はじめまして。スマサテ株式会社でデータサイエンティストをしている大村です。
スマサテには賃貸物件の賃料査定機能を中心としてさまざまなデータサイエンスの技術が組み込まれており、現在も機能の追加・ブラッシュアップに向けて様々な試みを行っています。
今回は「不動産データと因果推論」というテーマの書きはじめとして、なぜ不動産データに因果推論が必要なのかについてお話したいと思います。
賃貸物件の「設備」と「賃料」
賃貸物件には、さまざまな設備が付帯しています。共用部に設置される宅配ボックスやエントランスのオートロック、部屋ごとに設置されるウォシュレットやエアコン、またはインターネットが無料で使えるか?など規模や種類は多岐にわたります。私たちも引っ越しの時にはこのような設備・サービスの充実度を参考にしながら物件探しをしていますよね。
さて、スマサテのユーザー、すなわち賃貸物件を供給する側にとっての大きな関心ごとは「この設備をつけたら家賃をどれくらい上げられるのか?」という問題です。賃貸物件の家賃設定を行うオーナーや管理会社は自分の物件をより魅力的なものにして家賃を維持・引き上げしていくために設備の追加を検討しますし、新築物件の建設を検討するディベロッパーはどんな設備を設置するかを計画する必要があります。この問いにデータ分析で取り組めないかを考えてみましょう。
分析してみよう
今回は、近年人気の設備である「宅配ボックス」について考えてみます。不在の時にも荷物を受け取ることができる便利な設備です。分析の目標は「宅配ボックスの有無によって家賃相場がどれくらい変わるのか?」「既存の物件に宅配ボックスを設置したらどれくらい賃料(=物件の価値)が高まるのか?」をデータから推定することです。
単純に考えると、データを宅配ボックスありグループと宅配ボックスなしグループの家賃に分けて、家賃平均を比較すれば設備の家賃影響額が分かりそうですね。とあるエリアのデータを集計してみましょう。
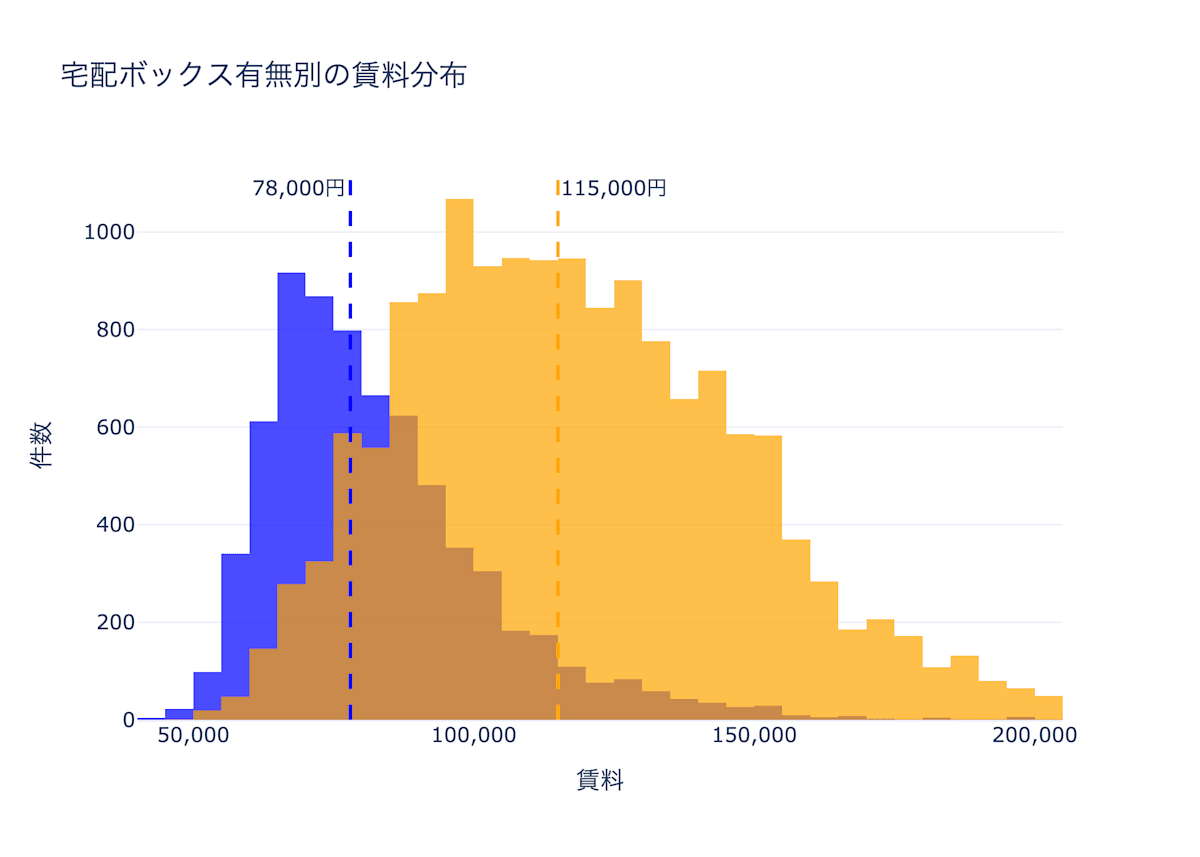
綺麗に傾向が分かれました。わかりやすい傾向が現れると嬉しいですね。
宅配ボックスなしでは平均賃料78,000円くらい、ありでは平均賃料115,000円となったので、差額は37,000円です。 かくして宅配ボックスが付いていることによる賃料への効果額は+37,000円とわかったのでした。めでたしめでたし...
...とはいきませんね。宅配ボックスがあるだけで毎月の家賃が+37,000円も高いのはさすがに違和感があります。この集計は何がいけなかったのでしょうか?
集計に潜むバイアス
因果関係の定量的な分析を行おうとするとき、大きな障壁となるのはバイアスの存在です。
例えば、宅配ボックスと物件の築年数には強い関係性があります。以下のグラフを見てください。

