ネットワークパフォーマンスを支える技術 - OS/ハイパーバイザ最適化の要諦 🫠
1. 執筆モチベーション
「ネットワーク機能のソフトウェア実装、もうちょっと踏み込んでみるか?」
あるときふとそう思った。
そこで見つけたのが、次の論文「Operating Systems and Hypervisors for Network Functions: A Survey of Enabling Technologies and Research Studies」。
この論文は、汎用コンピューティング(GPC)プラットフォーム上でのネットワーク機能の実装に関するオペレーティングシステムとハイパーバイザーの側面を調査したもの。ちょうどええやんと思い、読み進めることにした。
2. なぜネットワーク機能のソフトウェア実装に注目するのか
従来のネットワーク機能は、専用のハードウェア(いわゆる「ブラックボックス」と呼ばれる独自のインフラ)で実行されてきた。これらの専用ハードウェアは予測可能なパケット処理レイテンシやスループットを実現できるが、大きな制約がある。それは、柔軟性とスケーラビリティの欠如だ。
そこで注目されるのが、汎用コンピューティング(GPC)プラットフォーム上でのネットワーク機能の実装である。具体的にはx86(Intel)、x64(AMD)、ARMプロセッサなどの一般的なコンピュータアーキテクチャ上でネットワーク機能を動作させる方法が研究されている。
2.1. ネットワーク機能をソフトウェアで実装する際の課題
ソフトウェアでネットワーク機能を実装するのは簡単ではないことがわかる。GPCプラットフォーム上でのパケット処理には、いくつかの特有の課題があるためである。論文のなかで列挙される課題は以下の通り。
-
I/O集中型処理の課題
ネットワークインターフェースカード(NIC)にラインレートでパケットが到着すると、システムはI/O活動で圧倒されることがある。これらのI/O活動は、GPC内のプロセッシング要素間のデータ転送に使われる相互接続(オンチップのAXIやチップ間のPCIeなど)に負荷をかける。 -
計算集中型処理の課題
パケット処理のタイプは、単純なヘッダー検索から複雑な計算(IPSecなどの暗号化やディープパケットインスペクション)まで幅広く、CPUに大きな負荷をかける。パケットサイズ、パケットレート、接続状態、フロータイプ(UDPやTCP)などの要素も全体的なCPU負荷に影響する。 -
繰り返しと定型的な操作
CPUコアによるパケット処理は本質的に定型的で、到着するパケットごとに繰り返される。例えば、リンク層(L2)転送(スイッチング)機能は、入ってくるパケットごとにヘッダーを検査し、転送ポートを特定する。 -
レイテンシに敏感
CPUコア上でのプロセスとスレッドのスケジューリングは相対的な優先度に基づいて行われるため、処理レイテンシにバラつきが生じる余地がある。これによりパケットフローにジッター(揺らぎ)が発生する可能性がある。 -
専用キャパシティの必要性
ラインレート(例:各ポート10Gbps)で動作するように設計されたネットワーク機能は、ネットワーク機能に専用のハードウェアリソース(CPUコア数やメモリ量など)を確保する必要がある。 -
大容量メモリの必要性
ゲートウェイ機能を実装するネットワーク機能は、複数のポートからのパケットデータをバッファリングするための大容量のシステムメモリを確保する必要がある。
これらの課題を見ると、一般的なアプリケーション向けに設計された従来のオペレーティングシステムやハイパーバイザーでは、効率的なネットワーク機能処理には不十分であることがわかる。
2.2. オペレーティングシステムとハイパーバイザーの役割

https://ieeexplore.ieee.org/document/9844719
論文によれば、オペレーティングシステムとハイパーバイザーは、次の重要な特性を持っている。
-
抽象化(Abstraction)
抽象化は仮想化に不可欠であり、ハードウェアリソースを分離して共有できるようにする。CPUコアは抽象化プロセスをサポートし、仮想化を実現する。例えば、IntelプロセッサのHyper-Threading(HT)は、プロセス実行のハードウェア多重化を可能にする。また、CPUコアの状態を電力節約とパフォーマンスのために切り替えることができる(P状態とC状態など)。 -
メモリ(Memory)
Non-Uniform Memory Access(NUMA)は、データをコアの近くのメモリセルに格納・取得するため、コアの近接性に関連したアフィニティを持つ。メモリ抽象化はアドレス変換のオーバーヘッドを追加するが、ソフトウェアが線形アドレス空間を使用できるようにする。 -
I/Oデバイス(I/O devices)
I/OデバイスはSystem-on-Chip(SoC)コンポーネントのハードウェア機能を、PCIeなどの相互接続を通じて拡張する。これらのハードウェア機能には、ストレージ、追加の計算ハードウェアユニット(FPGA、GPU、XPUなど)が含まれる。I/OデバイスはCPUの外部にあり、サービス要求やシステムメモリを通じたトランザクションの共有・調整のための追加のソフトウェアオーバーヘッドが必要となる。
2.3. 仮想化の基本概念
論文ではさらに仮想化の基本概念について説明している。
汎用コンピューティング(GPC)システムは、ハードウェアリソースを共有することで複数のアプリケーション(プロセスやスレッド)を同時に実行できる完全に独立した実行環境である。NF(ネットワーク機能)アプリケーションは、オペレーティングシステムやハイパーバイザーに独自の要件をつくり出す。

https://ieeexplore.ieee.org/document/9844719
ソフトウェアコンポーネントがハードウェアとやり取りする主なメソッドは2つある。
-
アプリケーションバイナリインターフェース(ABI)方式
NFアプリケーションは、低レベルのハードウェア操作を行わず、ABIを通じてOSにサービス要求を行う。ABIは、NFアプリケーションからの高レベルのサービス要求をプラットフォームハードウェアが理解可能なシステムISA要求に翻訳する。 -
命令セットアーキテクチャ(ISA)方式
システムソフトウェアコンポーネント(アプリケーションプロセス、スレッド、OS、ハイパーバイザードライバーなど)がプラットフォームハードウェアと対話するための広範なインターフェースセットを提供する。
さらに仮想化の概念として仮想マシンモニター(VMM)が紹介されている。
VMMはゲストオペレーティングシステムとそれに関連するアプリケーションプロセスを仮想化ソフトウェア上でホストできる。一般的に、VMMはゲストプロセスに仮想ABI環境を提供するか、ゲストオペレーティングシステムにISAベースの仮想システム環境を提供する。
3. ネットワーク機能のためのオペレーティングシステムとハイパーバイザー

https://ieeexplore.ieee.org/document/9844719
3.1. オペレーティングシステム(OS)
注目するのは、OSがネットワーク機能にとってどのような役割を果たすのかという点。論文によれば、OSは「ソフトウェアアプリケーションがハードウェアリソースを効率的に使用できるようにする」という基本的な役割がある。まあそれはそう。
初期のオペレーティングシステムは、バッチ処理プロセス、I/O、メモリ管理など非常に基本的な機能に限定されていた。しかし、ハードウェア技術の進歩に伴い、OSはその範囲を拡大し、多様なハードウェア機能をサポートし、幅広いアプリケーションを管理する必要が出てきた。
これにより、OSの設計は次の2つの部分に分かれる。
- カーネル(「カーネル空間」とも呼ばれる):ハードウェアに焦点を当てた機能
- ユーザースペース:ユーザー定義のアプリケーションに焦点を当てた機能
このカーネルとユーザースペースの分離は、セキュリティとシステムの安定性を高めるために重要であるが、ネットワーク機能の実装にとっては追加のオーバーヘッドや遅延を引き起こす可能性がある。なぜかと言うと、ユーザースペースのアプリケーションがネットワークパケットを処理するためには、カーネル空間とのデータのやり取りが必要になるためである。
カーネルの主要な機能としては、メモリ管理、ファイルシステム、I/O管理、プロセススケジューリングがある。これらの機能はネットワーク機能の性能に直接影響を及ぼす。
OSは、リアルタイムかノンリアルタイムかというカーネル機能の特性に基づいて分類できる。また、アプリケーション中心の側面によって、組み込み型、分散型、クライアント型、クラウド/サーバー型などに分類することもできる。
3.2. ハイパーバイザー
続いて、論文はハイパーバイザー(Virtual Machine Monitor(VMM)とも呼ばれる)について説明をする。
ハイパーバイザーは、GPCプラットフォーム上で単一または複数の仮想マシン(VM)を作成・実行するソフトウェアである。ハイパーバイザーの主な目的は、プラットフォームハードウェア(CPU、メモリ、I/Oデバイスを含む)を抽象化することによって仮想化を可能にし、基礎となる物理ハードウェアリソースの共有を可能にすることである。
ハイパーバイザーには主に2つのタイプがある。

https://www.researchgate.net/publication/335866538_A_Pattern_for_an_NFV_Virtual_Machine_Environment
-
タイプ1ハイパーバイザー(ベアメタルまたはネイティブハイパーバイザーとも呼ばれる)
- Microsoft Hyper-V、VMware ESXi、Linux Kernel-based Virtual Machine (KVM)などが例
- 物理サーバー上で直接実行され、ネイティブハイパーバイザーと物理サーバーの間にソフトウェアやOSは介在しない
- 単一または複数のVMを実行できる「オペレーティングシステム」として機能する
- ハードウェアリソースを直接割り当てたり、変換を通じて抽象化したりできる
-
タイプ2ハイパーバイザー
- VMware Workstation、Oracle VM (Virtual Box)、Microsoft Virtual PCなどが例
- 実行するために基礎となるオペレーティングシステムが必要
- 仮想化ソフトウェア上にVMをホストする
- ハードウェアの構成やI/Oサービスのエミュレーションを含む構成では、VMと物理プラットフォームハードウェア間の変換(ABIやISA要求を介した)の一部としてソフトウェアによる相互作用が必要となり、オーバーヘッドが増加し効率が低下する
興味深いことに、タイプ1とタイプ2の両方のハイパーバイザーは、IntelのVT-xやVT-dなどの仮想化拡張機能を使用して、ISAを介して直接プラットフォームハードウェアにアクセスするように構成できる。したがって、仮想化のパフォーマンスペナルティはエミュレートされた仮想デバイスや仮想CPUなどの構成アプローチに依存し、VMで実行されるワークロードにも依存する。

https://linuxdevices.org/virtualization-stack-supports-new-intel-processor-capabilities/
KVMは特に興味深い事例である。LinuxのOSカーネルがVMをサポートするためにVMMサービスを提供するように拡張されている。KVMは基礎となるLinux OSカーネルをインストールする必要があり、KVMはLinux OSカーネルに依存してvCPUをスケジューリングするため、KVMはタイプ2ハイパーバイザーとも考えられる。

この点で、オペレーティングシステムとハイパーバイザーは両方とも同じような内部構造を持ち、プラットフォームハードウェアを抽象化しているが、OSはアプリケーションの実行に最適化され、ハイパーバイザーは他のオペレーティングシステムの実行に最適化されている。
3.3. ソフトウェア化されたネットワーク機能のコンポーネント
論文の次の部分では、ソフトウェア化されたネットワーク機能のコンポーネントについて説明している。
アプリケーションは、実行可能なバイナリを作成するためにプログラムまたはコードをコンパイルすることによって生成される。一般的に、OSでバイナリプログラムを実行する場合、OSは主に実行中に十分なメモリと処理(CPU)リソースを提供することに焦点を当てている。加えて、アプリケーションとして実装されたNFの場合、OSはNICとの間のパケットデータのやり取りに十分なI/Oトランザクション容量を提供する必要がある。
高いデータレートでのパケット処理には、高い処理(CPU)容量、大きなメモリ、高いI/Oトランザクション容量が必要である。これらの要件に対処するために、さまざまな最適化が提案されている。例えば、Data Path Development Kit (DPDK)、Berkeley Packet Filter (BPF)、eXpress Data Path (XDP)などのライブラリは、アプリケーションが望むネットワーク機能を実装するために使用できる高度なパケット処理機能を提供する。
これらのライブラリは以下のように使用できる。
- ユーザースペースで静的または動的ライブラリとして使用する
- カーネルモジュールとして使用する

