【OpenTelemetry】オブザーバビリティバックエンド8種食べ比べ
sumirenです。
技術顧問やSREをしています。
背景
2024年現在、OpenTelemetryが盛り上がっており、ベンダへの依存度を下げてテレメトリを収集・送信することがトレンドになってきているように思います。多くの企業様で、OpenTelemetry対応のオブザーバビリティバックエンドを選定されているのではないでしょうか。
一方で、E2E自動テストツールなどもそうですが、デベロッパーツールは画面やUXの情報がパブリックな情報として出回ることが少ないように思います。オブザーバビリティバックエンドの場合、シグナル3種に関してOpenTelemetryベースでもフルに機能が活用できるのかという疑問もあります。
そうしたこともあり、オブザーバビリティバックエンドは実際にトライアルしてみないと選定しづらいです。監視など狭義のオブザーバビリティ外の機能や、OpenTelemetryの範囲外のベンダ固有のオブザーバビリティ機能も検証するとすると、実際の業務においてはあたりをつけて数種類を検証してみるくらいしかできないように思います。筆者も、本業ではそのように検証を行いました。
この記事について
本業で2つしかオブザーバビリティバックエンドを検証する時間がなかった経験を経て、筆者はOpenTelemetryのバックエンドとしてはどのツールが最強なのか、少なくとも筆者として一番推せるのか興味を持ちました。8個の製品を触ってみて、予想外の結論になった側面もあり、面白かったので記事として残すことにしました。
もちろん、現実には事業の状況やプロダクトの特性、ドメインの制約で重み付けが変わるかもしれません。それでも御託や知名度抜きで机上の最強を決めてみたくなるのは、人間の性でしょう。
この記事では、筆者が触ってみた8個のオブザーバビリティツールについて、筆者の独断と偏見で、推し順で紹介していきます。概ね以下のような観点で触っています。
- 機能性
- つなぎこみの手間
- コストと制約
- 所感
皆さんがオブザーバビリティツールを選定する際に候補を絞り込んだり、選定の観点を整理する用途などでこの記事が役に立てば嬉しいです。
制約
-
- この記事を執筆する上でのスタンス
- 記事の趣旨は筆者の推すポイントの紹介であり、筆者の思想によって重み付けが変わっています。公平性という観念はなく独断と偏見に基づきます
- 純粋に良いものを推すという目的以外の下心や手心や配慮がないことは保証します。ベンダ様やベンダ様ステークホルダとの関係性は考慮しません
- 概ね観点に沿って各ツールは触っていますが、気分で恣意的に触ってるところもあるのでムラはあります。機械的にやるより、筆者の創造性と洞察を活かすことを優先しました
- 2024年3月時点の調査によるものです
-
- この記事の技術的なスコープ
- 8個の製品は、単に筆者が聞いたことがある製品から恣意的に選んでいます
- 狭義のオブザーバビリティのみにフォーカスしており、監視モニタリング等は触っていません
- 実際には監視もセットで1ツールとして選定する場合が多いと思うので、適宜ご自身で情報を補ってください
- オブザーバビリティの中でも、OpenTelemetryベースでテレメトリを流した場合の体験や機能について記載しています。ベンダ固有の機能については評価しません
- オブザーバビリティで重要視されやすいトレースとログ中心で触っています。今回メトリックは流していません
- 実際にはインフラメトリックも必要ですし、アプリ上のカスタムメトリックは実質トレースやログと同じくらい重要です。メトリック機能については適宜ご自身で情報を補ってください
- 気づけなかった機能や学習コスト/セットアップコストが高く触りづらい機能は使えていない可能性があります
- ベンダの方で、言及されていない機能に関して不服があればご連絡ください。素直に推せる機能で、かつ、気づかなったことがUIのわかりづらさではなく筆者側の見落としの側面が強いと筆者が判断すれば、記事を修正する判断をする場合があります
- 一定量データがある状態での応答性は検証できていません
- 費用体系が難しいものが多く、圧倒的に安いもの以外は費用について言及・比較していません
1. Honeycomb
一番の推しは、尖ったツールで採用に勇気が必要ですが、Honeycombです。
一番の推しなので、文章量を割きます。
機能性
分析
Honeycombはトレースに対する分析のケイパビリティが圧倒的です。
Queryという機能で柔軟にスパンの分析と視覚化のクエリを組むことができます。例えば以下は、エンドポイントごとに時系列のリクエスト数を出しています。HAVINGやGROUP BYができ、可視化対象の属性もVISUALIZEで決められるので、しっかりと集合に対して分析ができます。結果のリストにカーソルを当てると、グラフ上でハイライトされます(下に添付)。

GROUP_BYは2つ以上指定できるので、ソート順を工夫すれば以下のようにエンドポイントごとのステータスコードの推移なども見やすいです(下に添付1)。VISUALIZEにはMAXやCOUNT_DISTINCTやパーセンタイルなど、とても豊富な選択肢があり、例えば同じことをするのにGROUP_BYではなくVISUALIZEでHEATMAPを選択するという手もあります(下に添付2)。


