論文要約: Computer vision tasks for intelligent aerospace perception: ...



2025年はいよいよAgentic AI登場という感じで、存在価値の不安に日々押しつぶされております。人間の要約なんて意味あんのか、と思いつつ、執筆過程そのものを楽しむという線でやっていきます。
さて、2024年7月にarxivに公開されていた、宇宙x認識のサーベイ論文です。
既存のOn-Orbit Service(OOS)に関するDeep Learning(DL)ベースの手法についてよくまとまっています。早速見ていきましょう
論文: Link
Computer vision tasks for intelligent aerospace perception: An overview
本論文のスコープ
タイトルにある通り本論文のスコープはまず、宇宙かつ認識です。しかし実際にはIntroduction, Preliminariesにおいて、さらにスコープを以下のように絞り込んでいます。
- 軌道上の観測
一口に宇宙の認識といっても、軌道上での観測を用いるものと地上観測を用いるものがあります。地上観測は大気や地理的な影響を受けるという短所を理由に、本論文では軌道上の観測にフォーカスします。 - 3つの認識タスク: 姿勢推定・3D再構築・識別
OOSにおける意思決定や制御に重要なタスクとして姿勢推定・3D再構築・識別の3つをあげ、以降はこれらにフォーカスします。 - センサー: LiDAR・可視光カメラ
上記のセンサー以外には赤外カメラやLaser Range Finder(LRF)・ミリ波レーダがOOSに使用されるセンサーとしてあげられています。しかし赤外カメラは解像度に限界があること、LRFとミリ波レーダでは姿勢情報がえられないことを理由にスコープアウトしています。
