AmazonのDynamoから学ぶ高可用性キーバリューストアの設計解剖メモ
はじめに
Amazonのようなeコマース事業者では、わずかなサービス停止でも重大な財務影響につながる。数万台のサーバーとネットワークコンポーネントから成るインフラでは、大小によらずコンポーネント障害が日常的に発生し、この環境下での状態管理がシステムの信頼性を左右する。
従来のデータベースは多くの機能を提供するが、高可用性と水平スケーラビリティには複雑な解決策が必要になる。一方で、多くのWebサービスはショッピングカートやセッション管理など、単純なキーバリューアクセスパターンで十分な場合が多い。
Amazonが開発したDynamoは、シンプルなキーバリューインターフェースを持ちながら、「常時利用可能」な高可用性を実現し、特定の障害シナリオで一貫性を犠牲にする。
ここでは「Dynamo: Amazon’s Highly Available Key-value Store」を参考に、Dynamoの設計原則とアーキテクチャをメモする。
2007年度のSOSP(ACM Symposium on Operating Systems Principles)で発表された論文で、Dynamoの設計原則やアーキテクチャが詳しく説明されている。だいぶ古い論文だが、DynamoはAmazonの多くのサービスで利用されており、現在もその設計原則は有効だ。
Dynamoシステムの全体像
Dynamoは高可用性を実現するための複数の分散システム技術を組み合わせたプラットフォームだ。以下の表はDynamoの主要技術要素をまとめたものだ。
| 課題 | 採用技術 | 利点 |
|---|---|---|
| データ分割 | 一貫性ハッシュ | ・段階的なスケーラビリティ ・ノード追加/削除時の最小限の再分配 |
| 書き込み時の高可用性 | 読み取り時の調整を伴うベクタークロック | ・更新頻度とバージョンサイズの分離 ・競合の効率的な検出 |
| 一時的な障害処理 | スロッピークォーラムとヒンテッドハンドオフ | ・レプリカの一部が利用不可でも高可用性を維持 |
| 永続的な障害からの復旧 | マークルツリーを使用した反エントロピー | ・バックグラウンドでのレプリカ同期 ・効率的なデータ比較 |
| メンバーシップと障害検出 | ゴシップベースのプロトコル | ・対称性の維持 ・集中型レジストリの回避 |
Dynamoは完全な分散アーキテクチャで、各ノードが対等な責任を持つ。そのため、ノードの追加・削除が手動パーティショニングなしで行える。
実際のリクエスト処理フローは以下のような感じ。
Amazonプラットフォームでは、Dynamoは様々なユースケースで利用されている。
| サービス種別 | Dynamoの利用方法 | 特性 |
|---|---|---|
| ショッピングカートサービス | アプリケーション固有の調整ロジック | ・異なるバージョンのカートをマージ ・常に書き込み可能 |
| セッション管理 | タイムスタンプベースの調整 | ・「最後の書き込みが勝つ」ポリシー ・高可用性が重要 |
| 製品カタログやプロモーション情報 | 高性能読み取りエンジン | ・読み取りが多く書き込みが少ない ・R=1, W=Nの設定 |
Dynamoはこれらのサービスを支え、忙しい休暇シーズン中にもダウンタイムなしでピーク負荷に対応できる。ショッピングカートサービスは1日で数千万件のリクエストと300万以上のチェックアウトを処理し、セッション管理サービスは数十万の同時セッションを扱っている(論文執筆時点)。
従来の分散システムとの大きな違いは、DynamoがCAP定理における一貫性よりも可用性を優先している点だ。多くの分散データベースが一貫性のために可用性を犠牲にするのに対し、Dynamoは「結果整合性」アプローチで、更新が最終的にすべてのレプリカに到達することを保証する。
基本設計原則
可用性と一貫性のトレードオフ
分散システム設計の基本課題は、可用性と一貫性のバランスだ。以下の表はこのトレードオフを示している。
