空間インデックス(Geohash, Quadtree, Google S2)の空間分割思想
1. はじめに
「さて、今夜私がいただくのは ...」でおなじみのフードデリバリーサービスをはじめ、多くのアプリケーションは位置情報に基づいた機能に依存しています。
「ユーザーの半径5km以内にあるレストランを全て見つける」というような一見単純な要求も、大規模なデータセットでは複雑な計算問題となります。たとえば、2億件のビジネスデータから検索するとなると、単純な線形探索では現実的なレスポンス時間を達成することは難しいと言えます。
この記事では、位置情報サービスにおける高効率な検索を実現するための三つの主要な地理空間インデックス技術である
- Geohash
- Quadtree
- Google S2
について少し掘り下げてみます。これらの技術は、地理空間データを効率的に処理するために特別に設計されたデータ構造とアルゴリズムを提供します。本記事では、地理空間を分割する手法について焦点を当てます。
ついでに、Redisを活用した近接検索の実装方法についても触れます。Redisは、地理空間データを扱うための便利な機能を提供しています。
2. 地理空間データの基礎
地理空間データを扱う上での前提知識を整理しておきます。
| 概念 | 説明 | 空間インデックスへの影響 |
|---|---|---|
| 緯度・経度 | 地球上の位置を特定するための座標系 | 二次元データを一次元に変換する必要がある(Geohash、S2など) |
| 球面と平面 | 地球は球形だが、計算は平面上で行われることが多い | インデックス方式によって球面歪みの補正精度が異なる |
| 距離計算 | 二点間の距離計算(ハーバーサイン公式など) | 近接検索の精度と計算コストのトレードオフが発生 |
| 密度分布の不均一性 | 都市部と郊外ではデータ密度が大きく異なる | 均一分割(Geohash)vs 動的分割(Quadtree)の選択 |
| 空間的局所性 | 物理的に近い点は一緒に検索されることが多い | 空間充填曲線の選択が重要(Z-order vs ヒルベルト曲線) |
これらの概念は、後述する三種類の空間インデックス技術(Geohash、Quadtree、Google S2)の設計思想と長所・短所に直接影響しています。たとえば、Geohashは実装が簡単ですが球面歪みの補正が弱く、Google S2はより正確な球面表現を実現しています(ただし、情報が少ないうえに実装はゲキムズ)。
3. 空間インデックスの基本:空間分割の思想
地理空間インデックス技術は、どれも「広大な空間を効率的に管理可能な単位に分割する」という基本思想を共有しています。空間分割の手法によって各技術の特性が大きく左右されるため、まずはこの基本的な考え方に触れます。
空間分割のアプローチ
空間分割のアプローチは、大きく三つに分類することができます。
| 分割方法 | 説明 | 代表的な技術 |
|---|---|---|
| 均一分割 | 空間を同じサイズの区画に規則的に分割する | Geohash |
| 再帰的分割 | 必要に応じて区画をさらに小さな区画に分割していく | Quadtree |
| 球面階層分割 | 球面を階層的に分割する | Google S2 |
均一分割は、空間を均等に分けることで計算の単純化を図りますが、データの密度が不均一な場合には効率が悪くなることがあります。
https://dev.to/pubnub/what-is-geohashing-52pg
再帰的分割は、データの密度に応じて分割粒度を調整できるため、特に都市部などの高密度エリアで効果を発揮します。

https://opendsa-server.cs.vt.edu/ODSA/Books/Everything/html/PRquadtree.html
球面階層分割は、地球の曲率を考慮した設計であり、特に大規模な位置情報サービスでの精度と性能を両立させることができます。
Google S2 の場合は、立方体の6つの面を単位球面に投影し、これが最上位レベルの6つの「フェイスセル」になります。各セルはさらに4つの子セルに分割され、これを繰り返すことで階層的な構造が形成されます。分割は最大で30レベルまで行われ、このレベルのセルは「リーフセル」と呼ばれます。

https://s2geometry.io/devguide/s2cell_hierarchy
分割における重要な考慮点
