分散メッセージキュー解剖メモ ~ 目先のことに鈍感になれ ~
はじめに
分散メッセージキューシステムについて自分なりに整理するメモ。
分散メッセージキューとは、アプリの部品同士が直接やりとりをするのではなく、間に「キュー」という箱みたいなものを置いて、そこにメッセージ(データ)を一旦入れておく仕組みのこと。
送信側(Producer)はキューにメッセージを放り込むだけ。受信側(Consumer)は自分の好きなタイミングでキューからメッセージを取り出して処理する。お互いが「今、相手は動いてるかな?」とか気にしなくていい(非同期通信)。メッセージはConsumerが取るまでキューが預かってくれるから、途中でConsumerが止まってもメッセージはなくならない。
いろんなところで活躍している。
アーキテクチャと基本概念
分散メッセージキューシステムの基本構造を理解すると、その強力さが見えてくる。まずは基本的なアーキテクチャを眺めてみる。
Publish/Subscribe (Pub/Sub) モデル
分散メッセージキューシステムの基本はPub/Subモデルである。以下の図はその概念を表す。
このモデルにおける各要素の役割は次の通り。
| 要素 | 役割 |
|---|---|
| Producer | メッセージを生成し、特定のTopicに対して発行(Publish) |
| Broker | Producerから発行されたメッセージを受信し、Topicごとに分類して保持・管理。通常、複数のBrokerサーバーでクラスターを構成し、負荷分散と耐障害性を確保。 |
| Consumer | 特定のTopicを購読(Subscribe)し、Brokerからメッセージを受信して処理(Consume) |
Pub/Subモデルの利点は、メッセージを送る側と受け取る側が互いを知る必要がないこと。Producerは「このTopicに関連するニュースがあるよ」と発信するだけで、誰が聞いているかを知らなくていい。一方、Consumerは「このTopicの情報が欲しい」と宣言するだけで、誰が情報を発信しているかを把握する必要がない。これにより、システムの柔軟性と拡張性が向上する。
システムにおける役割
コンポーネント間の直接的な依存関係を排除することで、一方の変更が他方に与える影響を最小限に抑え、開発やメンテナンスの効率を高める。疎結合化は以下の3つの側面から実現される。
| 側面 | 説明 |
|---|---|
| 時間 | Producerとconsumerが同時にアクティブである必要がなく、メッセージはBrokerに保存され、Consumerが利用可能になったときに処理される |
| 空間 | ProducerとConsumerはお互いの物理的なロケーションや接続先を知る必要がない |
| 非同期 | ProducerはメッセージをBrokerに送信した後、Consumerの処理を待たずに次の処理に進める |
この「疎結合」という特性が、現代の分散システムやマイクロサービスアーキテクチャにおいて、メッセージキューが重要な役割を果たしている理由である。例えば、あるサービスが一時的にダウンしても、そのサービス宛のメッセージはキューに安全に保管され、サービスが復旧した後に処理される。これにより、システム全体の頑健性が向上する。
要素技術
分散メッセージキューシステムを支える要素技術を眺める。これらの技術が複雑に組み合わさることで、高いスループットと信頼性を兼ね備えたシステムが実現される。
メッセージングの基本要素
下図の Kafka のアーキテクチャ(Zookeeper依存時代)をベースに基本要素をさらう。
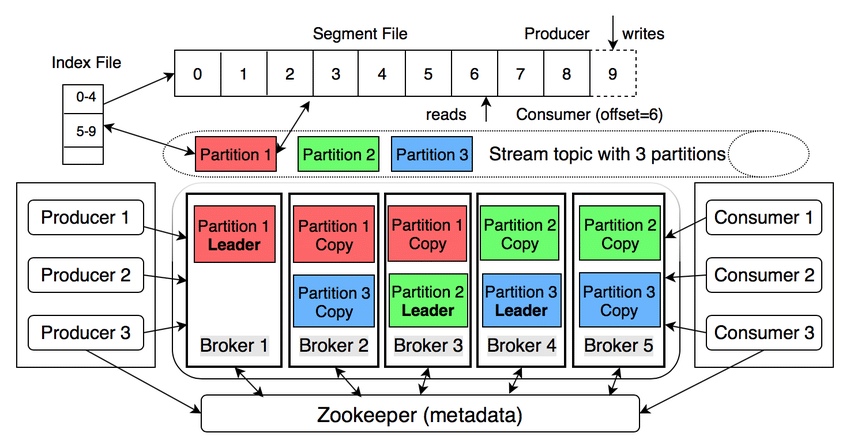
Topic
メッセージの論理的な分類名、あるいはストリーム名。ProducerはこのTopicを指定してメッセージを発行し、ConsumerはこのTopicを購読する。
Topicは、メールのメーリングリストや掲示板のカテゴリのようなもの。「財務情報」「ユーザー登録」「注文情報」といった具合に、メッセージの種類ごとにTopicを作成するのが一般的である。適切なTopicの設計はシステムの効率と管理のしやすさに大きく影響する。
Partition
Topicをさらに分割する物理的な単位。一つのTopicは一つ以上のPartitionで構成される。
| 機能 | 説明 |
|---|---|
| 並列処理 | PartitionごとにConsumerを割り当てることで、メッセージ処理を並列化。Consumer Group内のConsumer数は、通常、Partition数以下になる。 |
| 負荷分散 | メッセージを複数のPartitionに分散させることで、Brokerへの負荷を分散 |
