モニタリングとアラートシステムの解剖メモ ~ ゴリラに恋して ~
はじめに
システム監視の技術要素について個人的な理解を深めるためのメモ。
大規模分散システムにおけるメトリクス収集から可視化、アラート発行までの各コンポーネントの技術的特性を整理する。
モニタリングシステムのアーキテクチャコンポーネント
基本コンポーネント構成

https://www.statcan.gc.ca/en/data-science/network/monitoring-alerting-system
モニタリングシステムを構成する主要コンポーネントとその技術特性を整理する。各コンポーネントには複数の技術選択肢があり、要件に応じた適組み合わせが選択される。
| コンポーネント | 技術的役割 | 主要実装技術 | 技術的考慮点 |
|---|---|---|---|
| メトリクス生成元 | 計測値生成 | ・カーネルメトリクス ・インストルメンテーション |
・オーバーヘッド ・粒度 ・網羅性 |
| メトリクス収集 | 取得・正規化・転送 | ・Prometheus Exporters ・Telegraf ・OpenTelemetry Collectors |
・Pull/Push方式 ・認証・暗号化 ・フィルタリング |
| データバッファリング | 一時保存と耐障害性 | ・Kafka ・RabbitMQ ・Redis Streams |
・永続性 ・スループット ・パーティション戦略 |
| 時系列DB | 時系列データ 保存・検索 |
・Prometheus ・InfluxDB ・TimescaleDB ・VictoriaMetrics |
・圧縮率 ・クエリ性能 ・保持期間 ・シャーディング |
| 可視化 アラート基盤 |
データの可視化 異常検知 |
・Grafana ・Alertmanager ・PagerDuty |
・ダッシュボード設計 ・アラートルール ・通知経路 |
メトリクス生成元の実装形態は多様であり、技術的に最も基本的なのはOSカーネル由来のシステムメトリクス(CPU、メモリ、ディスク、ネットワーク)である。一方でアプリケーションレベルのインストルメンテーションは、ライブラリ(Micrometer、Prometheus Client、StatsD)を用いて実装される。また一部のミドルウェア(データベース、メッセージブローカー)は専用のエクスポーターを通じてメトリクスを提供する。技術実装上の重要ポイントは、計測によるパフォーマンス低下を最小限に抑えつつ、適切な粒度でのデータ収集を実現することである。
メトリクス収集技術にはプロセスベース(node_exporter等)、サイドカーコンテナ、エージェントレス(SNMP、JMX等)など多様なアプローチがある。技術的特性としては、エンドポイント認証機能、TLS通信対応、メトリクスフィルタリング機能、メタデータ拡張機能などが重要となる。また大規模環境では分散配置による負荷分散や階層化構成も検討すべき技術要素である。
データフローと処理パイプライン
| 通信区間 | 主要プロトコル | 技術的特性 | 最適化ポイント |
|---|---|---|---|
| 生成元→収集エージェント | ・HTTP ・TCP ・UDP ・Unix Socket(local) |
短期接続(Pull)または持続接続(Push) | ・コネクション管理 ・タイムアウト設定 |
| 収集エージェント→キュー | ・HTTPS ・AMQP ・Kafka Protocol |
メッセージフォーマット、認証 | ・バッチサイズ ・圧縮設定 ・再試行ポリシー |
| キュー→TSDBライター | ・キュー依存プロトコル 例:Kafka, AMQP |
パーティション割り当て、オフセット管理 | ・コンシューマグループ設計 ・バッチ処理 |
| TSDBライター→TSDB | ・HTTP API ・専用プロトコル |
書き込みバッファリング、並列接続 | ・接続プール ・再試行戦略 ・書き込みバッチ化 |
| クエリエンジン->TSDB | ・SQL ・PromQL ・FluxQL |
クエリ最適化、並列実行 | ・クエリキャッシュ ・部分スキャン最適化 |
| 可視化->クエリエンジン | ・HTTP/JSON ・WebSocket |
増分更新、圧縮 | ・データダウンサンプリング ・キャッシング |
| アラートエンジン→通知 | ・SMTP ・HTTP Webhook ・SMS API |
配信確認、フォールバック | ・再試行ポリシー ・優先順位付け |
データ変換・エンリッチメント処理も重要な技術要素である。生のメトリクスデータには、変換(単位変換、正規化)、エンリッチメント(メタデータ付加、タグ付け)、アグリゲーション(事前集計、ダウンサンプリング)などの処理が適用される。技術的には、これらの処理をどのコンポーネントで実行するかが重要な設計判断となる。例えば、収集エージェントで実行すると転送データ量削減になるが、エージェント負荷が増加する。一方、中央処理すれば柔軟な変更が可能だが、中央サーバーの処理負荷が高まる。
耐障害性を考慮したデータフロー設計では、以下の技術的アプローチが検討される。
| 耐障害技術 | 実装メカニズム | 適用コンポーネント |
|---|---|---|
| ローカルバッファリング | ・ディスクベースのキュー ・WAL |
・収集エージェント ・TSDBライター |
| 冗長パス | ・マルチパス送信 ・レプリケーション |
・キューイングレイヤー ・TSDB |
| 再試行ロジック | ・指数バックオフ ・ジッター付き再試行 |
・すべての通信経路 |
| サーキットブレーカー | ・障害検出と自動切り離し | ・クライアント-サーバー間通信 |
| ヘルスチェック | ・アクティブ/パッシブプローブ | ・全コンポーネント |
メトリクス収集アーキテクチャ