https://ieeexplore.ieee.org/document/9844719
図2は、NFの開発に関連する様々なソフトウェアコンポーネントを示している。
NFアプリケーションは、開発のためにライブラリとアプリケーションプログラミングインターフェース(API)を用いて開発することができる。
同様に、OSのカーネルで実行され、ユーザーアプリケーションと比較して高い特権を持つカーネルモジュールも、ライブラリとAPIの助けを借りて開発できる。カーネルモジュールはOSの一部として実行されるため、OS自体のすべての特権を継承する。したがって、適切に管理されていないと、カーネルモジュールとして実行されるNFアプリケーションはセキュリティ上の脅威をもたらす可能性がある。
プラットフォームハードウェアのすべてのパケットトランザクションに固有のパケット処理機能、またはIPSecトンネル終端やファイアウォールなどのすべてのユーザーアプリケーションの独立したパケット処理操作を可能にするために必要なNFアプリケーションは、カーネルモジュールとして実行できる。これは、ディープパケットインスペクションやフィルタリングなどの専用I/Oハードウェアベースのパケット処理機能の拡張としても見ることができる。
さらに、FPGAやGPUなどのプログラム可能なハードウェアコンポーネントもあり、共通ライブラリとAPIをコンパイルして開発できるバイナリ(ソフトウェアコンポーネント)が必要である。
3.4. ソフトウェア化されたネットワーク機能の形態
「NFはどのような形でGPCプラットフォーム上に実装され、どのような特性を持つのか」
伝統的に、NFは専用(プログラム不可能)ハードウェアで実装されてきた。
汎用コンピューティング(GPC)プラットフォーム上でソフトウェアとして実装することには大きなメリットがある。最も重要な特長は、ネットワーク機能の動作特性を柔軟に変更できる点にある。この柔軟性により、固定的な機能しか持たない従来のハードウェア実装から脱却し、要件の変化に対応できるようになるというわけだ。
こうした理由から、従来の固定的なハードウェアネットワークを、柔軟性の高いソフトウェアベースのネットワークへと変革することは、学術界と産業界の両方から高い注目を集める。
論文内で展開されるNFの実装パターンは次の通り。
-
ネイティブOS上のアプリケーションとしてのNF(BM-NF)
コンテナ化や仮想化なしにプラットフォームハードウェア上のネイティブOSで実行されるNFアプリケーションは、ベアメタルネットワーク機能(BM-NF)と呼ばれる。BM-NFは、抽象化と仮想化がないためソフトウェアオーバーヘッドが低く、高いパフォーマンスを達成できる。ただし、BM-NFはOSとハードウェアリソースへの直接アクセスを必要とすることが多く、OS依存およびハードウェア固有の実装となり、複数のプラットフォームやオペレーティングシステムで柔軟にスケールすることができない。 -
OSカーネルモジュールとしてのNF
ネイティブOSでアプリケーションとして実行されるNFは、OSによってスケジュールされ(OSのタスクスケジューラサービスなど)、アプリケーションの優先度に基づいて通常管理され、ユーザースペースに含まれるため、メモリやI/Oデバイスなどのハードウェアリソースへの直接アクセスはない。
対照的に、カーネルモジュールとして実行されるNFはOSに挿入され、OS自体の一部になる。OSの一部として、NFはハードウェアに対して完全に透過的に動作でき、抽象化なしで、厳格なカーネルスケジューリングポリシーに従ってスケジュールされ、NFの継ぎ目のない操作(カーネル空間では、より高い優先度のタスクによるタスクプリエンプションはなく、多重化による予約の制限もない)を実現する。 -
コンテナ内のアプリケーションとしてのNF(CNF)
コンテナは、大規模なクラウドインフラストラクチャを管理するためのクラウドネイティブな原則を使用する人気のある管理フレームワークである。アプリケーションはコンテナイメージに含まれ、コンテナエンジン(Docker)によって柔軟にスケール、移行、管理できる。
同じ原則を使用して、NFアプリケーションをコンテナ化し、Kubernetesなどのクラウドネイティブなフレームワークをクラウドインフラストラクチャ管理に使用しているコンテナとして管理することができる。このようにコンテナで実装されたNFアプリケーションは、コンテナ化されたネットワーク機能(CNF)と呼ばれる。 -
VM内のアプリケーションとしてのNF(VNF)
仮想マシン(VM)は、それぞれが独自のOSカーネルとユーザーアプリケーションを持つことで、コンテナよりも高度な分離を提供する。VMはハイパーバイザー上で実行され、分離と高度なセキュリティのために最適化されている。結果として、高度な分離とセキュリティを必要とするNFアプリケーションはVM内で実行できる。
VM内で実行されるNFは、一般に仮想化されたネットワーク機能(VNF)と呼ばれる。VM内でNFアプリケーションを実行するプロセス技術は、一般にネットワーク機能仮想化(NFV)と呼ばれる。 -
VM内のコンテナとしてのNF
コンテナは柔軟性と低いソフトウェアオーバーヘッドを提供し、VMは分離と抽象化によって高度なセキュリティとハードウェアからのソフトウェア独立性を提供する。したがって、コンテナとVMは異なる一連のメリットを提供し、互いに補完する。
両方の世界の最良の部分を実現するために、複数のコンテナを単一のVM上で実行できる。コンテナ管理は柔軟性を提供し、VMは全体的なセキュリティ、分離、ハードウェアからのソフトウェア独立性を提供する。あるいは、VMを最適化して全体的な抽象化オーバーヘッドを減らし、コンテナのような軽量の環境を提供して、アプリケーションをホストすることもできる。例えば、KataコンテナはコンテナとVMの両方のメリットを提供する特別なコンテナタイプである。VM(そしてその上で実行されるかもしれないコンテナ)で実行されるNFは、一般にコンテナネットワーク機能(CNF)と呼ばれる。 -
プログラム可能なハードウェア機能としてのNF
伝統的な汎用コンピューティング(GPC)プラットフォームには、CPU、メモリ、ストレージ、ネットワーク機能を含むハードウェアが含まれている。効率的なコンピューティングのために、GPCプラットフォームは専用(プログラム不可能)およびカスタム(プログラム可能)ハードウェアアクセラレータを増強できる。これにより、CPUは特定の一連の計算機能をハードウェアアクセラレータにオフロードできる。専用アクセラレータは、特定の一連の計算機能のオフロードをサポートする。
対照的に、プログラム可能なアクセラレータは、アプリケーションが必要とする計算機能を実装するために動的にプログラムされる(実行時)可能性がある。FPGAとGPUは、ハードウェアにプログラムされる計算機能の一般的な例である。NFはプログラム可能なハードウェアに実装され、パケット処理機能を実現できる。例えば、超高速取引(HFT)などの高スループットと低レイテンシの処理を要求するアプリケーションのために、TCP/IPプロトコルに必要な計算機能は一般にプログラム可能なハードウェア機能として実装される。プログラム可能なハードウェア機能として実装されたNFは、ハードウェアアクセラレーテッドネットワーク機能と呼ぶことができる。
4. 周辺概念と課題
4.1. NFVアーキテクチャの概要 (VNF,NFVI, MANO)
ネットワーク機能仮想化(Network Function Virtualization:NFV)は、従来の専用ハードウェアベースのネットワーク機能を、標準的な汎用サーバー上でソフトウェアとして実装するアプローチ。欧州電気通信標準化機構(ETSI)によって提案されたNFVのアーキテクチャフレームワークは、主に3つの主要コンポーネント(VNF,NFVI, MANO)から構成される。

https://www.netone.co.jp/knowledge-center/blog-column/knowledge_takumi_038/
4.1.1. VNFの概要
VNF(Virtualized Network Function)は、従来ハードウェアとして実装されていたネットワーク機能を仮想化したソフトウェアコンポーネント。
例えば、次のような機能が含まれる。
- ファイアウォール
- ルーター
- ロードバランサー
- NAT(Network Address Translation)
- IDS/IPS(侵入検知/防止システム)
- DPI(Deep Packet Inspection)
- プロキシサーバー
各VNFは、一つもしくは複数の仮想マシンやコンテナ上で実行され、特定のネットワーク機能を提供する。VNFは一般的に「ステートフル」と「ステートレス」に分類される。ステートフルなVNFは接続状態やセッション情報を保持する必要があり、より複雑なメモリ管理や状態同期メカニズムが必要となる。
4.1.2. NFVIの概要
NFVI(NFV Infrastructure)は、NFVを実現するための物理的および仮想的なリソース基盤。
具体的には、以下の要素から構成される。
- 物理リソース:汎用的なサーバー(x86、ARM等)、ストレージ、ネットワーク機器
- 仮想化レイヤー:ハイパーバイザ(KVM、VMware ESXi等)やコンテナ技術(Docker、Kubernetes等)
- 仮想リソース:仮想コンピューティング(vCPU)、仮想ストレージ、仮想ネットワーク
4.1.3. MANOフレームワーク
MANO(Management and Orchestration)は、NFVの管理とオーケストレーションを担当するフレームワーク。ETSIによって標準化されたMANOフレームワークは、以下の主要コンポーネントから構成される。
- VNF Manager (VNFM):個々のVNFのライフサイクル管理(起動、設定、スケーリング、終了など)を担当
- NFV Orchestrator (NFVO):複数のVNFから構成されるサービスの全体的なオーケストレーションを担当
- Virtualized Infrastructure Manager (VIM):NFVIリソースの管理と割り当てを担当(OpenStack、VMware vCloud Director等)
MANOは、これらのコンポーネントを通じて、VNFのデプロイメント、スケーリング、モニタリング、更新などのライフサイクル管理を自動化する。さらに、Service Function Chaining(SFC)を通じて複数のVNFを連携させ、エンドツーエンドのネットワークサービスを構築する機能も提供する。
4.2. NFに求められる性能要件 (スループット、レイテンシ、ジッター等)
ネットワーク機能(NF)には、特にキャリアグレードの環境において厳格な性能要件が課される。これらの要件は、サービス品質(QoS)の保証や、サービスレベル契約(SLA)の遵守のために不可欠である。
4.2.1. スループット要件
スループットは、単位時間あたりに処理できるデータ量を指す。NFには、以下のようなスループット要件がある。
- 高帯域幅:現代のネットワークでは、10Gbps、40Gbps、100Gbps、あるいはさらに高速な回線速度に対応する必要がある。
- パケット処理率:一般に、小さいパケットの処理はより多くのCPUリソースを消費する。NFは、最小サイズのパケット(64バイト)でも高いパケット処理率(Packets Per Second: PPS)を維持する必要がある。
- 同時接続数:特に、ファイアウォールやロードバランサーなどのNFでは、数百万から数千万の同時接続を処理できる能力が求められる。
4.2.2. レイテンシ要件
レイテンシは、パケットがNFを通過するまでにかかる時間。NFのレイテンシ要件は、アプリケーションの特性によって異なる。
- 通常のインターネットトラフィック:数ミリ秒(ms)程度のレイテンシが許容される
- 金融取引:数百マイクロ秒(µs)以下のレイテンシが求められることも
- 5G/TSNなどの超低遅延アプリケーション:数十マイクロ秒以下の厳格なレイテンシが必要
さらに、レイテンシの一貫性も重要である。突発的なレイテンシのスパイクは、アプリケーションのパフォーマンスに重大な影響を与える可能性がある。
4.2.3. ジッター要件
ジッターは、パケット間の到着時間のばらつきを指す。特にリアルタイムアプリケーション(VoIP、ビデオ会議、オンラインゲームなど)では、低ジッターが重要である。
- 音声/ビデオ通信:一般に30ms以下のジッターが望ましい
- 工業用アプリケーション:より厳格なジッター要件(数マイクロ秒レベル)が求められることも
4.2.4. その他の性能要件
- リソース効率:CPU、メモリ、ネットワークI/Oなどのリソースを効率的に使用する能力
- スケーラビリティ:トラフィック増加時に円滑にスケールアウト/スケールインできる能力
- 復元力:ハードウェア障害やソフトウェア障害からの迅速な回復能力
- エネルギー効率:特に大規模デプロイメントでは、消費電力の最適化が重要
これらの性能要件を満たすためには、従来の汎用OSやハイパーバイザの最適化だけでなく、特殊なハードウェアアクセラレーション技術や、NFに特化したソフトウェアスタックの開発が必要となる。
4.3. 従来のOS/ハイパーバイザにおけるネットワーク処理の課題
従来の汎用的なオペレーティングシステム(OS)やハイパーバイザは、ネットワーク機能(NF)のような高性能かつI/O集約型のワークロードに対して最適化されていない。これらのシステムは、多様なアプリケーションをサポートするために柔軟性と抽象化を重視して設計されており、高速なパケット処理に特有の課題を抱えている。
4.3.1. カーネルネットワークスタックのオーバーヘッド
従来のOSカーネル(特にLinux)のネットワークスタックには、以下のようなオーバーヘッドが存在する。
-
コンテキストスイッチング
パケットがネットワークインターフェースから到着すると、割り込みが発生し、カーネル空間からユーザ空間へのコンテキストスイッチが必要になる。これにより、数マイクロ秒のオーバーヘッドが発生する。 -
メモリコピー
パケットデータは、物理NICからDMA転送によりカーネル空間のバッファに転送され、その後、ユーザ空間アプリケーションのバッファに再度コピーされる(ゼロコピーの最適化がない場合)。これらの複数回のメモリコピーは、特に小さいパケットの高速処理において大きなボトルネックとなる。 -
メモリ割り当てとページング
動的なメモリ割り当てと仮想メモリのページングは、予測不可能なレイテンシを引き起こす可能性がある。 -
ロック競合
複数のCPUコアがネットワークスタックの共有リソース(ソケットバッファなど)にアクセスする際に、ロック競合が発生し、パフォーマンスが低下することがある。 -
プロトコルスタックのオーバーヘッド
TCP/IPスタックの処理(チェックサム計算、セグメンテーション、再組み立てなど)は、CPU集約的であり、特に高速ネットワークでボトルネックとなる。
4.3.2. ハイパーバイザ固有の課題
ハイパーバイザを使用した仮想化環境では、さらに次のような課題が追加される。
-
I/O仮想化のオーバーヘッド
仮想マシン(VM)からのI/O操作は、一般的にハイパーバイザによる仲介が必要であり、これにより追加のレイテンシが発生する。 -
エミュレーションオーバーヘッド
従来の仮想ネットワークインターフェース(vNIC)は、物理ハードウェアをエミュレートするため、パフォーマンスが低下する。 -
VMエグジット
VMからのI/O操作は、多くの場合「VMエグジット」を引き起こし、ゲストからホストへの制御の移行が必要になる。これにより、数マイクロ秒から数十マイクロ秒のオーバーヘッドが発生する。 -
メモリオーバーコミット
ハイパーバイザが物理メモリを過剰にコミットしている場合、ページスワッピングが発生し、予測不可能なレイテンシスパイクを引き起こす可能性がある。 -
vCPUスケジューリングの遅延
仮想CPU(vCPU)のスケジューリングの遅延により、パケット処理の遅延が増加する可能性がある。 -
仮想スイッチングのオーバーヘッド
VM間の通信は、多くの場合、仮想スイッチ(vSwitch)を経由する必要があり、これにより追加のソフトウェア処理が必要になる。
4.3.3. NUMA関連の課題
現代のマルチソケットサーバーでは、Non-Uniform Memory Access(NUMA)アーキテクチャが一般的である。NUMAシステムでは、メモリアクセス時間がCPUコアとメモリの物理的な位置関係に依存する。
-
リモートNUMAアクセス
パケット処理がCPUコアとは異なるNUMAノードのメモリにアクセスする場合、アクセス時間が大幅に増加する(ローカルアクセスと比較して2〜3倍)。 -
NUMAアウェアでないスケジューリング
OSまたはハイパーバイザがNUMA最適化を考慮せずにスレッドやVMをスケジューリングすると、クロスNUMAメモリアクセスが増加し、パフォーマンスが低下する。 -
キャッシュの局所性の問題
CPUコア間でのスレッドの移行は、キャッシュの局所性を損ない、特にパケット処理のような高速処理が必要なワークロードで問題となる。
これらの課題は、従来のOS/ハイパーバイザがネットワーク機能のような高性能ワークロードを処理する上での障壁となっている。
5. オペレーティングシステムに関する側面
論文「Operating Systems and Hypervisors for Network Functions」を読み進めていくと、オペレーティングシステムがネットワーク機能(NF)の性能に与える影響の大きさに気づかされる。従来型のOSはビジネスアプリケーションや一般的なワークロード向けに設計されているため、高速パケット処理を必要とするNFには最適化されていない。
NF処理に関わるOSの重要な側面を掘り下げる。
5.1 カーネルバイパス技術
「なぜ通常のOS経由でパケット処理を行うだけではダメなのか?」
Thyagaturu et al. (2022)の研究によれば、従来のカーネル経由のパケット処理パスには複数の深刻なオーバーヘッドが存在する。ユーザースペースとカーネルスペース間の切り替え、複数のバッファコピー操作、パケットごとの割り込み処理などが重なると、高性能なNF実行には致命的な非効率が生じる。

