【python】スクレイピングしたデータをcsvに出力する
「今日個人で使用できる陸上競技場を検索するアプリ」を作っています。
いちいちデータを調べてCSVにまとめるのが面倒だったので、スクレイピングしてきたデータをCSVに保存する処理をpythonで実装しました。
開発環境
| pip | python | chromedriver |
|---|---|---|
| 22.3 | 3.9.10 | 102.0.5005.27 |
戦略
すでに競技場情報がまとまっているサイトがあったので、以下の手順で取得しようと考えています。
- サイトをクローリング
- 競技場の名前と住所をスクレイピング
- CSVに出力
本当は使用料金や開放時間も取得したかったのですが、平日と休日で料金や開放時間が違ったりして面倒なので、今回は競技場名と住所だけにとどめておきました。(手動で書き写した方が早いのでは?)
開発環境の構築
スクレイピングに必要なライブラリをインストールしていきます。
python
Homebrewを使ってpythonをインストールしていきます。
まずは、お使いのPCでインストールできるpythonのバージョンを確認しておきましょう。
brew search python | grep "python@"
#python@3.10
#python@3.7
#python@3.8
#python@3.9
インストール
brew install python@3.9
ダウンロードできているか確認します
$ which python
/Users/subaru/.pyenv/shims/python
$ python -V
Python 3.9.10
$ which python3
/Users/subaru/.pyenv/shims/python3
$ python3 -V
Python 3.9.10
データをスクレイピングする
こちらのサイトから、競技場の名前、競技場の住所を取得したいと思います。
selenium driver, requests
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = "https://www.homemate-research-athletic-field.com/14/list/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
track_names = []
track_address_virtual = []
track_address = []
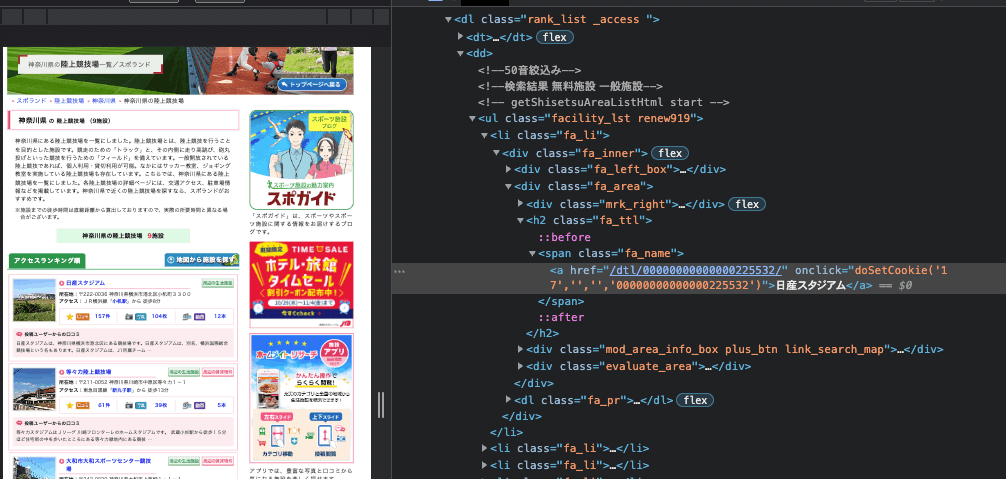
for element in soup.findAll(attrs={"class": "fa_ttl"}):
name = element.find("a")
if name not in track_names:
track_names.append(name.text)
for b in soup.findAll(attrs={"class": "fa_address"}):
name2 = b.contents[3]
track_address_virtual.append(name2.text.strip("\t/\n"))
track_address_length = len(track_address_virtual)
for i in range(0, track_address_length):
if i % 2 == 0:
track_address.append(track_address_virtual[i])
prefecture = ["kanagawa"] * len(track_address)
df = pd.DataFrame(
{"Names": track_names, "Address": track_address, "Prefecture": prefecture}
)
df.to_csv("./csvs/kanagawa_tracks.csv", index=False, encoding="utf-8")
import requests
import pandas as pd
from bs4 import BeautifulSoup
クローリングしてスクレイピングするためのライブラリをimportしています。
ちなみに、クローリングは「巡回して情報を取得」、スクレイピングは「情報を抽出する」という意味があるそうです。
スクレイピングとクローリングの違いとは?コードで解説(Python) - Workship MAGAZINE(ワークシップマガジン)
スクレイピングでよく使われるBeautifulSoup、クローリングではchromedriverとrequestsを使用しています。
pipを使ってダウンロードしておきましょう。すぐできます。
python3 get-pip.py
pipをダウンロード
pip install pandas
pip install beautifulsoup4
pandas requests beautifulsoup4をダウンロード
データ取得
url = "https://www.homemate-research-athletic-field.com/14/list/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
データを取得しています。
データ取得先のurlを指定
リクエストを実行
取得したJSONデータに含まれるhtmlテキストを、BeautifulSoupで掬い取ります。
スクレイピング
track_names = []
track_address_virtual = []
track_address = []
for element in soup.findAll(attrs={"class": "fa_ttl"}):
