Prometheus, Loki, Grafana レシピ
ingress-nginx のデフォルトログにラベルを付けて整形しやすくする
ingress-nginx はこれ 既に ingress-nginx のログが loki に収集されているところからスタートする。
ログの設定がドキュメントで見つけられなかったのでコンテナから引っ張ってくる
$ kubectl exec \
-n ingress-nginx \
-it ingress-nginx-controller-6c8dcbb56c-ggc62 \
-- cat nginx.conf
log_format upstreaminfo '$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_length $request_time [$proxy_upstream_name] [$proxy_alternative_upstream_name] $upstream_addr $upstream_response_length $upstream_response_time $upstream_status $req_id';
LogQL の pattern でやると良い しかも正規表現より早いって
{namespace="ingress-nginx"}
| pattern `<remote_addr> - <remote_user> [<time_local>] "<request>" <status> <body_bytes_sent> "<http_referer>" "<http_user_agent>" <request_length> <request_time> [<proxy_upstream_name>] [<proxy_alternative_upstream_name>] <upstream_addr> <upstream_response_length> <upstream_response_time> <upstream_status> <req_id>`
これで整形は完成だが、エラーが入ると破綻するため少しフィルタリングする。
{namespace="ingress-nginx"}
| stream = `stdout`
| pattern `<remote_addr> - <remote_user> [<time_local>] "<request>" <status> <body_bytes_sent> "<http_referer>" "<http_user_agent>" <request_length> <request_time> [<proxy_upstream_name>] [<proxy_alternative_upstream_name>] <upstream_addr> <upstream_response_length> <upstream_response_time> <upstream_status> <req_id>`
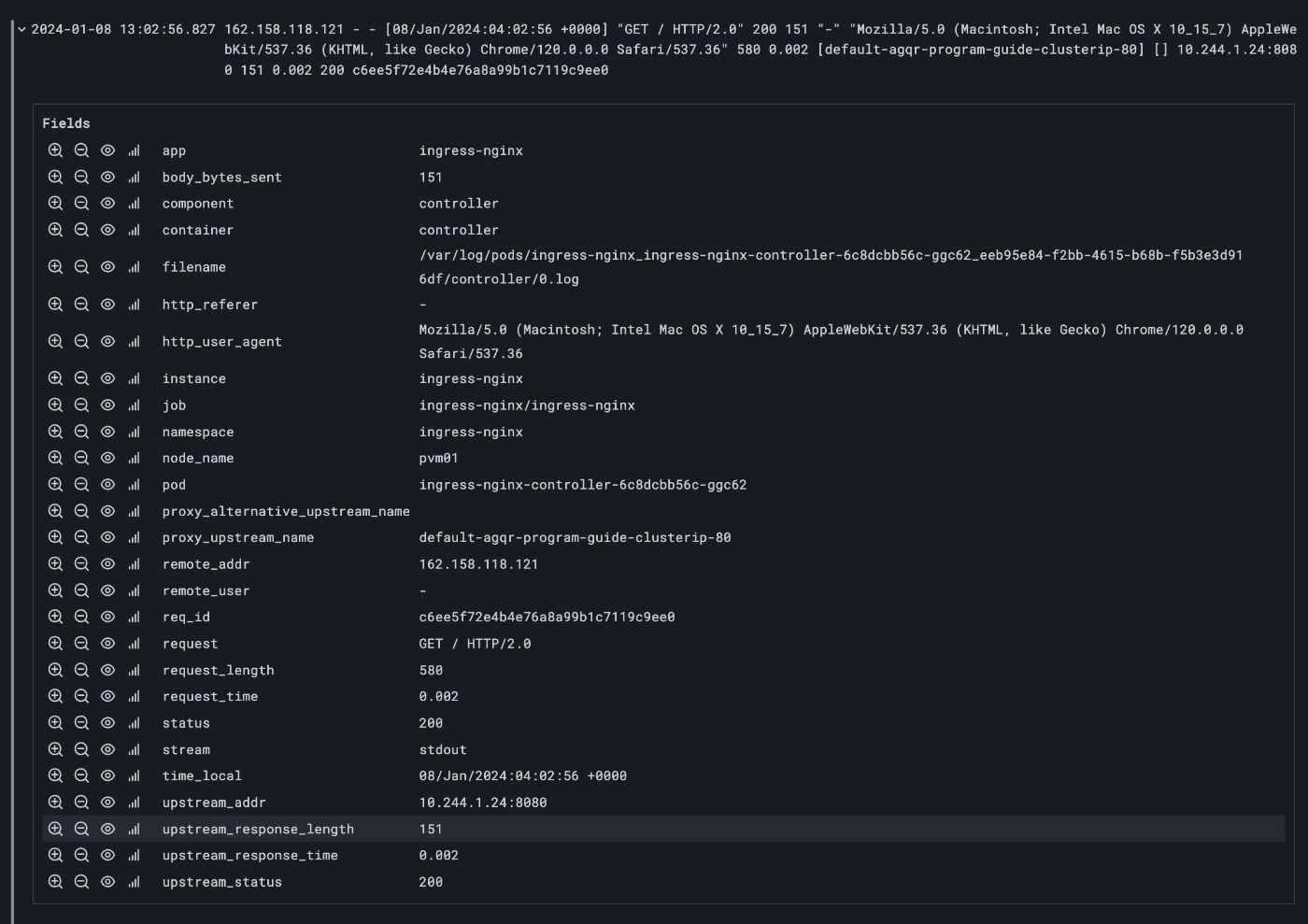
Log Format の additional variables として ingress_name などがあるのでそれを入れておくのがベター。今の私の環境は前段に Cloudflare をおいているため、それが付与するヘッダー(http_cf_connecting_ip)も使える。