| 順序保証 | 同一Partition内では、メッセージが発行された順序でConsumerに配信されることが保証される。ただし、異なるPartition間のメッセージ順序は保証されない。 |
Partitionは、ファイルシステムでいえばシャード(分散保存)のような役割を果たす。例えば、大量のログメッセージを処理するシステムでは、単一のストレージでは速度的にもスケール的にも限界があるため、複数の物理的なPartitionに分散させることで処理能力を向上させる。
Broker
| 機能 | 説明 |
|---|---|
| メッセージストア | 受信したメッセージをディスクやメモリに保存 |
| フォワーディング | Consumerからの要求に応じてメッセージを配信 |
| クラスター構成 | 複数のBrokerでクラスターを組み、負荷分散、スケーラビリティ、可用性を高める |
Brokerはシステムの「心臓部」として、メッセージの受信、保存、配信を担当する。耐障害性を確保するため、大規模システムでは通常、3台以上のBrokerでクラスターを構成する。
Producer
| 機能 | 説明 |
|---|---|
| メッセージ発行 | Brokerに対してメッセージを送信 |
| バッチ処理 | ネットワーク効率を高めるため、複数のメッセージをまとめて送信する機能を持つことが多い(例: Kafka) |
Producerは情報の「発信者」であり、あらゆるシステムやアプリケーションがProducerになりうる。センサーデータを送信するIoTデバイス、ユーザーアクションを記録するWebサーバー、在庫更新を通知するECサイトのバックエンドなど、多様な情報源がメッセージを発行する。
Consumer
| 機能 | 説明 |
|---|---|
| メッセージ受信 | Brokerからメッセージを取得 |
| 処理ロジック | 受信したメッセージに基づいて、データの保存、分析、他のサービスへの通知など、様々な処理を実行 |
Consumerは情報の「消費者」であり、メッセージを受け取って実際の仕事を行う。データベースに情報を格納するプロセス、リアルタイム分析を行うストリーム処理エンジン、アラートを送信する監視システムなど、様々な形態がある。
Consumer Group
複数のConsumerインスタンスが協調して一つのTopic(または複数のPartition)を消費するグループ。以下の特徴がある。
| 特徴 | 説明 |
|---|---|
| メッセージ配信の排他性 | Topic内のメッセージは、グループ内のいずれか一つのConsumerにのみ配信される |
| 負荷分散と並列処理 | 複数のConsumerで処理を分散することで、処理能力を向上 |
| グループ間の独立性 | 異なるConsumer Groupは、それぞれ独立して同じTopicの全メッセージを受信可能(Pub/Subモデルの実現) |
Consumer Groupは、作業チームのようなもの。同じ仕事(Topicのメッセージ処理)を分担して効率的に進める。あるチーム(Group A)が「顧客データを保存する」という目的でメッセージを処理する一方で、別のチーム(Group B)が「マーケティング分析を行う」という全く異なる目的で同じメッセージを処理することも可能だ。
メッセージデータ構造
分散メッセージキューシステムでやり取りされるメッセージは、一般的に以下の要素で構成される。特にKafkaのようなシステムでは、これらの要素が重要な役割を果たす。
| 構成要素 | 説明 | Kafkaにおける役割・特徴 |
|---|---|---|
| キー (Key) | メッセージを識別またはグループ化するためのオプションのデータ。バイト列。 | ・Partition割り当て。キーが存在する場合、キーのハッシュ値に基づいてメッセージが送信されるPartitionが決定される。これにより、同じキーを持つメッセージは常に同じPartitionに送信され、そのPartition内での順序が保証される。 ・キーが存在しない(null)場合、デフォルトではRound Robin方式でPartitionに割り当てられることが多い。 ・キー自体もシリアライズされてバイト列として送信される(例: IntegerSerializer, StringSerializer)。 |
| ペイロード (Value) | 実際のデータ本体。バイト列。 | ・アプリケーションが送受信したい主たる情報(例: JSON文字列、センサーデータ、イベント情報)。 ・Producer側で適切なシリアライザ(例: StringSerializer, AvroSerializer, ProtobufSerializer)によってオブジェクトからバイト列に変換され、Consumer側で対応するデシリアライザによってバイト列からオブジェクトに復元される。 |
