それでも僕はGoで最速のJSONデコーダーを作りたかった
はじめに
こんにちは。Sugawara Yuutaです。前回"Go言語で最速のJSONデコーダーを作った話"という記事を投稿したものです。もし前回の記事をまだご覧になっていない方は経緯を説明しやすくなると思いますのでしたから一緒に読んでいただけると幸いです。
その後
その後go-jsonの著者であるgoccyさんからissueをいただきました。内容は自分でベンチマークを行ったところREADMEで紹介してあったほどのパフォーマンスが出なかったというものでした。goccyさんは比較的小さいJSONでベンチマークを取ったようでしたので、自分でも行ってみると予想していたよりもはるかに遅い結果が出てしまいました。おそらく大きめのJSONファイルのデコードしかベンチマークしていなかったことが裏目に出たものだと思いますが、それでも差は大きいものでした。
ということで今回は、反省を踏まえて改良を重ねてきたのでその内容を紹介しようと思います。
sugawarayuuta/sonnet
特徴
- 前回とは違い、Go言語標準ライブラリである
encoding/jsonのテストを全て通過しています。 - 互換性のためにエンコーダーを追加しました。これもテストは全て通過しています。
- 小さい構造体へのデコード速度が倍速になりました。
- いくつかのテクニックによって(下で紹介します)メモリ使用量を大幅に削減しました。
ベンチマーク
ベンチマークは広く使用されているgoccy/go-jsonから借りさせていただきました。
一番実際に使用される状況に近いことが予想されるmediumの結果のみ貼っておきます。
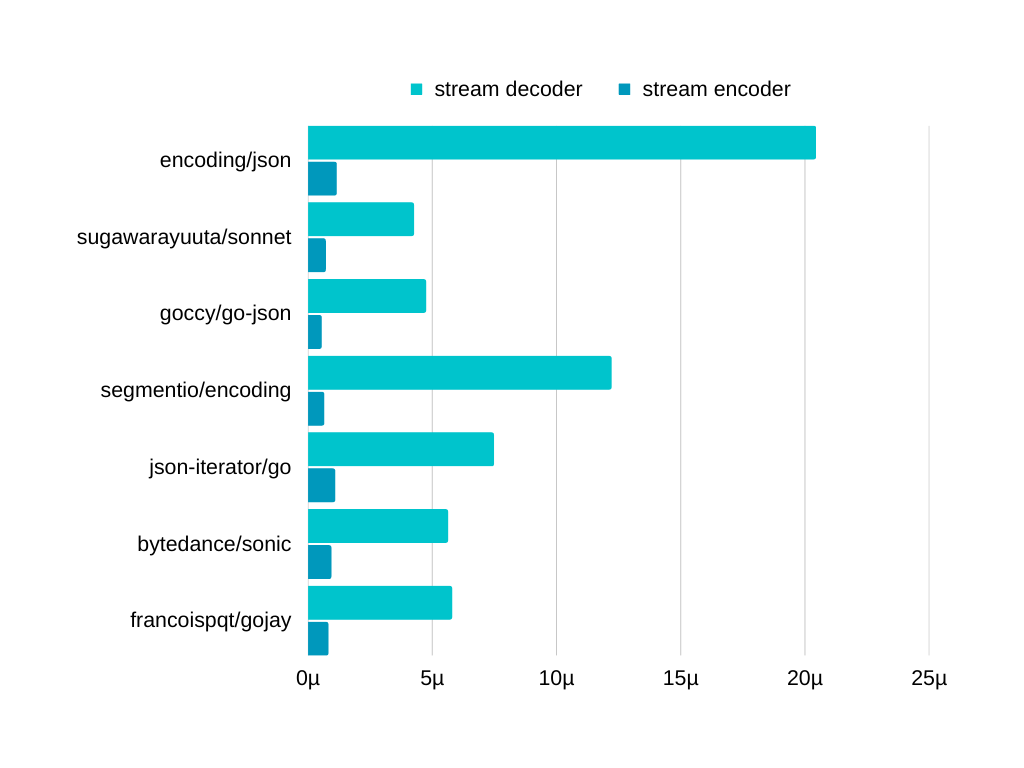
もし気になった方がいましたらご自身で計測されることをお勧めします。
実装
- 並行アクセス可能なマップの作成方法
前回はsync.Mutexを利用していましたが、unsafeを利用できる場合はsync/atomic.XXXPointerの方が読み込みはより高速に動作することが多いです。(書き込みに関して一概にそうと言えないのは僕の知る限りでは毎回新しいマップを作成して中身をコピーした後ポインターが変化していなければ挿入する方法しかないためです。)
- 完全ハッシュ関数
前回はオブジェクトのキーのルックアップにロビンフッドハッシュ法を使用していたのですが、作り終わってからキーと値のペアが最初から知られていて変更が起こり得ない場合は完全ハッシュ関数を作成できることに気づきました。
そこで、シードを取るハッシュ関数(この場合hash/maphash.String等)を使い、重複がなくなるまでシードをシャッフルするという簡易的なものでO(1)のルックアップ時間を実現しました。
- 完全ハッシュ関数のためのハッシュ
最初はアセンブリで書かれている高速なmaphashパッケージでハッシュを行なっていたのですが、内部で使われているmemhashやstrhashを直接使った方が不必要な動作を省けて高速に実行できることがベンチマークで分かり、そちらに変更しました。
結局最後にはループ展開して手動インライン化したFNV-1aに変更しました。理由は一文字ずつ読み込むため手動インライン化が簡単だったことと(ハッシュ関数のボトルネックはビット演算ではなく関数呼び出しだったためこれを考えていました)、文字が全てASCIIで成り立っている場合は256文字全てを小文字に変更したルックアップテーブルを利用することによって小文字にする作業とハッシュを生成する作業を同時に行うことができることです。