https://ieeexplore.ieee.org/document/9844719
ここで注目すべきなのが「カーネルバイパス技術」という解決策だ。これは文字通り、OSカーネルを「バイパス(迂回)」して、アプリケーションがネットワークハードウェアに直接アクセスできるようにするアプローチである。
カーネルバイパスの採用により得られる主要なメリットは次の通り。
- パケット処理レイテンシの大幅な削減(場合によっては10分の1以下に)
- スループットの飛躍的向上
- 予測可能で一貫したパフォーマンス特性
- CPUオーバーヘッドの大幅な軽減
しかし、この技術にもトレードオフが存在する。カーネルのセキュリティメカニズムを迂回することは潜在的なセキュリティリスクをもたらす可能性があり、また多くの場合、特権モードでの実行を必要とする。さらに、OSの標準機能(ファイアウォールやトラフィック制御など)からの分離も考慮すべき点である。
5.2 ユーザスペース高速パケット処理技術
「実際にはどのような技術でこれを実現するのか?」
業界で広く採用されている代表的な実装に、Data Plane Development Kit (DPDK)とnetmapがある。
5.2.1 Data Plane Development Kit (DPDK)
DPDKは、当初Intelが主導して開発したユーザスペース高速パケット処理フレームワークで、現在はLinux Foundationの管理下にある。

https://hackmd.io/@sohailanjum97/SkWE46ywu
DPDKのポイントは次の通り。
- ユーザスペースでの直接メモリアクセス(DMA)により、カーネルを介さずにNICとアプリケーションが直接データをやり取り
- 専用のPoll Mode Driver (PMD)によるパケット処理(割り込み処理ではなく積極的に状態を確認)
- パケットをバッチ処理することで、個別処理のオーバーヘッドを大幅に削減
- NFVアプリケーション開発に特化した豊富なライブラリセット
- 複数のCPUコアにわたる効率的なパケット分散処理
- ヒュージページ(通常は2MBまたは1GB)を使用して、TLB(Translation Lookaside Buffer)ミスを減少させ、メモリアクセスのパフォーマンスを向上
- NUMAアウェアなメモリアロケーションによるメモリアクセスのレイテンシ最小化
- ロックレスリングバッファを使用して、マルチコア環境でのロック競合を排除
- ゼロコピー技術の採用による、メモリコピーの最小化
実際の性能面では驚くべき結果が報告されている。
- 従来のLinuxネットワークスタックと比較して10倍以上のスループット向上
- サブミリ秒レベルの低レイテンシ処理が可能
- 多様なNICに対応するドライバの提供
しかし、何事にもトレードオフがあるように、DPDKにも課題がある。
- ポーリング方式の採用によるCPU使用率の増加(特にトラフィックが少ない状況で非効率)
- 多くの機能で特権モードでの実行が必要
- ユーザスペースドライバの導入に伴う開発の複雑性と学習曲線の存在
5.2.2 netmap
DPDKと並んで注目すべきもう一つの技術が、カリフォルニア大学で開発されたnetmap。
アプローチが少し異なっており、次のような特徴を持つ。
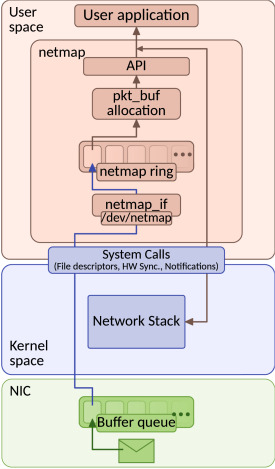
https://www.sciencedirect.com/topics/engineering/network-data-processing
- カーネル内に単純化されたネットワークインターフェースを提供
- ユーザスペースとカーネル間のゼロコピー転送を実現
- メモリマッピング技術を活用してNICバッファへの直接アクセスを可能に
- 標準のソケットAPIとの互換性を維持
個人的に興味深いのは、netmapが以下のような点でDPDKとは異なるアプローチを取っている点。
- 既存のアプリケーションとの互換性を重視
- BSDとLinux両方のプラットフォームで利用可能
- DPDKと比較して軽量な実装とシンプルな設計哲学
もちろん、netmapにも限界はある。
- DPDKほどの広範なハードウェアサポートがない
- 特定のNICアーキテクチャでのパフォーマンス最適化が限定的
NFVシナリオにおいて、DPDKとnetmapはともに標準のカーネルネットワークスタックと比較して大幅なパフォーマンス向上を示している。選択はハードウェアの互換性と具体的なユースケースに依存するが、高性能NFの実装において両者は極めて重要な役割を果たしていると言えそうだ。
5.2.3 AF_XDP (Address Family XDP)
AF_XDPは、Linuxカーネルの一部であるXDP(eXpress Data Path)を活用するソケットファミリである。
これはDPDKやnetmapとは異なるアプローチを取っている。

https://www.minzkn.com/moniwiki/wiki.php/XDP
-
高性能ユーザスペースアクセス
AF_XDPは、XDPフックで処理されたパケットへの効率的なユーザ空間アクセスを提供する。 -
ゼロコピー操作
AF_XDPは、適切に設定された場合、ゼロコピーモードで動作できる。 -
カーネル統合
AF_XDPはLinuxカーネルの一部であるため、最新のLinuxディストリビューションで利用可能。
この技術は、カーネルの一部として動作しながらも、ユーザスペースアプリケーションに高速なパケットアクセスを提供するという点で、完全なカーネルバイパスと従来のカーネルネットワーキングの中間に位置する独自のアプローチだ。
5.3 ポーリング vs 割り込み
「パケットの到着をどう検知するか」
この点について考えると、二つの対照的なアプローチが見えてくる。割り込み駆動型とポーリング駆動型。
5.3.1 割り込み駆動型アプローチ
従来から使われてきた割り込み駆動型パケット処理は、多くの人にとって馴染みのあるモデルと言える。この方式では、パケットがNICに到着すると、ハードウェアが割り込み信号を生成し、CPUの通常作業を中断させて、パケット処理ルーチンに制御を移す。
このアプローチには明確な利点がある。
- アイドル状態(パケットがない時)ではCPUリソースを他のタスクに解放できる
- 低トラフィック状況では電力効率が非常に良い
- ほとんどのOSカーネルでデフォルトの標準的な処理方法として実装されている
しかし、高性能NF処理においては、いくつかの重大な問題が浮上する。
- 高パケットレート環境では「割り込みストーム」が発生し、システム全体が過負荷になる
- パケットごとのコンテキストスイッチによる大きなオーバーヘッド
- システム負荷に応じた予測不能なレイテンシ変動が生じる
5.3.2 ポーリング駆動型アプローチ
対照的に、ポーリングアプローチでは、CPUが継続的かつ積極的にNICのパケットバッファをチェックし続ける。
このアプローチの強みは次の通り。
- 高い予測可能性と一貫したレイテンシ(ジッターの大幅な削減)
- 割り込み処理に関連するオーバーヘッドの完全な排除
- DPDKやその他の高性能パケット処理フレームワークで広く採用されている手法
もちろん、デメリットも存在する。
- アイドル状態(パケットが少ない時)でもCPUを常に占有する
- その結果として電力消費が増加する
- 専有コアが必要なため、他のタスクに影響を与える可能性がある
実際のパフォーマンス差はどれほどか?Nakajima et al. (2018)による研究では、ポーリングベースのアプローチは小さいパケットサイズ(64バイト)で5.7倍、大きいパケットサイズ(1500バイト)で2.8倍のパフォーマンス向上を示した。この差は驚くべきものだが、すべての環境で常にポーリングが最適というわけではない。
現在の研究では、変動するトラフィックパターンに対応するため、状況に応じて割り込みとポーリングを切り替える適応型のハイブリッドアプローチも注目されている。これにより、トラフィックが少ない時は電力効率を優先し、トラフィックが増加した時はレイテンシとスループットを優先するという、賢い切り替えが可能になる。えらい。
5.4 CPUアフィニティとコア分離
「どのCPUコアでこの処理を実行すべきか?」
マルチコアプロセッサが当たり前となった現在、この質問の重要性はますます高まっている。
5.4.1 CPUアフィニティ
CPUアフィニティとは、特定のプロセスやスレッドを特定のCPUコアに「固定」する技術である。一見単純な概念だが、NF処理において影響が大きい。

https://poweradm.com/set-cpu-affinity-powershell/
なぜCPUアフィニティがNFで重要なのか。
-
キャッシュローカリティの向上
同じコアで同じタスクを続けて実行することで、CPUキャッシュヒット率が劇的に向上する。これはパケット処理のような繰り返し作業で特に効果的。 -
プロセス間のコンテキストスイッチの減少
特定のコアに特定のタスクを固定することで、OSのスケジューラによる頻繁なタスク切り替えを防ぐことができる。 -
NUMAアーキテクチャでのメモリアクセス最適化
プロセスをメモリ位置に「近い」コアで実行することで、メモリアクセスのレイテンシを最小限に抑えられる。
実際の実装方法としては次のようなものがある。
- Linuxの
tasksetコマンドやsched_setaffinity()システムコールを使用した明示的な割り当て - DPDKの
--lcoresパラメータによる細かなコア割り当て制御 - NUMAトポロジーを分析し、最適なコア割り当てを自動的に行う高度なツール
5.4.2 コア分離
CPUアフィニティをさらに一歩進めたのが「コア分離」というアプローチだ。これは特定のCPUコアをOSのスケジューラから完全に除外し、NFアプリケーション専用にするという徹底した方法である。