Pull方式 と Push方式
メトリクス収集の基本アプローチとしてPull型とPush型があり、それぞれに固有の技術的特性と内部メカニズムがある。

https://www.alibabacloud.com/blog/pull-or-push-how-to-select-monitoring-systems_599007
Pull方式(Prometheus型)の内部動作メカニズムは以下のように構成される。
| 技術要素 | 実装メカニズム | 詳細 |
|---|---|---|
| サービスディスカバリ | ・ファイルベース ・DNS ・API連携 |
ターゲットリストの動的更新と管理 |
| スクレイプ処理 | ・並列HTTP(S)クライアント | 設定されたインターバルでのポーリング実行 |
| レスポンス解析 | ・テキストパーサ ・プロトコルバッファパーサ |
OpenMetrics/Prometheusフォーマット解析 |
| メトリクス系列保持 | ・インメモリデータ構造 ・ラベルインデックス |
ラベルごとのユニーク系列管理 |
| 一時的障害対応 | ・タイムアウト ・再試行メカニズム |
一定回数の再試行後に失敗とマーク |
| リレーショナル設定 | ・ターゲットのグループ化 ・ジョブ概念 |
論理的なメトリクス構造化 |
Pull方式の内部処理フローを詳細に見ると、各スクレイプサイクルでのHTTPリクエスト発行、レスポンスのパース、タイムスタンプ付与、ラベル正規化、メモリ内時系列の更新というステップが実行される。特に重要な技術的最適化ポイントとして、メトリクスの差分処理(前回と変わらない値の効率的な処理)、レスポンス圧縮(gzip)対応、接続プーリングによるTCP接続再利用などがある。
Push方式(InfluxDB/Graphite型)の実装詳細は以下の通り。
| 技術要素 | 実装メカニズム | 詳細 |
|---|---|---|
| 送信プロトコル | ・HTTP(S) POST ・TCP/UDP |
単発送信と持続接続の選択 |
| データフォーマット | ・LineProtocol ・JSON ・Protocol Buffers |
シリアライズ効率とパース負荷 |
| バッファリング | ・メモリ内バッファ ・ディスクスプール |
送信失敗時のローカル保持機能 |
| バッチ処理 | ・時間/サイズベースのバッチング | ネットワーク効率とレイテンシのバランス |
| 再試行ロジック | ・バックオフ ・優先度付け |
送信失敗時の処理制御 |
| ロードバランシング | ・クライアントサイドシャーディング | 複数受信端点への分散送信 |
Push方式の内部処理フローでは、メトリクス生成、メモリバッファへの追加、バッチアセンブリ、シリアライズ、送信、確認応答処理というステップが実行される。技術的に重要な最適化ポイントとしては、送信頻度とバッチサイズの調整(小さすぎると効率低下、大きすぎるとメモリ消費増)、非同期送信による処理ブロッキング回避、送信失敗時の指数バックオフによるサーバー保護などがある。
収集エージェント
収集エージェントには主にエージェント型、サイドカー型、eBPF型の実装パターンがある。
エージェント型実装の技術要素は次の通り。
| 技術要素 | 実装詳細 | 考慮点 |
|---|---|---|
| 権限管理 | ・特権 ・非特権実行モード |
・root権限必要性 ・最小権限原則 |
| リソース使用量 | ・CPU,メモリ制限 ・I/O最適化 |
・オーバーヘッド管理 ・優先度設定 |
| 分離性 | ・プロセス分離 ・コンテナ分離 |
・障害波及防止 ・セキュリティ境界 |
| 自動更新 | ・パッケージマネージャ連携 ・セルフアップデート |
・継続的デプロイメント |
| 設定管理 | ・ファイルベース ・API経由 ・動的再構成 |
・大規模環境での設定一貫性確保 |
エージェント型では、OS固有インターフェース(Linux:procfs/sysfs、Windows:WMI/PerformanceCounters)を通じたデータ収集が中心となる。特に権限レベルの設計は重要な技術判断であり、例えばLinuxのcapabilities機能を活用して必要最小限の権限に制限する実装が安全性確保に寄与する。また、エージェントの分離性確保のために、一部の監視機能をプラグインとして分離実装し、メインプロセスの安定性を高める手法も採用される。
次に、サイドカー型実装の技術要素は次のように整理できる。
| 技術要素 | 実装詳細 | 考慮点 |
|---|---|---|
| コンテナ連携 | ・共有ボリューム ・ネットワーク名前空間 |
・Pod内通信 ・データ共有メカニズム |
| 自動インストルメンテーション | ・サイドカー自動注入 | ・アプリケーションコード非変更での監視導入 |
| 設定注入 | ・ConfigMap ・Secret ・環境変数 |
・動的設定更新 ・シークレット管理 |
| リソース制約 | ・CPU/メモリ制限 ・QoS設定 |
・アプリケーションとの資源競合回避 |
| ライフサイクル管理 | ・Init Container ・Readiness/Liveness Probe |
・初期化順序 ・障害検出 |
サイドカー型の典型的な実装例としては、Kubernetes Podにおける監視サイドカーコンテナがある。技術的には、メインアプリケーションコンテナとサイドカーコンテナ間の通信方式が重要な設計ポイントである。localhost経由のHTTP通信、共有ボリュームを介したファイル読み取り、Unixソケット通信などの選択肢があり、それぞれにパフォーマンスとセキュリティのトレードオフがある。
最後に、eBPF型監視の技術要素を以下に整理する。
| 技術要素 | 実装詳細 | 考慮点 |
|---|---|---|