空間分割を行うにあたっては、いくつか定めておくべき考慮点があります。これらは、インデックスの精度やパフォーマンスに直接影響を与えます。
| 考慮点 | 説明 | 影響 |
|---|---|---|
| 分割の粒度 | 区画のサイズや詳細度 | 精度とパフォーマンスのトレードオフ |
| 分割の規則性 | 均一か不均一か | データ構造の複雑さと適応性 |
| 次元の扱い | 2次元データを1次元に変換する方法 | インデックス効率と空間的局所性 |
| 境界問題 | 区画の境界付近のデータ処理 | 検索精度と複雑さ |
空間分割の目的は、「点と点の関係性」を効率的に把握することにあります。例えば「この点から5km以内にある全ての点」を探すとき、全ての点同士の距離を計算する代わりに、あらかじめ空間を分割しておくことで計算量を大幅に削減できます。
今回取り上げている Geohash、Quadtree、Google S2 はそれぞれ異なる空間分割アプローチを採用していますが、「大きな問題を小さな問題に分解する」という基本的な戦略では共通しています。空間をどう分割するかによって、精度、検索効率、メモリ使用量などのトレードオフが生じることから、各技術の特性には差異が生まれます。
4. Geohash:一次元文字列による地理空間インデックス
Geohashは、二次元の緯度・経度データを一次元の文字列に変換する手法です。
Geohashの仕組み
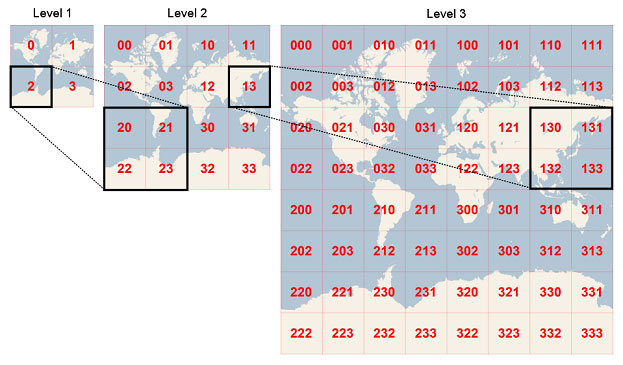
下記に再掲する図をもとに、具体的な分割フローを追跡してみます。
https://dev.to/pubnub/what-is-geohashing-52pg
ステップ1:地球表面の初期分割
まず地球全体を4つの大きな区画に分割します(図のLevel 1)。
この分割は緯度と経度の中間値でなされます。
- 左上(0):緯度[0〜90]、経度[-180〜0]
- 右上(1):緯度[0〜90]、経度[0〜180]
- 左下(2):緯度[-90〜0]、経度[-180〜0]
- 右下(3):緯度[-90〜0]、経度[0〜180]
この時点で、例えば東京(35.6895, 139.6917)は右上の区画「1」に位置することがわかります。
ステップ2:再帰的な区画の細分化
次に、各区画をさらに4つの小区画に分割していきます(図のLevel 2)。
図の例では、Level 1の「2」の区画が選択され、それがさらに「20」「21」「22」「23」という4つの小区画に分割されています。
この分割は以下のビット表現で理解できます。
「2」は2進数で「10」
その下の区画は「00」「01」「10」「11」を追加
結果として「20」=「1000」、「21」=「1001」、「22」=「1010」、「23」=「1011」
さらにLevel 3では、例えば「22」の区画が「220」「221」「222」「223」に細分化されます。
ステップ3:ビット列の構築
位置情報をGeohashに変換する過程では、緯度と経度の情報が交互にビット列に組み込まれます。
図の分割パターンを見ると、各レベルで追加される2ビットは、その区画の相対的な位置(左上、右上、左下、右下)を表しています。
例えば、左下の大区画「2」を選び、さらにその中の右下「23」、そしてさらにその中の左上「230」と進むと、最終的なビット列は次のようになります。
- 「2」=「10」(左下)
- 「23」=「10」+「11」(右下)
- 「230」=「10」+「11」+「00」(左上)
このように、位置を特定するたびに2ビットずつ情報が追加され、精度が向上していきます。
ステップ4:Base32エンコーディング
最終的に得られたビット列は、5ビットごとにBase32文字セット(0-9およびb-z、ただしa,i,l,oを除く)にエンコードされます。これにより、長いビット列がコンパクトな文字列に変換され、「xn76uw」のような形式のGeohashが生成されます。
Geohashの精度とプレフィックス
| Geohash長 | グリッドサイズ | 精度 | 典型的な用途 |
|---|---|---|---|
| 1文字 | 5,000km×5,000km | 大陸レベル | 広域データのクラスタリング |
| 3文字 | 156km×156km | 都市間レベル | 広域地域の分析 |
| 5文字 | 4.9km×4.9km | 地区レベル | 都市内の大まかな位置 |