https://chronicle.software/chronicle-tune-your-cpu/
実際にこれを設定する方法には以下のようなものがある。
- Linuxカーネルのブートパラメータ
isolcpusを使用する - RedHatなどが提供する
tunedプロファイルやcpu-partitioningプロファイルを適用する - リアルタイムスケジューリングポリシーを特定のプロセスに適用する
この徹底したアプローチによる利点は明確。
- 他のシステムプロセスからの干渉が完全に排除される
- 高い予測可能性とパフォーマンスの一貫性が得られる
- 決定論的なレイテンシプロファイル(重要な通信サービスに不可欠)
適切なコア分離とCPUアフィニティの設定だけで、NFの処理性能が最大30%向上するという結果が報告されている。特に、NUMA最適化と組み合わせると、その効果はさらに大きくなる。つまり、単に高性能なハードウェアを用意するだけでなく、それをいかに「賢く使うか」が重要と言える。えらい。
5.5 メモリ管理の最適化 (HugePagesなど)
「なぜメモリ管理がネットワーク機能に重要なのか?」
パケット処理には膨大なメモリアクセスが伴う。一般的なデータセンターの10Gbpsリンクでさえ、1秒間に約1400万パケットが流れる可能性があり、それぞれにメモリ操作が必要となる。
5.5.1 HugePages
普段あまり意識することのない、OSの低レベルなメモリ管理に関わる機能。
通常、LinuxなどのOSは標準で4KBの小さなページサイズでメモリを管理する。しかしHugePagesを使うと、2MBや場合によっては1GBという巨大なページサイズを使用できるようになる。

https://haryachyy.wordpress.com/2019/04/17/learning-dpdk-huge-pages/
これがもたらす利点には次のようなものが考えられる。
-
TLBミスの劇的な減少
Translation Lookaside Buffer(TLB)は仮想アドレスから物理アドレスへの変換をキャッシュする。ページサイズが大きいほど、同じメモリ量をカバーするために必要なTLBエントリが少なくなる。 -
ページテーブルウォークのオーバーヘッド削減
TLBミスが発生した場合のページテーブル検索時間が大幅に短縮される。 -
全体的なメモリ管理オーバーヘッドの低減
システム全体で管理するページ数が減少する。
NFアプリケーションでの具体的な効果は次の通り。
- アドレス変換に関連するレイテンシが大幅に削減される
- NICAからメモリへのDMA操作効率が向上する
- 大規模なパケットバッファを効率的に管理できるようになる
5.5.2 NUMAアウェアメモリ割り当て
重要なのが、マルチプロセッサシステムでのメモリ割り当て方法。現代のサーバーでは、Non-Uniform Memory Access (NUMA)アーキテクチャが一般的である。これは、メモリアクセスのレイテンシがCPUソケットによって異なることを意味する。
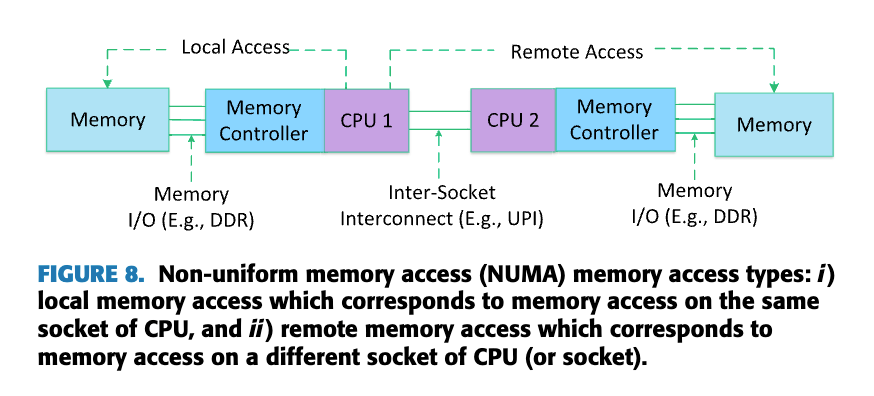
https://ieeexplore.ieee.org/document/9844719
論文を読むとNUMAアウェアなメモリ割り当ての重要性を次のように理解できる。
- プロセスが実行されるCPUソケットに「近い」メモリを使用することで、アクセス速度を最大化する
- ソケット間をまたぐメモリアクセス(遅い)を最小限に抑える
- I/OデバイスとCPUとメモリの位置関係を考慮して最適配置を行う
Sieber et al. (2017)による研究によれば、彼らはNUMAを考慮しないメモリ割り当てが、ソケット間でのパケットコピーを引き起こし、CPU使用率を増加させるだけでなく、大きなパフォーマンスペナルティをもたらすことを明確に示している。
実装方法としては以下のようなものがある。
-
numactlコマンドやmbind()システムコールによる明示的な制御 - DPDKが提供するNUMA対応メモリ割り当て機能の活用
- アプリケーション固有のカスタムNUMAポリシーの実装
5.5.3 RDMA (Remote Direct Memory Access)
RDMA(Remote Direct Memory Access)は、リモートコンピュータのメモリに直接アクセスするためのハードウェア機構であり、高速ネットワーク環境で低レイテンシのデータ転送を実現する技術。

https://elements.tv/blog/an-introduction-to-rdma-remote-direct-memory-access/
RDMAには以下のような特徴がある。
-
カーネルバイパス
RDMAは、リモートノードのメモリに直接アクセスし、OSカーネルを介さずにデータを転送する。 -
ゼロコピーデータ転送
RDMAは、メモリコピーのオーバーヘッドなしで、あるシステムから別のシステムにデータを直接転送できる。 -
CPU使用率の低減
RDMAは、データ転送タスクをNICにオフロードするため、CPUリソースを解放する。
これらのメモリ最適化技術を組み合わせることで、メモリアクセスがボトルネックとなる状況を大幅に緩和し、10Gbps、40Gbps、さらには100Gbpsという高速ネットワークでも効率的に動作するNF実装が可能になる。
5.6 I/O集約型タスクのためのスケジューリング戦略
ここまでCPUとメモリの最適化について見てきたが、NF処理のようなI/O集約型タスクには、さらに特別なスケジューリング戦略が必要となる。通常のデスクトップアプリケーションとは異なり、NFアプリケーションはミリ秒単位ではなく、マイクロ秒単位の処理レイテンシが要求されることが多い。
5.6.1 リアルタイムスケジューラ
標準的なLinuxスケジューラは、公平性と全体のスループットを最適化するように設計されている。しかし、NFアプリケーションにとって重要なのは「予測可能性」と「低レイテンシ」だ。そこで登場するのがリアルタイムスケジューリングポリシーである。
リアルタイムスケジューラが提供する主な機能は次の通り。
-
優先度ベースのプリエンプション
高優先度のNFタスクは、他の低優先度タスクをいつでも中断して実行できる -
固定された実行時間枠
タスクが確実に一定時間内に完了するよう保証する -
他のシステムタスクに対する優先的な実行
システムの他の部分より優先してNFタスクを実行する

https://www.embedded.com/comparing-real-time-scheduling-on-the-linux-kernel-and-an-rtos/
LinuxではSCHED_FIFO(First In, First Out)やSCHED_RR(Round Robin)といったリアルタイムスケジューリングポリシーが提供されており、これらを利用することでNFタスクに決定論的な実行特性を与えることができる。この「決定論性」は、通信システムにおいて極めて重要な要素だ。
5.6.2 I/Oスケジューリングの最適化
NICからのデータ受信と処理のスケジューリングも最適化する必要がある。
I/O集約型NFには、以下のような効率的なI/Oスケジューリング技術を適用できる。
-
マルチキューNICのRSS(Receive Side Scaling)
受信パケットを複数のCPUコアに分散させる技術 -
割り込みスレッドのアフィニティ設定
特定の割り込みを特定のCPUコアに割り当てる -
ブロックI/Oスケジューラの調整
ストレージI/Oが関わるNFVシナリオでの最適化 -
VMエグジット最小化
仮想環境でのコンテキストスイッチを減らすためのハイパーバイザスケジューリング最適化
Nakajima et al. (2018)による研究によれば、彼らはI/O仮想化のオーバーヘッドを軽減するために、仮想キューベースのポーリングモードドライバを提案した。この手法により、CPUトランジション、割り込み処理、アドレス変換のオーバーヘッドが大幅に削減された。
5.6.3 NUMA対応スケジューリング
現代のマルチソケットサーバーでは、スケジューリングとNUMAトポロジーの関係も考慮すべき重要な要素。
NUMA対応スケジューリングでは以下のような最適化が行われる。
-
ソケット内のコアへのタスクの局所化
タスクの移動を最小限に抑え、キャッシュ局所性を維持する -
NICからCPUまでのデータパスの最小化
パケットが物理的に通る経路を最短にする -
メモリアクセスパターンに基づくタスク配置
タスクが頻繁にアクセスするメモリの位置に基づいて配置を決定する
Wang et al. (2017)による研究によれば、DPDKベースのパイプラインNFに対するスレッド配置戦略が実装された。彼らは「Locality First Mapping」という手法を用いて、リモートソケットメモリアクセスによるパケット処理レイテンシを大幅に削減することに成功している。
これらのスケジューリング戦略を組み合わせることで、I/O集約型のNFアプリケーションの性能を飛躍的に向上させることができる。通常のアプリケーション向けのデフォルト設定では得られない性能特性を実現するためには、このようなきめ細かな最適化が不可欠である。
5.7 Linuxカーネルネットワークスタックの改善と限界
5.7.1 Linuxカーネル改善
Linuxカーネルは、NFに関連する以下の改善を導入している。
-
XDP (eXpress Data Path)
カーネル内の初期段階でのパケット処理。NICドライバレベルで動作し、パケットがカーネルの深い層に到達する前に高速処理が可能。 -
AF_XDP
ユーザスペースアプリケーションのためのXDPインターフェース。前述のように、XDPの利点をユーザスペースから活用できる。 -
eBPF (extended Berkeley Packet Filter)
カーネル内のプログラム可能なパケット処理。Just-In-Timeコンパイルと検証メカニズムによって安全かつ高速な実行を実現。 -
SO_BUSY_POLLソケットオプション
ハイブリッドポーリングモデルを提供し、低レイテンシと低CPU使用率のバランスを取る。 -
マルチキューネットワークスタック
パケット処理をコア間で効率的に分散し、スケーラビリティを向上。
これらの改善は、完全なカーネルバイパスソリューションに近いパフォーマンスを提供しつつ、標準のOSセキュリティモデルを維持することを目指している。
5.7.2 Linuxカーネルネットワークスタックの限界
しかし、Linuxカーネルネットワークスタックには依然として以下の制限がある。
-
汎用性と専門性のトレードオフ
様々なワークロードとハードウェアに対応するために設計されているため、特定のNFシナリオに最適化されていない。 -
OSカーネルの割り込み処理オーバーヘッド
高速パケット処理において依然として重要なボトルネック。 -
ユーザ空間とカーネル空間の間のコンテキストスイッチ
特に小さなパケットを高レートで処理する際に問題となる。 -
複雑なプロトコルスタックによる処理レイテンシ
フルスタック処理は多くのNFアプリケーションには過剰である。 -
完全なカーネルバイパスソリューションと比較した場合のパフォーマンスギャップ
XDPなどの技術でも、DPDKのような完全バイパスには及ばないケースが多い。
XDPなどの技術は、これらの制限の一部を緩和しているが、最高のパフォーマンスを必要とするシナリオでは、DPDKなどの完全なバイパスソリューションが依然として優位性を持つ。
5.8 NF向けに特化したOSまたはOS改修の研究
5.8.1 特化型OSアプローチ
研究コミュニティは、NFに最適化された特化型OSを提案している。

https://unikraft.org/docs/concepts
-
Unikraft - NFアプリケーション向けの軽量なユニカーネルベースアプローチ(Kuenzer et al., 2019)
- 単一アドレス空間
- 完全モジュール設計
- 単一保護レベル
- 不要なカーネルコンポーネントを排除するための静的リンク