| カーネルフック | ・kprobes ・uprobes ・tracepoints |
・カーネルバージョン依存性 ・安定性 |
| 安全性検証 | ・JITコンパイル ・検証器 |
・カーネル保護 ・バグ回避 |
| パフォーマンス計測 | ・レイテンシプロファイリング ・I/O追跡 |
・オーバーヘッド最小化 ・詳細度 |
| データ集約 | ・BPFマップ ・ユーザー空間転送 |
・メモリ効率 ・転送頻度 |
| フィルタリング | ・カーネル内選別 ・イベント絞り込み |
・情報損失と精度のバランス |
eBPF技術の特徴は、カーネルレベルでの透過的な監視が可能なことである。従来のエージェントやサイドカーが必要とする明示的なインストルメンテーションなしに、システムコール、ネットワークパケット、ファイルI/O、メモリアクセスなどを詳細に監視できる。また、カーネル空間で動作するため、パフォーマンスオーバーヘッドも最小限に抑えられる。ただし、観測内容やプログラムによってはCPU負荷が増大する場合もある。
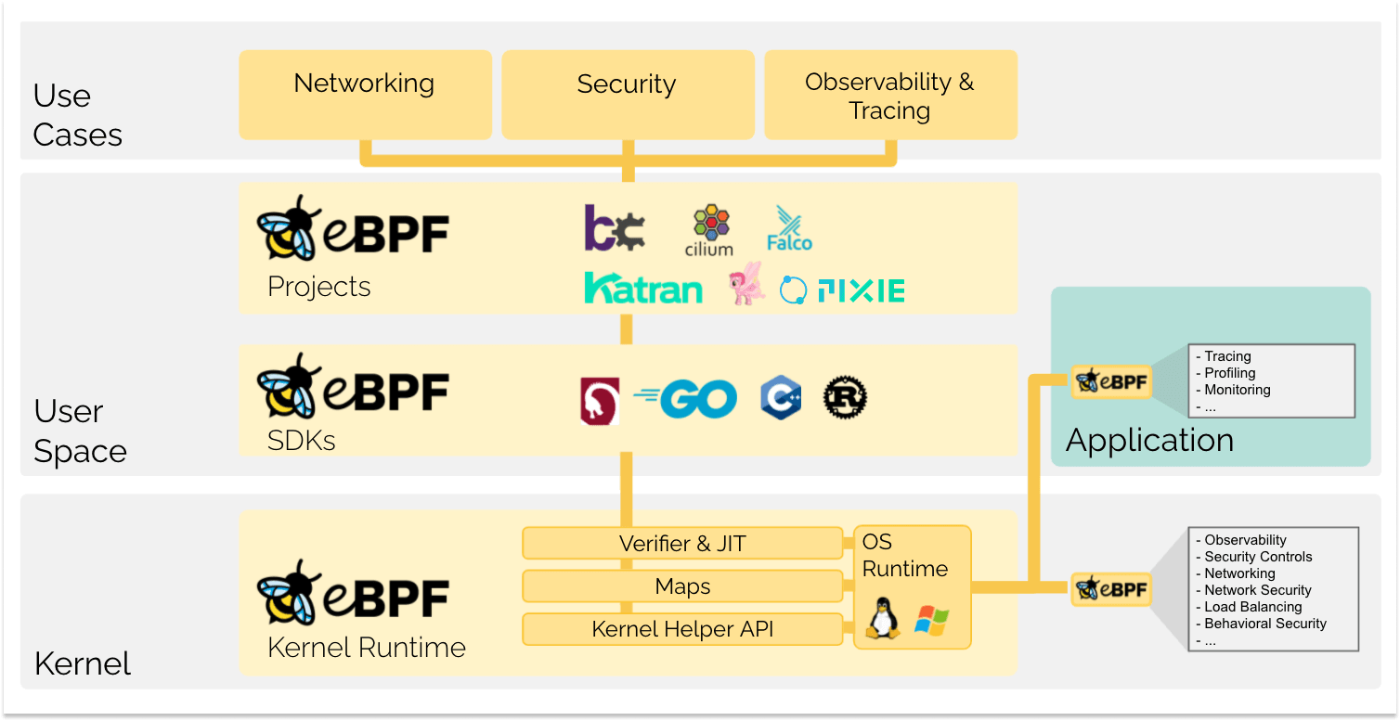
eBPF監視の実装例としては、Cilium Hubble(ネットワークモニタリング)、Pixie(アプリケーション監視)、Falco(セキュリティモニタリング)などがある。これらはeBPFプログラムをカーネルに挿入し、特定のイベントをトレースしてユーザー空間に集約するアーキテクチャを採用している。
メトリクスデータモデル
メトリクスデータモデルの設計において、カーディナリティ管理(ラベル, タグ設計)は重要な考慮事項である。
| 技術要素 | 最適化アプローチ | 実装テクニック |
|---|---|---|
| ラベル設計 | 高基数ラベルの制限 | 文字列ID→数値ID変換、階層化 |
| 命名規則 | 標準化と一貫性確保 | 命名ルール強制、検証ツール |
| ラベル統合 | 複合ラベルの分離/結合 | ラベルマージ、分離パターン |
| 動的ラベル管理 | 変更頻度の高いラベルの隔離 | 分離されたメタデータストア |
| レートリミット | カーディナリティ爆発防止 | 新規系列生成制限、サンプリング |
具体的な考慮事項として、高カーディナリティのラベルはTSDBのパフォーマンスを著しく低下させる。例えば、ユーザーIDやリクエストIDのような一意性の高い値をラベルとして使用すると、系列数が爆発的に増加し、インデックスのメモリ消費やルックアップ性能が悪化する。このような問題に対しては、高基数値のハッシュ化、バケット化(範囲グループ化)、サンプリングなどの技術的対策が有効である。
Prometheusデータモデルにおけるラベル設計の例
# 不適切な設計(高カーディナリティ)
http_requests_total{path="/api/user/12345", method="GET", status="200", user_id="789012"}
# 最適化された設計
http_requests_total{path="/api/user/:id", method="GET", status="2xx"}
user_requests{user_type="premium"} # ユーザー固有メトリクスは分離
また、サンプリング頻度と精度はトレードオフ関係にある。
| サンプリング戦略 | 技術的実装 | トレードオフ |
|---|---|---|
| 固定間隔サンプリング | 一定時間間隔での収集 | 単純だが一時的なスパイクを見逃す可能性 |
| 適応的サンプリング | 変動に応じた頻度調整 | 変化検出と効率性のバランス |
| 統計的サンプリング | ランダム選択による標本収集 | 大量データの効率的表現、精度低下 |
サンプリング頻度設定は単純なようで実は難しい。例えば、CPUやメモリのような基本メトリクスは15秒から1分間隔が一般的だが、高速な変動を示すキューの長さやリクエストレートなどは数秒間隔でのサンプリングが望ましい。一方で長期傾向分析用のデータは、ダウンサンプリング(例:5分、1時間平均)による精度低下と引き換えに長期保存が可能になる。ストレージ料金は馬鹿にならない。
最後に、データ圧縮処理とネットワーク最適化手法について触れる。
| 最適化技術 | 実装方法 | 効果 |
|---|---|---|
| バイナリプロトコル | Protocol Buffers、Avro | テキスト形式より効率的なシリアライズ |
| 差分エンコード | 前回値からの差分のみ送信 | 反復データの圧縮 |
| ランレングスエンコード | 連続同一値の圧縮 | 変化の少ないデータの効率化 |
| 一括送信最適化 | バッチサイズとタイミング調整 | ネットワークオーバーヘッド削減 |
| 帯域幅管理 | 転送レート制限、優先順位付け | ネットワーク輻輳対策 |
特に大規模環境では、メトリクスデータの転送量が膨大になるため、データモデルの設計だけでなく、効率的な転送プロトコルの選択も重要である。例えばPrometheus remote_writeでは圧縮率の高いSnappyと組み合わせたProtocol Buffersベースのバイナリエンコードを使用している。
キューイングシステムによるデータ損失防止
キューイングレイヤーの必要性
キューイングレイヤーは大規模モニタリングシステムにおける信頼性とスケーラビリティを確保するための技術コンポーネントである。TSDB障害・過負荷時のデータ保護メカニズムとしての価値は以下の通り。
| 技術課題 | キューイングによる解決 | 実装メカニズム |
|---|---|---|
| TSDB障害時のデータ消失 | 一時保存と再送機能 | 永続化メッセージ、デリバリ保証 |
| 一時的負荷増大 | 負荷平準化 | 受信バッファリング、バックプレッシャー |