| 7文字 | 152m×152m | 街区レベル | 一般的なロケーションベースアプリ |
| 9文字 | 4.8m×4.8m | ビルレベル | 詳細な位置追跡 |
Geohashの長所と短所
| 長所 | 短所 |
|---|---|
| シンプルな文字列表現で扱いやすい | グリッド境界で近い位置でも異なるハッシュになる問題がある |
| 標準的なDB,キーバリューストアで使用可能 | 距離計算が近似的(実際の距離とは若干異なる) |
| プレフィックスによる階層的な検索が可能 | 緯度・経度でのビット交互処理により異方性を持つ |
| 位置変更時の更新が容易 | 極地方での歪みが大きい |
| 実装が比較的シンプル | Z-orderカーブに基づくため空間的局所性が中程度 |
5. Quadtree:空間を再帰的に分割するデータ構造
Quadtreeは、二次元空間を再帰的に4つの象限(四分木)に分割するインメモリデータ構造です。データの分布に応じて動的に分割粒度を調整できる特徴があります。
Quadtreeの基本構造
| 構成要素 | 説明 |
|---|---|
| ノード | 空間領域を表す。内部ノードと葉ノードがある |
| 内部ノード | 4つの子ノード(NW, NE, SW, SE)を持つ |
| 葉ノード | 実際のデータポイントまたはデータポインタを格納 |
| 分割条件 | ノード内のデータポイント数が閾値を超えた場合に分割 |
動的分割の仕組み
Quadtreeの重要な特徴は、データ密度に応じて動的に分割できることです。たとえば、都市部(高密度)では細かく分割し、田舎(低密度)では粗く分割することで、メモリ使用を最適化します。
下記に再掲する図をもとに、具体的な分割フローを追跡してみます。
https://opendsa-server.cs.vt.edu/ODSA/Books/Everything/html/PRquadtree.html
ステップ1:初期空間の定義
まず、図(a)のように0〜127の座標範囲を持つ正方形の二次元空間があります。この空間内に点A, B, C, D, E, Fが配置されています。この空間全体がQuadtreeのルートノード(図(b)の最上部の円)に対応します。
ステップ2:最初の分割
初期空間が4つの等しい象限に分割されます。
北西(nw)象限:左上の領域
北東(ne)象限:右上の領域
南西(sw)象限:左下の領域
南東(se)象限:右下の領域
この最初の分割で、点Aは北西象限、点B南西象限、点C・Dは北東象限、点E・Fは南東象限に振り分けられます。
ステップ3:再帰的な分割
各象限に格納されるデータ点の数が多すぎる場合(閾値を超える場合)、その象限はさらに4つの小象限に分割されます。図(b)では、これが木構造で表現されています。
北西象限には点Aのみで、これ以上分割する必要がないため、それ自体がリーフノードになります(座標40,45)。
北東象限には点C(70,10)とD(69,50)があります。この象限はさらに分割され、CとDはそれぞれ適切な小象限に配置されます。
南西象限には点B(15,70)のみなので、これ以上分割されません。
南東象限には点E(55,80)とF(80,90)があります。これも分割され、EとFはそれぞれの小象限に配置されます。
ステップ4:木構造の完成
分割プロセスが完了すると、図(b)のような木構造が形成されます。
円はさらに分割が必要な内部ノードを表します
四角形はデータ点を保持するリーフノードを表します
各枝は空間分割における象限(nw, ne, sw, se)を表します
Quadtreeの長所と短所
| 長所 | 短所 |
|---|---|
| データ密度に応じた動的分割が可能 | メモリ消費が大きい(インメモリ構造) |
| 実装が直感的で理解しやすい | 大規模データセットでの構築に時間がかかる |
| 近接ポイント検索が高速 | 更新時のバランス再調整が必要 |
| 視覚的表現がわかりやすい | 地球の曲率を考慮していない |
| 二次元データの局所性が高い | ディスクベースのストレージとの相性が悪い |
6. Google S2:ヒルベルト曲線を用いた高度な空間インデックス
Google S2は、球面をヒルベルト空間充填曲線にマッピングすることで、二次元(実際には三次元)の空間を一次元のインデックスに変換する先進的な手法です。Googleマップなどの大規模位置情報サービスで使用されています。