config:
log-format-upstream: >-
$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer"
"$http_user_agent" $request_length $request_time [$proxy_upstream_name] [$proxy_alternative_upstream_name]
$upstream_addr $upstream_response_length $upstream_response_time $upstream_status $req_id
[$http_cf_connecting_ip] [$ingress_name]
この場合も LogQL 側はパターンに追加するだけで良い
{namespace="ingress-nginx"}
| stream = `stdout`
| pattern `<remote_addr> - <remote_user> [<time_local>] "<request>" <status> <body_bytes_sent> "<http_referer>" "<http_user_agent>" <request_length> <request_time> [<proxy_upstream_name>] [<proxy_alternative_upstream_name>] <upstream_addr> <upstream_response_length> <upstream_response_time> <upstream_status> <req_id> [<http_cf_connection_ip>] [<ingress_name>]`
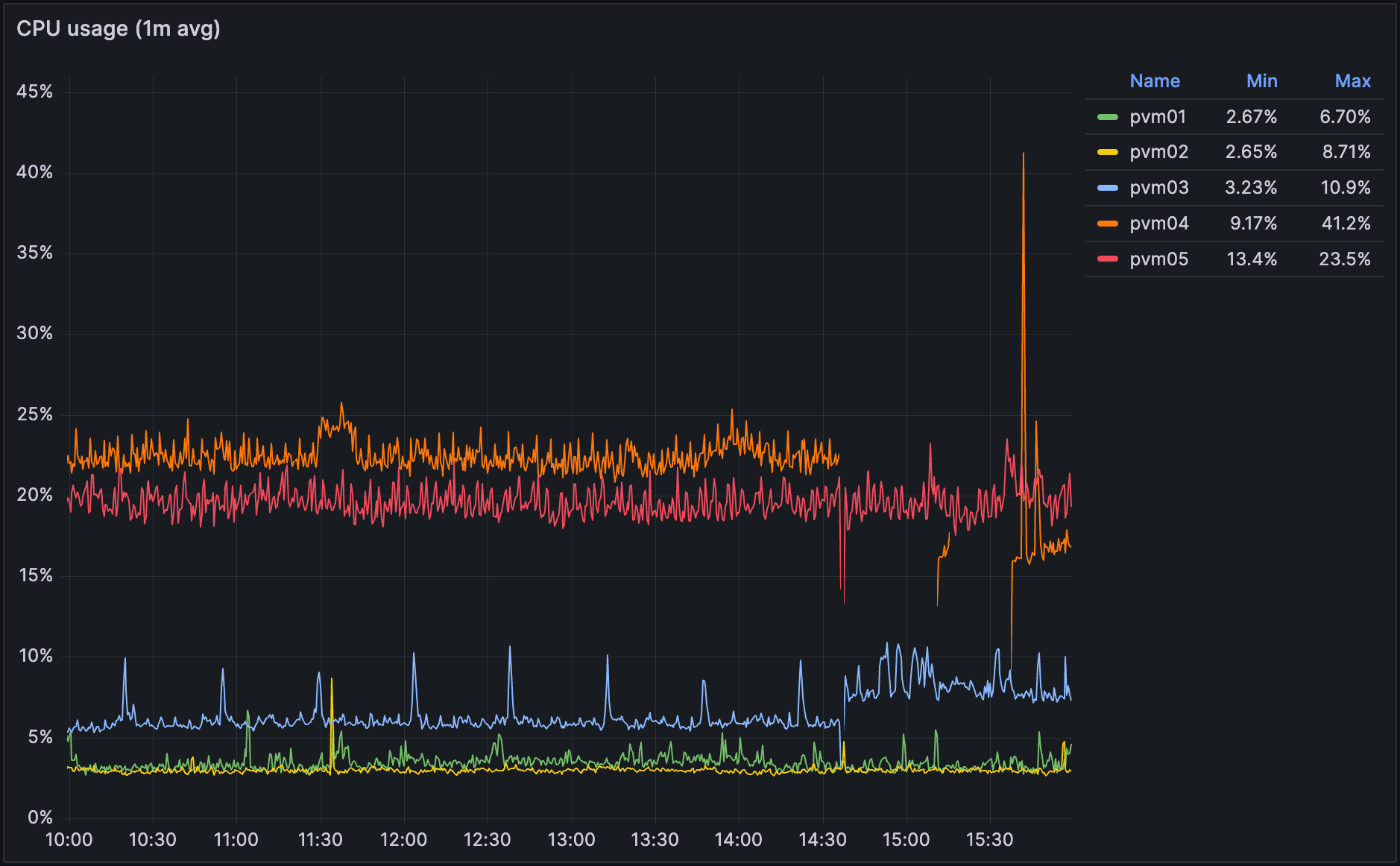
CPU 使用率を出す (kube-prometheus 使用)
いろんな dashboard を見たけどみんなそれぞれの書き方してて正解がわからん。
一応 top コマンドと見比べて大体同じになったのでこれを使っていく。
label_replace(
sum by(instance) (rate(node_cpu_seconds_total{mode!="idle"}[1m])),
"node", "${0}",
"instance", ".*"
)
/ on(node)
sum by (node) (machine_cpu_cores) * 100
node_cpu_secounds_total と machine_cpu_cores はそれぞれインスタンスを instance node という名前で保存している。PromQL で計算するためにはここを一致させる必要があるので、 label_replace で変形した。特に難しいことはせず instance: (.*) を node: ${0} に変換しているだけ。
インスタンスごとにグラフを作成したかったため、 sum by (instance) にしている。
Grafana で出力する時は Type: Range にしないと変な出力が出てくる(1敗)