| メンテナンス中の継続収集 | 運用継続性保証 | オフライン処理、非同期再接続 |
| 処理遅延のバッファ | 非同期による遅延許容 | 非同期コンシューマー、優先度制御 |
TSDBは一般的にスケールアウトが複雑なコンポーネントであり、書き込み容量には物理的な限界がある。キューイングレイヤーはこの限界を超えるバースト負荷からTSDBを保護する緩衝材として機能する。例えば、大規模なデプロイメントやシステム再起動時には、多数のサービスが同時にメトリクスを送信し始め、TSDB書き込み容量を一時的に超過する可能性があるが、キューイングレイヤーがこの負荷を吸収し、一定レートでTSDBに書き込むことで安定した処理が可能になる。
バッファリングによるスパイク対応と書き込み平準化の具体的なメカニズムは以下の通り。
| バッファリング技術 | 実装詳細 | 効果 |
|---|---|---|
| メモリバッファ | リングバッファ、優先度キュー | 短期的なスパイク吸収 |
| ディスクキュー | WAL、順次ファイル、LSM | 大容量バッファ、耐障害性 |
| 分散キュー | マルチノードレプリケーション | スケーラブルなバッファ容量 |
| レートリミット | トークンバケット、リーキーバケット | 書き込み速度制御 |
例えばKafkaを使用したバッファリング実装では、Topic内のパーティションをメトリクス種別やテナントごとに分割し、それぞれに独立したコンシューマーグループを割り当てることで、並列処理と負荷分散を実現できる。また、レートリミットによって、下流のTSDBに対する書き込み負荷を調整することが可能になる。
収集層とストレージ層の分離によるアーキテクチャメリットは、技術的な障害分離だけでなく、独立したスケーリングや更新も可能にする。
| アーキテクチャメリット | 技術的実現方法 | 効果 |
|---|---|---|
| 独立スケーリング | コンポーネント別の水平スケール | リソース効率の最適化 |
| フェイルオーバー | アクティブ-アクティブ構成 | 単一障害点の排除 |
| ローリングアップデート | 順次更新、カナリアデプロイ | ダウンタイムなしの更新 |
| マルチTSDBサポート | ディスパッチャー実装 | 複数バックエンド同時書き込み |
メッセージングシステム技術選定
主要なメッセージングシステムの技術比較は以下の通り。
| 特性 | Apache Kafka | RabbitMQ | Redis Streams | クラウドサービス |
|---|---|---|---|---|
| メッセージモデル | ・永続ログ ・パーティション |
・交換-キュー ・ルーティング |
時系列追加型リスト | サービス固有 |
| スループット | 非常に高い | 中〜高 | 高い | サービスレベルによる |
| レイテンシ | 低〜中 | 低 | 非常に低 | サービスによる変動 |
| 耐久性保証 | ・レプリケーション ・ACK設定 |
・キュー持続化 ・レプリケーション |
・AOF/RDB(Redis全体の永続化機能) ・レプリケーション |
マネージドレプリケーション |
| スケーラビリティ | 水平拡張性高 | クラスタモードで中程度 | クラスタモードで中程度 | 自動スケーリング(制限あり) |
| 運用複雑性 | 中〜高 | 中 | 低 | 最小(マネージド) |
メトリクスデータは一般的に高頻度(数秒〜分単位)で生成され、順序性よりもスループットが重視される傾向がある。また、個々のメッセージサイズは比較的小さいが、総量は膨大になる場合が多い。これらの特性から、特に大規模環境ではApache Kafkaが技術的な優位性を持つことが多い。
Kafkaの技術的優位点は以下の通り。
- パーティション機能による並列処理と水平スケーラビリティ
- 高スループット対応(数百万メッセージ/秒を実現可能)
- ディスクベース設計による大容量バッファ(数日〜週間のリテンション)
- ブローカー障害耐性(レプリケーションファクターによる制御)
- コンシューマーグループ機能によるロードバランシング
一方、RabbitMQの技術的優位点としては以下が挙げられる。
- 柔軟なルーティング機能(トピック、ヘッダー、パターンベース)
- 複雑なメッセージングパターン対応(RPC、発行-購読、ワークキュー)
- 優先度キューやTTL(有効期限)等の細かい制御機能
- より低いレイテンシ(特に低〜中程度のスループット環境)
Redis Streamsは比較的新しい技術で、以下のような特徴がある。
- 極めて低いレイテンシ(インメモリベース)
- 簡易設定と運用の容易さ
- 時系列指向のデータモデル(メトリクスデータとの相性)
- 既存Redis環境への統合容易性
クラウドネイティブキューイングサービスについても軽く触れる。
| クラウドサービス | 技術的特徴 | 制約事項 |
|---|---|---|
| AWS Kinesis | ・シャードベース設計 ・順序保証 |
・シャード数制限 ・スケーリング遅延 |
| Google Pub/Sub | ・グローバル分散 ・自動スケーリング |
・デフォルトではメッセージ順序保証なし ・レイテンシ変動 |
| Azure Event Hubs | ・Kafkaプロトコル互換 ・キャプチャ機能 |
・スループット単位制限 ・保持期間制約 |
| AWS SQS | ・シンプルな非同期キュー | ・スループット制限 ・Standardキュー: 順序保証なし ・FIFOキュー: あり |
クラウドサービスの選択においては、課金モデルとスケーリング特性について理解しておく必要がある。例えばKinesisは事前プロビジョニングモデルであるため、トラフィックパターンが予測可能な場合は効率的だが、急激な負荷変動には対応しにくい。一方、Pub/Subは完全自動スケーリングだが、高負荷時のコスト予測が難しい面がある。
