はじめに
今回は、本番稼働中の弊社メインとなるサービスを ElasticBeanstalk から ECS+Fargate に移行する機会があったので、その軌跡をまとめます。アプリケーションは主に Laravel で構築されており、API サーバ、Worker、cron によるバッチ処理といった構成で運用されています。
開発チームで管理している API サーバは、主にお客様向けの API サーバと社内運営向けの API サーバの 2 つがあります。前者については約 4 ヶ月間(2023 年 6 月から 2023 年 10 月)かけて移行を完了しましたが、後者は私が空き時間を利用して進めていたため、結果として完全移行に予想以上の時間がかかりました 🙏
また、少し前に MySQL のバージョンアップ作業を終え、今回の ECS+Fargate への移行作業も無事完了し、ようやくインフラ周りの大規模な変更が一段落しました。
背景
弊社で管理するメインサービスの API サーバは、サービスイン当初から ElasticBeanstalk で運用しておりました。ElasticBeanstalk は、アプリケーションのデプロイ、スケーリング、ロードバランシング、モニタリングなどを自動で行ってくれるサービスで、インフラの知識が浅いエンジニアでも簡単に運用できるため、初期段階での選択肢としては非常に優れたサービスです。
ただ、サービスが成長するにつれて、ElasticBeanstalk で運用する上で、いくつかの課題が浮かび上がってきました。主に、以下のような課題がありました。
-
プラットフォームの更新が手間
- 新しいバージョンのプラットフォーム、ランタイムを利用する際、基本的に 0 からの新規構築が必要で、簡単にバージョンアップができない。
-
ランタイムに関するバージョン更新の遅延
- ElasticBeanstalk はプラットフォームの更新が遅く最新の PHP ランタイムなどが利用できない。
-
デプロイの遅延
- ElasticBeanstalk はデプロイ時に EC2 インスタンスを新たに立ち上げ、古いインスタンスを削除するため、デプロイに時間がかかる。
-
スケーリングの遅延
- ElasticBeanstalk はスケーリング時に EC2 インスタンスを新たに立ち上げるため、スケーリングに時間がかかる。
-
スケーリングの粒度
- ElasticBeanstalk はスケーリングの粒度が EC2 インスタンス単位であるため、スケーリングの際に無駄なリソースを立ち上げることがある。
上記課題 に関し幾つかは ElasticBeanstalk にて、Docker コンテナからアプリケーションをデプロイすれば解決でますが、コンテナ化するのであれば、ECS+Fargate の方が適していると考え、ECS+Fargate への移行を決定しました。
以降、ElasticBeanstalk を eb と表記します。
なぜ AWS Fargate を選択したのか
弊社、開発チームメンバのスキルセットとしては、アプリケーション開発がメインであるため、以下を念頭に選定しました。
- シンプルなインフラ構成であること
- インフラの運用コストを抑えること
AWS Fargate 以外の候補としては、以下のような選択肢がありました。
ECS + EC2 との比較
ECS + EC2 は、ECS を使用してコンテナを管理し、EC2 インスタンス上でコンテナを実行するサービスです。そのため、EC2 インスタンスの管理が必要となります。一方、Fargate を使用する場合、EC2 インスタンスの管理は不要です。このことから、Fargate の方が運用コストが低いと考え、Fargate を採用しました。
EKS(Elastic Kubernetes Service) との比較