S2の基本概念
| 概念 | 説明 |
|---|---|
| S2セル | 球面を階層的に分割した要素。一意のセルIDを持つ |
| セルID | 64ビットの整数値。位置と解像度を表現 |
| ヒルベルト曲線 | 空間充填曲線の一種。空間の局所性を保持 |
| カバリング | 任意の領域をS2セルの集合で近似表現 |
S2 の仕組み
下記に再掲する図をもとに、具体的な分割フローを追跡してみます。
https://s2geometry.io/devguide/s2cell_hierarchy
ステップ1:地球を立方体に投影する
まず、Google S2は球体である地球を立方体に投影します。図では、緑色と赤色の大きな境界線が見えますが、これは立方体の面(face)を表しています。地球全体は合計6つの面で覆われていますが、図では主に2つの面(緑と赤)が見えています。
この投影は単純な平面投影ではなく、球面と立方体面の間の特殊な変換を使用することで、面積の歪みを最小限に抑えています。
ステップ2:各面を階層的に細分化する
次に、各立方体の面は階層的に4等分されていきます。図では特に赤い面(アジア・太平洋地域を含む部分)において、さらに小さな区画に分割されているのが分かります。中国、タイなどの領域がより細かく分割されています。
この階層的な分割は、各セルを常に4つの子セルに分けることで行われます。
レベル0:立方体の6つの面
レベル1:各面を4分割した24のセル
レベル2:さらに4分割した96のセル
...
このプロセスは理論上、最大30レベルまで続き、最小のセル(リーフセル)は地球上で約1cm四方の大きさになります。
ステップ3:ヒルベルト曲線による番号付け
Google S2の最も重要な特徴は、これらのセルに番号を付ける方法です。図では直接見えませんが、S2はヒルベルト曲線という特殊な空間充填曲線を使用しています。

https://s2geometry.io/devguide/s2cell_hierarchy
この曲線は、連続した一本の線で各セルを一度だけ通過し、近い位置にあるセルは曲線上でも近い位置にあるように配置されます。
これにより、近いセルID同士は地理的にも近い位置関係にあり、データを順番に読み込むと、地理的に近いデータが連続して処理されます。
ステップ4:非均一なセル分割の活用
図から分かるように、すべての地域が同じ密度で分割されているわけではありません。中国やタイなどの領域はより細かく分割されていますが、海洋部分はより大きなセルのままです。
これはGoogle S2の重要な特性を示しています。
- データや関心の密度に応じて異なるレベルのセルを使用できる
- 必要な精度に合わせてセルサイズを選択できる
- 複雑な形状の領域も様々なサイズのセルの集合として効率的に表現できる
ステップ5:実用的な応用
この階層的な分割システムにより、Google S2はいくつかの強力な機能を提供します。
- 近接検索が非常に効率的(「この地点から5km以内の全てのポイントを見つける」など)
- 異なる解像度のセルを組み合わせて任意の形状を近似できる
- 空間的局所性が保持されるため、データベース操作やキャッシュが効率的
例えば、Google Mapsはこのシステムを使って、地図上のオブジェクトのインデックス作成や検索を効率化しています。
参考までに、ポケモンGOについて興味深い考察を行っている記事を下記に紹介します。
ヒルベルト曲線の特性
ヒルベルト曲線は、Z-orderカーブ(Geohashで使用)よりも空間的局所性が高く、物理的に近い点が曲線上でも近い位置になる確率が高いという特性があります。

https://www.bic.mni.mcgill.ca/~mallar/CS-644B/hilbert.html
ラーメン容器に見られる幾何学模様「雷紋」のようにも見えますが、よく見ると(見なくても)違います。

https://www.wikiwand.com/ja/articles/雷紋
S2の長所と短所
| 長所 | 短所 |
|---|---|
| 球面の歪みを最小限に抑えた設計 | 実装が複雑で学習曲線が急 |
| 非常に高い空間的局所性 | リソース消費が比較的大きい |
| 階層的なセル構造により精度調整が可能 | オープンソースだが、専門的な知識が必要 |
| 高度な領域カバリング機能 | 小規模アプリケーションではオーバースペック |