| ヘッダー (Headers) | Key-Value形式のメタデータ(付加情報)のリスト。オプション。 | ・メッセージ自体に関する追加情報(例: 送信元システムID、トレースID、スキーマバージョンなど)を付与するために使用される。 |
| タイムスタンプ (Timestamp) | メッセージが作成された時刻、またはBrokerに受信された時刻。 | ・イベント発生時刻の記録や、時間ベースでのデータ処理(例: ウィンドウ処理)に使用される。Producerが付与するか、Brokerが受信時に付与するか設定可能。 |
| オフセット (Offset) | Partition内でのメッセージの論理的な位置を示す一意で単調増加する番号 。 | ・Brokerによって自動的に割り当てられる。 ・Consumerはこのオフセットを記録・管理することで、どこまでメッセージを読み進めたかを把握し、障害からの復旧や再開を可能にする。 ・Partition番号とオフセットの組み合わせで、Topic内のメッセージを一意に特定できる。 |
| Partition番号 | メッセージが属するPartitionの番号。 | Producerクライアントが(通常はキーに基づいて、またはRound Robinで)決定し、メッセージを送信する対象のPartitionを示す。BrokerはそのPartitionにメッセージを格納する。 |
Pull vs Push モデル
| モデル | 説明 | メリット | デメリット | 代表例 |
|---|---|---|---|---|
| Pull | Consumerが自身のタイミングでBrokerにメッセージを取りに行く方式 | ・Consumerは自身の処理能力に合わせてメッセージを取得可能(流量制御が容易) ・メッセージの再読み込み(リワインド)が容易 |
・メッセージ到着の遅延がPushモデルより大きくなる可能性 | Kafka |
| Push | Brokerが能動的にConsumerにメッセージを送り届ける方式 | ・メッセージ到着の遅延が少ない | ・Consumerの処理能力を超えてメッセージが送られる可能性(別途流量制御が必要) | RabbitMQの一部 |
Pull/Pushモデルの違いは、レストランでの食事と宅配の違いに似ている。Pullモデルはレストランに自分で行き、自分のペースで料理を注文して食べるようなもの。一方、Pushモデルは宅配サービスで、料理が準備できたらすぐに自宅に届けられる。どちらが良いかは状況によって異なる。
信頼性と可用性
Replication (レプリケーション)
Partitionのデータを複数のBrokerに複製して保持する仕組み。
| 特徴 | 説明 |
|---|---|
| Leader-Follower構造 | 各Partitionにリーダー(Leader)とフォロワー(Follower)が存在。書き込みはリーダーが行い、フォロワーがそれを複製。 |
| 障害時の引継ぎ | リーダーに障害が発生した場合、フォロワーの一つが新しいリーダーに昇格。 |
| レプリケーション係数 | 何台のBrokerにデータを複製するかを示す値。通常は3が推奨(1つのリーダーと2つのフォロワー)。 |
レプリケーションは保険のようなもの。何かあったときのために同じデータの複数のコピーを異なるサーバーに保持しておく。これにより、一部のサーバーが故障してもシステム全体は動き続けることができる。このような冗長性はもはや贅沢ではなく、必須の要素となっている。
ACK (Acknowledgement - 確認応答)
メッセージが正しく処理されたことを確認するための応答。
| 種類 | 説明 | トレードオフ |
|---|---|---|
| Producer ACK | ProducerがBrokerにメッセージを送信し、Brokerがそれを正しく受信・永続化したことを確認する応答。 | ACKのレベル(リーダーのみ、指定数のフォロワー含むなど)によって、信頼性とパフォーマンス(レイテンシ)のトレードオフが発生。 |
| Consumer ACK | Consumerがメッセージを正しく受信し、処理を完了したことをBrokerに通知する応答(RabbitMQなどで重要)。 | 処理中にConsumerが失敗した場合に、メッセージが再配信されることを保証。 |
Kafkaにおいては、Producer ACKレベルとして以下のような選択肢がある。
| ACKレベル | 意味 | 信頼性 | レイテンシ |
|---|---|---|---|
| 0 | Producerはレスポンスを待たない | 低(メッセージ損失の可能性大) | 最小 |
| 1 | リーダーのみが応答 | 中(リーダー障害時に損失の可能性) | 中 |
| all (-1) | リーダーと指定された数のフォロワーが応答 | 高(適切な設定で損失なし) | 最大 |