実装パターンと設定最適化
キューイングシステムを効果的に実装するためには、適切な配信保証レベルの選択が重要である。
| 配信保証レベル | 技術的実装 | 適用シナリオ |
|---|---|---|
| at-most-once | ・非確認送信 ・タイムアウト破棄 |
・一部データ損失許容 ・最大スループット要求 |
| at-least-once | ・ACK必須 ・再送メカニズム |
・標準的なメトリクス収集(重複許容) |
| exactly-once | ・トランザクション ・冪等性ID |
・課金データ ・重複不可メトリクス |
メトリクスデータの多くは集計操作(平均、合計、最大など)を適用するため、重複データが結果に大きな影響を与えないことが多い。そのため、多くの実装ではパフォーマンス優先でat-least-once保証を採用することが一般的である。
また、パーティショニング戦略とスケーリング手法も重要な技術選択である。
| パーティション戦略 | 技術的実装 | 利点と欠点 |
|---|---|---|
| メトリクス名ベース | メトリクス名のハッシュ | ・関連メトリクスのローカリティ ・不均衡リスク |
| テナントベース | テナントIDによる分割 | ・マルチテナント分離 ・テナント間不均衡 |
| ラウンドロビン | 循環割り当て | ・均等分散 ・ローカリティなし |
| 固定シャード | 静的シャード割り当て | ・予測可能性 ・拡張困難 |
| 動的シャード | 負荷に応じた再分配 | ・適応性 ・オーバーヘッド増加 |
障害発生時の信頼性確保のため、リカバリメカニズムについて理解しておくことも重要である。
| リカバリ機能 | 技術実装 | 効果 |
|---|---|---|
| オフセット管理 | コミット制御、チェックポイント | 再起動時の継続位置保証 |
| デッドレターキュー | 処理失敗メッセージの分離 | 問題データの隔離と分析 |
| リプレイ機能 | 保存メッセージの再処理 | データ復旧、テスト、移行 |
| スナップショット | 特定時点の状態保存 | 一貫性のある復元ポイント |
最後に、バッチ処理とバッファサイズの最適化技術もパフォーマンスに直接影響する。
| 最適化技術 | 実装方法 | パフォーマンス影響 |
|---|---|---|
| バッチサイズ調整 | メッセージ数、サイズベース制限 | スループットとレイテンシのバランス |
| バッチ時間調整 | 最大待機時間設定 | 完全バッチとタイムリー処理のバランス |
| プリフェッチ | 先行読み取りバッファ設定 | 処理効率向上、メモリ増加 |
| 並列処理 | コンシューマースレッドプール | CPU利用効率、順序保証との競合 |
時系列データベース(TSDB)アーキテクチャ
主要TSDB内部設計の技術比較
時系列データベースの内部設計は、大規模メトリクスの効率的な格納と検索のために最適化されている。主要TSDBの内部構造と最適化機構の技術的特徴を比較する。
Prometheus TSDBの内部構造は次の通り。
| 技術コンポーネント | 実装詳細 | 最適化メカニズム |
|---|---|---|
| ブロックストレージ | ・2時間単位のチャンク構成 | ・時間分割による検索効率向上 |
| Write-Ahead Log | ・ディスクベースのトランザクションログ | ・クラッシュ耐性 ・データ復旧 |
| メモリインデックス | ・シリーズ識別子とラベルのインメモリマップ | ・高速ルックアップ ・トレードオフはメモリ消費 |
| ゴリラ圧縮 | ・XOR差分エンコーディング | ・高効率時系列データ圧縮 |
| チャンク管理 | ・固定サイズチャンク ・圧縮アルゴリズム |
・I/O効率 ・キャッシュヒット率最適化 |
| コンパクション | ・バックグラウンドブロック統合 | ・ディスク使用効率化 ・クエリパフォーマンス向上 |
Prometheus TSDBでは、メトリクスデータは一時的にメモリ内のヘッドブロックに書き込まれた後、デフォルトでは2時間単位(ただし設定により変更可能)でディスク上の不変ブロックにコンパクションされる。これにより、時間範囲クエリの効率化と古いデータの効率的な管理が実現されている。
Prometheus TSDBの技術的な制約としては、基本的に単一ノード設計であり、フェデレーション機能を備えてはいるものの、水平スケーラビリティには限界がある。ただし、ThanosやCortex/Mimirなどの分散拡張プロジェクトを利用することで、水平スケールや長期保存が可能となる。また、高カーディナリティラベルに対するパフォーマンス低下が挙げられる。特に後者のカーディナリティ問題は、数百万〜数千万の時系列を扱うと顕著になる。
InfluxDB, TimescaleDB, VictoriaMetricsの技術アーキテクチャ比較は次の通り。
| TSDB | ストレージエンジン | インデックス | クエリ最適化 | 分散アーキテクチャ |
|---|---|---|---|---|
| InfluxDB | TSMツリー | ・インメモリタグインデックス+TSI | ・時間ベースパーティショニング ・フィールド分離 |
Enterprise(1.x系)版のみシャード+レプリカ |
| TimescaleDB | ハイパーテーブル (PostgreSQL拡張) |
・B-ツリーインデックス ・部分インデックス |
・チャンク除外 ・パラレルクエリ |
・シングルノード(Community版) ・マルチノードクラスタ(Enterprise v2.0+) |
| VictoriaMetrics | 独自エンジン | ・独自インデックス ・(メモリ効率重視) |
・インデックススキャン最適化 ・ベクトル化(SIMD) |
ネイティブクラスタリング |