このクエリ、トレースではなくスパンを対象にしているのもポイントです。例えば以下のように、怪しいスパンの種類に絞って分析をかけるといったことが可能です(下に添付)。WHERE文に注目してみてください。

タイムスケールもドラッグで簡単に絞り込むことができ、実際のトレースを見に行ったり、分析の粒度も指定できます。5分など狭いタイムスケールにすると、1秒単位など非常に細かい粒度で分析をかけられるのも素晴らしいです(下に添付)。

さて、ここまででも圧倒的に分析機能が豊富なのですが、Honeycombを次元の違うプロダクトにしているのはクエリした後の操作です。ヒートマップ上で異常な部分をドラッグすると、BubbleUpという機能が使えて、異常な集合とそれ以外の集合の属性の違いを比較できます。以下添付は、処理時間の遅いスパン(黄色)とそうでないスパン(青)の属性値の比較です。

上記添付の下のほうのグラフで、特定のユーザーのリクエストに集中していることや、cartのエンドポイントに異常なトレースが集中していることがわかります。具体的にトレースを追してもいいですし、このエンドポイントだけでクエリしてみてもいいでしょう。クエリ結果が同じように一部のリクエストだけが異常な傾向を示しているなら、エンドポイント全体の問題というよりはデータや状態の問題である可能性が高いので、もう一度BubbleUpして属性値の違いをさらに鮮明に見ることもできます。
トレース検索・詳細
このように最先端の分析機能を持つHoneycombですが、トレースの検索や詳細もシンプルながら非常に洗練されています。トレースの検索は上記の分析画面がその機能を兼ねており(分析結果にTracesというタブがあります)、WHEREやORDER BY中心に使うことで欲しいトレースを探せます。
注目したいのはトレース詳細画面です。見やすいツリー型の表示で、エラーをハイライトしたりスパンをフィルタするなど、優先度の高いユーティリティ機能を備えています。特徴的なのは、同じ画面の中でスパンレベルでログを追えることです(下に添付)。
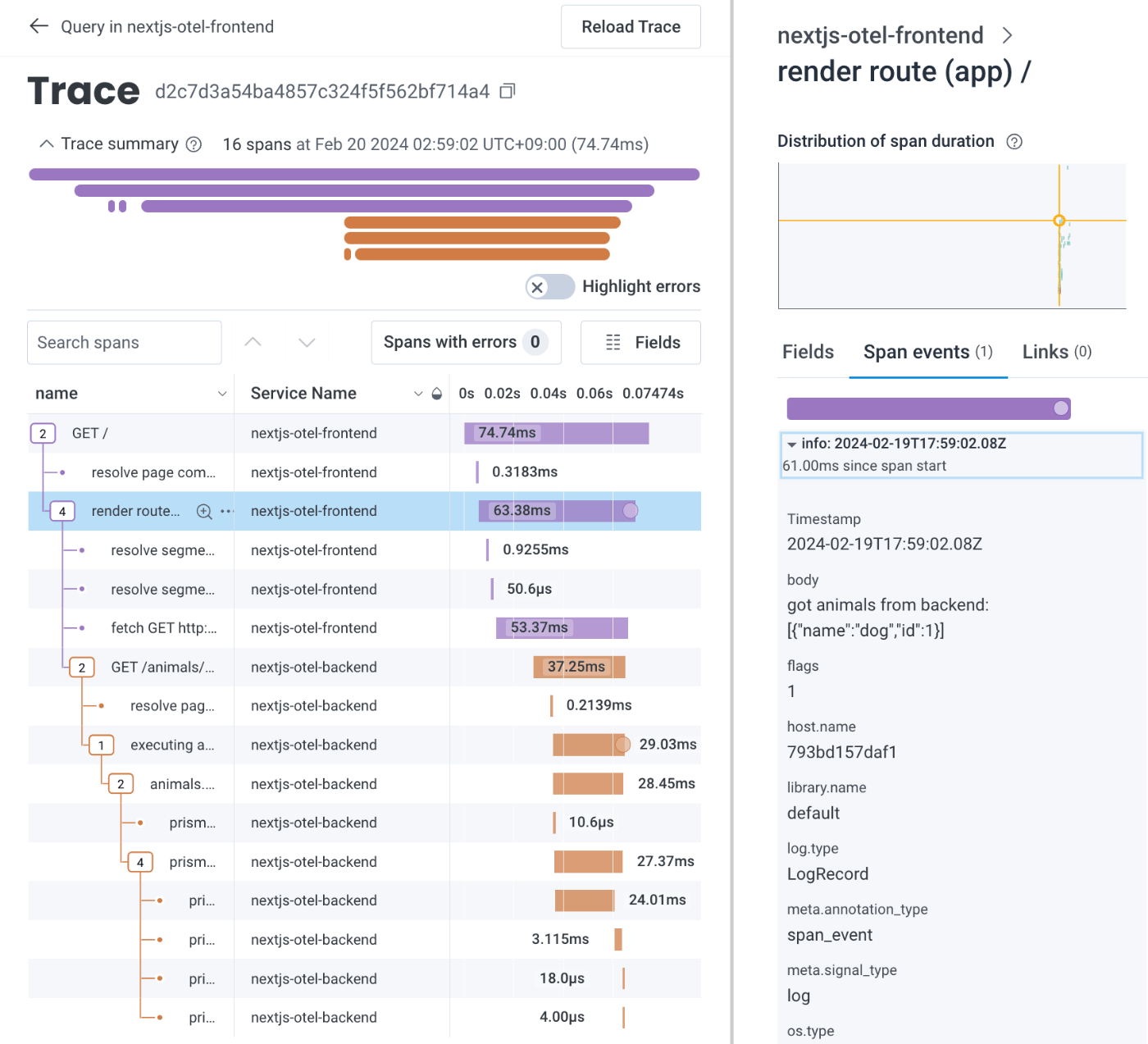
筆者はオブザーバビリティの大きな価値の1つはトラブルシュートの民主化だと考えています。その点、どのログがどのスパンで出ているのか分かることは、初見で当該トランザクションの全体像を掴むためにとても価値があると思います。上記画像のようにスパンレベルでログが紐づき、かつスパンの所要時間とログを見比べやすいUIを実現しているのは、今回の8種類の中ではHoneycombとGoogle Cloudの2種類のみです。
