論文要約: RoMa: Robust Dense Feature Matching
この論文は画像のfeature matchingの中のdense matchingと呼ばれるアプローチのSotA手法とされています。DeDoDeという別の論文の精度プロットでも最も高いパフォーマンスと紹介されていたので読むことにしました。
Abstract
特徴点マッチングは同一3次元空間にある2枚の画像間の対応を推定する重要なComputer Vision タスクである。dense matchingはそのような対応をすべて推定する。ロバストなモデル、すなわち実世界の厳しい変化に対してもマッチ可能なモデルを獲得することが目的である。本研究では基盤モデルであるDINOv2の学習済み特徴量を活用するモデルを提案する。この特徴量はゼロから学習された局所特徴よりも顕著にロバストだが、不可避的に疎な特徴である。そこで、特殊なConvNetの密な特徴量と組み合わせ、正確に位置推定可能な特徴量ピラミッドを作成した。さらなるロバスト性のため、アンカー確率を推定する特製のtransformerによるマッチデコーダを提案する。それにより、マルチモーダルを表現することができる。最後に、改善された損失を提案する。それは分類による回帰を下流のロバストな会期と用いることで実現される

提案手法は、マッチングすることが極めて難しいような撮像条件が大きく異なる画像間でもマッチングすることができる
この論文の位置づけ
この論文は”Feature Matching”に取り組む研究です。Feature Matchingとは、与えられた複数枚の画像中で3次元的に対応している点(ピクセル)を検出するタスクです。3次元モデルの復元などに必要になる非常に重要な行程です。
さて、Feature Matchingはこれまでどのようなアプローチで行われてきたのでしょう。まず伝統的にはdetection-descriptionアプローチで行われてきました。このアプローチでは、まず複数の画像中で同じ点を同定しやすいkeypointと呼ばれる点をまず検出します(detection)。そして検出されたkeypointそれぞれをどんな点なのか特徴を算出します(description)。最後にそれぞれの画像のkeypointsを比較していき、互いに似ていれば対応していると判断します。
この伝統的なアプローチの問題は、実際には画像間で対応している点がどちらの画像においてもkeypointとして発見されない限り対応点として検出されないため、対応点を充分量得られないことでした。そこで近年はdetectorのないアプローチが提案されています。この手法ではkeypointとして検出された点ではなく、画像全体を均一にdescriptionしていき、対応点を発見します。これにより対応点の検出量が大幅に改善されました。
上記の手法にはまだ問題点がありました。画像全体をmatchingの対象とするものの、descriptionされる点は疎に分布しているため、依然として見落としは存在します。その解決に提案されているのがdense matchingアプローチであり、これは原理的にはすべての対応点を漏れなく検出することが可能です。この論文はdense matchingの既存手法に対してさらなる改善を提案するものです。
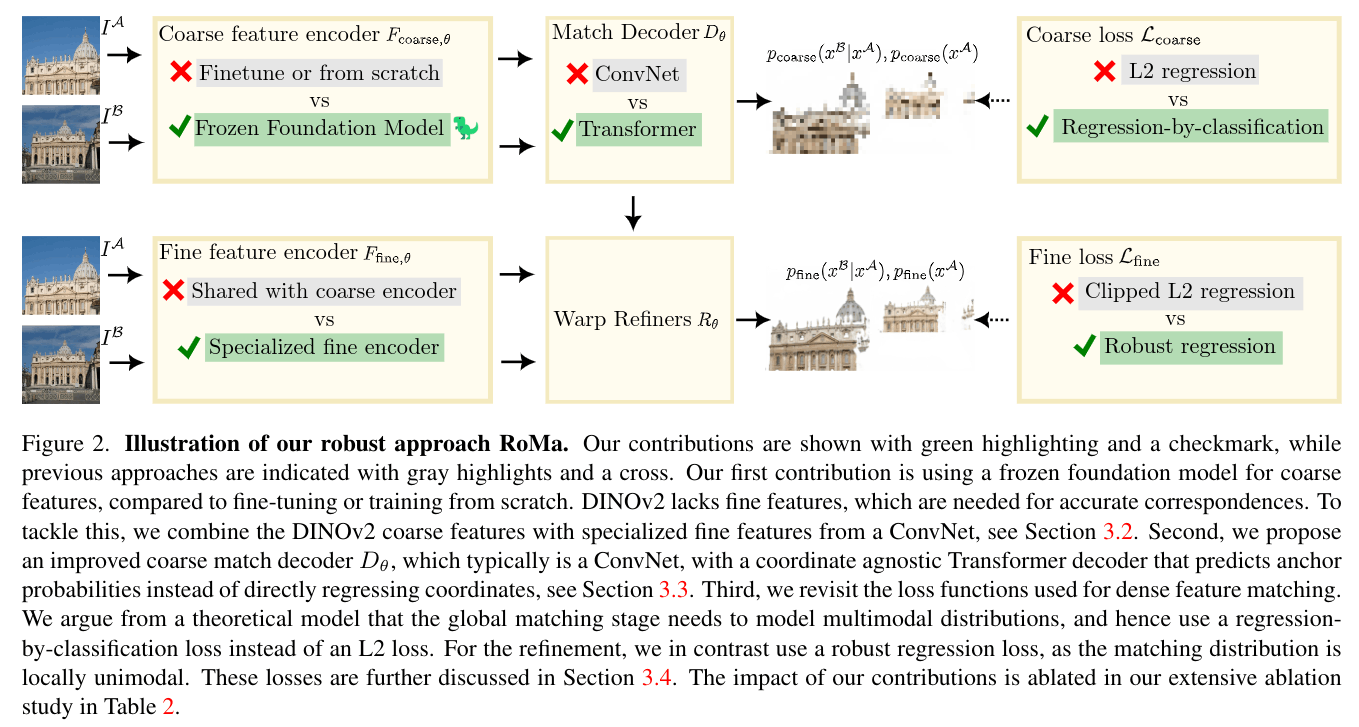
提案手法の構造の概要図。上段に疎な特徴マッチング工程が、下段に密なマッチング工程が示されている
Discussion