InfluxDBは、LSM(Log-Structured Merge Tree)から派生したTSM(Time-Structured Merge Tree)ファイルフォーマットを採用している。このアーキテクチャでは、インメモリキャッシュに最初にデータが書き込まれ、一定のしきい値に達するとディスク上のTSMファイルに永続化される。TSMファイルは不変であり、バックグラウンドプロセスによって定期的に圧縮される。タグによるデータの高速フィルタリングのために、専用のインデックス構造が使用される。
TimescaleDBは、PostgreSQLの拡張として実装されており、「ハイパーテーブル」という抽象化を通じて時系列データを管理する。ハイパーテーブルは内部的に「チャンク」と呼ばれる小さなテーブルに分割され、各チャンクは特定の時間範囲のデータを格納する。この構造により、時間範囲クエリの効率が向上し、古いデータのアーカイブや削除が容易になる。また、PostgreSQLの豊富なインデックス機能(B-tree、GiST、GIN等)をそのまま活用できる。
VictoriaMetricsは、Prometheusとの互換性を持ちながら、独自の高効率ストレージエンジンを実装したTSDBである。特筆すべきは、メモリ効率の高いインデックス設計により、メモリ使用量を大幅に削減している点である。
また、書き込み/読み取りパス最適化も重要な技術要素である。
| 最適化対象 | 技術的アプローチ | 実装例 |
|---|---|---|
| 書き込みパス | ・WAL ・バッチ処理 ・非同期コミット |
Prometheusの2段階書き込み(メモリ→ディスク) |
| 読み取りパス | ・キャッシュ ・クエリ並列化 ・SIMD命令 |
VictoriaMetricsのチャンクデコードSIMD最適化 |
| インデックス | ・メモリマップ ・ブルームフィルター |
InfluxDBのTSIインデックス階層化 |
| 圧縮処理 | ・差分エンコード ・ディクショナリ圧縮 |
TimeScaleDBのネイティブ圧縮 |
ストレージと圧縮アルゴリズム
ストレージコストは、特に大規模環境においてはかさみがちである。主要な圧縮技術の比較は以下の通り。
| 圧縮技術 | アルゴリズム原理 | 圧縮率 | パフォーマンス特性 |
|---|---|---|---|
| ゴリラ圧縮 | ・XOR差分 ・繰り返しビットパターン最適化 |
約10:1 | ・デコード高速 ・繰り返しパターンに強い |
| デルタエンコーディング | 連続値の差分シリアライズ | 変動(約3:1〜5:1) | ・エンコード簡易 ・デコード時順次処理 |
| ディクショナリ圧縮 | 値→索引マッピング | 限られた値種での高圧縮 | ・ルックアップコスト ・メモリオーバーヘッド |
| スナップショット+デルタ | 基準点+差分保存 | 中〜高(変動による) | ・ランダムアクセス支援 ・復元処理複雑化 |
| ランレングスエンコード | 連続同値のカウント圧縮 | 変化少ないデータで高効率 | ・頻繁な変化で効率低下 ・実装単純 |
特にゴリラ圧縮(Facebook由来の時系列圧縮アルゴリズム)は、Prometheusを含む多くのTSDBに影響を与えている。このアルゴリズムは時系列データの特性(連続するタイムスタンプの規則性や、値の小さな変動)を活用して高効率な圧縮を実現する。

https://www.vldb.org/pvldb/vol8/p1816-teller.pdf
具体的には、以下の2つの主要最適化を行う。
- タイムスタンプ圧縮
連続するタイムスタンプの差分(デルタ)を保存。さらに連続するデルタ値間の差分(デルタ-オブ-デルタ)がゼロまたは小さい値である傾向を利用。 - 値の圧縮
連続する値のXOR結果を保存。多くの場合、値の変化は小さいため、XOR結果は多くのリーディングゼロとトレーリングゼロを含む。これらのゼロを効率的にエンコード。
また、チャンク化とダウンサンプリングの実装技術も長期保存と高速クエリのバランスに重要である。
| 技術要素 | 実装方法 | 効果 |
|---|---|---|
| チャンク分割戦略 | ・時間範囲 ・サイズベース分割 |
・クエリ効率 ・書き込み効率のバランス |
| チャンク圧縮 | ・個別/集約圧縮 ・可逆/非可逆 |
ストレージ効率と検索効率のバランス |
| ダウンサンプリング | ・自動/手動集約 ・保持ポリシー |
・長期データの圧縮保存 ・傾向分析 |
| 統計的要約 | ・プリアグリゲーション ・ヒストグラム |
・高速傾向分析 ・精度と容量のバランス |
特に大規模環境では、ダウンサンプリングが重要な技術となる。
大規模環境向け分散TSDBアーキテクチャ
大規模環境では単一ノードTSDBの限界を超えるため、分散アーキテクチャが必要となる。Thanos, Cortex/Mimirのコンポーネント構成と技術詳細を以下に整理する。
Thanosのコンポーネント構成は次の通り。

https://thanos.io/tip/thanos/quick-tutorial.md/
| コンポーネント | 技術的役割 | 実装詳細 |
|---|---|---|
| Sidecar | Prometheus統合、ブロックアップロード | ・gRPCを介したクエリ転送 ・オブジェクトストレージ接続 |
| Store Gateway | 長期ストレージアクセス | ・オブジェクトストレージからのデータ読み取り ・インデックスキャッシュ |
| Querier | 検索統合、結果統合 | ・並列クエリ実行 ・重複排除 ・ダウンサンプリング適用 |
| Ruler | 一元的なルール評価 | ・一貫したアラートルール評価 ・オブジェクトストレージへの結果保存 |
| Compactor | 長期データの最適化 | ・ブロック統合 ・ダウンサンプリング生成 ・インデックス最適化 |
