ローカルLLMを使って英語の動画に英日字幕をつける
はじめに
私は英語力があんまりないので、字幕がないと(ときには字幕があっても)海外の動画を理解するのは難しいです。
最近LLM使ってなんかできないかな~と思っていたのもあって、せっかくなので困っていたことの一つにチャレンジしてみました。
おおまかな手順は下記の通り。
- 英語の動画から音声認識をして字幕ファイルを作る
- 字幕ファイルの英語を日本語に翻訳して追記する
- 元の動画と字幕ファイルを合成する
- 楽しむ
外部サービスには出したくないのでローカルLLMを使います。
PCスペック的には最近のゲームがそこそこ動くPCなら大丈夫だと思う。
コードはこの辺にもおいてます。
手順
音声認識&字幕ファイル生成
音声認識自体は昔やったことがあって、Whisperというのを使ってました。
なんかfaster-whisperという高速化バージョンがあるらしいのでそっちを使う。
字幕はどうやらSRTという形式がメジャーらしい。よくわからんけどそれで。
import sys
import datetime
from pathlib import Path
import srt
import torch
from faster_whisper import WhisperModel
def seconds_to_timedelta(seconds: float) -> datetime.timedelta:
return datetime.timedelta(seconds=seconds)
def generate_subtitles(audio_file: Path, model: WhisperModel):
segments, info = model.transcribe(str(audio_file), beam_size=5)
segments = list(segments)
total = len(segments)
subtitles = []
for index, segment in enumerate(segments, start=1):
print(f"Processing segment {index}/{total}...", flush=True)
start = segment.start
end = segment.end
text = segment.text.strip()
subtitle = srt.Subtitle(
index=index,
start=seconds_to_timedelta(start),
end=seconds_to_timedelta(end),
content=text
)
subtitles.append(subtitle)
return subtitles
def main():
audio_file = Path(sys.argv[1])
device = "cuda" if torch.cuda.is_available() else "cpu"
compute_type = "float16" if device == "cuda" else "float32"
model = WhisperModel("base.en", device=device, compute_type=compute_type)
subtitles = generate_subtitles(audio_file, model)
srt_output = srt.compose(subtitles)
output_file = audio_file.with_suffix('.srt')
with open(output_file, "w", encoding="utf-8") as f:
f.write(srt_output)
if __name__ == "__main__":
main()
変換が完了すると、こんな感じのファイルができます。
あとはこれをいい感じにコネコネしていきます。
1
00:00:00,000 --> 00:00:02,200
Hey, good morning.
mp3の抽出はffmpegとか使って適当に。
$ ffmpeg -i input.webm -q:a 0 -map a output.mp3
英日翻訳
Google先生に聞いたところ Helsinki-NLP/opus-mt-en-jap というのが比較的人気の高いモデルだとのハナシ。
ところが、使ってみたらあまりに悲しい(ハルシネーションが多すぎる)翻訳にうんざりしたのでLLMに任せることにしました。
使ったモデルは去年くらいに話題になったこれ。
最近のおりこうモデルと比べると推論パワーは落ちますが、ローカルでも軽々動いて性能もそこそこ良いです。
API Serverとして動かすのは、JanというGUIアプリケーションの機能でよしなにしました。
とりあえず翻訳だけ試してみる。
余計なことは言わずに日本語に訳せやというプロンプトで。
import sys
import requests
def translate_with_api(text: str) -> str:
response = requests.post(
"http://127.0.0.1:1337/v1/chat/completions",
headers = {"Content-Type": "application/json"},
json={
"messages": [
{
"role": "user",
"content": f"You are a professional translator. Translate the following English text into Japanese. Do not include any additional explanations, system messages, or formatting—provide only the translated text as your answer. : {text}"
}
],
"model": "Llama-3-ELYZA-JP-8B-q4_k_m",
"stream": False,
"max_tokens": 1024,
"stop": ["End"]
}
)
answer = response.json()['choices'][0]['message']['content']
return answer.replace("<|eot_id|>", "")
def main():
translation = translate_with_api(sys.argv[1])
print(translation)
if __name__ == "__main__":
main()
$ uv run python translate.py "Hey, good morning."