他にも、スパン上でログのタイミングが表示されている点なども嬉しいです。分析画面ではCorrelationsのタブからトレースの視覚化とメトリクスの視覚化の時系列での相関性も見れて、総じてシグナル間の連携が強力です。
全体的な体験としても、レスポンスや描画が早く快適です。国内じゃないはずなのにすごい。フロントエンドだけでなく、テレメトリを分析したり検索するバックエンドのAPIも速い印象があります。使いそうもない機能が大量にあるといったこともなく、分かりやすいと感じました。
つなぎこみ、コスト
全てのシグナルがOTLP対応のため学習コストが低く、コピペできるconfigがドキュメント上ですぐ見つかるため、OpenTelemetry Collectorをサクッと設定すれば5分でつなげます。このあたりはベンダ側からは軽視されがちかもしれませんが、短気な筆者としてはまだ採用するかもわからない1オブザーバビリティツールとのつなぎこみは1分1秒を惜しんで終わらせたい類の作業なので、助かります。
もちろん、実際にはAWS上でマネージドでCloudWatch Logsに流れるログを、HoneycombとAWSのインテグレーションで流すなど、アーキテクチャによってシグナルごとの収集方法を設計する必要があるので、OTLP対応がそこまで重要かと言われると微妙ですが、選定において第一印象や直感は大事です。
また、コストについても、ホスト数など高額かつ試算すら難しい課金体系が多い中、Honeycombは基本的にデータ量のみに依存する体系でわかりやすく、非常に低額です。なんとフリープランさえあり、月2000万件もログやトレースを流せる上、data retentionも60日と太っ腹です。
制約や知名度
一方、制約として挙げられるのがリージョンです。正式なドキュメントが見つけられなかったのですが、セットアップした感じ、デプロイ先はUSかEUの二択しかなく、テレメトリを日本国外に出せないようなドメインや企業コンプライアンスの場合には採用は難しいかもしれません。
知名度も、グローバルのシェア等は調べられていませんが、少なくとも国内ではあまり高くないように思います。そのためハマったときに気軽に日本語の技術記事などに当たれない、サポートとも英語でやりとりする必要があるといった制約はあります。
