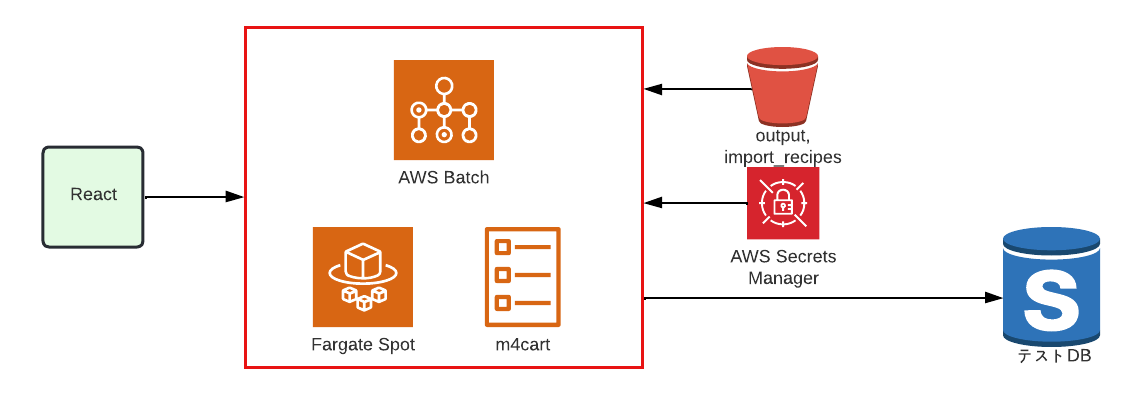
テスト環境にDBのダンプを適用できる
テストDBへのダンプ適用も同様に AWS Batch 、実行環境は Fargate Spot を使用しています。
コンテナ上でPythonを実行しています。
S3を参照しテストDBにダンプを適用するという流れです。
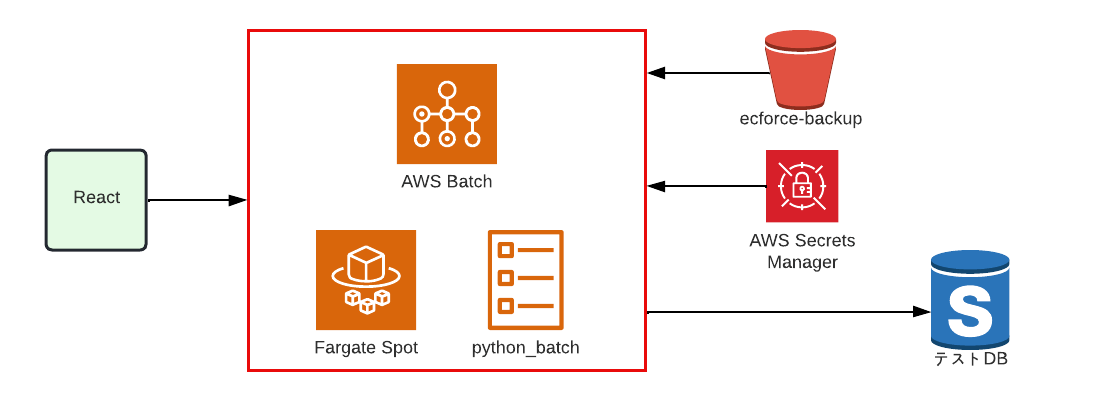
レシピを実行できる
レシピの実行も同様に AWS Batch 、実行環境は Fargate Spot を使用しています。
コンテナ上でPythonを実行しています。
S3からレシピを取得し、出来上がった中間CSVをS3にアップロードするという流れです。
また実行環境は Fargate Spot を採用しています。
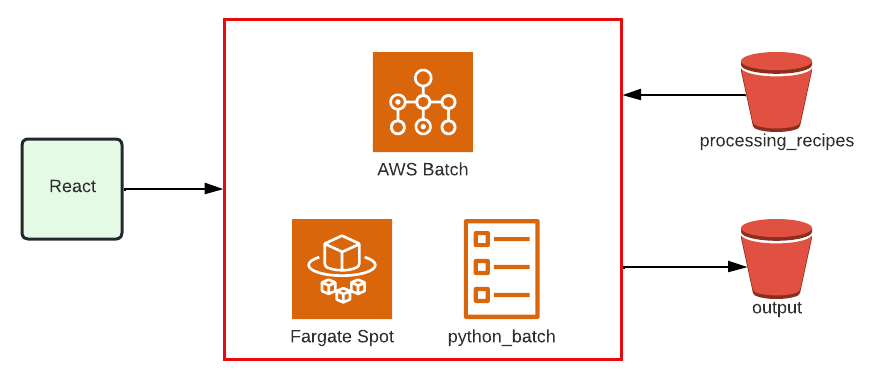
データベースへのインポートを実行できる
データベースへのインポートも同様に AWS Batch 、実行環境は Fargate Spot を使用しています。
コンテナ上でRuby(Rails)スクリプトを実行し、part1で触れたように、バルクなSQLと並列処理で一気にデータをインポートします。
ちなみに本番データベースへのインポートは VPCピアリング という別のネットワークを跨いで通信できるような技術を使っています。
まとめ
いかがでしたでしょうか。
今回はエンジニアの脱属人化や効率化に伴う、移行業務のシステム化についてまとめました。
また5章に渡り、移行業務の進化についてまとめました。
- SQLのチューニングによる高速化
- スクリプトの並列化
- データの「加工」を分離させ、さらに高速化
- コンテナ化による脱環境依存
- 移行業務のシステム化
この5つをすべて行なったからこそ、多様なECシステム移行を効率良く対応できたのではないかと思っています。
SUPER STUDIOの採用について
SUPER STUDIOでは、エンジニアを採用しています。
少しでも興味がありましたら、以下をご覧ください。
昨年12月に9期目を迎えたSUPER STUDIOのキックオフイベントで社内表彰されたエンジニア受賞インタビュー記事です。よりSUPER STUDIOのエンジニア組織を理解できる内容となっておりますので、ご一読ください。

Discussion