本論文では従来的なルールベースとDLベースの手法の双方が議論されます。しかし、明確に主眼は後者にあります。DLベースの手法を議論するための土台として、従来手法が示される形です。
本論文は以下のように構成されます。
1章: イントロ
2章: 前提知識。従来の宇宙プログラムの内容、センサー、従来手法について
3章: DLベースの姿勢推定
4章: DLベースの3D再構築
5章: DLベースの識別
6章: 限界と将来の研究について
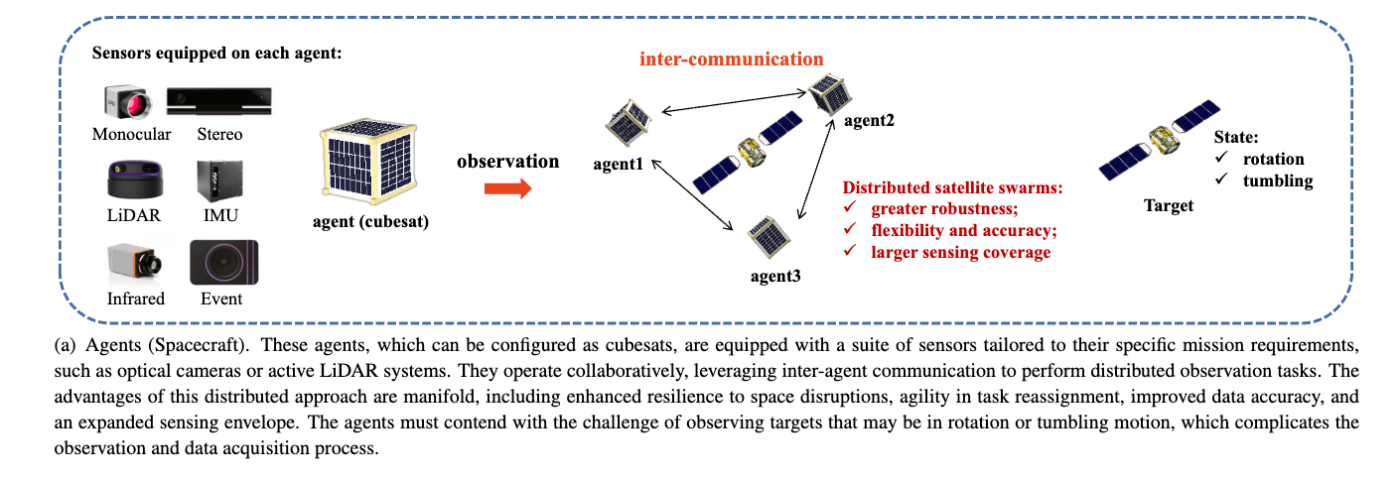 ターゲットへのランデブーイメージ
ターゲットへのランデブーイメージ
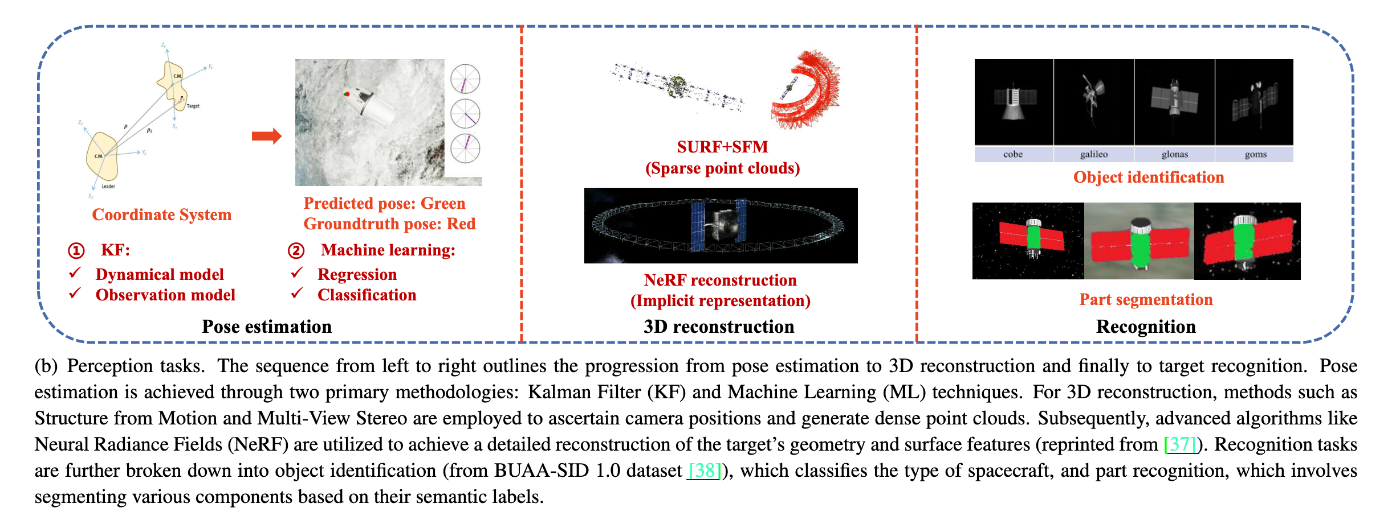 本論文では議論するタスクたち
本論文では議論するタスクたち
 On-Orbit Serviceはこんなことに使われる
On-Orbit Serviceはこんなことに使われる
前提知識・従来手法
従来の宇宙プログラムとして表の6つが挙げられています。LiDARを使ったものはありません
。これが先行事例がないことを意味するのか、あるいは可視光カメラに寄った本論文の恣意的な選定なのかは定かではないです。
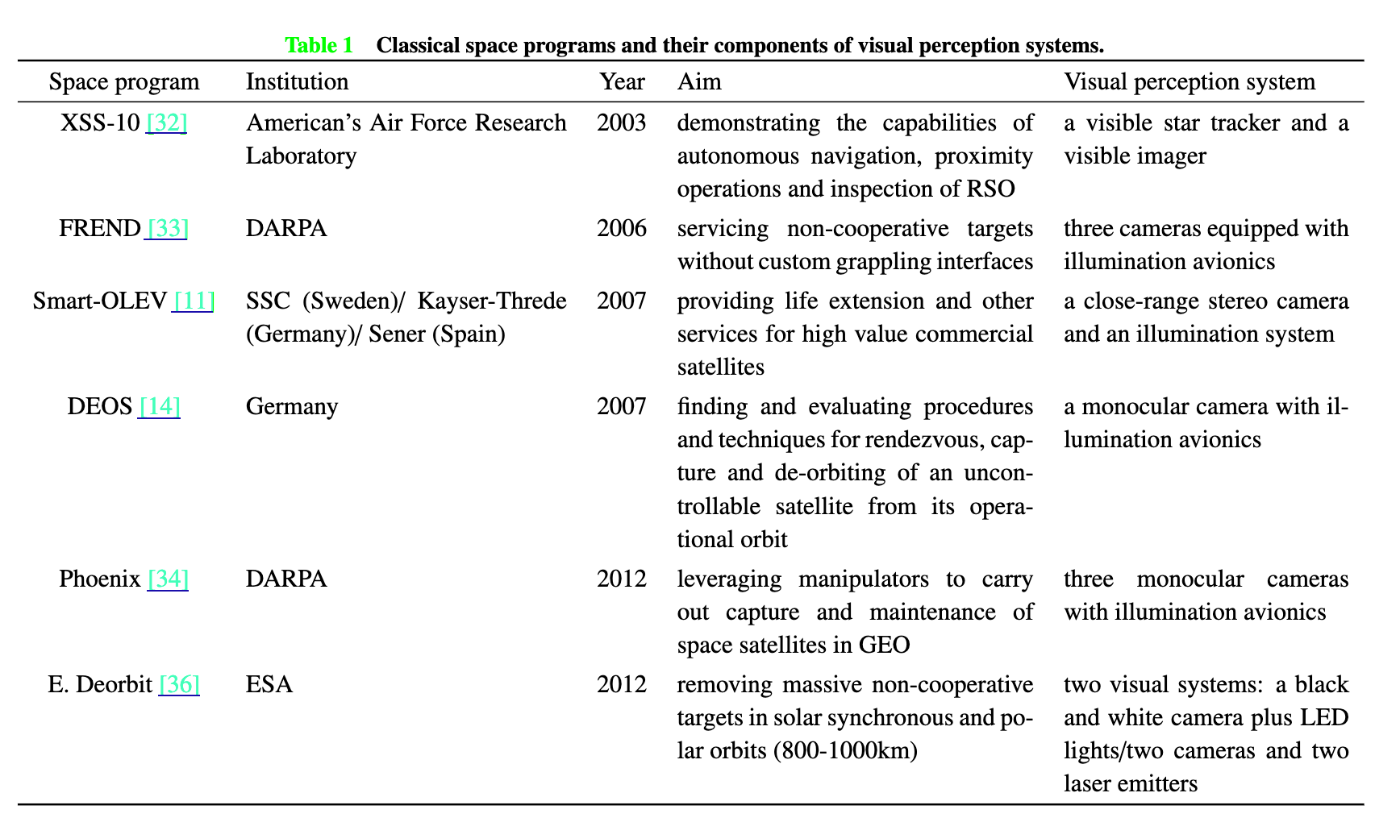 従来の宇宙プログラム
従来の宇宙プログラム
センサーの種類
前述の通り、本論文ではLiDARと可視光カメラにフォーカスします。本論文はそれを更に分類することで見通しを良くしています。
- LiDAR
- Scanning LiDAR: 1点ずつスキャンしていく