https://marksilberstein.com/wp-content/uploads/2020/02/hotos.pdf
-
OmniX - accelerator中心のOS(Silberstein, 2021)
- 標準OS抽象化の拡張
- 複数システムプロセッサ(CPU、GPU、FPGA)にわたる抽象化
- 効率的なNear-X加速ユニット間通信
5.8.2 OS修正アプローチ
既存のOSに対する修正も研究されている。
-
パラバーチャリゼーション - 仮想環境での性能向上(Eiras et al., 2022)
- ハイパーバイザと直接通信するためのソフトウェア層
- ハードウェア機能の選択的エミュレーション
-
ウルトラバイザー - 障害耐性強化(Landis et al., 2016)
- 論理的または仮想的なホストシステムパーティショニング
- 特別なインフラストラクチャパーティションによるリソース管理
-
エネルギーモニタリングとコントロール
- 仮想化環境における電力管理フレームワーク
- ホストレベルとゲストレベルの管理サブシステム
これらの特化型OSと修正アプローチは、標準的な汎用OSと比較して、NFアプリケーションのパフォーマンス、予測可能性、および効率性の大幅な向上を示している。
6. ハイパーバイザに関する側面
「そもそもなぜネットワーク機能を仮想化環境で実行する必要があるのか?」
もう一つの重要な要素であるハイパーバイザについて見ていく。
実際、多くの通信事業者やデータセンターでは、複数のネットワーク機能を効率的に展開するために仮想化技術を採用している。これにより、物理ハードウェアの利用効率が上がり、迅速な展開と柔軟なスケーリングが可能になる。しかし仮想化には常にオーバーヘッドというトレードオフが存在する。
6.1 ハイパーバイザの種類 (Type 1 vs Type 2) とNFへの影響
「すべてのハイパーバイザが同じではない」
大きく分けて2つのタイプのハイパーバイザが存在する。うえのほうで基本概念はメモ済であるが、NFを考慮に含めた整理をする。
6.1.1 Type 1 (ベアメタル) ハイパーバイザ
Type 1ハイパーバイザは、ハードウェア上で直接実行される「ベアメタル」アーキテクチャを採用している。

https://www.bdrsuite.com/blog/type-1-and-type-2-hypervisor/
具体的には次の通りの特徴を持つ。
- KVM、Xen、VMware ESXi、Microsoft Hyper-Vなどが該当する
- ハードウェアリソースへの直接アクセスが可能
- 低オーバーヘッド設計を特徴とする
これらがNFに与える影響として次のようなものが考えられる。
- 低レイテンシのパケット処理が可能(物理ハードウェアに近い性能)
- I/Oパフォーマンスが予測可能で一貫性がある
- リソース利用効率が高い
Type 1ハイパーバイザは物理ハードウェアとより「近い」関係にあるため、パフォーマンスクリティカルなNF処理に適している。
6.1.2 Type 2 (ホスト型) ハイパーバイザ
Type 2ハイパーバイザは通常のOSの上で動作する「ホスト型」アーキテクチャを採用している。

https://www.bdrsuite.com/blog/type-1-and-type-2-hypervisor/
具体的には次の通りの特徴を持つ。
- VirtualBox、VMware Workstation、QEMUなどが代表的
- ホストOSを介してハードウェアにアクセスする必要がある
- 展開と管理が柔軟な反面、パフォーマンスに影響が出る
NFへの影響としては次のようなものが考えられる。
- 追加のレイヤーによるパフォーマンスオーバーヘッドが顕著
- レイテンシの予測可能性が低い傾向がある
- 開発やテスト環境として有用だが、本番環境には通常不向き
研究結果によれば、NFV環境では基本的にType 1ハイパーバイザが推奨されるが、特定の最適化技術(パラバーチャリゼーションやSR-IOVなど)を利用することで、Type 2ハイパーバイザでも十分な性能が得られるケースもあるという。
6.2 仮想スイッチング
ハイパーバイザ環境でネットワーク機能を実装する際に避けて通れないのが「仮想スイッチング」の問題。
「物理的なネットワークスイッチの代わりに、ソフトウェアでパケットの転送を行う」ことはかなり複雑な課題を含んでいる。
6.2.1 Open vSwitch (OVS)
仮想スイッチの世界で最も広く採用されているのが「Open vSwitch (OVS)」。
これは単なるスイッチではなく、多層分散型の仮想スイッチングプラットフォームとして設計されている。

https://ja.m.wikipedia.org/wiki/Open_vSwitch
OVSの主要機能は次の通り。
-
SDNプロトコル対応
OpenFlowやOVSDBといったSDN(Software-Defined Networking)プロトコルをサポートし、プログラマブルなネットワーク制御を可能にする -
ハードウェアオフロード機能
特定の処理を対応するNICにオフロードすることでパフォーマンスを向上 -
ステートフルファイアウォール機能
接続状態を追跡する高度なフィルタリング機能 -
QoSポリシーの実装
きめ細かなトラフィック制御と優先度付けが可能
パフォーマンス面での工夫も多くなされている。
-
DPDK統合
データプレーンの高速化のためにDPDKを組み込み、パケット処理をカーネルからユーザースペースに移動 -
フロー管理の最適化
頻繁に使われるフローパスをキャッシュすることでルックアップを高速化 -
NUMA対応設計
マルチソケットサーバーにおけるキャッシュ局所性の向上
OVSは今日、マルチテナント環境でのNF展開におけるデファクトスタンダードとなっている。しかし、最適なパフォーマンスを得るには適切な構成とチューニングが欠かせない。特にDPDKとの統合は劇的なパフォーマンス向上をもたらすが、設定の複雑さも増加する点に注意が必要。
6.2.2 VPP (Vector Packet Processing)
VPPはもともとCiscoが開発し、現在はFD.io(Fast Data - Input/Output)プロジェクトの一部として発展している。

https://codilime.com/blog/why-vector-packet-processing-is-worth-your-time/
VPPの特徴は次の通り。
-
パケットのバッチ(ベクトル)処理
個々のパケットではなく、複数のパケットをまとめて処理することでパイプライン効率を大幅に向上 -
モジュラーアーキテクチャ
プラグイン形式での機能拡張が可能 -
レイヤー2からレイヤー4までの豊富な機能セット
フル機能の仮想ルーターとして使用可能
パフォーマンス面での特徴は次の通り。
-
キャッシュ効率を最大化したパケット処理
CPUキャッシュヒット率を高める設計 -
DPDKとの密な統合
高速I/Oの恩恵を最大限に享受 -
ポールモードドライバの積極的活用
低レイテンシを実現
実際のパフォーマンス比較では、VPPはOVSよりも低レイテンシと高いパケット処理レートを示すケースが多い。しかし、展開の複雑さとSDNエコシステムとの統合度の低さが主なトレードオフとなっている。つまり、純粋なパフォーマンスを追求するならVPPが優れているが、管理のしやすさや既存のSDNコントローラとの統合を重視するならOVSが適しているケースが多い。
6.2.3 その他の仮想スイッチ
仮想スイッチの世界は多様化しており、他にも注目すべきソリューションがいくつか存在する。
-
Snabb Switch
LuaJITベースの高速ネットワークスイッチで、特に通信事業者向けのNFV用途に最適化されている。ユーザースペース設計が特徴。 -
Lagopus
マルチコアCPUを最大限に活用するように設計されたソフトウェアスイッチ。DPDK統合とOpenFlowのフル対応が特徴。 -
Microsoft VFP (Virtual Filtering Platform)
Windows Hyper-Vネットワーキング向けに開発された仮想スイッチ。Azure等のMicrosoftクラウドサービスで広く使用され、SDNポリシー実施とハードウェアオフロード機能に特化している。
これらの仮想スイッチはそれぞれ異なる強みと弱点を持っている。例えば、テレコム環境では低レイテンシが最重要であるためVPPやSnabbが選ばれることが多い一方、クラウド環境ではOVSの管理性とエコシステム統合が重要視される傾向がある。
6.3 I/O仮想化技術
「仮想マシンがどのようにして物理ネットワークカードと通信するのか?」
仮想環境でネットワーク機能を実行する際の最大の課題の一つが、I/Oデバイス(特にNIC)へのアクセスをいかに効率化するかという点だ。いくつかの異なるアプローチがあると整理できる。
6.3.1 エミュレーション
最も基本的なI/O仮想化の形態は「エミュレーション」。これは、ソフトウェアでハードウェアデバイスの振る舞いを模倣する方法である。

https://www.redhat.com/ja/blog/virtqueues-and-virtio-ring-how-data-travels
代表的な例としては次のようなものがある。
- QEMUによる仮想デバイス(virtio-netやe1000など)
- 各種の仮想NICとデバイスドライバの組み合わせ
このアプローチの特徴は次の通り。
-
広範なハードウェア互換性
ほぼすべてのハードウェアデバイスをソフトウェアで再現できる -
ゲストOSの修正不要
標準的なドライバで動作するため、特別な準備が不要 -
分離性と移行の容易さ
ハードウェアの詳細から完全に抽象化されているため、VM移行が容易
しかし、当然ながら制限もある。
-
高いCPUオーバーヘッド
すべての操作をソフトウェアでエミュレートするため、大きなCPU負荷がかかる -
レイテンシの増加
実デバイスと比較して応答時間が著しく長くなる -
スループットの制限
高速ネットワークでのパケット処理にボトルネックとなる
NFVのコンテキストでは、エミュレーションは最も柔軟性が高いものの、パフォーマンスが最も低い選択肢だと言える。10Gbps以上のネットワーク環境ではほぼ常に不十分なパフォーマンスしか得られない。
6.3.2 準仮想化 (Para-virtualization: VirtIOなど)
エミュレーションの限界を克服するために開発されたのが「準仮想化(Para-virtualization)」。これは、ゲスト自身が仮想環境で動作していることを認識した上で、ゲストOSとハイパーバイザが協調して動作するための特別なインターフェースを提供するアプローチ。
主要な準仮想化技術は次の通り。
-
VirtIO
LinuxとKVMをはじめとする多くの環境で採用されている標準的な準仮想化インターフェース

https://repositorio.uam.es/bitstream/handle/10486/674401/moreno_martinez_victor.pdf
-
VMware VMXnet
VMware環境に特化した準仮想化NICドライバ -
Xen PV drivers
Xenハイパーバイザ向けの準仮想化ドライバセット
準仮想化の主な特徴は次の通り。
-
エミュレーションよりも低いオーバーヘッド
ハードウェアの完全な模倣ではなく、効率的なインターフェースを提供 -
共有メモリによる効率的な通信
ゲストとハイパーバイザ間で直接メモリを共有することでデータ転送を効率化 -
ゲストドライバの変更が必要
標準のデバイスドライバではなく、専用のドライバが必要
Nakajima et al. (2018)の研究によれば、準仮想化アプローチの最適化により、仮想環境でのI/Oパフォーマンスが大幅に向上する可能性が示されている。彼らはPMD(Poll Mode Driver)ベースの手法を提案し、準仮想化環境におけるオーバーヘッドを削減することに成功した。
6.3.3 直接割り当て (Direct Assignment: Passthrough, SR-IOV)
最高のI/Oパフォーマンスを実現するために、より直接的なアプローチも開発されている。
a) デバイスパススルー

https://xtech.nikkei.com/it/article/COLUMN/20110726/362841/
「パススルー」は、物理デバイスを直接VMに割り当てる技術。
- Intel VT-d / AMD-Vi技術を活用して、VMが物理デバイスに直接アクセスできるようにする
- ハイパーバイザによる介入をほぼ完全に排除する
- ほぼネイティブに近いI/Oパフォーマンスを実現する
しかし、このアプローチには制限もある。
- デバイスを複数のVMで共有することができない(1つの物理デバイスは1つのVMにしか割り当てられない)
- ライブマイグレーション(実行中のVM移行)が著しく複雑になる、または不可能になる
- 利用可能な物理デバイスの数に制限される
b) Single Root I/O Virtualization (SR-IOV)
上記の制限を克服するために開発されたのが「SR-IOV」。これは、PCIeの標準化された拡張機能で、1つの物理デバイスを複数の「仮想機能(VF)」に分割する。