| 側面 | 強い一貫性モデル | Dynamoの結果整合性モデル |
|---|---|---|
| ネットワーク分断時の動作 | ・書き込み操作を拒否 ・一貫性優先で可用性低下 |
・書き込み操作を常に受け入れ ・可用性優先で一時的な非一貫性を許容 |
| 競合解決のタイミング | 書き込み時に解決 | 読み取り時に解決 |
| 競合解決の責任 | ストレージシステム | アプリケーション |
Amazonの経験では、ACID属性を完全保証するデータストアは可用性が低くなる傾向がある。Dynamoは一貫性よりも高可用性を優先し、分離保証を提供せず、単一キーの更新のみを許可する。
ショッピングカートのようなサービスでは、顧客の更新を拒否すると顧客体験を損なう。ネットワーク障害やサーバー障害があっても、顧客がカートに商品を追加・削除できる必要があり、これにより「常に書き込み可能」なシステムが必要になる。
実践におけるCAPの定理
分散システムはネットワーク障害の可能性がある環境では、強い一貫性と高い可用性を同時に達成できない。Dynamoはこの制約を受け入れ、楽観的なレプリケーション技術で可用性を高めている。変更はバックグラウンドでレプリカに伝搬され、切断された同時作業も許容される。課題は競合する変更の検出と解決だが、Dynamoは最終的な一貫性を保証している。つまり、すべての更新が最終的にすべてのレプリカに到達する。
「常に書き込み可能」という哲学
Dynamoの根本的な特徴は「常に書き込み可能(always writeable)」な設計哲学だ。
| 設計側面 | 従来のアプローチ | Dynamoのアプローチ | 影響 |
|---|---|---|---|
| 競合解決のタイミング | 書き込み時 | 読み取り時 | ・書き込み操作が常に成功 ・競合解決の複雑さが読み取り側に移動 |
| 競合解決の方法 | データストアレベル | アプリケーションレベル | ・データスキーマを理解した適切な解決 ・ビジネスロジックに合わせた対応 |
| バージョン管理 | 単一バージョン | 複数バージョンの並行管理 | ・ベクタークロックによる因果関係の追跡 ・最終的な一貫性の実現 |
この設計は顧客体験を最優先するAmazonの哲学を反映している。複雑さを書き込みから読み取り操作に移し、書き込みが拒否されないようにしている。
段階的なスケーラビリティと分散化
Dynamoは、システムへの影響を最小限に抑えながら、一度に1つのノードをスケールアウトできる。トラフィック増加に応じて段階的に容量を追加できる。
また、完全な分散化と対称性を重視している。各ノードは対等で、特別な役割を持つノードは存在しない。この対称性でシステム管理が簡素化される。集中型制御ではなく分散型のピアツーピア技術を優先し、より単純でスケーラブルなシステムを実現している。
コアシステムアーキテクチャ
一貫性ハッシュによるデータ分割
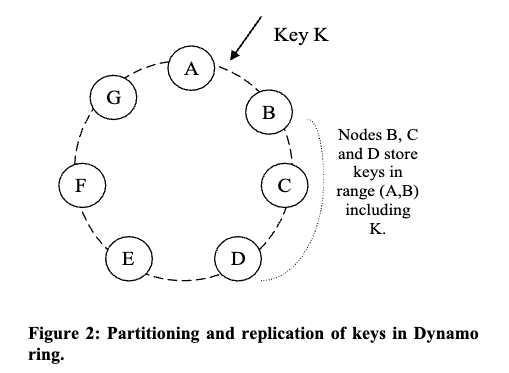
Dynamoのパーティショニングは一貫性ハッシュに基づいて負荷を分散する。ハッシュ関数の出力範囲を円状空間(「リング」)として扱い、各ノードにリング上の位置を割り当てる。データアイテムはキーのハッシュ値に基づいて、時計回りに最初に見つかるノードに割り当てられる。
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
一貫性ハッシュの主な利点は、ノードの出入りが隣接ノードにのみ影響することだが、基本アルゴリズムには問題点もある。
- ノード位置のランダム割り当てによる不均一分布
- ノード性能の異質性への非対応
これらに対処するため、Dynamoは「仮想ノード」概念を導入した。単一ノードを単一点ではなく複数点に割り当て、各物理ノードが複数の仮想ノードを担当できるようにしている。
負荷分散のための仮想ノード
仮想ノードを使用する利点を改めると、ノードの負荷を均等に分散できることだ。