AWS Fargate 同様、EKS はコンテナオーケストレーションサービスですが、EKS は Kubernetes をベースとしているため、EKS の運用には Kubernetes の知識が必要です。弊社の開発チームメンバのスキルセットとしては、Kubernetes の知識が浅いため、EKS の導入は避けることとしました。
以上のことから、ECS + Fargate を採用することにしました。
移行前の構成
既存 eb 上で運用されていたサービスは、以下のような構成で動作していました。PHP ランタイム上で Laravel アプリケーションが動作しており、比較的一般的な構成です。
構成要素
-
API サーバ
- 一部のエンドポイントでは、Blade テンプレートを使用して HTML レスポンスを返却
-
Worker
- 主に非同期処理のためのキュー処理を担当
-
cron によるバッチ処理
- 期的に実行されるバッチジョブを担当
移行後の構成
API サーバ、Worker に関しては、以下のような構成で構築しました。
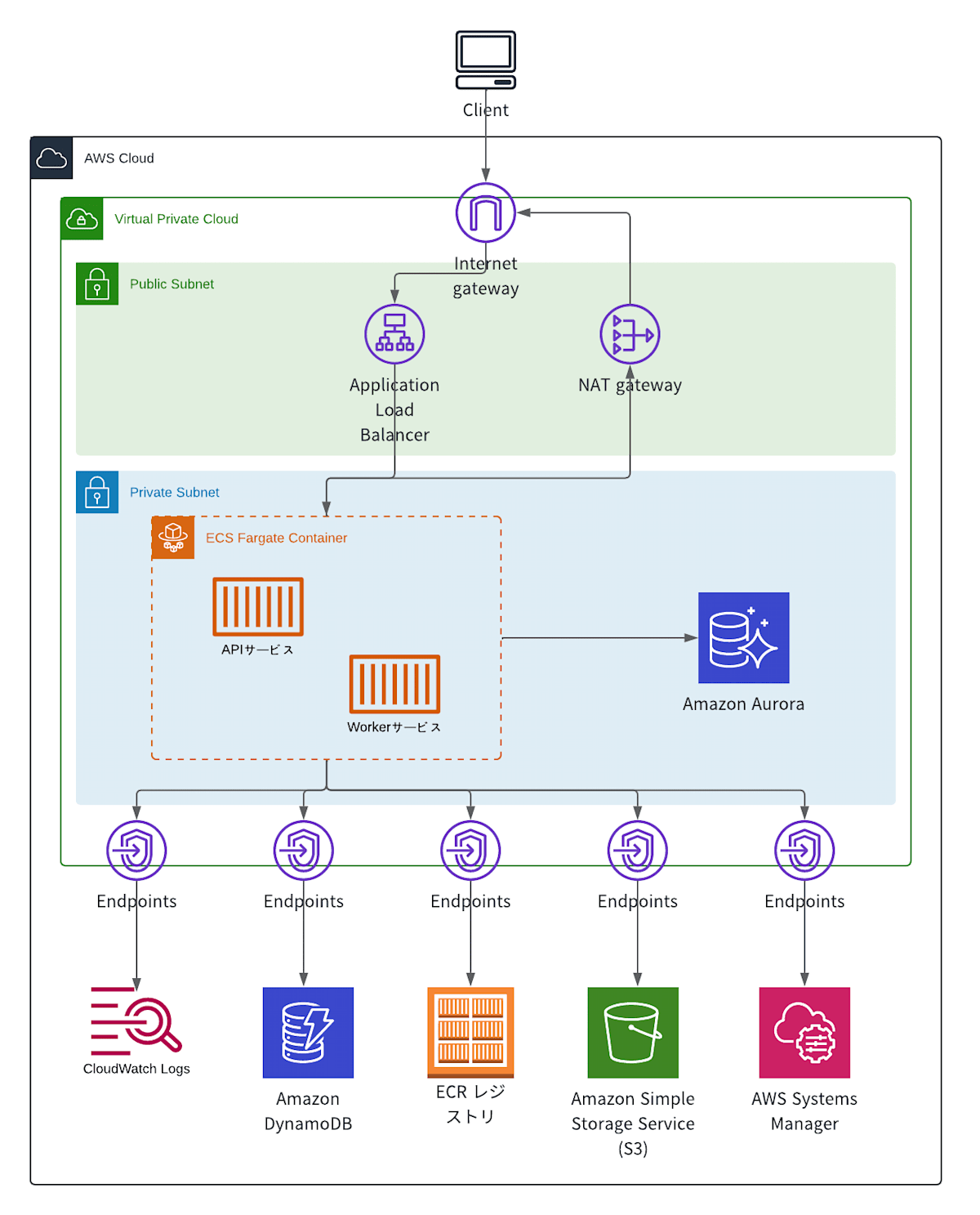
API サーバ、Worker は、それぞれ ECS サービスとしてデプロイし、Fargate 上 で実行しています。API サーバも Worker も同じコンテナイメージを利用しており、Worker コンテナ起動時にArtisan command(php artisan queue:work)渡して、Worker として動作するようにしています。
デプロイに関しては、GitHub Actions で自動化してます。ecspresso を利用して、ECS サービスのデプロイを行っています。
ECS 環境への移行方法
構成図には記載していませんが、Route 53 から ALB(Application Load Balancer)に向けて、API サーバへのリクエストを適切に振り分ける設定を行っています。具体的には、Route 53 の加重ルーティングポリシーを活用し、リクエストを徐々に ECS 環境へシフトさせる方法を採用しました。
このアプローチにより、ECS 環境への移行が段階的に進行し、システム全体に負荷をかけず、リスクを最小限に抑えることができました。また、段階的な移行により、ECS への移行が正常に行われていることを確実に確認しつつ、問題が発生した場合にも迅速に対応できる体制を整えることができました。
最終的には、全てのトラフィックを ECS 環境に移行し、従来の環境から完全に切り替えることができました。
今後の考慮事項
VPC エンドポイントを利用して S3、DyanamoDB などにアクセスするようにしていますが、通信量が少ないエンドポイントに関しては、NAT ゲートウェイを利用する方がコストが抑えられそうです。(S3、DynamoDB は VPC エンドポイントの利用料は無料です)
cron によるバッチ処理の移行
cron によるバッチ処理は、ECS Scheduled Task を利用して実行することにしました。
ECS Scheduled Task は、cron 形式で定期実行するタスクを定義できるサービスです。
概要
既存の各バッチ処理をArtisan commandで実行できるように調整し、ECS Scheduled Task で定期実行するように設定しました。バッチ実行するコンテナイメージも API サーバと同じものを使用することで、コンテナイメージの管理を簡略化しています。
また、「ECS Scheduled Task の管理を ecschedule で GitOps 化しました」を参考に、ecscheduleを利用しました。
以下のような yml ファイルを作成し、ecscheduleコマンドでバッチのスケジュールを管理しています。
region: ap-northeast-1
cluster: test-cluster
aliases:
- &ecs_settings
taskDefinition: test-task
launch_type: FARGATE
