AIイラストサーチ:バックエンド編
はじめに
以前、AIイラストサーチというものを作ったという記事を投稿しました
今回の記事は、バックエンドを開発している際に、自分が頭の中で考えていたことを、文字として残すために書いています。(ので、ほぼ個人用のメモ。参考にならない可能性あり)
やったこと
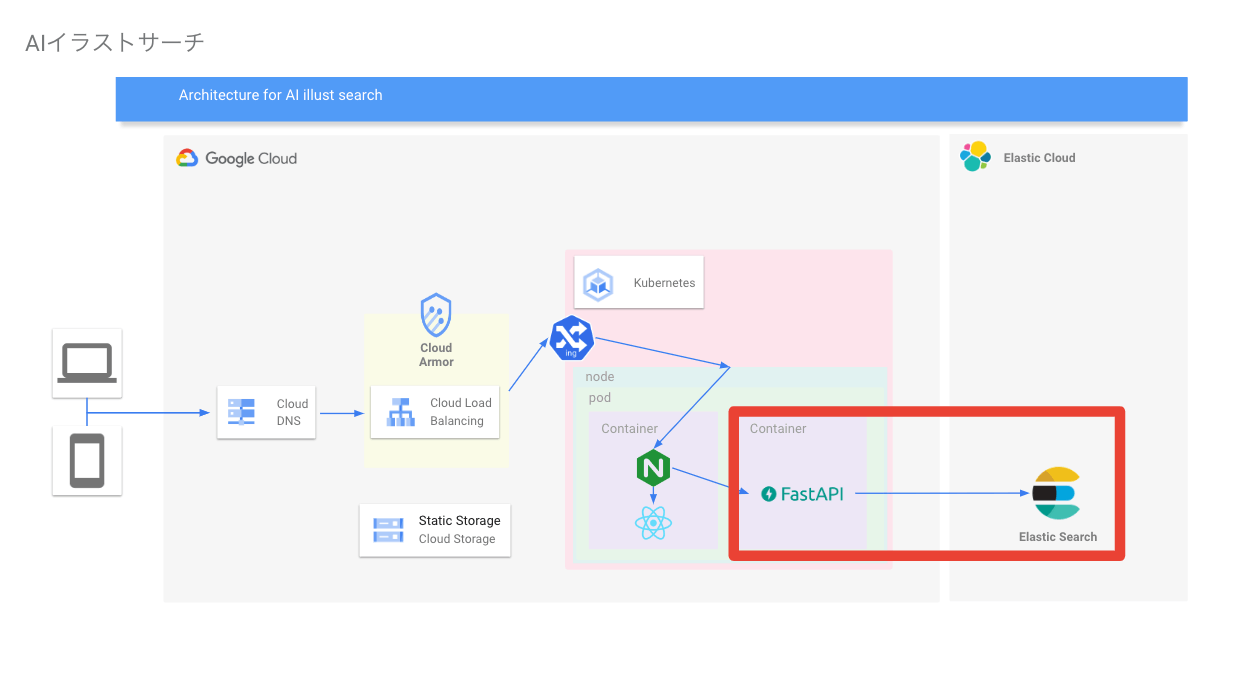
- 推論サーバーの構築
- 機械学習推論バッチの作成(2022/7/11次点では割愛)
考えていたこと
使用フレームワークは?
fastAPIを選定
- djangoと比べて軽量のフレームワークであり、今回の用途だとdjangoほどの機能はいらない
- 非同期処理に対応したASGIに準拠しているため、Flaskと比べて大量のリクエストを捌ける
- OpenAPI(APIのドキュメント)を自動生成してくれるので、仕様などを共有しやすい
あたりが理由
アーキテクチャは何を採用した?
アーキテクチャはMVCを採用し、一部DDDを導入している。
-
なぜMVC?
MVCの問題点は、モデル層が肥大化し担う責務が多くなってしまうことであるが、シンプルなアプリケーションのため、肥大化することはほぼないと判断した。あと可読性が高い。そのため、MVCを採用している。 -
一部DDDとは?
一部の処理で、型プリミティブ(int,string,listなどのみの使用)で実装しまくると、バグを埋め込む可能性があった。
具体的には、「ユーザーからの入力のテキスト -> 特殊処理がされたテキスト -> テキストをトークナイザーにわたす -> 機械学習モデルにわたす」という処理にバグが入る可能性があった。特殊処理を行う前のテキストを、トークナイザーそして機械学習モデルに渡すと、推論結果がめちゃくちゃになる。しかし、アプリケーションとしてはエラーを吐かない。
そのため、機械学習処理部分は、秘密の処理がされたテキストクラスのオブジェクト以外を受け取ると、バリデーションエラーを吐くようにしている。
上記以外にも、型プリミティブで実装はせず、DDDの値オブジェクトで実装している。 -
その他アーキテクチャは検討しなかったの?
クリーンアーキテクチャでいうインフラストラクチャ層とインターフェース層の導入は、見送った。クリーンアーキテクチャのメリットは、変更が上位の層に影響しにくいこと。しかし、今回、DBを叩く処理に関しての変更はほぼ無いと判断したため。
テストやlint書いた?
テストはpytestを入れた。
lint系は、black,pyflake,isortなど。
また、型で縛るモダンなpythonの書き方をしているので、mypyなどの型チェックも行うようにした。
CI/CD組んだ?
CIも組んだ。CDはめんどくさくなってやめた。
(理由は諸事情により、サービスの継続はしないと決めたため)
DBは何にした?
DBに求める要件は、ベクトルでの近似近傍探索を行える結果を取得できること。
faissなどの近似近傍探索pythonライブラリはあるが、
- テーブルの作成やデータのインサートがAPIを通して行えない(生のPythonでしか扱えない)
- ベクトル以外の他の検索条件(完全一致、部分一致)などの拡張がしづらい
などから、Elastic Searchが良いと判断した
Elastic Searchはなぜフルマネージド版にした?
Elastic searchはフルマネージドのElastic Cloudに載せた
理由としては、
- Elasitc Searchが動いているコンテナのメモリが少ないと検索処理が失敗する
- k8sで構築する場合、複数のPodから参照できるストレージ(Persistent Volume)を考慮した上でElastic Searchを構築する必要がある。複数クラスタの場合、非常に複雑になる
- DBをマイクロサービスとして分割し、さらにGKE外に出すと、バッチによるデータのインサートなどがやりやすくなる
などの理由があり、フルマネージドのElastic Cloudにおまかせすることにした。
Discussion