はじめに
皆さん、こんにちは。自分は Sun* で 2024 年末からバックエンドエンジニアをしているホアン・スアン・バクです。Sun* Advent Calendar 2025 に合わせて、本記事では keyset pagination について共有します。
最近、システムのパフォーマンス最適化に取り組む中で、非常に有効な手法である「keyset pagination」を学びました。これは、現在広く使われている「offset pagination」の抱える問題を解決できるページネーション手法です。本記事では keyset pagination について解説します。
概要
テクノロジーの急速な発展に伴い、Web やアプリケーションといったオンラインプラットフォームへのアクセス量は年々増加しています。大量のデータを扱う中で、システムの監視・運用・性能維持はこれまで以上に難しくなっています。そのため、データを複数の ページ に分割して扱いやすくする Pagination は、ユーザー体験とシステムの安定性を両立させるための重要な技術となっています。
数ある分割手法の中でも、Offset Pagination は最も一般的で、多くのフレームワークやライブラリで採用されています。しかし、広く使用されている一方で、Offset Pagination には性能面でさまざまな制約が存在します。こうした課題を解決するために登場したのが Keyset Pagination で、Offset Pagination では十分な性能が得られない場面で効果的な手法として活用されつつあります。
Offset pagination(現在広く使われているページネーション手法)
Keyset Pagination を理解する前に、まず最も一般的な手法である Offset Pagination の制約について確認しておく必要があります。
Offset pagination の概念
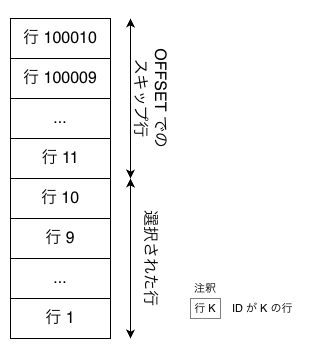
ページ番号を N、1ページあたりの件数を M とすると、ページ N のデータを取得するには、先頭から (N − 1) × M 件をスキップ(OFFSET (N − 1) × M)し、その後に M 件を取得(LIMIT M)します。
Offset pagination の例
ここでは、ユーザーのメッセージを保存する Messages テーブルを簡略化して用います。
CREATE TABLE messages (
id INT PRIMARY KEY AUTO_INCREMENT,
user_name VARCHAR(255),
message TEXT
);
offset pagination によるページングは以下のようになります。
SELECT *
FROM messages
ORDER BY id DESC
LIMIT 10 OFFSET 0; -- 1ページ目(page_size = 10)
SELECT *
FROM messages
ORDER BY id DESC
LIMIT 10 OFFSET 10; -- 2ページ目
SELECT *
FROM messages
ORDER BY id DESC
LIMIT 10 OFFSET 20; -- 3ページ目

以下の図は、各ページにおける LIMIT と OFFSET の動作を示しています。
ページ 1 では最初の 10 件を取得し、ページ 2 では 10 件をスキップして次の 10 件を取得します。ページ 3 では 20 件をスキップした後に 10 件を取得します。
ここまでで、Offset Pagination が内部的にどのように動作しているかを理解できました。
次に、Offset Pagination が本質的に抱えている 2 つの欠点 ― 性能 と データの正確性 に大きく影響する要因 ― を詳しく見ていきます。
パフォーマンスの問題
これは SQL の動作に起因します。OFFSET K を実行する場合、K はスキップする件数ですが、SQL は見つかった先頭 K 件を順番に走査して捨てる必要があります。そのため、処理量(I/O、CPU)はスキップ件数に比例して増大します。
- K が大きくなるほど、scan+skip の負荷が増え、クエリが遅くなる
- K が大きくなるほど、コストは線形に増加しやすい(計算量 O(n)、n はスキップ件数)
言い換えると、OFFSET が大きいほどクエリは遅くなり、データが増えるほど問題は深刻になります。
小規模なシステムでは目立たないかもしれません。しかし、件数が数十万、数百万と増えると、OFFSET によるページネーションは顕著な性能低下を招き、ユーザー体験や安定性に悪影響を与えます。
データ同期(整合性)の問題