- Array LiDAR: 全点一気に取得する
- Flash LiDAR
- ToF LiDAR
- Visible Camera
- Stereo Vision
- Monocular Vision
それぞれのPro / Conざっくりまとめると以下のようになります。結論としては組み合わせないとダメだよね、のようです。
| Pro | Con | |
|---|---|---|
| LiDAR | 照明環境の影響を受けない | 解像度、コスト、電力、質量 |
| Stereo | 高精度 | 計算負荷、距離域 |
| Monocular | シンプルさ、電力、計算負荷 | 原理的に深度が得られない |
姿勢推定の従来手法
姿勢(Pose)推定というタスクはIntroductionで以下のように定義されています。対象に対して自身の位置(Position)と回転(Attitude)を正確に計測することを目的とするタスク。
従来の手法は3つに分類されModel-based, Feature-based, Bayesian-basedとされます。概要を下表にまとめます。
| 概要 | 課題 | |
|---|---|---|
| Model-based | 対象の3次元構造の事前情報と観測された特徴を突き合わせて姿勢推定する | 対象の正確な3次元構造は手に入りづらい |
| Feature-based | 角など、画像中の特徴をフレーム間でマッチングしていくことで姿勢推定する。様々な特徴が提案されている | 言及なし |
| Bayesian-based | いわゆるカルマンフィルタ。変化が一定な動的システムに強い。 | 初期姿勢に依存度が高い。計算負荷が大きくなる。 |
先行研究が表にまとめられています。左半分が姿勢推定です。事前情報の必要性、使用されるセンサーがまとめられています。