https://ieeexplore.ieee.org/document/9844719
SR-IOVのの主な特徴は次の通り。
- ハードウェアレベルでの分離を実現し、セキュリティを維持
- 各VMに専用のVFを割り当て、他のVMからの干渉を防ぐ
- ハイパーバイザの関与を最小限に抑えることでオーバーヘッドを削減
SR-IOVの主な利点は次の通り。
- ネイティブに近いパフォーマンス(パススルーとほぼ同等)
- 複数のVMによるリソース共有が可能
- 各種NIC、ストレージコントローラー、GPUなど様々なデバイスでサポート
しかし、課題も存在する。
- ハードウェア側のSR-IOVサポートが必要(全てのデバイスがサポートしているわけではない)
- ライブマイグレーションのサポートが限定的または複雑
- VFの数が固定されており、柔軟な再分配が困難
Challa et al. (2021)の調査によれば、SR-IOVは高パフォーマンスなI/O操作において、ほぼネイティブレベルのI/Oパフォーマンスを提供し、NFアプリケーションに最適な選択肢となる場合が多い。実際、多くのテレコム事業者やクラウドプロバイダーは、NFのための標準的なI/O仮想化技術としてSR-IOVを採用している。
6.4 ハイパーバイザの高度なメモリ管理技術
現代のハイパーバイザは複数の高度なメモリ管理技術を実装しており、これらはNFの性能に直接影響を与える。
6.4.1 SLAT (Second-Level Address Translation)
6.4.1.1 SLATとは何か
SLAT(Second-Level Address Translation)は、ハードウェア支援型の仮想化技術で、仮想マシン(VM)のメモリアドレス変換を効率化する。Intel®では「EPT (Extended Page Tables)」、AMDでは「Nested Page Tables」と呼ばれることもある。
従来の仮想化環境では、ゲストOSの仮想アドレスからホストの物理アドレスへの変換が複雑で非効率的だった。VMがメモリにアクセスするたびに、ハイパーバイザーが介入して変換を行う必要があり、これが大きなオーバーヘッドを生じさせていた。
6.4.1.2 SLATの仕組み
SLATは2段階のアドレス変換を実装する。
- ゲスト仮想アドレス → ゲスト物理アドレス:ゲストOS内のページテーブルによる変換
- ゲスト物理アドレス → ホスト物理アドレス::ハードウェア支援によるEPT/NPTを使用した変換
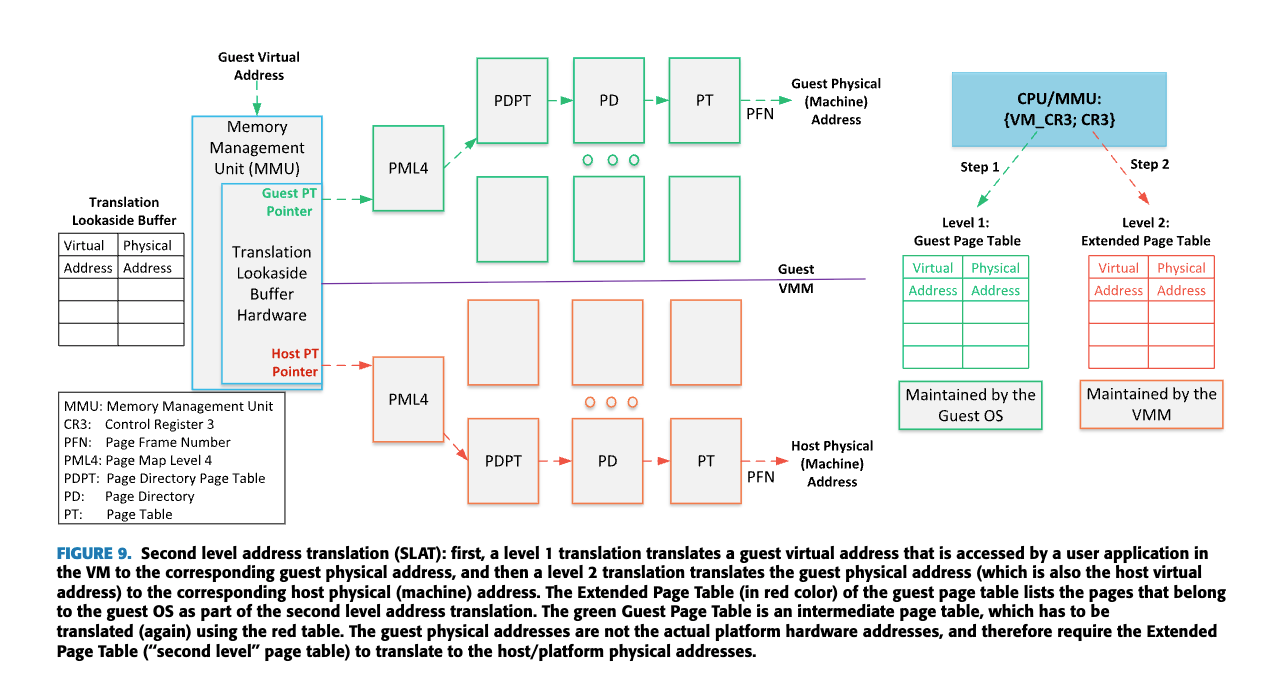
https://ieeexplore.ieee.org/document/9844719
この2段階の変換がハードウェアレベルで行われることで、ハイパーバイザーの介入が大幅に減少し、VM exit(仮想マシンからハイパーバイザーへの制御移譲)の頻度が減る。
6.4.1.3 NF仮想化におけるSLATの重要性
NFアプリケーションは以下の理由からSLATの恩恵を特に受ける。
-
高頻度のメモリアクセス
パケット処理では大量のメモリアクセスが発生し、アドレス変換のオーバーヘッドが積み重なる -
レイテンシの低減
ハイパーバイザの介入減少により、パケット処理のレイテンシが低減する -
TLBの効率向上
アドレス変換のキャッシュであるTLB(Translation Lookaside Buffer)の有効活用が可能になる
6.4.1.4 SLATの課題
ただし、SLATにも次のような課題がある。
-
TLBミス時のコスト増加
TLBミスが発生した場合、2レベルのページテーブルを歩く必要があり、単一レベルより時間がかかることがある -
メモリオーバーヘッド
追加のページテーブル構造を維持するために余分なメモリが必要
とはいえ、これらの課題は、ハイパーバイザの介入削減による大きなパフォーマンス向上によって相殺されることが多い。NF開発者はHugePagesのようなテクニックを使ってTLBミスを減らすことで、SLATの効率をさらに高めることができる。
6.4.2 I/O MEMORY MANAGEMENT UNIT (IOMMU)
6.4.2.1 IOMMUとは何か
IOMMUは、I/Oデバイス(NICなど)がシステムメモリにアクセスする方法を管理するハードウェアコンポーネント。
Intel®ではVT-d (Virtualization Technology for Directed I/O)、AMDではAMD-Viなどの名称で実装されている。

https://www.wikiwand.com/en/articles/Input–output_memory_management_unit
6.4.2.2 IOMMUの仕組み
IOMMUは以下の主要機能を提供する。
-
DMAリマッピング
I/Oデバイスの仮想アドレスを物理アドレスに変換する -
割り込みリマッピング
デバイス割り込みを適切なCPUやVMにルーティングする -
アクセス保護
許可されていないメモリ領域へのアクセスを防止する
IOMMUは独自のページテーブルを維持し、デバイスからのリクエストに基づいてアドレス変換を行う。これはCPUのMMU(Memory Management Unit)に類似した役割だが、I/Oデバイス用に特化している。
6.4.2.3 NF仮想化におけるIOMMUの重要性
NF仮想化においてIOMMUが重要な理由は以下の通り。
-
安全なデバイス割り当て
VMに物理NICを安全に直接割り当てることが可能になる(SR-IOVなど) -
DMA保護
悪意のあるデバイスがシステムメモリを破壊するリスクを軽減する -
パフォーマンス向上
仮想化環境でのI/Oパフォーマンスを向上させる
特に、SR-IOV(Single Root I/O Virtualization)技術を使用する場合、IOMMUは各Virtual Function(VF)が割り当てられたVMのメモリ領域のみにアクセスするよう保証するために不可欠だ。
6.4.2.4 IOMMUの課題
IOMMUの主な課題は以下の通り。
-
レイテンシオーバーヘッド
アドレス変換によって追加のレイテンシが発生することがある -
TLBミスのコスト
IOTLB(I/O Translation Lookaside Buffer)ミスが発生すると、パフォーマンスが低下する -
設定の複雑さ
適切に構成するには専門知識が必要
これらの課題にもかかわらず、IOMMUはNF仮想化におけるセキュリティとパフォーマンスのバランスを取るために必須の技術となっている。
6.4.3 SHARED VIRTUAL MEMORY (SVM)
6.4.3.1 SVMとは何か
SVM(Shared Virtual Memory)は、CPUとI/Oデバイス間でメモリビューを統一する技術。従来、CPUとI/Oデバイスは異なるアドレス空間を使用していたため、データ転送には複雑な調整が必要だったが、SVMはこの問題を解決し、両者が同じ仮想アドレス空間を参照できるようにする。
6.4.3.2 SVMの仕組み
SVMの核心は、CPUのMMUとIOMMUを協調させることにある。

https://ieeexplore.ieee.org/document/9844719
- 統一アドレス空間:CPUとI/Oデバイスが同じ仮想アドレス空間を共有する
- ページテーブル共有:CPUとIOMMUが同じページテーブルまたは同期されたページテーブルを使用する
- PASID (Process Address Space ID):デバイスがアクセスするプロセスコンテキストを識別するために使用される
SVMでは、アプリケーションが割り当てたメモリの仮想アドレスを直接I/Oデバイスに渡すことができ、デバイスはCPUと同じアドレス変換機構を通じてそのメモリにアクセスする。
6.4.3.3 NF仮想化におけるSVMの重要性
SVMはNF仮想化に以下の利点をもたらす。
-
ゼロコピーデータ転送
バッファのコピーや変換が不要になり、パケット処理効率が大幅に向上する -
プログラミングモデルの簡素化
開発者はアドレス変換やバッファ管理の複雑さを気にする必要がなくなる -
レイテンシの削減
メモリコピー操作の排除により、パケット処理レイテンシが低減する -
キャッシュコヒーレンシの改善
CPUとデバイス間でキャッシュ一貫性が維持されやすくなる
6.4.3.4 SVMと仮想化
SVMは仮想化環境においても機能する。IOMMUとSLATが協調して動作することで、ゲストVMのアプリケーションが割り当てたメモリの仮想アドレスをI/Oデバイスが直接使用できるようになる。この場合、vIOMMU(仮想IOMMU)がゲストVMとI/Oデバイス間の橋渡しをする。
6.4.3.5 SVMの課題
SVMの主な課題は以下の通り。
-
ハードウェアサポートの必要性
比較的新しい技術であり、すべてのハードウェアでサポートされているわけではない -
複雑な実装
特にレガシーシステムとの統合が難しい場合がある -
キャッシュコヒーレンシのオーバーヘッド
デバイス間のキャッシュ一貫性を維持するためのオーバーヘッドが発生する可能性がある
6.5 仮想マシン vs コンテナ for NFs
「仮想マシン(VM)を使うべきか、それともコンテナを使うべきか?」
両者には大きな違いがあり、それぞれに長所と短所がある。
6.5.1 仮想マシン(VM)ベースのNF
まず、従来のアプローチとも言える「仮想マシン」ベースのNF実装。
VMの本質的な特徴は次の通り。
- それぞれのVMが完全に分離された環境で動作し、独自のOSカーネルを持つ
- ハードウェアからの広範な抽象化レイヤーを提供
- 物理サーバーの完全な仮想表現として機能
これがNF展開にもたらす利点は次の通り。
-
強力な分離
VMは本質的に互いに完全に隔離されており、セキュリティ境界が明確 -
異なるOS環境の実行能力
Windows、Linux、FreeBSDなど異なるOSを必要とするNFを同じホスト上で実行可能 -
成熟した管理ツールエコシステム
VMwareのvSphereやOpenStackなど、長年にわたって発展した堅牢な管理ツールが利用可能
一方、無視できない欠点も存在する。
-
大きなメモリフットプリント
各VMは独自のOSカーネルを実行するため、かなりのメモリオーバーヘッドが発生 -
起動時間の長さ
完全なOSブートプロセスが必要なため、起動に数十秒から数分かかることも -
抽象化オーバーヘッド
ハードウェア仮想化による性能低下(特に最適化なしの場合)
6.5.2 コンテナベースのNF
対照的に、近年急速に普及している「コンテナ」ベースのアプローチを見てみる。
コンテナの基本的特徴は次の通り。
- 軽量な分離技術を使用し、ホストOSのカーネルを共有
- アプリケーションとその依存関係だけをパッケージ化
- ホストシステムリソースへの効率的なアクセスを提供
NF展開における利点は次の通り。
-
高速な起動時間
通常は数秒以内、場合によっては数百ミリ秒単位で起動可能 -
低メモリオーバーヘッド
OSカーネルが共有されるため、リソース効率が高い -
簡素化されたデプロイメントとオーケストレーション
KubernetesやDockerなどのツールにより、展開と管理が容易
しかし、コンテナにも重要な制約がある。
-
限定的な分離
カーネルが共有されるため、VMほどの強固な分離は提供できない -
ホストOSカーネルへの依存
特定のカーネル機能や最新カーネルが必要なNFに制約が生じる可能性 -
セキュリティ境界が相対的に弱い
カーネルの脆弱性がすべてのコンテナに影響する可能性
6.5.3 ハイブリッドアプローチ
最近の研究開発では、両者のメリットを組み合わせるハイブリッドアプローチが注目されている。
-
Kataコンテナ
VMレベルの分離と安全性をコンテナに提供する技術。各Kataコンテナは軽量なVMで実行される -
軽量VM
コンテナのような起動速度と効率性を持ちながら、VMの分離性を備えたソリューション -
マイクロVM
FirecrackerやCloud HypervisorなどのAWS開発による軽量VM技術