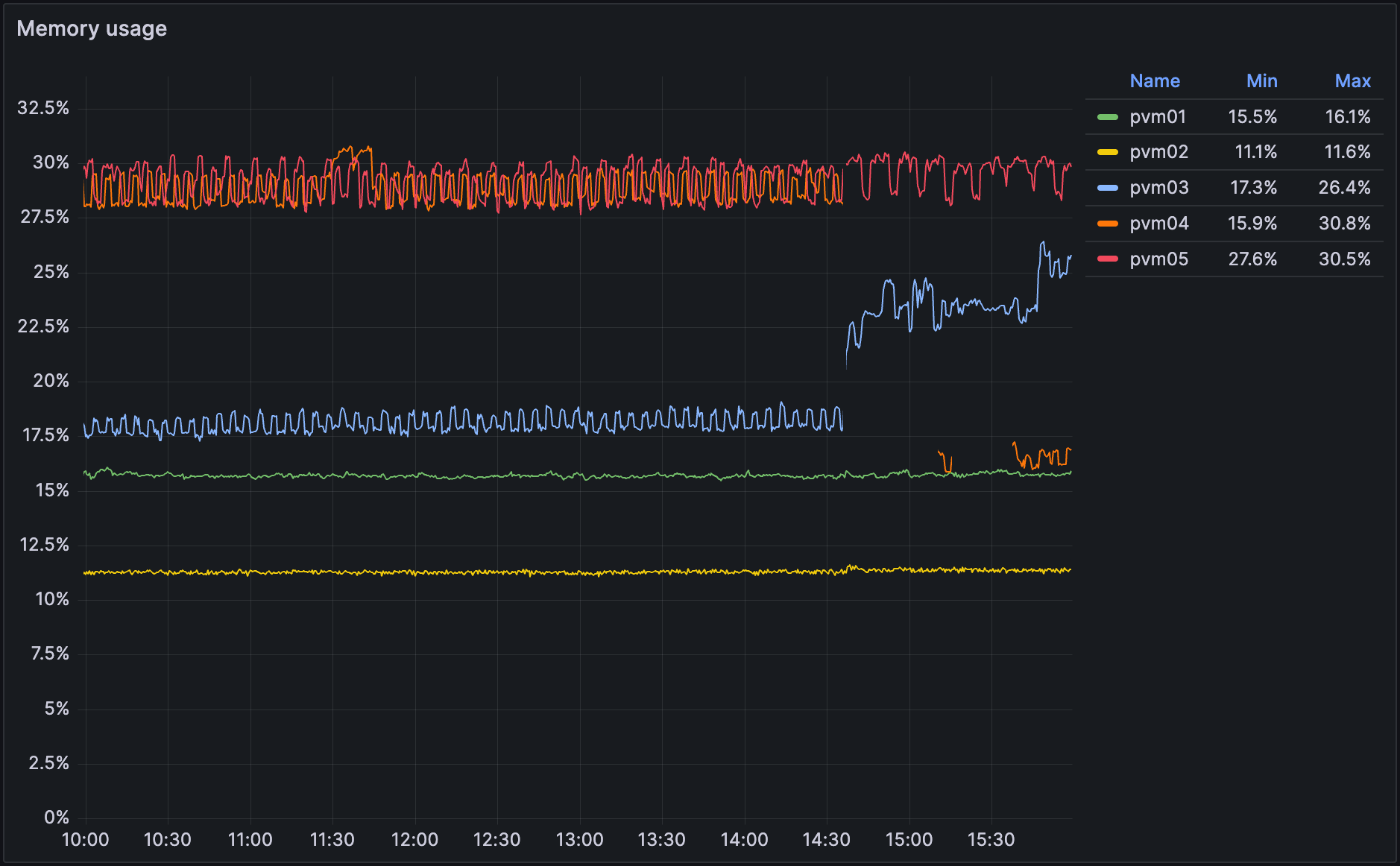
メモリ使用率を出す (kube-prometheus 使用)
(
sum by (instance) (node_memory_MemTotal_bytes)
-
sum by (instance) (node_memory_MemAvailable_bytes)
)
/
sum by (instance) (node_memory_MemTotal_bytes) * 100
これは割と適当。 htop と見比べて同じ感じだったので採用
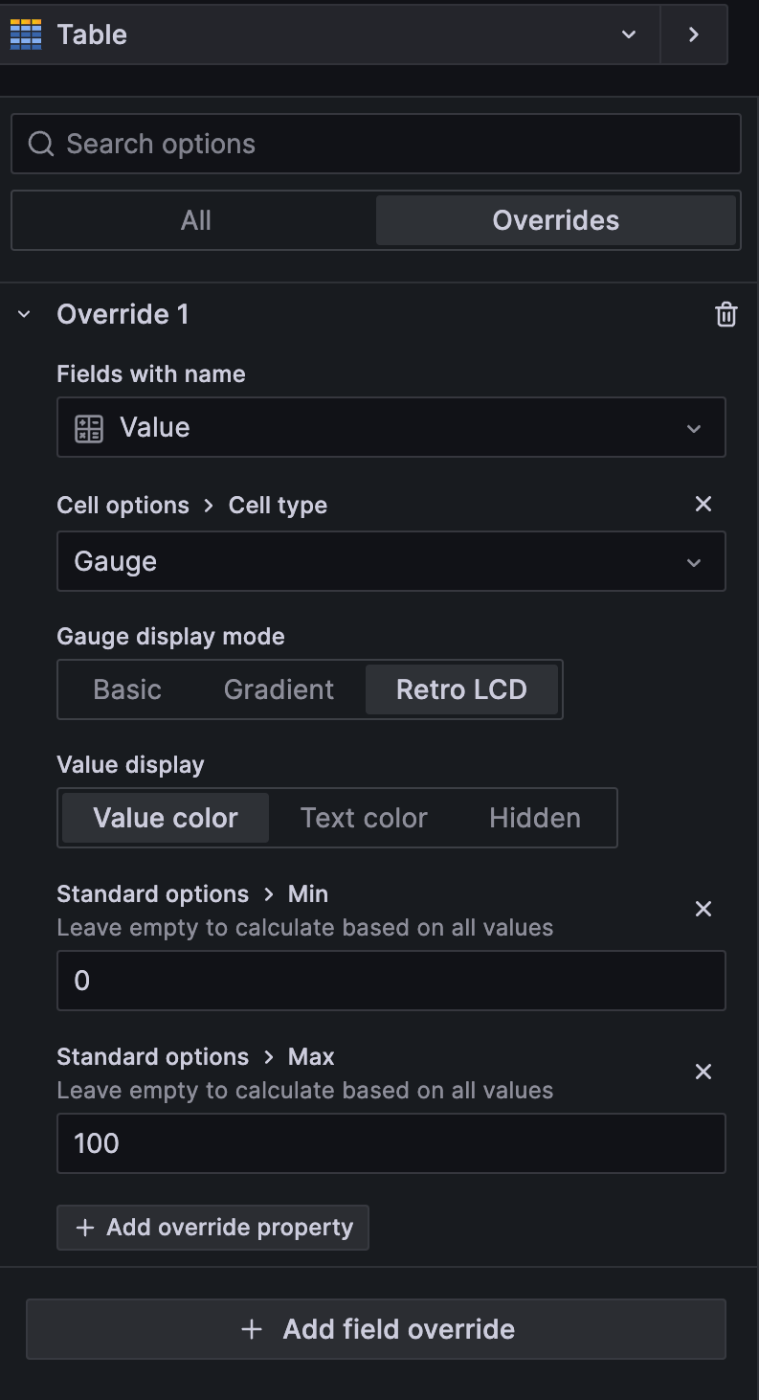
画像の Persistent Volumes >90% Capacity [now] っぽいものを作る

Query
(
kubelet_volume_stats_capacity_bytes
-
kubelet_volume_stats_available_bytes
)
/
kubelet_volume_stats_capacity_bytes
* 100
Transform
Filter by name
namespace, persistentvolumeclaim, Value を残す
Organize fields (並び替え)
persistentvolumeclaim, namespace, Value の順にする
Sort by
Value を Resverse にする
表示を Table にして各種設定しつつ、 Value だけゲージの形にするので Override する