新築物件には宅配ボックスがほぼ100%設置されており、築25年くらいから急激に普及率が下がっていくのがわかります。先ほどの賃料比較を思い出すと、宅配ボックスの有無別にデータを分けて賃料を比較していたつもりが、知らない間に宅配ボックスあり群には築浅ばかりが、宅配ボックスなし群には築古ばかりが偏った状態で集計を行ってしまっていたことになります。
このような隠れた偏りを引き起こしてしまう要素は交絡因子と呼ばれます。 築年数は宅配ボックスの普及率と家賃の両方に作用する(と考えられる)因子の一つです。

ではどうする?因果推論の手法
これまでの考察の通り、単純な集計ではうまくいかないことがわかりました。問題の難しさを理論的に把握するために、問題の定式化してみましょう。鍵となるのは潜在的効果(Potential Outcome)という考え方です。
※本当は異なる枠組みの体系もありますが、今回はRubin流の考え方に則ります。
問題の定式化
潜在的効果の考え方は以下の通りです。
それぞれの物件は宅配ボックスが設置されている世界線での家賃
私たちがやりたいことは、現実世界で観測できなかった方の潜在的な家賃を推定し、観測できた方の家賃と比較することです。宅配ボックス設置による効果量は以下のように定式化されます。これは一般にATE(Average Treatment Effect)と呼ばれます。
ただし、先述したようにこの効果量は現実のデータでは計算できません。現実の世界では、同一の物件に対して宅配ボックスがついている世界とついていない世界を同時に観察することができないからです。
そこで仕方なく、先ほどの計算ではデータを宅配ボックスがついている群とついていない群をグループに分けてから家賃の平均を計算したのでした。これは以下のような計算をしたことになります。
本来求めたかった
と変形できるので、
と分解できます。
ここでの❷がまさに先ほどの例で発生してしまった知らない間に宅配ボックスあり群には築浅ばかりが、宅配ボックスなし群には築古ばかりが偏った状態で集計を行ってしまっていた事象に対応するバイアスです。すなわち宅配ボックスがある群とない群でそもそも潜在アウトカムに差がある(宅配ボックスがついていない世界線に揃えたとしても家賃に差がある)ことによって、設備の効果が過剰に高く推定されてしまうことを表しています。
※❶についてもいろいろな観点があるのですが、ここでは省略します。ATTはAverage Treatment effect on Treatedの略で、処置(今回のケースでは設備の設置)が行われた群のみに対する処置効果の平均です。
因果推論の手法たち
上記で見た通り、セレクションバイアスの影響をなんとか小さくしながら真の効果
-
データの層化
築年でバイアスが起きてしまうなら、新築のグループで推定、築1-5年のグループで推定...とデータを層化してそれぞれに対して効果量を推定すれば良いのでは?といった発想で、共変量によってデータを適切に分割することでバイアスを軽減する方針 -
重回帰分析を用いる方針
T X -
傾向スコアを用いる方針
共変量X T -
Meta-Learnerを用いる方針
GBDTなどの複雑な機械学習モデルを用いて反実仮想(観測できなかった方のアウトカム)を推定する方針(S-Leaner, T-Learner, X-Learnerなど)
残念ながら、これらの中に万能な手法は存在しません。最新の手法の方がより効果的であるわけでもありません。それぞれの手法には制約条件があり、手法固有で発生してしまうバイアスも存在します(例えばMeta-Learnerは一見夢のような手法ですが、正則化バイアスは手強いバイアスです。)
因果推論に限らず、データサイエンスで取り組まれる課題は既存の手法に当てはめて結果がポン、で解決するものは非常に限定的です。各手法の特性の把握、データの持つ特性の分析と理解、ドメイン知識の深化...長い長い試行錯誤の旅が始まります───
おわりに
本項では、不動産データにおける因果推論というテーマの書きはじめとして、その必要性や問題設定の外観までを述べました。より具体的な試行錯誤の取り組み例などについても記事にしていきたいと考えていますのでお楽しみに!
採用情報
弊社ではWebフルスタックエンジニア、AIエンジニアなどを積極的に採用しています。
ご興味のある方はぜひWantedlyをご覧ください。
参考文献
- 効果検証入門:https://gihyo.jp/book/2020/978-4-297-11117-5
- 因果推論 : https://www.ohmsha.co.jp/book/9784274231230/
- はじめての統計的因果推論 : https://www.iwanami.co.jp/book/b639904.html
- Pythonライブラリによる因果推論・因果探索 : https://book.impress.co.jp/books/1123101074

Discussion