| 利点 | 説明 |
|---|---|
| 障害時の負荷分散 | ノード障害時の負荷が残りのノードに均等分散 |
| 復旧時の負荷分散 | 新ノード追加時に均等な負荷移行が可能 |
| 異質性への対応 | ノード能力に応じた仮想ノード数の調整が可能 |
このアプローチで負荷バランスが改善され、ホットスポット形成を防止。障害や回復時の負荷再分配もより均等になる。
レプリケーション戦略(N方向レプリケーション)
高可用性と耐久性のため、Dynamoはデータを複数ホストにレプリケートする。各データはN個のホストに複製され、Nはインスタンスごとに設定される。各キーkはコーディネーターノードに割り当てられ、自身の範囲内のキーをローカルに保存し、さらにリング上のN-1個の後続ノードにも複製する。
たとえば、N=3 の場合の key0 は、s1, s2, s3 に複製される。

https://books.dwf.dev/docs/system-design/c7
特定キーの保存担当ノードのリストは「プリファレンスリスト」と呼ばれる。ノード障害に備え、このリストにはN個以上のノードが含まれる。
クォーラムベースの一貫性(N、R、Wパラメータ)
レプリカ間の一貫性維持には、2つの設定可能な値RとWを使用する。
- R:読み取り操作に必要な最小ノード数
- W:書き込み操作に必要な最小ノード数
R + W > Nで設定するとクォーラムシステムになる。この条件は、読み取りと書き込みのノード集合に必ず共通部分が生じることを保証する。get/put操作のレイテンシーはR/Wレプリカの最遅ノードで決まるため、通常はRとWをNより小さく設定してレイテンシーを改善する。
設定例と効果は次の通り。
| 設定 | 効果 | 使用例 |
|---|---|---|
| W=1 | ・単一ノード書き込みで操作完了 ・最高の書き込み可用性 |
最高レベルの可用性が必要なアプリケーション |
| W=N | ・全レプリカへの書き込み必要 ・最大の耐久性 |
データ耐久性が極めて重要なアプリケーション |
| R=1 | ・どのレプリカからでも読取可能 ・最高の読取可用性 |
高性能読取エンジン |
| R=N | ・全レプリカからの確認が必要 ・最高の一貫性 |
最新データ必須のアプリケーション |
本番環境では、多くのAmazonサービスは(N, R, W) = (3, 2, 2)の設定を使用している。これは次の状態であることを意味する。
- データは3台のサーバーに複製される
- 読み取りは2台のサーバーから取得
- 書き込みは2台のサーバーに成功すれば完了
- 2 + 2 > 3 なので、少なくとも1台のサーバーは必ず両方の操作に参加する
このため、最新の書き込みを含むサーバーから少なくとも1つは読み取ることができ、古いデータしか読めない状況を防げる。
バージョン管理のためのベクタークロック
Dynamoは最終的な一貫性を提供し、更新が非同期で伝播するが、get()操作が最新更新を含まないオブジェクトを返す可能性もある。Amazonのプラットフォームには、この非一貫性を許容するアプリケーションがある。例えばショッピングカートでは、「追加」操作が拒否されてはならない。
Dynamoはこれを実現するため、各変更を新しい不変データバージョンとして扱う。通常は新バージョンが旧バージョンを置き換えるが(構文的調整)、障害と同時更新で競合バージョンが生じた場合はクライアントによる調整が必要になる(意味的調整)。
バージョン間の因果関係追跡にはベクタークロック((ノード, カウンター)ペアのリスト)を使用。クライアント更新時はコンテキスト情報を含むことで、どのバージョンを更新しているかを指定する。
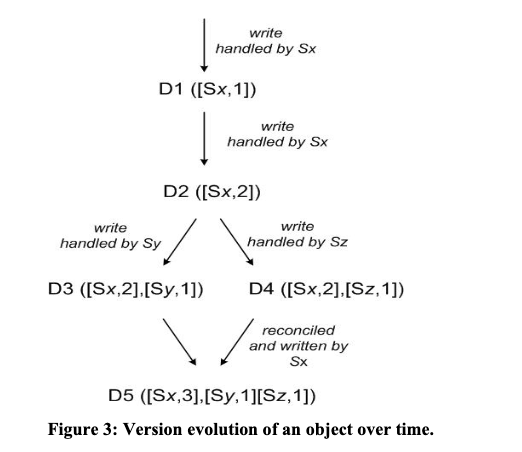
具体的な流れを下図でトレースする。
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
-