| Receiver | リモートライトエンドポイント | ・Push型データ受信 ・バッファリング ・書き込み分散 |
Thanosアーキテクチャの主要技術的特徴は、既存のPrometheusインスタンスを活用しながら分散機能を拡張できる点にある。各Prometheusにサイドカーコンテナを追加し、クエリをグローバルQuerier(クエリフェデレーション)に転送すると共に、ブロックデータをオブジェクトストレージにアップロードする。これにより、最小限の変更で既存環境を拡張できる。
Cortex/Mimirの主要コンポーネント構成は次の通り。

https://grafana.com/docs/mimir/latest/references/architecture/deployment-modes/#microservices-mode
| コンポーネント | 技術的役割 | 実装詳細 |
|---|---|---|
| Distributor | 入力負荷分散、検証 | ・テナントID認証 ・レプリケーション ・負荷分散 |
| Ingester | 書き込みバッファリング、永続化 | ・インメモリバッファ ・チャンク化 ・WAL管理 |
| Query Frontend | クエリ最適化、キャッシュ | ・クエリスプリット ・キャッシュ ・再試行 |
| Querier | クエリ実行、結果結合 | ・Ingester+ストレージからの並列データ取得 |
| Ruler | ルール評価、アラート生成 | ・テナントごとの分離評価 ・スケジュール管理 |
| Alertmanager | アラート処理、通知 | ・マルチテナントルーティング ・重複排除 |
| Compactor | データ最適化、集約 | ・テナント別ブロック統合 ・インデックス最適化 |
分散クエリ実行では、以下のようなアプローチが採用されている。
| クエリ実行技術 | 実装メカニズム | 最適化ポイント |
|---|---|---|
| クエリスプリット | ・時間レンジ分割 ・サブクエリ生成 |
・並列処理効率 ・メモリ使用量分散 |
| 並列フェッチ | ・マルチソースからの同時データ取得 | ・レイテンシ削減 ・スループット向上 |
| 結果マージ | ・データセット統合 ・重複排除 |
・正確な結果集約 ・メモリ効率 |
| 部分結果キャッシュ | ・クエリ部分結果の一時保存 | ・類似クエリ最適化 ・リソース再利用 |
| アダプティブクエリ処理 | ・実行時フィードバックによる最適化 | ・動的環境への適応 ・性能劣化防止 |
例えばCortexのQuery Frontendでは、大規模範囲クエリを小さなサブクエリに分割し、それらを並列実行することで、メモリ使用量を抑えつつ応答時間を短縮している。また、頻繁に実行される類似クエリに対してはキャッシュを活用して負荷を軽減している。
分散TSDBにおけるマルチテナント対応実装も企業環境で重要な技術要素である。
| マルチテナント機能 | 技術的実装 | 効果 |
|---|---|---|
| テナント分離 | 論理/物理分離、認証 | セキュリティ確保、リソース分離 |
| クォータ管理 | レート制限、使用量上限 | 公平な資源分配、過剰使用防止 |
| 課金メトリクス | 使用量計測、アカウンティング | 従量課金、コスト配分 |
| テナント固有設定 | 保持期間、レプリケーション係数 | 柔軟な要件対応、最適化 |
例えばCortexでは、すべてのAPIリクエストにテナントIDヘッダーが必要であり、これに基づいて完全な論理分離が実装されている。各テナントには独自のクォータ(1秒あたりのクエリ数、書き込みレート、アクティブな時系列数など)を設定でき、テナント間の干渉を防止している。
アラート技術とノイズ削減
アラート検出アルゴリズム
アラート検出技術は、単純な閾値ベースから高度なSLOベースや機械学習モデルまで進化している。静的閾値からSLOベースアラートへの技術的進化は以下のようにまとめられる。
| アラート方式 | 技術的実装 | 進化ポイント |
|---|---|---|
| 静的閾値 | ・固定値比較 ・持続時間指定 |
・基本的な異常検出 ・false positive多発 |
| 動的閾値 | ・移動平均ベースライン ・パーセンタイル閾値 |
・パターン変動への適応性向上 |
| アノマリー検出 | ・統計モデル ・機械学習ベース予測 |
・季節性・傾向認識 ・コンテキスト理解 |
| SLOベース | ・エラーバジェット消費監視 ・バーンレート |
・ビジネス影響に直結 ・アラート疲れ低減 |
特にSLOベースアラートは技術的に重要な進化である。従来の静的閾値(「CPU使用率が90%を超えたらアラート」など)では、実際のサービス影響と必ずしも相関せず、false positiveを多発しやすい。一方、SLOベースアラートでは、「月間99.9%の可用性」といったビジネス目標を基に、そのエラーバジェットの消費率や消費速度をモニタリングする。
統計的異常検知手法の実装と調整方法も重要な技術要素である。
| 異常検知技術 | 実装アルゴリズム | 調整パラメータ |
|---|---|---|
| Z-スコア | 平均からの標準偏差距離 | ・閾値σ倍率 ・基準期間 |
| ピアソン残差 | 期待値からの正規化偏差 | ・有意水準 ・時間窓サイズ |
| ARIMA | 自己回帰和分移動平均 | ・差分次数 ・平均化項数 |
| ホルト・ウィンターズ | 指数平滑法、季節性対応 | ・平滑化係数 ・季節項数 |
| MAD | 中央絶対偏差 | ・スケール係数 ・検出閾値 |
また、機械学習による予測型アラートの実装技術も近年注目されている。
| ML技術 | アルゴリズム | 特徴 |
|---|---|---|