またツールとしても小さいので、オブザーバビリティでは最先端を行っているとしても、監視機能やインテグレーション、OpenTelemetry外の独自機能ではDatadogやSplunk等のビッグプレイヤーに対して見劣りする可能性は高いです(触ってません)。
最後に、有料プランでもデータのリテンションは60日となっており、特にログ等を長期保存したい場合は設計の考慮が必要です。
所感
オブザーバビリティとはダッシュボード主義的にならずエンジニアが気の向くままに自由にテレメトリを探求できる仕組みだ、というのはオブザーバビリティ界隈で合意された理想で、筆者もそうした思想を持っていますが、Honeycombの分析機能はその理想に最も近い高みに位置するように思います。
また、トレース詳細も一番ほしい機能がしっかり揃っており、トラブルシュートの民主化を重視する筆者の思想ととてもマッチしていました。分析機能を抜きにしても余裕の最推しです。
デベロッパーツールは不透明なものやベンダサイドとのコミュニケーションにストレスのあるものが多い印象ですが、HoneycombはオープンなSlackコミュニティもありますし、アカウント登録しなくても体験を見れるサンドボックスまであります。コスト体系もそうでしたが透明性が感じられ、とても信頼できます。
筆者の思想ともマッチして、Honeycombが提供する機能やドキュメントを使いこなしていくだけで、一流以上のオブザーバビリティスキルが身につきそうな印象です。
一定以上大きくなった事業でもしっかりと検証すれば十分採用できるかと思いますし、スモビジやスタートアップであればサクッと入れてしまってもいいのではないでしょうか。特にバーンレートが重要となるシード〜アーリーのスタートアップであれば、無料〜月2万円で使えることは極めて大きいメリットです。
2. Dynatrace
機能性
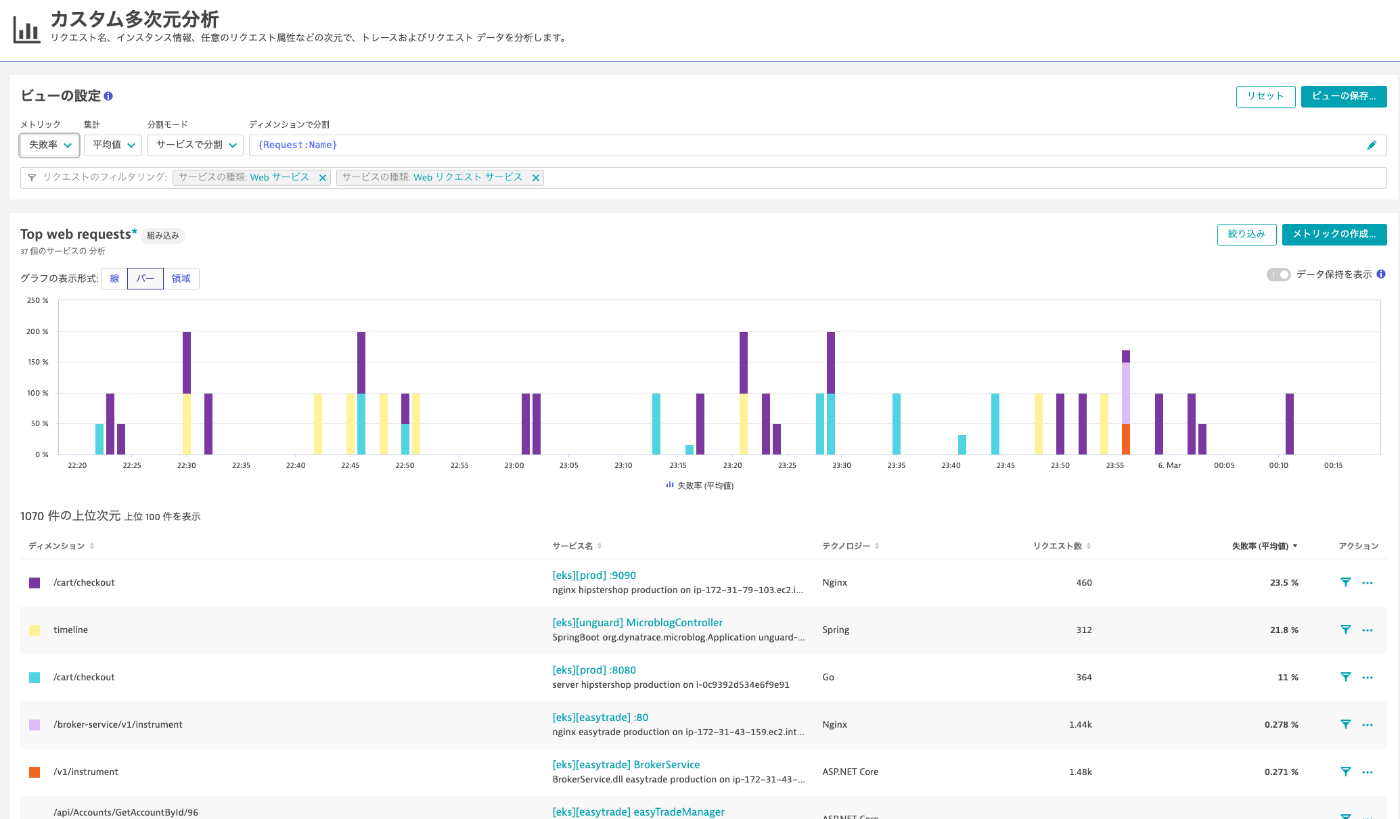
まず、トレースの集合に対するカスタム多次元分析という機能があります(下に添付)。ディメンションで分割がGROUP BY、メトリックが関数と属性にあたります。ただこれはSandbox上で、自分でOpenTelemetryベースでトレース流しただけだと上手く出なかったので、もしかしたら制約があるかもしれません。筆者は、ビルドインでなんでも見せてくれるというよりは、自分で興味をもって色々なことを聞けるケイパを提供するオブザーバビリティツールのほうが好みなので、この分析機能の方向性は推せます。