最初のステップでは、クライアントが新しいオブジェクトを書き込み、ノードSxがこの処理を担当する。この時点でオブジェクトD1が作成され、ベクタークロック[(Sx, 1)]が付与される。
-
次に同じクライアントがオブジェクトを更新し、再びノードSxが処理する。新しいバージョンD2が作成され、ベクタークロックは[(Sx, 2)]に更新される。D2はD1を論理的に上書きする。
-
同じクライアントがさらに更新を行うが、今回は異なるノードSyが処理する。その結果、オブジェクトD3が作成され、ベクタークロックは[(Sx, 2), (Sy, 1)]になる。
-
並行して、別のクライアントがD2を読み取って更新し、ノードSzがその処理を担当する。これによりオブジェクトD4が生成され、ベクタークロックは[(Sx, 2), (Sz, 1)]となる。
-
ここで重要なのは、D3とD4は並行して作成されたため、どちらも他方を論理的に上書きできない点である。どちらのバージョンも有効であり、システムはこの競合を自動的に解決できない。
-
最終的に、クライアントが両方のバージョン(D3とD4)を受け取り、アプリケーションレベルで競合を解決する。この調整された結果がD5として書き込まれ、ノードSxがこの処理を担当する。新しいベクタークロックは[(Sx, 3), (Sy, 1), (Sz, 1)]となり、D3とD4の両方の変更履歴を包含する。
この図はDynamoの重要な特徴である「結果整合性」と「アプリケーション支援の競合解決」を示している。システムは一時的な不整合を許容し、読み取り時に複数のバージョンを返して、最終的にクライアントが意味的に適切な方法で競合を解決できるようにしている。
ベクタークロックの問題点は、多数のサーバーが書き込みを調整するとサイズが大きくなることだ。Dynamoはこれに対処するため、しきい値(例:10)に達すると最も古いペアを削除するクロック切り捨てスキームを採用。理論上は問題の可能性があるが、実運用では顕在化していない。
障害シナリオの処理
スロッピークォーラムとヒンテッドハンドオフ
従来のクォーラムアプローチではサーバー障害やネットワーク分断時に利用不能になる問題を、Dynamoは「スロッピークォーラム」で解決する。読み取り/書き込み操作はプリファレンスリストから最初のN個の健全なノードで実行され、必ずしも最初のN個のノードとは限らない。
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
例えば、N=3の条件下でノードAが一時的にダウンした場合、通常Aに保存されるレプリカがノードDに送信される(プリファレンスリストのB,Cにはすでに複製済であり、あと一つAの代わりに複製先を探す必要があるため)。このレプリカには本来の受信者(A)を示す「ヒント」がメタデータに含まれる。Aが回復したら、DはレプリカをAに戻す仕組みだ。
これにより、一時的な障害でも操作失敗を防ぐ。高可用性アプリケーションではWを1に設定でき、単一ノードが書き込めれば成功となる。ただし、本番環境では多くのサービスが耐久性向上のためにより高いWを設定している。
さらに、データセンター全体の障害対応のため、Dynamoは複数データセンターにわたるレプリケーションを設定。高速ネットワークで接続されたデータセンター間でレプリケーションすることで、データセンター全体障害からも保護される。
マークルツリーを使用した反エントロピー
ヒンテッドハンドオフは変動の少ない環境に効果的だが、ヒントレプリカが元のノードに戻せない場合もある。このような耐久性の脅威に対処するため、Dynamoは反エントロピープロトコルを実装している。
レプリカ間の不整合を早く検出し、転送データ量を最小化するため、マークルツリー(ハッシュツリー)を使用。ルートハッシュが一致すればデータは同期済み、不一致なら子ハッシュを交換し、リーフに到達するまで続けて「非同期」キーを特定する。