Offset Pagination のもう一つの大きな欠点は、ユーザーが ページ A から ページ A + 1 へ移動する際に、データが 重複 したり 欠落 したりする可能性がある点です。
これは、2 回のクエリの間にデータベース内のデータが変更される可能性があることに起因します。
ユーザーが ページ A を閲覧している間に、新しいレコードが追加されたり、既存のレコードが削除された場合、OFFSET の計算に利用されるデータの並び順が、ページ A + 1 を取得する時点ではもはや一致しなくなります。
その結果、2 つのページ間でデータが同期しなくなってしまいます。
例:A = 1 の場合
ページ 1 では、システムが row 30 ~ row 21 を返すとします。
その後、ページ 2 を取得する前に、以下の 2 つのケースが発生する可能性があります。

追加(Insert)の場合
新しい row 31 が先頭に追加されます。
OFFSET 10 でページ2を取得すると、
- ページ2は row 21 → row 12 を返す
- row 21 がページ1とページ2の両方に現れる
→ データの重複
削除(Delete)の場合
ページ1の範囲にある行が削除されます。
OFFSET 10 でページ2を取得すると、
- ページ2は row 19 → row 10 を返す
- row 20 がどのページにも現れない
→ データの欠落
これらの問題は、商品一覧のようなケースではそれほど深刻ではないかもしれません。しかし、メッセージ、システムログ、またはタイムラインをページング処理する場合、データの重複や欠落は大きな影響を及ぼします。
- メッセージが失われる → ユーザーが文脈を誤解する
- メッセージが再表示される → ユーザー体験が非常に悪い
- システムの信頼性が低下する
これが、offset pagination が更新頻度の高いデータには適していないとされる理由です。
Keyset pagination(課題解決のアプローチ)
前のセクションでは、offset pagination の動作原理と、その2つの大きな制約について分析しました。
- クエリコストがスキップするレコード数に比例して増加する
- データベースに変更があると、データの重複や欠落が起きやすい
ここからは、Keyset Pagination(Cursor Paginationとも呼ばれます)について説明します。これは、パフォーマンスとデータ整合性の両方の問題を解決するために設計された手法です。
Keyset pagination の概念
OFFSET のように固定件数のレコードを単純にスキップするのとは異なり、Keyset Pagination では 前のページで取得した最後のレコードの値 を基準にして、次のページの開始位置を決定します。
この手法では、並び順が保証された一つまたは複数の ユニーク性を持つカラム(keyset) を “カーソル(cursor)” として利用します。
このカーソルを基点に、システムはその値 より大きい/より小さい レコードのみを問い合わせるため、offset pagination のようにデータをスキャンしたりスキップしたりする必要がありません。
Keyset pagination の例
前述のメッセージアプリの例で、総件数が 30、id は 1~30 とします。
-- 1ページ目
SELECT *
FROM messages
ORDER BY id DESC -- 新しい順に取得
LIMIT 10; -- 最後のレコードの id が 21 だったとする
-- 2ページ目
SELECT *
FROM messages
WHERE id < 21
ORDER BY id DESC
LIMIT 10; -- 最後のレコードの id が 11 だったとする
-- 3ページ目
SELECT *
FROM messages
WHERE id < 11
ORDER BY id DESC
LIMIT 10; -- 最後のレコードの id が 1
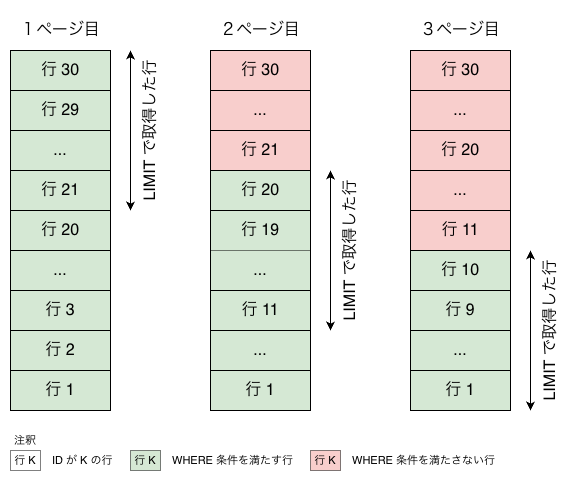
図の通り、
- ページ2:
WHERE id < 21で前ページ末尾より古い行だけに絞り、LIMIT 10で次の10件を取得 - ページ3: 同様に
WHERE id < 11で10件取得
「パフォーマンス」の解決
前の章では、Offset Pagination が性能面で問題を抱えている理由として、OFFSET 句の計算量が O(k) ~ O(n) となり、必要なデータを取得する前に k 件のレコードを順番にスキップする必要がある ことを説明しました。
では、Keyset Pagination における WHERE 句はどうでしょうか。
多くの場合、インデックスが存在しない WHERE 句も O(n) となり、条件に一致するレコードを探すために SQL エンジンがテーブル全体を走査する必要があります。