platform_version: LATEST
network_configuration:
aws_vpc_configuration:
subnets:
- test-subnet
security_groups:
- test-sg
assign_public_ip: DISABLED
rules:
- name: is_alive
scheduleExpression: cron(0 * * * ? *)
<<: *ecs_settings
containerOverrides:
- name: batch
command: ["artisan", "command:is_alive"]
disabled: false
CI/CD パイプラインで、バッチのスケジュールを変更する際には、この yml ファイルを変更し、コードレビューを行うことで、バッチのスケジュール変更を GitOps 化し管理しています。
ECS Scheduled Task 移行時の課題
「ECS の Schedule Task (Fargate) と Laravel」の「Schedule Task のつらみ」に記載にある通り、ECS Scheduled Task では、稀にタスクが多重起動する問題があります。この問題に対しては、参考記事の対策と同じように、AtomicLock する機構を導入することで排他制御を行いました。以下のような trait クラス を作成し、各バッチ処理に適用しました。
trait AtomicLock
{
public static function runIfNotRunning(string $cacheKey, callable $func, int $lockSec = 300)
{
$lockResult = Cache::driver('dynamodb')->lock($cacheKey, $lockSec);
if ($lockResult->acquire()) {
try {
$func();
} finally {
$lockResult->release();
}
} else {
Log::info("{$cacheKey} is already running. do nothing.");
}
}
}
上記 trait を以下のように利用します。
class IsAlive extends Command
{
use AtomicLock;
protected $signature = 'command:is_alive';
public function handle()
{
self::runIfNotRunning($this->signature, function () {
// ここにバッチ処理の実装
});
}
}
移行してみて
移行により、プラットフォームの更新が容易になり、PHP や Laravel のバージョンアップもスムーズに行えるようになりました。また、デプロイ速度が大幅に向上し、リリース時間の短縮にも成功しました。さらに、移行作業を進める中で、既存のシステム構成を把握する必要がありましたが、terraform import を利用して既存リソースをインポートし、コード化することができました。これにより、インフラ管理の効率化も図ることができました。
これまでの取り組みによって、インフラの運用がより堅牢で柔軟になり、今後のサービス成長に向けた土台がしっかりと整ったと感じています。これからは、さらにユーザーファーストなサービスの提供に注力し、技術的なチャレンジにも積極的に取り組んでいきたいと思います。
助太刀について
「建設現場を魅力ある職場に。」というビジョン・ミッションを基に、事業者間マッチングサービス「助太刀」、正社員採用「助太刀社員」を開発、運営しています。
助太刀では一緒に開発してくれるメンバを募集してます!
少しでもご興味を持っていただけたら下記よりお気軽にご連絡ください!

Discussion