Honeycombのようにトレース集合間のスパンの属性差異を分析するような機能はありませんが、得意な処理として、失敗率を出すなどが挙げられます。Honeycombのクエリはあくまでスパンの属性を活用したものであり、失敗率やスループットのようなセマンティックな計算は苦手です。Dynatraceが失敗率を出したり(下に添付)、上記の添付のリスト内のようにスループットを出すことができるのは、入ってきたスパンに対して内部的に様々なメトリックを生成するアーキテクチャを取っているからだと予想します。
トレースの検索機能も充実しています。応答時間等の属性で検索をかけたられたり、検索結果もソート可能なリストで使いやすいです。列も設定できます。
トレースの詳細画面も、シンプルですが例外ハイライトやスパンフィルタのユーティリティがあり、十分機能的です(下に添付1)。そして、筆者の重要な推しポイントとして、Honeycomb同様にトレースとログや例外はスパンレベルで紐づき、同じ画面で見れます。できればスパンのタイムスパン見ながらログ見たいので、UIが少し惜しい(下に添付2)


全体的な体験としても、機能が多くOpenTelemetryのバックエンドとして見るとごちゃごちゃしている印象ですが、全体検索が優秀なのでTraceやLogの画面にはすぐにたどり着けます。レスポンスも日本リージョンになっていそうなトライアル環境では遅くはないです。
つなぎこみ
Honeycomb同様、OTLP対応かつコピペできるconfigがあるので速攻でつなげます。この配慮と学習コストの低さが嬉しい。
コスト、制約や知名度
コストはオブザーバビリティバックエンドにありがちな高いか安いかも判断できない複雑なやつですが、この界隈の商慣習なので仕方ないかなと割り切れます。日本リージョンもあります。
所感
DynatraceもHoneycomb同様、オブザーバビリティに関する思想が筆者とマッチしていて、触っていて楽しいです。
カスタム多次元分析はユースケースによってはHoneycombでは行いづらいクエリが可能です。記事で触れませんでしたが、サービスマップによる分析機能やサービス単体のダッシュボード的な機能もあり、カバレッジが広いです。
OpenTelemetry関連の機能に絞ると、Honeycombのほうが勝ると評価し2位にしました。トレースの集合への分析はどちらも長所があり、トレース詳細はHoneycombのほうが強力です。記事で触れていませんが、サービスマップのような機能はDynatraceのほうがリッチですが、筆者はあまり重視していません。そして、大きな差がつくポイントとして、Honeycombには切り札であるBubbleUpがあります。
しかし、Dynatraceには弱みになるような機能仕様や制約はないので、監視周りの要件ミスマッチがなければ間違いのなさそうな製品という印象です。
Honeycomb同様Sandboxが提供されており、包み隠さずUXを出している点で、プロダクトへの自信を感じられ、信頼できます。
3. Splunk Observability Cloud
機能性
分析機能について、まず、トレースやメトリクスの集合に対してAPMのトップでビルトインの分析結果を見れます。ダッシュボードを作らなくても、初めからエンドポイントごとにレイテンシやリクエスト/エラーのグラフが見れて、かつソートもできるので便利に使えそうです(下に添付)。

また、HoneycombやDynatraceにも似た機能があるのですが、Service Mapという機能でサービス間の依存関係やレイテンシを把握することができます。特定のマイクロサービス間のリクエストだけレイテンシが高いといったことに気づくことができれば、トラブルシュートの助けになりそうです(下に添付)。

Splunkの機能で筆者が最も推すのは、Tag Spotlightという分析機能です。これはHoneycombのBubbleUpに近い機能です。Requests/Errorとレイテンシという多くの場合に役に立つ2つの属性で分析でき、例えばレイテンシならパーセンタイル50、90、99という集合に分けて自動で比較してくれます(下に添付)。たとえば以下添付からはP90は/404へのGETが大半を占めていることがわかります。最初にタグへのインデックス設定が必要なようですが、使いこなせればとても強力そうです。

トレース検索の機能はDynatrace同様、フィルタやソートに対応しており使いやすいです。トレース詳細は機能が豊富で、通常のトレースツリーに加え、Root Causeに飛べる機能や、スパンの中で支配的なdurationを持つものが視覚的に表示できる機能などがあり、ややリッチな印象です(下に添付)。ただし、例外はスパン単位で紐づきますが、ログはトレース単位でしか紐づかないようです。