しかし、Keyset Pagination の強みは、WHERE 条件に使用するカラムがインデックス(通常は B-Tree)で管理されている 点にあります。
この場合、検索はテーブル全体ではなく B-Tree を辿るだけで済むため、計算量は O(log n) にまで低下します。
その結果、レコード数が増えてもクエリ性能が安定しやすく、大規模データでも高速に応答できるようになります。
例(上の3ページ目)
SELECT *
FROM messages
WHERE id < 11
ORDER BY id DESC
LIMIT 10;
ここでは、id 列にインデックスが張られているため、SQL エンジンは全表走査を行う必要がありません。代わりに B-Tree を辿り、11 の位置を見つけたうえで、11 より小さいノードを順に取得するだけで済みます。

「データ整合性」の解決
前のセクションで説明したように、Offset Pagination では、次のページに移動するタイミングで新しいレコードが追加されたり削除されたりすると、データの欠落 や 重複 が発生する可能性があります。
一方、Keyset Pagination では、最後に取得したレコードの値(last key) を次のページの起点として使用するため、この問題を回避できます。
つまり、この方式では 現在のテーブル状態に基づいて データを取得するため、途中でレコードが追加・削除されても影響を受けません。
例
ページ1 の末尾が id = 21 だった場合、ページ2 は「id < 21 の行」を順序通りに LIMIT で取得するだけです。
たとえば、現在 Page 1 にいて、最後のレコードの id が 21 だったとします。
Page 2 に進む場合は、単純に id < 21 のレコードを対象に、適切な順序で並べ替え、LIMIT を使って必要な件数だけ取得します。
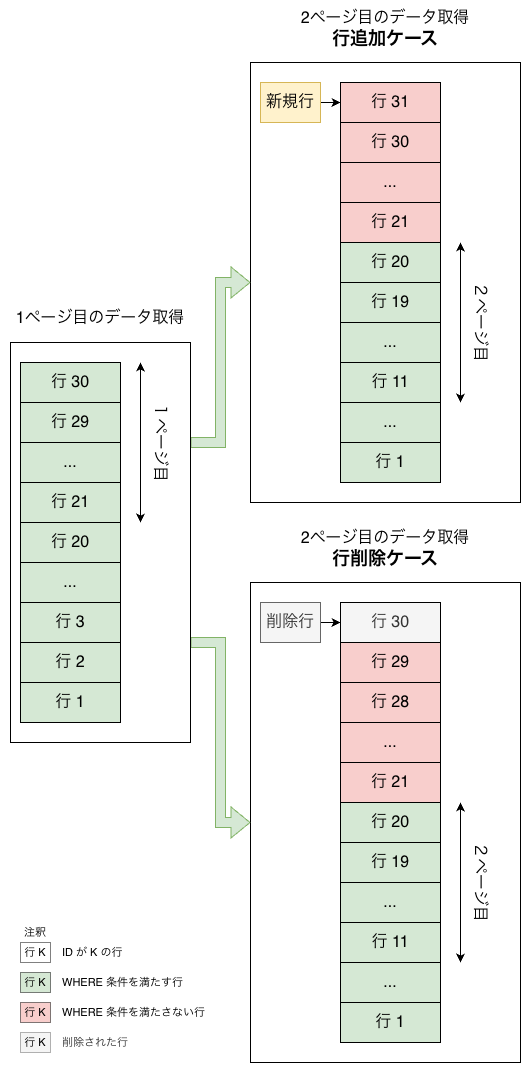
結果
図の例から分かるように、ページ遷移の直前に新しいレコードが追加されたり、既存のレコードが削除されたりしても、Page 2 に表示されるデータは 常に正確 で、重複も欠落もありません。
これは、クエリが常に「ユーザーが最後に確認したレコードのキー」を基準に実行されるためです。
応用
このような利点から、Keyset Pagination はデータが頻繁に更新されるシステム、たとえば Instagram、X、LINE などのソーシャルネットワークサービスで特に有効です。
また、ユーザーがページ番号を直接指定するのではなく、“Load More” 型のリスト表示でデータを順次読み込むようなアプリケーションとも非常に相性が良い手法です。
どちらのケースでも、Keyset Pagination はデータの一貫性を保ちながら、クエリコストを大幅に抑えることができます。
まとめ
データ量が増え続け、かつ更新頻度も高い現代のアプリケーションにおいて、Offset Pagination には多数の欠点があります。
パフォーマンスの低下、クエリの遅延、そして表示内容の不整合といった問題が発生しやすくなります。
そのような状況において、Keyset Pagination は高速で安定した応答性を提供し、データの整合性も確保できる効果的な解決策です。
特に、ソーシャルメディアのようにデータが常に更新されるサービスや、商品一覧などの “Load More” 型のアプリケーションで大きな力を発揮します。
もし今後プロジェクトでページネーションを実装する機会があれば、ぜひ Keyset Pagination を検討してみてください。
最後に、本記事で取り上げたポイントを踏まえて、Offset Pagination と Keyset Pagination の違いをひと目で理解できる比較表を用意しました。
それぞれの特徴や得意な場面がひと目で理解できると思います。
| 項目 | Offset Pagination | Keyset Pagination |
|---|---|---|
| 仕組み | OFFSET k で k 件スキップして取得 | 前ページの「最後のキー」を基準に続きのデータを取得 |
| パフォーマンス | 大量データで O(k)~O(n) と遅くなる | インデックス活用で O(log n)、高速で安定 |
| データ整合性 | 追加/削除で重複・欠落が発生しやすい | 最後のキー基準で常に一貫したデータを取得 |
| 実装の簡単さ | とても簡単。多くのフレームワークがデフォルト対応 | キー管理が必要でやや複雑 |
| 適した用途 | 小規模・更新頻度が低いデータ | SNS、タイムライン、更新頻度が高いデータ |
読んでいただきありがとうございました。

Discussion