Dynamoでは各ノードが各キー範囲ごとに別々のマークルツリーを維持する。ノード間で共通ホストするキー範囲のツリールートを交換し、差異を検出して同期アクションを実行する。欠点はノードの加入/脱退時にツリーの再計算が必要なことだが、改良されたパーティショニングで対処されている。
ゴシップベースの障害検出とメンバーシッププロトコル
Amazonの環境では、ノード停止(障害/メンテナンス)は一時的なことが多い。永続的離脱を意味することは少なく、パーティション再調整や修復につながるべきでない。そのため、明示的なメンバーシップ変更メカニズムを使用している。
管理者はコマンドラインかブラウザでDynamoノードに接続し、メンバーシップ変更を発行。処理ノードはこの変更と時刻を永続ストアに記録する。ゴシップベースのプロトコルがこの変更を伝播し、各ノードは毎秒ランダムピアと連絡してメンバーシップ履歴を調整する。
初回起動時、ノードはトークンセットを選択してマッピングをディスクに保存。このマッピングはメンバーシップ変更調整と同時に同期され、各ノードは他ノードのトークン範囲を認識できるようになる。
リカバリメカニズム
Dynamoには様々な障害シナリオの回復機能がある。一時的障害からの回復では、ノードは永続状態からデータを復元し、必要に応じてヒンテッドハンドオフレプリカを適用。長期的障害からは反エントロピープロトコルで他レプリカと同期する。
また、ノード追加/削除のためのリカバリメカニズムもあり、効率的かつ信頼性の高い状態転送を実現している。
リクエスト処理
読み取りと書き込み操作のフロー
クライアントがノードを選択する方法は2種類ある。
- ロードバランサー経由でリクエストをルーティング
- パーティション認識クライアントライブラリで直接コーディネーターにルーティング
前者はDynamo固有コード不要の利点、後者はレイテンシー削減の利点がある。
コーディネーター(通常はプリファレンスリスト最上位ノード)が操作を処理。読み取り/書き込み操作は健全なノードのみを使用し、ノード障害時は低ランクノードにアクセスする。
読み取り操作の基本フロー
- 上位Nノードにリクエスト送信
- 最小数R応答を待機
- タイムアウトで失敗または全バージョン収集
- 必要に応じて構文的調整とコンテキスト生成
- 古いバージョン検出時に自動読み取り修復
書き込み操作の基本フロー
- ベクタークロック生成とローカル書き込み
- N個の到達可能ノードに送信
- 最低W-1ノードの応答で成功
パフォーマンス最適化のため、前回の読み取りで最速応答したノードを書き込みコーディネーターに選択。これで「自分の書き込みを読む」一貫性が向上し、99.9パーセンタイルのパフォーマンスも改善される。
競合検出と解決
Dynamoはベクタークロックで競合検出を行う。クライアントはコンテキスト(ベクタークロック情報)を含む更新リクエストを送信し、複数クライアントが並行更新すると競合が発生。後続の読み取りでこれらの発散バージョンを検出し、すべてをクライアントに返す。
アプリケーション固有の調整が可能で、ショッピングカートサービスはカートバージョンを独自にマージ。セッション管理などでは単純な「最後の書き込みが勝つ」調整も使用される。この柔軟性で、各サービスが最適な解決策を選択できる。
本番環境での最適化
パフォーマンスチューニングと耐久性のバランス
Amazonでは、SLAは99.9パーセンタイルで定義され、Dynamoのほとんどのサービスでは読み取り/書き込み操作の99.9%が300ms以内に実行される必要がある。標準ハードウェアでの高性能実現は容易ではないが、Dynamoは様々な最適化で99.9パーセンタイルで200ms未満のレイテンシーを達成している。
パフォーマンスと耐久性のトレードオフを最適化するため、Dynamoは以下の2つの最適化を実施している。
- メモリ内オブジェクトバッファリング:読み取りがストレージではなくバッファから可能に
- 耐久性書き込み:1レプリカのみに耐久性書き込みを実行し、書き込み操作のパフォーマンスに影響なく耐久性確保