金融取引のような厳密な整合性が要求される領域では「ack=all」が選択される一方、リアルタイム広告入札のような超低レイテンシが求められる領域では「ack=1」もしくは「ack=0」が選択されることもある。
配信保証 (Delivery Guarantees)
メッセージがConsumerに何回配信されるかを保証するレベル。
| 保証レベル | 説明 | 適用場面 | 実装方法 |
|---|---|---|---|
| At-most-once (最大1回) | メッセージは最大1回配信されるが、失われる可能性あり。 | データの一部損失が許容される高スループットシステム | ACKを待たずに処理を進める |
| At-least-once (少なくとも1回) | メッセージは失われることはないが、重複して配信される可能性あり。 | データ損失が許容されないシステム。Kafkaのデフォルト。 | Producerが適切なACKを受け取るまで再送を試みる。アプリケーション側で重複排除(冪等性確保)が必要。 |
| Exactly-once (厳密に1回) | メッセージは厳密に1回だけ配信される。 | 重複も損失も許容されない金融取引など | トランザクション処理や冪等プロデューサー/コンシューマーなどの高度で複雑な仕組みが必要。パフォーマンスへの影響大。 |
配信保証は宅配サービスの品質保証に似ている。At-most-onceは「配達を試みるが、不在なら持ち帰り再配達なし」、At-least-onceは「確実に配達するが、場合によっては同じ荷物が複数回届く可能性あり(あくまで理論です)」、Exactly-onceは「確実に1回だけ配達、二重配達も紛失もなし」といったイメージだ。
メッセージ永続化 (Persistence)
Brokerが受信したメッセージをディスクなどの永続記憶装置に保存することで、Brokerが再起動した場合でもメッセージが失われないようにする。
| 実装例 | 特徴 |
|---|---|
| Kafka | OSのページキャッシュを積極的に利用し、ディスクへのシーケンシャル書き込みを行うことで永続化と高スループットを両立。 |
| RabbitMQ | キュー作成時に永続化オプション(Durable)を指定可能。 |
協調と管理
Rebalancing (リバランシング)
Consumer Group内でConsumerの追加や削除、またはBrokerの障害が発生した際に、各Consumerが担当するPartitionの割り当てを自動的に再調整するプロセス。
| 特徴 | 説明 |
|---|---|
| 自動調整 | Consumerの変動やBrokerの障害時に自動的にPartitionの割り当てを再調整 |
| 調整サービス | Kafkaでは、この調整のためにZooKeeper(最近のバージョンではKafka内部のコントローラー)のような調整サービスを利用 |
| 処理の一時停止 | リバランシング中は一時的にメッセージの処理が停止することがある |
| リバランス戦略 | Range, RoundRobin, Stickyなど様々な割り当て戦略が存在。Kafkaの場合、バージョンによって利用可能な戦略が異なる。 |
リバランシングは、オフィスの仕事の再分配のようなもの。ある社員が休暇を取ったり、新しいメンバーが加わったりした場合に、仕事を公平に再分配するプロセスだ。ただし、再分配中は一時的に仕事が停滞することがあるため、頻繁なリバランシングは避けることが望ましい。
Offset Management (オフセット管理)
ConsumerがTopicのPartitionをどこまで読み進めたか(最後に処理したメッセージのオフセット)を記録・管理する。
| 実装例 | 特徴 |
|---|---|
| Kafka | Consumer自身がオフセットを管理し、定期的にBrokerまたは外部ストア(ZooKeeperやKafka自身の専用Topic)にコミット。これにより、Consumerが再起動した際に、前回の続きから処理を再開可能。また、意図的に古いオフセットから読み直す(リワインド)ことも可能。 |
| 他のシステム | Brokerが管理する場合もある。 |
オフセット管理は、本の栞(しおり)のようなもの。読書を中断した際に、どのページまで読んだかを覚えておき、次回は続きから読み始めることができる。Kafkaでは、この栞を明示的に保存(コミット)する必要があり、コミットのタイミングと頻度は重要な設計判断となる。
ルーティングとフィルタリング
メッセージをどのQueueやConsumerに届けるかを決定する仕組み。
| 方式 | 説明 | 実装例 |
|---|---|---|
| Topicベース | 最も一般的で、Topic名に基づいて配信先が決まる | Kafka, 多くのPub/Subシステム |