| Googleが実務で使用している実績 | ライブラリサポートが限定的(主にC++, Go, Java) |
7. 三種類の地理空間インデックスの比較分析
性能と特性の比較
| 特性 | Geohash | Quadtree | Google S2 |
|---|---|---|---|
| 精度 | 中(プレフィックス長で調整) | 高(動的分割) | 最高(細かい階層と補正) |
| 構築時間 | 速い | 中程度 | 比較的遅い |
| メモリ消費 | 少ない | 多い | 中程度 |
| クエリ速度 | 速い | 非常に速い | 非常に速い |
| 更新の容易さ | 最も容易 | 複雑(再分割が必要) | 中程度 |
| 実装の複雑さ | 低い | 中程度 | 高い |
| 空間的局所性 | 中程度 | 良好 | 優れている |
| 境界問題 | あり | 少ない | 最小限 |
適したユースケース
| アプリケーション | 推奨インデックス | 理由 |
|---|---|---|
| 小〜中規模のウェブサービス | Geohash | 実装が容易で多くのDBがサポート |
| 人口密度が不均一な地域での検索 | Quadtree | 密度に応じた動的調整が可能 |
| 大規模グローバルサービス | Google S2 | 精度と性能のバランスが最適 |
| リアルタイム位置追跡 | Geohash, S2 | 更新が頻繁な場合はGeohash、精度重視ならS2 |
| AR・VRアプリケーション | Google S2 | 三次元空間との親和性が高い |
8. Redisを活用した近接クエリの最適化
Redisは高速なインメモリキーバリューストアであり、バージョン3.2以降は地理空間インデックスと検索をネイティブにサポートしています。Redisの地理空間機能はGeohashに基づいていますが、内部実装が最適化されています。
Redis GEOコマンド
| コマンド | 機能 | 例 |
|---|---|---|
| GEOADD | 位置データを追加 | GEOADD locations 139.6917 35.6895 "tokyo_station" |
| GEODIST | 2点間の距離を計算 | GEODIST locations "tokyo_station" "shinjuku_station" km |
| GEOHASH | 座標のGeohashを取得 | GEOHASH locations "tokyo_station" |
| GEOPOS | 登録された座標を取得 | GEOPOS locations "tokyo_station" |
| GEORADIUS | 円形範囲内の要素を検索 | GEORADIUS locations 139.7 35.68 5 km |
| GEORADIUSBYMEMBER | メンバーを中心とした範囲検索 | GEORADIUSBYMEMBER locations "tokyo_station" 2 km |
Redisによる地理空間データのキャッシング戦略
| 戦略 | 実装方法 | 利点 |
|---|---|---|
| Geohashプレフィックスによるキャッシング | Geohashの上位文字をキーとして使用 | 階層的なキャッシュが可能 |
| グリッド別ビジネスIDのキャッシング |
grid:{geohash}:businesses 形式のキー |
効率的な範囲検索 |
| 有効期限(TTL)の設定 |
EXPIRE コマンドでTTLを設定 |
キャッシュの鮮度を保証 |
| パイプラインによる一括操作 | 複数のコマンドをパイプライン化 | ネットワークレイテンシの削減 |
実装例:RedisによるビジネスIDのキャッシング
9. まとめ
本記事では、Geohash、Quadtree、Google S2の三つの空間インデックス手法について少し掘り下げてみました。それぞれの手法は、異なるアプローチで地理空間データを効率的に管理し、検索するためのものです。
Geohashはシンプルで扱いやすく、Quadtreeは動的な分割が可能で、Google S2は高度な空間充填ラーメン曲線を利用しています。
どれも一長一短があります。選択する際は、アプリケーションの要件やデータの特性に応じて最適な手法を選ぶことが重要です。そのための知識を得るためのスナップショットとして、この記事を残しておきます。
Discussion