これらの最適化で、小さなバッファ(1000オブジェクト)でも99.9パーセンタイルレイテンシーが5倍改善される。
バックグラウンドvsフォアグラウンドのタスク管理
レプリカ同期やデータハンドオフなどのバックグラウンドタスクがフォアグラウンド操作に影響する問題を、アドミッションコントロールメカニズムで解決。バックグラウンドタスクは共有リソースのスライスを予約し、フォアグラウンドパフォーマンスに基づいてスライス数を調整する。
アドミッションコントローラーはリソースアクセスを常にモニタリングし、レイテンシーが閾値に近づくと、バックグラウンドタスクの活動を制限する仕組みだ。
クライアント駆動型とサーバー駆動型の連携
リクエスト調整には二つのアプローチがある。
- サーバー側状態マシン(デフォルト)
- クライアント主導の調整(クライアントノードに状態マシン移動)
クライアント主導では、10秒ごとにメンバーシップ状態をダウンロードし、ローカルで調整を実行。ロードバランサーが不要で、ネットワークホップも削減できる。測定では99.9パーセンタイルが約30ms、平均が3-4ms改善されている。
実装における実践的考慮事項
パーティショニング戦略の比較
Dynamoのパーティショニングは3つの戦略で進化した。

https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
| 戦略 | 方式 | 主な特徴 | メリット | デメリット |
|---|---|---|---|---|
| 1 | ノードあたりTランダムトークンと トークン値パーティション |
• 各ノードがランダムにトークンを選択 • トークン値によるパーティショニング |
• シンプルな実装 • ランダム分散 |
• 新ノード参加時の完全スキャンが必要 • キー範囲変更時のマークルツリー再計算 • アーカイブが複雑 |
| 2 | ノードあたりTランダムトークンと 均等サイズパーティション |
• ランダムトークンを維持しながら • 均等サイズのパーティション採用 |
• パーティショニングと配置の分離 • ランタイムで配置スキーム変更可能 |
• まだランダム性に依存 • トークン選択の最適性に課題 |
| 3 | ノードあたりQ/Sトークンと 均等サイズパーティション |
• 戦略的トークン配置(Q/S方式) • ノード参加/脱退時のトークン再分配 |
• 最良の負荷分散効率 • メンバーシップ情報サイズを3桁削減 • ブートストラップ/リカバリが高速 • アーカイブが容易 |
• トークン再分配のオーバーヘッド |
比較の結果、戦略3が最良の負荷分散効率を示し、メンバーシップ情報サイズも3桁削減。ブートストラップ/リカバリーが速く、アーカイブも容易になった。
実用的な運用上の課題
主な課題は負荷分散で、低負荷時は不均衡率20%、高負荷時は10%程度。高負荷では多数の人気キーがアクセスされて均等分散されるが、低負荷では少数キーへのアクセスで不均衡が生じる。
運用上の他の課題は次の通り。
- ノード追加時間:混雑期は完了まで最大1日
- マークルツリー再計算とゴシップ通信オーバーヘッド
運用の複雑さは導入障壁の一つだが、クラウドベースのマネージドサービスがこの問題を軽減できる。
結論
AmazonのDynamoは、分散システム技術を組み合わせて高可用性キーバリューストアを実現している。最終的な一貫性を持つストアが本番環境で要求の厳しいアプリケーションに使用できることを示し、実運用ではリクエストの99.9995%が成功応答を受け取り、データ損失は発生していない。
Dynamoの主な利点は(N,R,W)パラメータによる調整の柔軟性だ。一貫性と調整ロジックの問題を開発者に公開することで、アプリケーションが自身のビジネス要件に最適な解決策を選択できる。
Dynamoはクラウドコンピューティング時代のスケーラブルで高可用性のキーバリューストア設計の重要な基礎であり、その設計原則と教訓は現代の多くの分散データベースシステムに影響を与えていると言える。
Discussion