- ビット演算(SWAR)
この回で一番話したかったトピックはSWARです。正式名称は"SIMD within a register"であり、簡単に言うとSIMDが使えない環境でも複数バイトを同時に処理することができる技術のことを指します。複数バイトと聞いてピンと来た方もいるかもしれませんが、これは文字探索に利用できます。もし探したい文字が単数ならアセンブリを裏で利用しているbytes.IndexByteがおそらく一番良いのですが、そうでない時はこれを使うことができます。実行可能な例を以下に示します。
package main
import (
"encoding/binary"
"fmt"
"math/bits"
)
const mapper uint64 = 0x0101010101010101
func main() {
u8s := []uint8("01234567")
// 簡略化のためにencoding/binaryを使用
u64 := binary.LittleEndian.Uint64(u8s)
// バイト'5'が全てのバイトにマップされたuint64をXORする。
// XORは一致している場合は出力を0にする。
u64 ^= mapper * '5'
// 1が全てのバイトにマップされたuint64をひく。
// 前回の結果が0の場合はオーバーフローする。
u64 -= mapper * 1
// 0x80が全てのバイトにマップされたuint64をANDする
//(各uint8の最上位Bitをすくいだす)
u64 &= mapper * 0x80
if u64 != 0 {
// もし出力が0ではない場合はどこかで見つかったと言う意味なので、
// どこまでのビットが0なのかを確かめて8で割る。
fmt.Println(bits.TrailingZeros64(u64)/8, "で見つかりました!")
return
}
fmt.Println("見つかりませんでした。")
}
僕のコード内ではencoding/binaryの代わりにunsafeを使用していますがやっていることは変わりません。このようなトリックがもっと見たい方はここの記事を見ることをお勧めします。
- 段階つきプール
sync.Poolは並行アクセス可能、チャネルを利用する場合よりも高速など素晴らしいのですが、次にGetするときにどのオブジェクトが帰ってくるかを知る由がないため、不便なこともあります。(例えば「サイズ2048のバイトスライスが欲しい」時など。)
これを解消するために僕はプールの配列を作りそれぞれをサイズ分けしました。配列のどこに戻すかや、どこからとってくるかを決めるには、1024で割り、そのビット上の長さを計算します。これにより、だいたい2倍ずつ増えるスライスをアロケーションをほとんど発生させずに作成(再利用)できます。
- 文字列切り取り
上のようにバイトスライスを再利用するときに発生する問題が、返り値をどう分けるかということです。再利用している配列をunsafeを使ってそのままstringにキャストすると、あとで値が書き換わった時に、その返り値である文字列の中身まで書き換わってしまうということが発生してしまいます。これを解消するために毎回コピーをとっていたのですが、文字列毎に実行するとアロケーションが時に膨大になってしまうため、これを解決する策が必要でした。
結果的にはだいたい1024くらいの配列を先に作っておき、必要な分だけ切り取り、残った分はプールに入れて再利用するという方法を取ることによって解決しました。
Discussion