全体的な体験としては、ログは別製品となっている点で製品体系がやや複雑です。今回ログはトライアルできず触れませんでした。また、UIが伝統的なMPAであるためか、トレース画面への遷移などのたびにブラウザ全体が再読込されるため、日本リージョンでもややレスポンスが悪く感じます。
つなぎこみ
トレースやメトリクスはOTLPに対応しており、ドキュメントもあるためサクッとつなげます。ログは別製品となっており、専用のexporterでつなぐ必要があるようですが、ドキュメントさえあればすぐに見つかれば手間取ることはなさそうです。
コスト、制約や知名度
コストは機能が多いこともあり複雑な体系ですが、界隈では一般的なものです。日本リージョンもあるので、目立った制約やデメリットはなさそうです。
所感
1つ1つの機能がリッチな上、Tag Spotlightが推せるツールです。
全体を通じて、ユーザーに探求させるというよりSplunkとしての分析結果を提案する哲学があるようにも思いました。ビルトインの分析結果の表示もそうですし、Tag Spotlightについても、Honeycombと異なり、対象とする属性やどういう集合間で比較するかはSplunk側で決めているからです。
Dynatraceと僅差で、どちらを推し2位にするか迷いましたが、3位にしました。自分で様々な探求をしたい筆者の思想との間で哲学の違いを直感的に感じること、振る舞いのトラブルシュートのためにスパンとログが紐づいてほしいこと、全体的なUX、そしてTag Spotlightは強力だが真価を発揮するにはインデックス設定が必要で、ミスマッチによる評価全てをひっくり返せるほどのゲームチェンジャー感はなかったことが理由です。
チームの好みに合うなら非常に良い選択だと思います。筆者の推し4位以下とは大きな開きがあると考えます。
4. New Relic
機能性
まず分析については、APMのトップでビルトインの分析結果を見れる機能(下に添付1)と、Query You Dataという機能で柔軟に分析・可視化ができる機能の2つがあります(下に添付2)。ただし、後者については、筆者が触ったときはGROUPING等が上手く動かず。OpenTelemetryベースだと制約がある可能性があります。探求のケイパビリティを提供しつつビルトインで出す、Splunkに近いスタイルでリッチです。


トレースの検索も機能的で、属性によるフィルタや検索結果のソートが可能です。機能が豊富なトレース詳細画面は特徴的で、基本的なトレースのツリー表示やエラーハイライトに加え、マイクロサービス間のマップを表示したり、スパンごとに他のトレース含めて平均的な実行時間との比較が見れたりします(下に添付)。


体験としては、機能が多すぎて慣れないとややノイジーに感じる側面もありますが、ナビゲーションはシンプルで、見た目や動作もかっこよく先進的です。個人的に惜しいポイントとして、ログはスパンレベルでは紐づかず、どのログがどのマイクロサービスで出ているかは分かりづらいのが現状です。
つなぎこみ
OTLP対応かつコピペできるconfigがあるので速攻でつなげます。助かる。
コスト体系の懸念
コスト体系の透明性が高いと自慢のようですが、筆者はネガティブです。ユーザー数に依存するコスト体系となっており、これではユーザーを払い出すことに抵抗を覚える組織も出てくるでしょう。選ばれしSREだけがオブザーバビリティツールを使う、間違ったオブザーバビリティカルチャーにつながる懸念があります。
所感
HoneycombやDynatraceが持つトレースの集合に分析をかける機能もサポートしながら、トレースの詳細でもビルトインで分析をかけて付加価値を提供しており、総合点の高いツールのように思います。
トレースツリーが見づらい、スパンレベルでログが見れない、オブザーバビリティカルチャーと相性の悪い料金体系、トラブルシュートの民主化を重要視する筆者の思想とはミスマッチする部分も多く、HoneycombのBubbleUpやSplunkのTag Spotlightのような切り札的分析機能も備えていない点で、3位とは少し差をつけて推し順4位という評価です。
好みに合えば優秀なツールだと思います。ぜひエンジニア全員分のユーザーを払い出す前提でコスト見積・社内稟議を進めてください。
5. Google Cloud Stack
Google CloudにもCloud Traceなどのオブザーバビリティ機能が備わっています。
機能性
トレースの集合に対する分析機能は残念ながらありません。一方、トレースの検索や詳細画面はシンプルながら優先度の高い機能を備えています。検索ではトレースの属性に対してフィルタができ、視覚化やグラフ上からトレースを選択できます。詳細画面は見やすいツリー形式でトレースが表示され、ログが出たタイミングがスパン上に出たりします(下に添付)。

