OpenTelemetry 分散トレーシングのシステムアーキテクチャ
sumirenです。
SREやSDETや技術顧問やフルスタックエンジニアをしています。
この記事は OpenTelemetry Advent Calendar 2023 3日目の記事です。
2日目の記事は @k6s4i53rx さんの OpenTelemetryとOpenObserveを使ってKubernetes監視をかじる でした。
背景
OpenTelemetryを使うと、分散システムの各サブシステムでどのように処理が進んだのか可視化することができます。
経験を積んだエンジニアの方であれば、各サブシステムとオブザーバビリティバックエンドが一体どのようなコラボレーションをしているのか気になることかと思います。実際、SDKやOpenTelemetry Collectorを使って手軽に分散トレーシングを実現できても、仕組みを理解できていないと、いざトラブルが発生したときに問題解決が難しいでしょう。
この記事では、OpenTelemetryにおけるそうした分散トレーシングのシステムアーキテクチャを解説したいと思います。
この記事は、筆者なりに価値を出すために、説明を取捨選択したり筆者の視点を加えたりはしていますが、基本的には2023年12月時点での技術的事実を取り扱うものです。そのため、記事の誤り・事実誤認はコメント等でご指摘いただけますと幸いです。
対象読者
OpenTelemetryに関して最も基礎的な知識があることを前提とします。例えば、TraceやSpan、OpenTelemetry Collectorといった概念は既知のものとして説明しません。一般的なオブザーバビリティバックエンドでTraceを可視化した際のイメージも持てているものとします。
分散トレーシングのシステムアーキテクチャ
例えば、HTTPベースのAPIを持つ簡単なマイクロサービス間について、OpenTelemetry CollectorとJaegerで分散トレーシングを実現しているとします。マイクロサービス間は上流から下流に同期的にAPIを呼んでいくものとします。以下にブラウザから1つリクエストが来た際の処理を図解します。

さて、ブラウザからサービスBまでのリクエストの流れはシンプルです。単にRESTとかgRPCのようなHTTPベースのリクエストが同期的に流れているだけです。OpenTelemetry CollectorからJaegerにトレース(ログやメトリクスも)が連携されるのもわかりやすいでしょう。ブラウザは今回あまり関係ないためグレーアウトしています。
この記事で説明したい分散トレーシングの仕組みとは、各サービスとOpenTelemetry Collectorの間です(図中の赤い部分)。ここがどのような仕組みになっているか想像はつくでしょうか。想像がつかないようであれば、この記事が役に立つかもしれません。
正解は以下のようになっています。図中のtraceIdやspanIdといった項目名は実際の項目名とはやや異なります。値のxxxや1などもデフォルメしており、実フォーマットとは異なります。この図を見ながら一緒に処理を追っていきます。
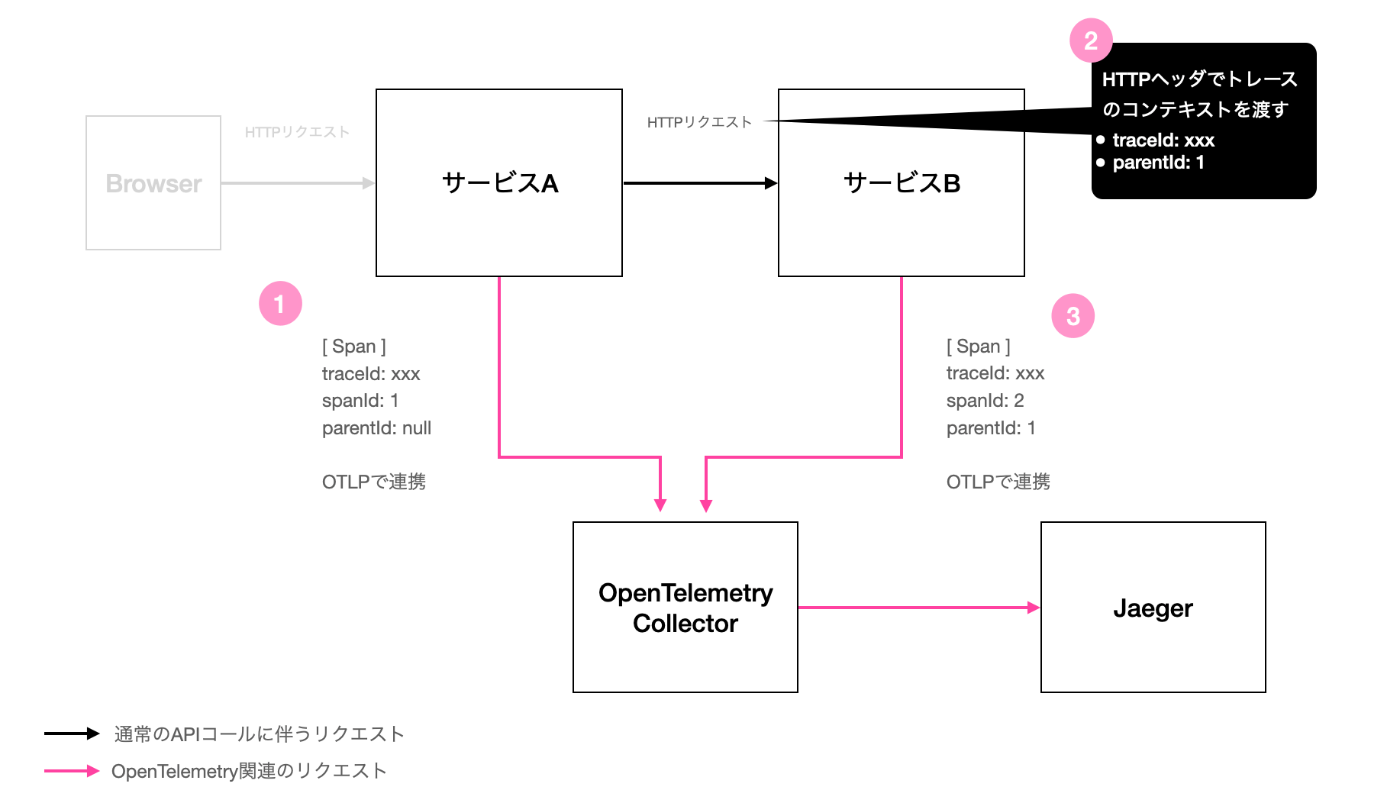
ポイント1. Spanは個別サービスから独立して送信される
まずサービスAがブラウザからリクエストを受け取ります。サービスAは自身がTraceのrootであるため、TraceのIDを発番します。そしてそのTraceのIDに紐付ける形でSpanのIDを発番していきます。これらの処理は自動計装であれば全てエージェントやSDKが行います。
ここで1.の処理が発生します(正確には非同期処理です)。結論から言えば、個別のマイクロサービスはそれぞれが独自にOpenTelemetry Collectorやオブザーバビリティバックエンドに対してSpanを連携します。これはつまり、サービスAがサービスBに詳細なSpan情報を送ったり、逆にサービスBがサービスAに自身が生成したSpan情報を返すことはないということです。ゆえに、サービスAやサービスBは、お互いがどのようなSpanを生成したかは知ることはありません。