name = element.find("a")
if name not in track_names:
track_names.append(name.text)
for b in soup.findAll(attrs={"class": "fa_address"}):
name2 = b.contents[3]
track_address_virtual.append(name2.text.strip("\t/\n"))
track_address_length = len(track_address_virtual)
for i in range(0, track_address_length):
if i % 2 == 0:
track_address.append(track_address_virtual[i])
BeautifulSoupが用意しているメソッドを用いて先ほど取得したHTMLの中から欲しい情報を取得しています。
findAll,findを使っています。もちろん多くのメソッドが用意されているので、気になった方は下記サイトをご覧ください。
【Python入門】BeautifulSoupの使い方を極める|HTML操作の基本
今回は競技場の名前と住所だけが欲しいので、以下の条件をパスする要素を抽出しています。
- 「指定したclass名を持つ要素を全て探し、ネストされている、aタグの中にあるテキスト」
- 「指定したclass名を持つ要素を全て探し、含まれているHTMLから改行コードを取り去ったテキスト」
例えばこちらはfa_ttlというクラス名をを持つ要素を指定する処理になります。
for element in soup.findAll(attrs={"class": "fa_ttl"}):
prefecture = ["kanagawa"] * len(track_address)
都道府県名を要素数分用意しています。自作しているアプリで県名が入るカラムを用意しているので、この処理を走らせています。
データフォーマッティング
df = pd.DataFrame(
{"Names": track_names, "Address": track_address, "Prefecture": prefecture}
)
先ほどインストールしたpandasを使って、競技場名、競技場の住所名、都道府県名をもつオブジェクトを作成します。
DataFrameというメソッドを使うと、key-vlaue型のオブジェクトが作成でき、今回のように使うと下記のようなオブジェクトを作成できます。
Names Address Prefecture
0 日産スタジアム 〒222-0036 神奈川県横浜市港北区小机町3300 kanagawa
1 等々力陸上競技場 〒211-0052 神奈川県川崎市中原区等々力1-1 kanagawa
2 大和市大和スポーツセンター競技場 〒242-0029 神奈川県大和市上草柳1-1-1 kanagawa
3 厚木市荻野運動公園陸上競技場 〒243-0202 神奈川県厚木市中荻野1500 kanagawa
4 レモンガススタジアム平塚 〒254-0074 神奈川県平塚市大原1-1 kanagawa
5 三増公園陸上競技場 〒243-0308 神奈川県愛甲郡愛川町三増1886 kanagawa
6 神奈川県立体育センター陸上競技場 〒251-0871 神奈川県藤沢市善行7-1-2 kanagawa
7 海老名運動公園陸上競技場 〒243-0424 神奈川県海老名市社家4032-1 kanagawa
8 城山陸上競技場 〒250-0045 神奈川県小田原市城山2丁目29-1 kanagawa
df['Names']のように書くと、Name列の値を全て取得できます。エクセルみたいですね。
0 日産スタジアム
1 等々力陸上競技場
2 大和市大和スポーツセンター競技場
3 厚木市荻野運動公園陸上競技場
4 レモンガススタジアム平塚
5 三増公園陸上競技場
6 神奈川県立体育センター陸上競技場
7 海老名運動公園陸上競技場
8 城山陸上競技場
CSV出力
df.to_csv("./csvs/kanagawa_tracks.csv", index=False, encoding="utf-8")
DataFrameで作成したデータをcsvに出力しています。複数の引数を指定することができます。
出力先のファイル名、indexの有無、文字コードを指定しました。
これで、kanagawa.py(今回作成したソースコードが書かれたファイル名)を実行してみると、csv/kanagawa.pyが出力されます。
$ python kanagawa.py
Names,Address,Prefecture
日産スタジアム,〒222-0036 神奈川県横浜市港北区小机町3300,kanagawa
等々力陸上競技場,〒211-0052 神奈川県川崎市中原区等々力1-1,kanagawa
大和市大和スポーツセンター競技場,〒242-0029 神奈川県大和市上草柳1-1-1,kanagawa
厚木市荻野運動公園陸上競技場,〒243-0202 神奈川県厚木市中荻野1500,kanagawa
レモンガススタジアム平塚,〒254-0074 神奈川県平塚市大原1-1,kanagawa
三増公園陸上競技場,〒243-0308 神奈川県愛甲郡愛川町三増1886,kanagawa
神奈川県立体育センター陸上競技場,〒251-0871 神奈川県藤沢市善行7-1-2,kanagawa
海老名運動公園陸上競技場,〒243-0424 神奈川県海老名市社家4032-1,kanagawa
城山陸上競技場,〒250-0045 神奈川県小田原市城山2丁目29-1,kanagawa
次回はcsvからgoogle spreadsheetへ出力するスクリプトを書いていきたいと思います。
Discussion