おはようございます。
いいかんじ。
字幕翻訳
前のやつを参考にSRTを書き換える。
import sys
from pathlib import Path
import srt
import requests
def translate_with_api(text: str) -> str:
response = requests.post(
"http://127.0.0.1:1337/v1/chat/completions",
headers = {"Content-Type": "application/json"},
json={
"messages": [
{
"role": "user",
"content": f"You are a professional translator. Translate the following English text into Japanese. Do not include any additional explanations, system messages, or formatting—provide only the translated text as your answer. : {text}"
}
],
"model": "Llama-3-ELYZA-JP-8B-q4_k_m",
"stream": False,
"max_tokens": 1024,
"stop": ["End"]
}
)
answer = response.json()['choices'][0]['message']['content']
return answer.replace("<|eot_id|>", "")
def main():
srt_file = Path(sys.argv[1])
with srt_file.open("r", encoding="utf-8") as f:
srt_content = f.read()
subtitles = list(srt.parse(srt_content))
total = len(subtitles)
for idx, subtitle in enumerate(subtitles, start=1):
english_text = subtitle.content.strip()
translation = translate_with_api(english_text)
print(f"[{idx}/{total}] {translation}")
subtitle.content = f"{english_text}\n{translation}"
output_content = srt.compose(subtitles)
output_file = srt_file.with_name(srt_file.stem + "_translated.srt")
with output_file.open("w", encoding="utf-8") as f:
f.write(output_content)
if __name__ == "__main__":
main()
1
00:00:00,000 --> 00:00:02,200
Hey, good morning.
おはようございます。
こんな感じになる。字幕生成に比べたらそこそこ速い。
字幕の合成
ffmpegを使うと音声とか動画とか字幕とか色々ガッチャンコできます。
字幕ファイルとして埋め込んでもいいけど、動画内に埋め込んだほうがいろんなデバイスで再生できるんじゃないかな。下記は一例。
$ ffmpeg -i input.webm -vf "subtitles=input.srt" -c:a copy output_subs.webm
私の場合、別に音声だけでよかったので真っ黒背景に字幕だけを入れてmp3と合成しました。
なんか知らんけどググったら下記のようなコマンドが出てきたので、じゃあそれでと入れたらできた。
$ ffmpeg -f lavfi -i color=c=black:s=1280x720 -i input.mp3 -vf "subtitles=input.srt" -c:v libx264 -c:a copy -shortest output.mp4
こんな感じ。
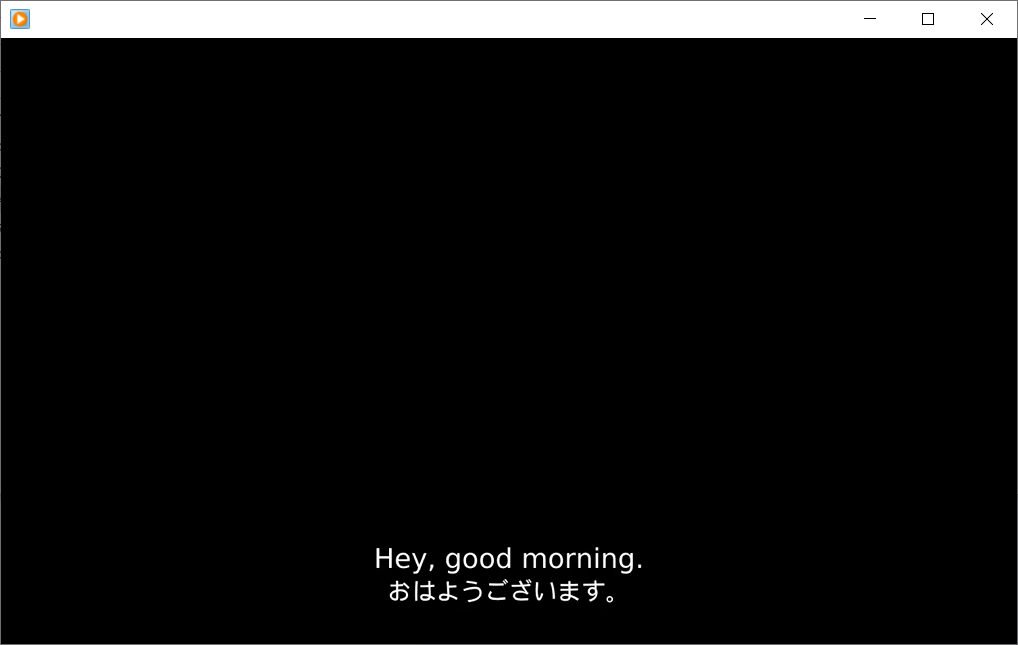
上記の例はすごい単純な英文だけど、実際にはそこそこ長くて専門的な話でもいい感じに訳してくれた。
それを見せないのは単に著作権におびえているだけです。
おわりに
思いつきでやったけどおもったよりいい感じにできてよかったね。
偉大なる先人達に感謝。あとコード書くの手伝ってくれたo3-mini-highにも。
お し ま い
Discussion