この例では、サービスAは自身が採番したtraceId:xxxと、spanId:1をOpenTelemetry Collectorへotlpというプロトコルで連携しています。このSpanはrootのため、parentIdはnullになっています。ここでは便宜上Spanが1つしか生成されていない前提になっていますが、実際には、サービスAの計装次第でデータベースアクセス等のSpanが細かく生成されることになります。
このとき、通信プロトコルとして、サービスとOpenTelemetry Collectorの間ではOTLP(OpenTelemetry Protocol)が使用されます。一方で、オブザーバビリティバックエンドとOpenTelemetry Collectorの間については、特に前者が有償の場合、ベンダはベンダ固有のExporterを入れるよう案内しています。OpenTelemetryに対応していてもOTLPは十分にサポートできていなかったり、固有のメタデータをExporterで付与したいのかもしれません。
ポイント2. サービス間はHTTPヘッダでメタデータを連携する
次に2.の処理が発生します。前のセクションで説明したとおり、OpenTelemetryのアーキテクチャでは、サービスBはサービスAがどのようなSpanを生成しているか知ることはありません。しかし、「サービスAの処理の一部としてサービスBの処理が走る」といったトレースの全体像をオブザーバビリティバックエンドで復元するためには、現在のリクエストのTraceのIdと、自分がこれから生成するSpanの親にあたるサービスAのSpanのIdは最低限知る必要があります。
そのために、サービスAからサービスBへのHTTPリクエストにはtraceparentというHTTPヘッダが付与されます。このヘッダにはハイフン区切りで上記の情報が含まれています。こうした機能はContext Propagationと呼ばれています[1]。このヘッダの付与や読み取りは、自動計装であればエージェントやSDKが行います。
3.の処理はここまで説明した内容の振り返りです。サービスBは生成するSpanの情報をサービスAに返したりすることはなく、単に独立してotlpで送信します。その際、サービスBはTrace全体のtraceIdがxxxであること、親SpanのspanIdが1であることを踏まえ、Spanの情報を構成します。こうして、オブザーバビリティバックエンドではSpan間の関係性を理解し、トレースの全体像が復元できます。
なお、ここでも便宜上Spanが1つしか送信されない書き方になっていますが、実際には多数送られることになります。サービスBが最初に送るSpanのparentIdのみ1となり、それ以降はツリーのようにサービスB自身のSpanが親Spanになっていきます。
まとめ
この記事を通じて、分散トレーシングのためにサービス間でどのようなコラボレーションが起きているのか、アーキテクチャの概要を説明しました。実際のところ、筆者もこうした知識がないと解決できない問題に出くわした経験があります。例えば、ローカルでは動くのにクラウドにデプロイするとトレースが壊れるといった事象です。例えば、Context PropagationがHTTPヘッダとして実現されていることを知っているだけでも、ロードバランサが怪しいといった形であたりをつけたり、どこでHTTPヘッダが途絶えているか調査することができます。
筆者の場合、問題が発生したときにログを仕込んだりWiresharkで通信内容を見て、苦労しながらOpenTelemetryへの理解を深めることになりましたが、そのときに筆者が知っていたかったことや公式ドキュメントから分かりづらかったことを端的にまとめたものがこの記事です。少しでもお役に立てば幸いです。
2023/12/9には、本業で所属している株式会社ヘンリーのアドベントカレンダーへのポストも予定しています。そちらでは、OpenTelemetryをクラウドに導入する際のポイントについて事例を書きたいと思っています。この記事の延長線上にある内容を予定していますので、よければ是非ご確認ください。よければTwitterもフォローいただけると嬉しいです。
4日目は @aereal さんです!
-
traceparentの他にbaggageヘッダもついてたり、traceparent以外のヘッダ名も選べたり、traceparentの値にはtrace flagsなども含まれていますが、割愛します。 ↩︎
Discussion