https://ieeexplore.ieee.org/document/9844719

https://www.ernestchiang.com/files/firecracker-coscup-2020/playing-with-firecracker.pdf

https://pages.awscloud.com/rs/112-TZM-766/images/Overview-AWS-Lambda-Security.pdf
Cziva et al. (2017, 2018)の研究によれば、多くのNFVフレームワークはコスト効率と展開の柔軟性のために、従来のVMからコンテナベースのアプローチへと移行する傾向がある。ただし、特に通信事業者の中核ネットワークなど、特定の高セキュリティ要件があるユースケースでは、VMの強力な分離特性が依然として必要とされている。
結局のところ、「VMかコンテナか」という問いには単純な答えはなく、具体的なNFの要件、セキュリティ配慮、パフォーマンス目標、運用環境によって最適な選択が変わってくる。場合によっては、同じ環境内で両方のアプローチを使い分けるハイブリッド戦略が最も効果的なこともある。
6.6 ライブマイグレーションとNFの可用性
「実行中のNFサービスを中断することなく、異なる物理サーバーに移動させる」
ネットワーク機能の仮想化の大きな利点の一つが「柔軟性」。その柔軟性を示す重要な機能が「ライブマイグレーション」である。しかし、特にNFの場合、これは単純な作業ではない。
6.6.1 NFのライブマイグレーション技術
NFのライブマイグレーションは、サービスの中断を最小限に抑えながら、あるホストから別のホストへNFを移動させる技術。
このプロセスには主に以下の要素が含まれる。
-
メモリ状態の転送
仮想マシンやコンテナのメモリ内容を移行先ホストに複製する -
デバイス状態の保存と復元
特にNICやその他のI/Oデバイスの状態を正確に複製する -
ネットワーク接続の維持
クライアントからの接続が途切れないようにする
実際のマイグレーション技術には、いくつかの重要なアプローチがある。
-
事前コピー(Pre-copy)
VMが実行中にメモリページを段階的に転送し、最終的に短い停止時間で残りのダーティページを転送する -
ポストコピー(Post-copy)
最小限の状態だけを転送して迅速に実行を再開し、必要に応じて残りのメモリページをオンデマンドで転送する -
ハイブリッドアプローチ
上記の両方を組み合わせ、特定のワークロードに最適化する手法
これらの技術は一般的なVMマイグレーションで使用されるものだが、NFの場合は特有の課題が存在する。
6.6.2 NFマイグレーションの課題
NFのマイグレーションは通常のアプリケーションと比べて特に難しい。
その理由をいくつか挙げると、次のようなものがある。
-
I/O集約的な性質
NFは非常に高いレートでパケット処理を行うため、マイグレーション中でもパケットロスを最小限に抑える必要がある -
状態保持の必要性
多くのNF(特にステートフルファイアウォールやNAT)は接続状態を維持する必要がある -
厳格なレイテンシ要件
NFは通常、移行中でもミリ秒単位のレイテンシ要件を満たす必要がある -
ハードウェア依存性
SR-IOVやパススルーデバイスを使用するNFは、それらのデバイス状態を移行することが特に困難
特に興味深いのは、SR-IOVのような高性能I/O技術を使用するNFのマイグレーション。これらの技術はパフォーマンスを大幅に向上させるが、デバイス状態の保存と復元が複雑になるため、マイグレーションを困難にする。例えば、SR-IOV VFの内部状態は通常ハイパーバイザから完全には見えないため、移行時に適切に保存・復元することが難しい。
6.6.3 NFの高可用性戦略
ライブマイグレーション以外にも、NFの可用性を確保するための戦略がいくつか存在する。
-
チェックポイント/リストア
NFの状態を定期的に保存し、障害時に最新のチェックポイントから復元する -
アクティブ/スタンバイレプリケーション
同一のNFを2つ以上のインスタンスで実行し、一方に障害が発生した場合に即座に切り替える -
状態同期メカニズム
複数のNFインスタンス間で内部状態を継続的に同期する -
Ultravisor
Landis et al. (2016)が提案した、自動フェイルオーバー機能を持つハイパーバイザ拡張
これらの技術は、それぞれ異なるレベルのサービス中断とリソースオーバーヘッドのトレードオフを提供する。例えば、アクティブ/スタンバイアプローチは中断時間を最小限に抑えられるが、リソース使用量が2倍になる。一方、チェックポイント/リストアは効率的だが、復元時に若干の中断が発生する。
NFの可用性戦略の選択は、具体的なサービスレベル契約(SLA)、許容できるリソースオーバーヘッド、および具体的なNFの特性に大きく依存する。多くの通信事業者の環境では、「ファイブナイン」(99.999%)の可用性、つまり年間で最大5.26分のダウンタイムしか許容されないため、非常に洗練された高可用性戦略が必要となる。
6.7 各種ハイパーバイザ設定の性能比較研究
「同じハイパーバイザでも、設定の違いによってNFのパフォーマンスがどれほど変わるのか?」
多くの研究がこの問題に取り組んでおり、ハイパーバイザの設定がNFパフォーマンスに大きな影響を与えることが示されている。
6.7.1 リソース割り当て
ハイパーバイザのリソース割り当て設定は、NFの性能に直接影響する。
特に重要なのは以下の側面。
vCPU割り当てポリシー
-
ピン留め vs 動的スケジューリング
vCPUを物理CPUコアに固定(ピン留め)すると、キャッシュローカリティが向上し、コンテキストスイッチのオーバーヘッドが削減される。一方、動的スケジューリングは柔軟性を提供するが、キャッシュミスが増加する可能性がある。 -
CPUオーバーコミットの影響
物理コアよりも多くのvCPUを割り当てると柔軟性が向上するが、コンテンションが発生した場合のパフォーマンス予測が困難になる。NFのような低レイテンシアプリケーションでは、オーバーコミットを避けるか、慎重に管理する必要がある。
メモリ最適化
-
バルーニング
ゲストOSのメモリ使用量を動的に調整する技術。効率的なリソース使用を可能にするが、不適切に設定すると予測不能なパフォーマンス低下を引き起こす可能性がある。 -
ページ共有
同一内容のメモリページをVM間で共有する技術。メモリ使用効率は向上するが、セキュリティリスク(サイドチャネル攻撃の可能性)や性能オーバーヘッドの増加を伴う。 -
HugePagesの影響
VMにHugePagesを割り当てると、TLBミスが減少し、アドレス変換のオーバーヘッドが大幅に削減される。これはNFのようなメモリアクセス頻度の高いワークロードで特に効果的。
I/Oチューニング
-
仮想化キューサイズ
大きすぎるとレイテンシが増加し、小さすぎるとスループットが制限される。NFのトラフィックパターンに基づいた適切なサイジングが重要。 -
割り込み調整
割り込みの頻度とコアリングを調整することで、CPU使用率とレイテンシのバランスを最適化できる。 -
I/Oスレッドアフィニティ
I/O処理スレッドを特定のCPUコアに割り当てることで、キャッシュ局所性とNUMA効率を向上させる。
6.7.2 ハイパーバイザ性能
特定のNFワークロードに対する様々なハイパーバイザの比較研究も数多く行われている。
主な検討項目は以下の通り。
-
マルチコア環境でのスケーラビリティ
vCPU数が増加した場合のパフォーマンススケーリング特性。理想的には線形スケーリングだが、実際にはハイパーバイザのオーバーヘッドにより非線形になることが多い。 -
割り込み仮想化効率
物理割り込みが仮想マシンにどのように配信されるか。特にパケット到着率が高い環境では、割り込み処理効率がパフォーマンスに大きな影響を与える。 -
ページテーブル仮想化
二段階のページテーブルウォークによるオーバーヘッドは無視できない。EPT(Extended Page Tables)やNPT(Nested Page Tables)の実装の違いにより、ハイパーバイザ間でパフォーマンス差が生じる。 -
I/Oデバイス仮想化のオーバーヘッド
各ハイパーバイザは、I/Oデバイスの仮想化に異なるアプローチを取る。エミュレーション、準仮想化、SR-IOVなどのサポート方法の違いが、NFパフォーマンスに大きな影響を与える。
Nakajima et al. (2018)による研究では、パケット処理におけるハイパーバイザのオーバーヘッドの主な原因として、VMM遷移(CPU状態の切り替え)、割り込み仮想化、ページテーブル仮想化、I/Oデバイス仮想化が特定された。これらの要素は、異なるハイパーバイザ設定で大きく異なる可能性がある。
6.7.3 セキュリティ対パフォーマンスのトレードオフ
ハイパーバイザのセキュリティ機能もNFパフォーマンスに大きな影響を与える。
主要なセキュリティメカニズムとその影響は以下の通り。
-
sHype
Sailer et al. (2020)によって開発されたハイパーバイザセキュリティアーキテクチャで、VM間の情報フロー制約を強制する。このセキュリティレイヤーはVM間の完全な分離を保証するが、パフォーマンスオーバーヘッドを伴う。 -
HyperSafe
Wang et al. (2020)が提案した低コストアプローチで、ハイパーバイザの制御フローコードの整合性を保証する。ハイパーバイザのセキュリティを強化しつつも、最小限のパフォーマンス影響を目指している。 -
HyperWall
信頼できないハイパーバイザからゲストVMを保護するためのセキュア仮想化アーキテクチャ。ハードウェアサポートを利用してVMの整合性と機密性を保証する。
平均して、これらのセキュリティ機能は約5%のパフォーマンスオーバーヘッドを導入すると報告されている。しかし興味深いことに、特定の条件下では、セキュリティ機能の追加が実際にパフォーマンスを向上させることもある。例えば、HyperSafeの制御フロー保護メカニズムは、特定のシナリオでキャッシュ利用率を向上させ、不要なメモリ読み取りを防止することで、全体的なパフォーマンスを向上させる可能性がある。
7. 研究事例と性能評価
「実際のところ、これらの技術はどのような性能を示すのか?」
理論は素晴らしいが、実世界でのパフォーマンスが真の価値を示す。
7.1 様々なNFにおける性能評価研究のサーベイ
7.1.1 ファイアウォールの性能評価
ファイアウォールはネットワークセキュリティの基本要素。多くの研究がその仮想化性能に焦点を当てている。
Emmerich et al. (2017)の研究においては、彼らはオープンソースのファイアウォールソリューション(pfSense、OPNsense、VyOS)を様々な環境設定で評価した。
評価の結果は以下の通り。
- DPDKを活用したユーザスペースファイアウォールは、従来のカーネルベースソリューションと比較して最大10倍のスループットを達成
- ルール数が1000を超えると、すべての実装でパフォーマンスが著しく低下する傾向
- 小さなパケット(64バイト)の処理は、どの実装でも特に課題となっている
Zhang et al. (2019)はさらに一歩進んで、NFVベースのファイアウォールのセキュリティと性能のトレードオフを分析した。彼らは、ディープパケットインスペクション(DPI)機能を有効にすると、スループットが最大70%低下する可能性があるものの、SR-IOVとDPDKの組み合わせによってこの低下を30%程度に抑えられることを示した。
7.1.2 ルータ/スイッチの性能評価
Linguaglossa et al. (2019)は、ソフトウェアルータの包括的なベンチマークを行った。
結果は以下の通り。
- VPP(Vector Packet Processing)は複雑なルーティングシナリオで最も高いパフォーマンスを示した
- SR-IOVを使用したDPDKベースの実装は、小さなパケットサイズでも40Gbpsに近いスループットを達成
- しかし、ルーティングテーブルのサイズが大きくなると(100万エントリ以上)、どの実装もスループットが50%以上低下
Gallo et al. (2018)の研究は、マルチテナント環境でのvSwitchのパフォーマンス分離に焦点を当てた。彼らは、OVSとVPPを使用した仮想スイッチング環境で、テナント間の公平性とパフォーマンス分離を評価し、以下のことを発見した。
- DPDK統合OVSは、標準OVSと比較して最大5倍のスループットを提供
- しかし、テナント数が増加すると(特に16以上)、リソース競合によりパフォーマンス予測可能性が大幅に低下
- VPPはテナント間の公平性において優れたパフォーマンス分離を示した
7.1.3 ロードバランサの性能評価
Miao et al. (2021)はソフトウェアベースのロードバランサについて詳細な分析を行った。
結果は以下の通り。
- L4(トランスポート層)とL7(アプリケーション層)ロードバランサの間に明確なパフォーマンスギャップが存在することを示した
- 最新のL4ロードバランサは、DPDK最適化とマルチコア設計により、40Gbpsを超えるスループットを達成