| 教師なし異常検知 | ・Isolation Forest ・One-Class SVM |
ラベル不要、未知パターン検出可能 |
| 時系列予測 | ・Prophet ・LSTM ・GRU |
季節性・傾向認識、予測信頼区間 |
| アンサンブル手法 | ・複数アルゴリズム統合 | 精度向上、誤検出率低減 |
| オンライン学習 | ・逐次更新型モデル | 環境変化への適応、継続的改善 |
相関とノイズ削減
アラートのノイズを削減し、本当に重要な通知に集中するためには、相関機能が重要である。
アラートグループ化と根本原因分析の実装手法は次の通り。
| 技術要素 | 実装アプローチ | 手法詳細 |
|---|---|---|
| ラベルベースグループ化 | メタデータマッチング | サービス、環境、クラスタなどの共通属性でグループ化 |
| 時間的近接性 | 時間枠内のクラスタリング | 短時間内に発生したアラートをバースト対応で集約 |
| トポロジカル相関 | 依存関係グラフ解析 | システム間の依存関係を考慮した関連性検出 |
| 因果分析 | 時系列間の因果関係推定 | グレンジャー因果性検定等による原因特定 |
| ベイジアンネットワーク | 確率的依存関係モデル | 事前知識と観測データに基づく確率推論 |
トポロジーベースの相関や依存関係のモデリングが、具体的にどのような技術で実現されているのか次に簡単にまとめる。
| 実装手法 | 技術的アプローチ | 適用例 |
|---|---|---|
| 静的トポロジーマップ | ・設定ファイルによる関係定義 | インフラコンポーネント間の固定依存関係 |
| 動的ディスカバリー | ・サービスメッシュ ・APM統合 |
マイクロサービス環境での実行時依存検出 |
| グラフデータベース | ・Neo4j ・Neptune等のグラフDB |
複雑な依存関係の格納と高速トラバーサル |
| 因果推論アルゴリズム | ・PC/FCI ・NOTEARS等 |
観測データからの因果関係自動学習 |
| トレースデータ相関 | ・分散トレース(Jaeger等)との統合 | リクエストフローに基づく実際の依存検出 |
依存関係グラフを用いることで、複数の関連アラートが発生した際に、その依存関係を辿って根本原因を特定することができる。例えば、データベース障害に起因するアプリケーションエラーが発生した場合、アプリケーションアラートよりもデータベースアラートを優先的に通知することで、効率的な問題解決が可能になる。
ノイズ削減のためのアラート抑制メカニズムも重要な技術要素である。
| 抑制メカニズム | 技術的実装 | 効果 |
|---|---|---|
| 明示的抑制ルール | 条件ベースの抑制ポリシー | 優先度の低いアラートの選択的非表示 |
| アラート集約/相関付け | パターン認識による統合 | 関連アラートの自動集約 |
| フラッピング検出 | 状態変化頻度の監視 | 不安定なアラートの抑制 |
| クォータ/バジェット | アラート総量制限 | 通知過多状態の防止 |
| コンテキスト考慮 | 時間帯、対応者状況等考慮 | 状況に応じた通知調整 |
アラート通知とエスカレーション
効果的なアラート通知システムとエスカレーションパスの設計も、運用効率と問題解決速度に直接影響する重要な技術要素である。
| 通知技術 | 実装メカニズム | 技術的考慮点 |
|---|---|---|
| Webhook統合 | HTTP POSTによるイベント配信 | ・再試行 ・冪等性 ・認証 |
| メール配信 | SMTP、メールAPIサービス | ・配信確認 ・スパム対策 ・書式 |
| モバイルプッシュ | プッシュ通知サービス、アプリ統合 | ・優先度 ・バッジ ・操作可能性 |
| SMS/音声通話 | 電話APIサービス、TTS | ・確実な到達 ・応答確認 |
| チャットツール統合 | Slack、Microsoft Teams等API | ・リッチフォーマット ・インタラクティブ性 |
マルチチャネル通知の技術的実装では、配信保証が重要な課題となる。具体的には以下のような技術的アプローチが用いられる。
- メッセージキューを用いた非同期配信と再試行
- 配信確認(デリバリーレシート)による到達確認
- 複数チャネルを用いたフォールバック(主経路失敗時の代替経路)
- 受信確認(アクノレッジメント)による対応者応答確認
- エスカレーション条件付きのタイムアウト設定
エスカレーションパス自動化の実装方法例を次に示す。
| エスカレーション技術 | 実装アプローチ | 特徴 |
|---|---|---|
| 時間ベースエスカレーション | 未応答時間に基づく段階的通知 | シンプル、予測可能 |
| 重大度ベースエスカレーション | アラート重要度に応じた通知先決定 | 影響度に即した対応 |
| ローテーションベース | オンコール当番への自動割り当て | 公平な負担分散、明確な責任 |
| アクション条件付き | 対応状況に応じた動的経路決定 | コンテキスト認識、適応型 |
| ポリシーベース | ルールエンジンによる複合条件評価 | 柔軟なルール設定、複雑シナリオ対応 |
PagerDutyなどのインシデント管理ツールでは、エスカレーションポリシーを設定することができる。例えば、アラートが発生すると最初に一次オンコール担当者に通知され、15分間応答がなければ二次担当者へエスカレーションされる。さらに応答がなければチームマネージャー、最終的にはCTOへと段階的にエスカレーションされる。こうした自動化により、重大なアラートが未対応のまま放置されるリスクを最小化できる。
まとめ
ゴリラはやはりかっこいい。

https://www.higashiyama.city.nagoya.jp/blog/2014/10/post-2126.html

Discussion