センサーの観点で見ていきます。LiDARはICPを使って対象の姿勢を推定することができます。しかし、電力・重量・費用の問題を抱えています。ステレオ視も深度を得ることができますが、距離域が限られています。単眼はこれらの問題を解決できる可能性があります。
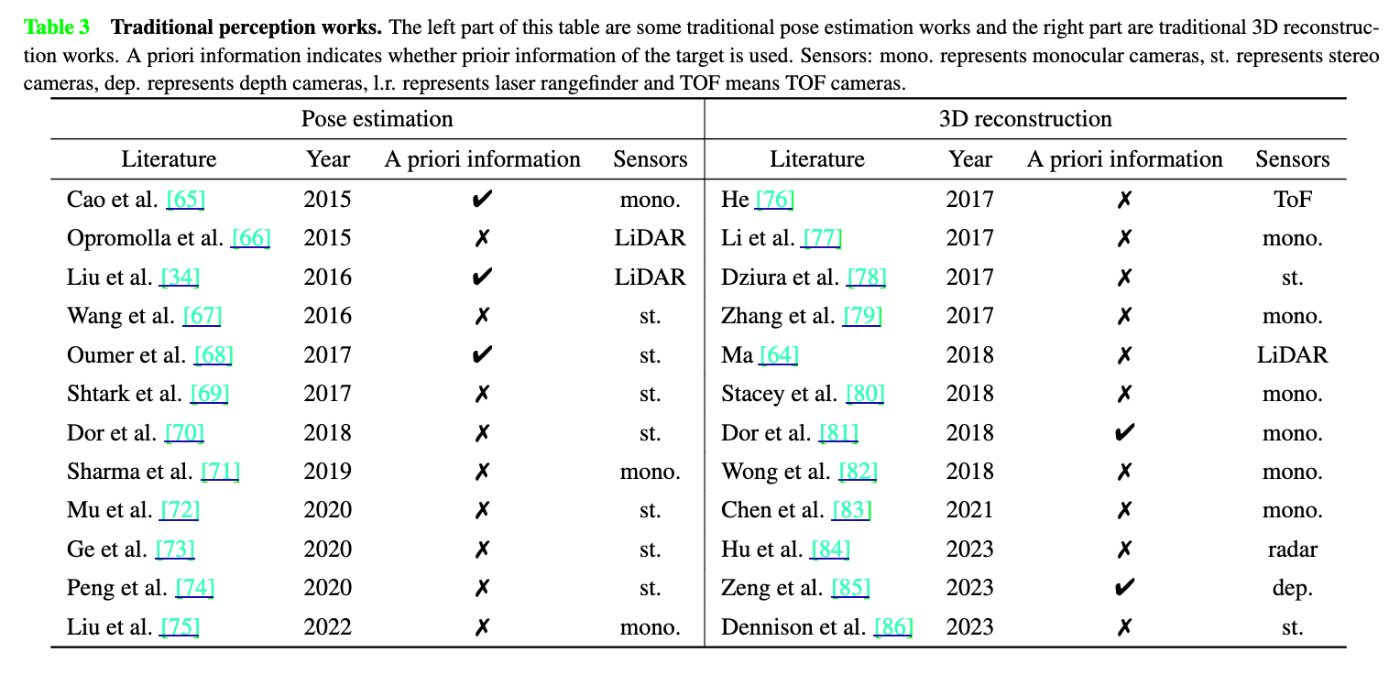 従来の認識研究 (mono.=単眼, st.=ステレオ視, dep.=深度カメラ, l.r.=レーザレンジファインダー)
従来の認識研究 (mono.=単眼, st.=ステレオ視, dep.=深度カメラ, l.r.=レーザレンジファインダー)
3D再構築の従来手法
用いるセンサーによって大別されます。LiDARなどのactiveセンサーを用いるものと、Visionなどのpassiveセンサーを用いるものです。前者は深度情報が直接手に入るので、それを用いて対象の点群を作っていきます。詳しくは述べられていません。後者はいわゆるSfM-MVSです。SfMはフレーム間で対応する特徴点をマッチングして、三角測量の要領で3次元的な位置を決定していきます。MVSはSfMで得られる疎な点群を密にします。センサーフュージョンを用いたものも盛んに提案されているようです。
従来手法の限界
従来手法の課題としては照明条件へのロバスト性が挙げられています。照明環境の変動が激しい宇宙という環境は従来手法の大きな障壁となります。
一方で、visionベースのDL手法が有力な代替案となっています。その優位性としては以下が挙げられています。カメラがコンパクトであること、従来手法が苦手とする姿勢推定の開始フェーズでロバスト性があることです。
Discussion