- L7ロードバランサ(HAProxy、NGINX等)は、HTTPヘッダ処理のオーバーヘッドにより、同じハードウェアでL4の25-40%のスループットしか達成できない
- コネクション追跡テーブルのサイズが増加すると、すべてのロードバランサでレイテンシが増加する傾向
Wang et al. (2020)は、コンテナベースのロードバランサとVM内のロードバランサを比較し、興味深い発見を報告している。
- コンテナベースの実装は起動時間が速い(数秒)が、ピークパフォーマンスは約15%低い
- CPU使用率では、コンテナベースの実装が約10-20%効率的
- ただし、高負荷状況(1秒間に10,000以上の新規接続)では、VMベースの実装の方が安定したパフォーマンスを提供
7.1.4 複合NFチェーンの評価
実際のNFV環境では、単一のNFではなく複数のNFが連鎖して機能することが一般的。
Cao et al. (2022)は、NF連鎖(Service Function Chaining)のパフォーマンスを評価した。
結果は以下の通り。
- 3つのNF(ファイアウォール、IDS、NAT)を連鎖させた場合、個々のNFパフォーマンスの単純な合計よりも30-45%パフォーマンスが低下
- NFの順序が性能に大きく影響する(例:IDSを最初に配置すると、最後に配置するよりも20%パフォーマンスが向上)
- 共有メモリベースのNF間通信を使用すると、vSwitchベースの通信と比較してエンドツーエンドのレイテンシが40%減少
これらの研究は、NF性能が単に個々のコンポーネントの性能だけではなく、それらがどのように組み合わされるかにも大きく依存することを示している。
7.2 OS/ハイパーバイザ技術の組み合わせ比較
NF実装においては、様々なOS、ハイパーバイザ、I/O技術の組み合わせが可能です。研究者たちはこれらの組み合わせのパフォーマンス特性を理解するために、さまざまな比較研究を行っています。
7.2.1 DPDK+SR-IOV vs Kernel+VirtIO
多くの研究が、DPDKとSR-IOVの組み合わせと、より従来的なカーネルベースの処理とVirtIOの組み合わせを比較している。
Liu et al. (2018)は、これらの組み合わせを詳細に比較し、次のような結果を報告している。
- DPDK+SR-IOVの組み合わせは、小さなパケットサイズ(64バイト)で最大12倍のスループット向上
- Kernel+VirtIOは、大きなパケットサイズ(1500バイト)では比較的競争力がある(DPDK+SR-IOVの約60-70%のパフォーマンス)
- しかし、CPU使用率においては、DPDK+SR-IOVが常に大幅に効率的(同じスループットを達成するために約30-40%少ないCPU使用率)
- スケーラビリティの面では、DPDK+SR-IOVがコア数の増加に対してほぼ線形のスケーリングを示したのに対し、Kernel+VirtIOは4コア以上でスケーリングが頭打ちになる傾向
Zhang et al. (2020)は、これらの組み合わせが異なるNFタイプに与える影響の違いを研究した。
- ステートレスNF(単純なパケット転送など)では、DPDK+SR-IOVが最大15倍のパフォーマンス向上
- ステートフルNF(NAT、ファイアウォールなど)では、性能差が縮小し、約5-8倍の差に
- メモリ集約型NF(ディープパケットインスペクションなど)では、さらに差が縮小し、約3-5倍の差に
このように、NF処理の特性によって、最適な技術の組み合わせは異なり得ることがわかる。
7.2.2 コンテナ vs VM ベースのNF
別の比較軸は、コンテナベースとVMベースのNF実装。
Cziva et al. (2018)の研究では、DockerコンテナとKVMベースのVMでNFを実行する場合の比較を行った。
- コンテナベースのNFは起動時間が圧倒的に速い(数百ミリ秒 vs. VMの数秒から数十秒)
- メモリ使用量もコンテナの方が少ない(同じNFで約40-60%削減)
- しかし、ピーク時のパケット処理性能では、適切に最適化されたVMが約10-15%高いスループットを達成
- さらに、高負荷状況下でのパフォーマンス安定性は、VMの方が優れている傾向
Antichi et al. (2019)はこの比較をさらに拡張し、KataコンテナとgVisorなどの保護されたコンテナランタイムを含めた。
結果は以下の通り。
- 標準Dockerコンテナは最高のパフォーマンス(ネイティブに近い)を提供するが、分離性は最も低い
- gVisorは追加のセキュリティレイヤーにより、約30-40%のパフォーマンスペナルティを被る
- Kataコンテナは、軽量VMの利点と標準コンテナの使いやすさを組み合わせ、約15-25%のパフォーマンスペナルティで良好な分離を実現
- 伝統的なVMは最高の分離を提供するが、約20-30%のオーバーヘッドがある
これらの研究から、「ワンサイズフィットオール」のソリューションは存在せず、具体的な要件(性能、分離、起動時間など)に基づいて最適なアプローチを選択する必要があることを改めて確認できる。
7.2.3 異なるハイパーバイザの比較
様々なハイパーバイザの間にも、NF性能に影響を与える違いがある。
Enberg et al. (2019)の研究では、KVM、Xen、VMwareなどの主要なハイパーバイザをNF処理の文脈で比較した。
- KVMは総合的に最高のパケット処理性能を示し、特にLinuxベースのNFに最適
- Xenは若干低いパフォーマンスだが、リソース分離と品質保証の面で優れた特性を示した
- VMwareは企業環境との統合が容易で、管理機能が充実しているが、オープンソースソリューションと比較してやや高いオーバーヘッド
Wang et al. (2021)は、さらにType 1(ベアメタル)とType 2(ホスト型)ハイパーバイザの比較を行った。
- Type 1ハイパーバイザは予想通り全体的に高いパフォーマンスを示した(平均で15-30%の差)
- しかし、SR-IOVなどの最適化技術を使用すると、Type 2ハイパーバイザでもほぼ同等のパフォーマンスを達成可能
- 管理のしやすさとデバッグ能力では、Type 2ハイパーバイザが優位
これらの研究は、ハイパーバイザ選択がNF性能に大きな影響を与える一方で、適切な最適化技術を適用することでその差を縮小できることを示唆している。
7.3 評価指標
NF性能を評価する際には、様々な指標が使用される。
研究によって重視される指標は異なるが、一般的に以下の指標が重要視される。
7.3.1 スループット
Li et al. (2020)は、NF評価におけるスループット測定の方法論を詳細に検討した。
彼らは以下の点を強調している。
- パケットサイズによる影響が大きい(小さなパケットは常に最大のチャレンジ)
- パケット生成方法と測定ツール(DPDK-pktgen、TRex、Moongen等)によって結果が大きく変わる可能性
- 測定時間が重要(短すぎる測定ではキャッシュ効果によって非現実的な結果が出る可能性)
- 複数の独立した測定と信頼区間の報告の重要性
彼らの研究によれば、10秒以上の測定時間と、少なくとも5回の独立した実行が信頼できる結果のために推奨される。
7.3.2 レイテンシ
レイテンシはスループットと並んで重要な指標であるが、その測定はより複雑である。
Zilberman et al. (2019)は、NFVレイテンシ測定における課題と方法論を詳細に分析した。
- エンドツーエンドレイテンシとパケット処理レイテンシの区別が重要
- ジッター(レイテンシの変動)は多くのアプリケーションにとってスループットよりも重要な場合がある
- 負荷に応じたレイテンシプロファイルが必要(低負荷と高負荷で大きく異なる)
- パーセンタイルレイテンシ(特に99.9パーセンタイル)が平均やメディアンよりも有用
特に興味深いのは、彼らが示した「負荷に対するレイテンシプロファイル」。ほとんどのNF実装は、ある負荷しきい値を超えると急激にレイテンシが増加する「ホッケースティック」パターンを示す。この閾値を特定することが、実際の運用キャパシティを決定する上で重要と思われる。
7.3.3 CPU使用率
Chen et al. (2021)は、NFのCPU使用効率に焦点を当てた研究を行った。
- パケット処理のスループットだけでなく、「パケット/CPU-サイクル」や「ビット/Hz」などの指標が重要
- I/O待ちやコンテキストスイッチなどの非生産的なCPU使用を分離して測定する必要性
- コア数に対するスケーラビリティ(理想的には線形)が実際の展開で重要な要素
彼らの発見によれば、DPDKベースのNFは通常、カーネルベースのNFよりも2-4倍のCPU効率(処理されたパケット/CPU-サイクル)を示す。しかし、アイドル状態では、カーネルベースのNFの方がCPU使用率が低くなる傾向があった。
7.3.4 電力効率
Kuznetsov et al. (2022)は、NFVの電力効率に関する研究を行った。
- 異なるNF実装間で最大5倍の電力効率の差がある(処理されたパケット/ワット)
- DPDKなどのユーザスペースフレームワークは高スループットを提供するが、常に電力効率が良いわけではない
- 特に低負荷時には、適応的電力管理機能によりカーネルベースのソリューションが優れた電力効率を示す
- NFチェーンでは、共有リソース利用により全体の電力効率が向上する可能性がある
彼らの研究では、NFVの電力効率を最適化するための「ワークロード対応型」アプローチの重要性が強調されてる。具体的には、負荷に応じてDPDKと従来のカーネル処理の間で動的に切り替えることで、最大30%の電力削減が可能だと示されている。
7.4 文献から得られた主要な知見とトレードオフ
これまで見てきた様々な研究から、いくつかの重要な知見とトレードオフが浮かび上がる。
7.4.1 パフォーマンスと柔軟性のトレードオフ
多くの研究が、高性能と柔軟性の間に明確なトレードオフがあることを示している。
- 最も高いパフォーマンスを得るためには、SR-IOVとDPDKの組み合わせが最適だが、この構成は動的な再構成や移行が難しい
- より柔軟な構成(例:VirtIOベースのVMまたはコンテナ)は管理が容易で適応性が高いが、パフォーマンスは低下する
- システムコンポーネントが専門化されるほど(例:特定のNF向けにチューニングされたOS)、パフォーマンスは向上するが、汎用性は低下する
Bjørgeengen et al. (2020)の研究では、このトレードオフの具体的な例として、フレキシブルなNFVプラットフォームを設計する際のパフォーマンス低下は避けられないものの、適切なアーキテクチャ選択によって最小限に抑えることができると結論づけている。
7.4.2 分離とパフォーマンスのトレードオフ
セキュリティと分離の要件も、NF性能に大きな影響を与える。
- 最強の分離を提供するアプローチ(例:完全な仮想化VM)は、通常最も高いオーバーヘッドを伴う
- コンテナは軽量だが、カーネル共有により分離レベルが低下する
- KataコンテナやgVisorなどのハイブリッドアプローチは、中間的なトレードオフポイントを提供する
Li et al. (2019)の研究では、NFV環境における分離レベルとパフォーマンスペナルティの関係を調査している。彼らの結果によれば、強力な分離メカニズムは10-40%のパフォーマンスオーバーヘッドをもたらす可能性があるが、その重要性は特に多テナント環境においては無視できないことを強調している。
7.4.3 最適化技術の複合効果
複数の技術を組み合わせた場合の効果は必ずしも加算的ではない。
- 例えば、DPDKとHugePagesの組み合わせは、個別に適用した場合の改善の合計よりも少ない改善しかもたらさない場合がある
- 一方で、一部の最適化技術(例:NUMAアウェアなスレッド配置とSR-IOV)は相乗効果を生み出し、個別の改善を上回る総合的な効果をもたらす
Kuznetsov et al. (2020)は、複数のNF最適化技術の組み合わせがもたらす複合効果について体系的な研究を行った。彼らの結果によれば、技術の選択と組み合わせ方法が重要であり、単に「すべての最適化を適用する」アプローチは必ずしも最適ではないことが示されている。
7.4.4 ワークロード特性の重要性
どのNF実装やOS/ハイパーバイザ構成が「最良」かという問いには、一般的な答えがないことが多くの研究から明らかになった。最適な選択は、具体的なNFのワークロード特性に大きく依存する。
- パケットサイズ分布(小vs大)
- ステートフル処理の程度
- フロー数と継続時間
- 処理の計算複雑性
- バースト性と負荷変動
Zhang et al. (2021)の研究では、同じNF実装でも、ワークロード特性に応じて最適な構成が大きく異なることを示している。例えば、長時間のフローを持つステートフルNFの場合は、キャッシュ局所性が重要になるため、コア固定と大きなメモリページが有効である。一方、短いフローが多数存在する場合は、ロードバランシングが重要になるため、動的スケジューリングの方が効果的な場合がある。
8. 参考文献
ここまでお読みくださった物好きな方、ありがとうございます。
残念なお知らせですが、深淵まで読み進めてしまった方は上昇負荷によりヒトの姿を保てなくなります。

Discussion