全体的な機能性は見劣りしますが、ログがしっかりスパンレベルでトレースと紐づき、視覚的な応答時間と一緒に見られるのは筆者の好みです。トラブルシュートの民主化という意味では十分に価値が出せると思います。
また、Google Cloudでは、トレースはCloud Trace、ログはCloud Logging、メトリックはCloud Monitoringに対応しています。この対応関係のわかりやすさは体験として良いです。
Google Cloudインフラとのシナジー、コストの強み
Google Cloudのオブザーバビリティバックエンドの推せるポイントは、上記のように機能性もそこそこ優秀な上、Google Cloud上のシステムと相性が良いということです。
普通にオブザーバビリティバックエンドを採用すると、クラウドプラットフォームとは別にその製品とセットアップやアカウント管理が必要になりますが、Google Cloudのオブザーバビリティバックエンドを使えば、全てをGoogle Cloudだけで完結でき、ハードルが低いです。
加えて、費用も非常に安く、わかりやすい料金体系です。
つなぎこみの手間、アップデートやサポート体制への懸念
一方で、これはインフラとのシナジーのトレードオフになりますが、全体的に密結合につながっていてベストプラクティスが分かりづらい現状はあると思います。
他にも、クラウドプラットフォームであるGoogle Cloudのセキュリティの重要性が高い分、OpenTelemetry Collectorの設定もわかりづらく、独自のexporterを使う必要がでてくるといった調査と実装の手間があります。
また、専任でオブザーバビリティバックエンドを開発している企業に比べると、Google Cloudの1サービスでしかないこれらのツールの開発スピードとサポート体制にはあまり期待できない気もします。
所感
機能は最低限ですが筆者の好みで、導入コストもランニングコストも低く、Google Cloud上にデプロイしているシステムに計装する一歩目としては推せます。
ログとメトリクスが標準の仕組みでCloud LoggingやCloud Monitoringに流れていれば、とりあえず計装してtraceだけ流せばいいですし、Collectorさえなんとかすれば、コストの社内稟議やGoogle Cloud内からデータを出すことに対するリスクアセスメントも不要で、総じてハードルが低いです。
6. Datadog
ここからは筆者としてあまり推さない方向のツールになります。
機能性
ユーザーが自ら手を動かしてトレースの集合に対して分析を行えるような機能は見つかりませんでした。
ビルトインの条件でトレースの集合を分析する機能はあります(下に添付)。サービスマップでサービス単位のレイテンシやエラー率等が見れる他、トレース検索の機能がフィルタやソートに対応しておりエラーレートなどの可視化が行われます。

トレース詳細の方向性はSplunkやNew Relicに近く、マイクロサービス毎の処理時間やエラーハイライトといったユーティリティに加え、このトレースが属する応答時間のパーセンタイルを表示するなど、Datadogとしての分析やサマライズを付加価値として提供しています。

ただ、このトレース詳細は筆者的にはイマイチです。たしかに付加的な情報はパフォーマンス改善には役に立ちますが、振る舞いに関するトラブルシュートでは処理が追いやすいことが重要です。このトレース詳細はツリー表示ではないため論理的に追いづらいです。加えて、ログが紐づくのもトレースレベルです。総じて振る舞いのトラブルシュートでの利用は厳しい印象です。
体験としては、レスポンスは早いですし、全体検索からトレースやログの画面にはすぐにたどり着けます。一方で、Datadogの基盤として、そもそもスパン間の親子関係をセマンティックに追えておらず、ゆえにスパン毎の開始時間終了時間で可視化しているのではといった疑念があります。少なくとも筆者は触っていてところどころ違和感を感じます。
つなぎこみの手間
OpenTelemetry Collectorの独自エクスポーターがあります。最低限の設定自体はシンプルなのですが、5分探してもコピペできるconfigが見当たらなかったのと、ドキュメントのサンプルがヘビィで第一印象は悪いです。一方で設定値が細かく書かれているので、採用後はまた心象が変わるかもしれません。
コスト、制約や知名度
コストは界隈で一般的な複雑なものです。日本リージョンもあるので、目立った制約はなさそうです。
所感
方向性としては探求するケイパを提供するというよりビルトインの分析結果を提供していく考え方なので、その時点で筆者の思想とはミスマッチでしたし、トレース詳細も個人的には苦手で、筆者としては推さないです。
Service Catalogという機能があり、この機能が分析機能への導線を兼ねていて実は超優秀、という可能性はありますが、テレメトリを流すだけでは使えるようにならなかったので今回は諦めてしまいました。
7. AWS Stack
機能性
トレースの傾向を分析する機能はアナリティクスという画面があり、ビジュアライズはできませんが様々な属性でグルーピングしてリストで見ることができます。また、特徴的な機能として、マイクロサービスのマップを自動で書いて、その単位でメトリクスを見られるTrace Mapという機能があります。

トレースの検索ですが、そもそも6時間以内しか検索対象にできず、この記事を書くのに過去取得したトレースを探すのに苦労しました。トレース詳細でもサービス間のマップが出てくるのは面白いのですが、肝心のトレースはツリーになっておらず見づらいです。また例外はスパン単位で紐づきそうですが、ログはトレース単位でしか紐づきません。

全体的な体験があまり良くありません。X-Rayがトレース、CloudWatch Logsがログ、Cloud Watch Metricsがメトリックに対応しており、やや分かりづらいです。また、X-Rayではスパンのことをセグメントと呼んだりと、概念の独自定義が多く学習コストが高い印象です。
AWSインフラとのシナジー、コスト
Google Cloud同様、AWSインフラを使うのであれば、ツールやコストの管理負荷の面でメリットがあります。費用もとても安いです。
つなぎこみの手間
AWSが提供するAws DISTRO for OpenTelemetryを使ってOpenTelemetry Collectorを立てる必要があります。独自のイメージに独自のエクスポーター、そして開発中にローカルからAWSにテレメトリを送りたくなったときの認証の調査など、Google Cloud Stack同様に学習コストとつなぎこみの手間は大きい印象です。
所感
正直チープで触っていて楽しくありません。オブザーバビリティに真剣に向き合うならサクッと他ツールに移行したほうが良い気はします。
8. Grafana Cloud
筆者はGrafanaをセルフホストで触ったことがないので、この体験がGrafana Cloud特有のものか、Grafanaも同様なのか、あるいはGrafanaをカスタマイズすれば良い体験が得られるのか等は理解せずに書いています。ご認識おきください。
機能性
まず全体に学習コストが高く、触り始めの体験はとても悪いです。ナビゲーションや全体検索がわかりづらく、トレースやログが見たいだけなのに、どこに行けばいいのか全くわかりません。ちなみに正解はExploreです(下に添付)。またログについてはトライアルでは No logs volume available という表示が出てしまい、これが何故出ているのか、どうしたら解消できるのか10分調べてもわからず、結局あきらめました。

トレース検索はフィルタやソートが可能、トレース詳細はスパンのフィルタ等が可能と、一般的な機能を備えています。唯一筆者が思いつくGrafana Cloudの強みとしてスパンレベルでログと紐づくことが挙げられるのですが、惜しいことに、これは1画面内で見ることができず画面遷移してしまい、障害対応時に各スパンで出るログを見ていくといった使い方は厳しいです。

また、トレースの集合に対する分析やビジュアライズの機能については、HoneycombやDynatraceのように深堀るケイパを提供する機能も、New RelicやSplunkのようにビルトインで提供する機能も見つけられませんでした。
つなぎこみの手間
コピーできるCollectorの設定がドキュメントにあります。ただし、トレース以外は独自のエクスポーターだったり、設定も重厚で初見でコピペするのは抵抗感を感じます。Loki、Tempo、Prometheusといったシグナルごとの製品名・機能名も覚える必要があります。またシグナルごとにURLやユーザー名を入れる必要があり、製品自体の初見の体験がよくないことも相まって、セットアップにはかなり手間取りました。
所感
機能も商用ツールに対して劣後しており、学習コストも非常に高く、よほどオープンな技術を選ぶべき制約でもない限り、筆者が勧める機会はなさそうです。
まとめ
この記事では、筆者が触ってみた8種類のオブザーバビリティ(OpenTelemetry)バックエンドについて、筆者の強い思想を込めて、推し順で紹介しました。
結論としては、Honeycombが最推しです。次点でDynatrace、Splunkが同じくらい推せます。この3つが爆推しグループです。New Relicは筆者の思想とはマッチしませんが優秀、Google Cloudもクラウドプラットフォームの備え付けにしては優秀です。この2つは普通に推しです。残りの3つは推しません。
実は筆者は、この試みを始める前、Grafana Cloudが最強なのではという漠然と思っていました。理由は単にGrafanaがオープンな技術だからです。多くの人にとってベンダというのは、平気でベンダロックインさせてくる、設計センスがない、チケット切っても技術わからないCSの相手をさせられる、お極めつけには高額な費用と、とにかく信用ならない輩といったイメージでしょう。私も皆さんと同じです。
しかし、8種食べ比べをやってみて、当初の先入観は完全に覆されました。HoneycombやSplunkが持つトレース属性間の相関性の分析、HoneycombやDynatracの持つ探求のケイパビリティ、SplunkやNew Relicのビルトインの分析による追加情報の提供といったものは、単にテレメトリを保存検索できたりシグナル間を紐づけられるという域を越えて、より高度なオブザーバビリティオペレーションを実現しています。UIUXやドキュメンテーション、オンボーディングにもしっかりと投資されています。
この試みを通じて、有償オブザーバビリティバックエンドの素晴らしさをより解像度高く認識できました。同時に、オブザーバビリティベンダへの期待と信頼が高まったことで、外形監視やリアルユーザーモニタリングなど、筆者はベンダ独自のオブザーバビリティ機能にも興味が出てきています。
この記事が、候補の絞り込みや選定観点の整理など、少しでもツール選定の助けになれば幸いです。皆さんにオブザーバビリティの導きのあらんことを。
追伸
よければTwitterもフォローいただけると嬉しいです。
業務委託で技術顧問やSREもやっていますので、お困りごとなどあればぜひご相談ください。
変更ログ
typoなど軽微な物は記載しません。
- 2024/03/06
- 制約セクションに、筆者が気づけなかった機能やセットアップコストが高かった機能は評価に含めていない旨を追記
- Dynatraceのカスタム多次元分析について、トレースに対する内部メトリックを生成しているという考察とスクリーンショットを追加
- SplunkのTag Spotlightについて、機能がわかりづらいのではなく筆者の見落としと判断し、記載を追加。あわせて、評価順も変更し、全体的な説明も修正
- Dynatraceの所感に、Honeycombとの比較考察の記載を追加
Discussion