| コンテンツベース | メッセージの内容(ヘッダー属性など)に基づいてフィルタリングし、条件に合致するConsumerにのみ配信 | RabbitMQなど |
| Exchange-Binding (AMQP) | ExchangeとQueueの間にBindingと呼ばれるルールを設定し、柔軟なルーティングを実現 | RabbitMQ |
AMQPでは、以下のようなExchangeタイプが定義されている。
| Exchangeタイプ | 動作 |
|---|---|
| Direct | ルーティングキーが完全一致するQueueにのみ配信 |
| Topic | ワイルドカードを含むパターンマッチングでルーティングキーを評価し、マッチするQueueに配信 |
| Fanout | ルーティングキーを無視し、接続されている全てのQueueに配信 |
| Headers | メッセージヘッダーの属性に基づいてルーティング |
ルーティングとフィルタリングは、郵便局の仕分け作業のようなもの。宛先や内容に応じて適切な配送先に振り分ける。特にRabbitMQのような高度なルーティング機能を持つシステムでは、非常に複雑なルールに基づいた配信が可能になる。
スキーマ管理
ProducerとConsumer間でメッセージのデータ構造(スキーマ)の互換性を保証するための仕組み。
| 技術 | 説明 |
|---|---|
| スキーマ定義言語 | Avro, Protobuf, JSON Schemaなどの言語を使用してデータ構造を定義 |
| Schema Registry | スキーマを集中管理するサービス(例: Confluent Schema Registry)。スキーマのバージョニングや互換性チェックを行う。 |
| バージョニング | スキーマの変更をバージョン管理し、互換性をチェック。前方互換性(新しいConsumerが古いデータを読める)と後方互換性(古いConsumerが新しいデータを読める)を確保。 |
スキーマ管理は、言語の文法と辞書のようなもの。Producerが送信するメッセージの構造とConsumerが期待するメッセージの構造が一致しなければ、コミュニケーションは成立しない。Schema Registryは、共通の辞書を管理し、バージョンの異なるProducerとConsumerの間でも「翻訳」ができるようにサポートする。
フロー制御 / バックプレッシャー
Producerのメッセージ発行レートがConsumerの処理レートやBrokerの処理能力を上回った場合に、システム全体が破綻しないように流量を制御する仕組み。
| モデル | 仕組み |
|---|---|
| Pullモデル | Consumerが自身のペースで取得するため、比較的制御しやすい |
| Pushモデル | BrokerやConsumer側で受信バッファサイズ制限やACKの遅延などを利用して、Producer側に発行を抑制するよう促す(バックプレッシャー)仕組みが必要 |
各実装における具体的な制御方法は以下の通り。
| 実装 | 制御方法 |
|---|---|
| Kafka | Consumerが自身のペースでPullするため自然に制御。また、ProducerからBrokerへのバックプレッシャーはバッファサイズの制限やACKタイムアウトによって実現。 |
| RabbitMQ | キューの深さに基づく流量制御、consumer prefetchカウント設定、キュー長に基づくブロッキングなどの機能を提供。 |
バックプレッシャーは、水道のバルブのようなもの。水(メッセージ)の流れが速すぎると配管(システム)が破裂する恐れがあるため、適切に流量を調整する。適切なバックプレッシャー機構がないと、高負荷時にシステムが不安定になり、最悪の場合はメッセージ損失やシステムクラッシュを招く。
セキュリティ
| 要素 | 説明 |
|---|---|
| 認証 | 正当なProducer/Consumer/Brokerであることを確認(例: SASL, TLSクライアント証明書) |
| 認可 | Topicへの読み書き権限などを制御(ACL: Access Control List) |
| 通信の暗号化 | Brokerとクライアント間、Broker間の通信をTLS/SSLで暗号化し、盗聴や改ざんを防止 |
代表的な実装例
分散メッセージキューには様々な実装が存在する。ここでは代表的なものをいくつか眺める。
Apache Kafka
LinkedInによって開発され、現在はApacheソフトウェア財団のトップレベルプロジェクト。元々はログ処理のために設計され、高スループットとスケーラビリティに重点を置いている。
| 項目 | 詳細 |
|---|---|
| 概要 | 高スループットで耐障害性の高い分散メッセージングシステム。分散ログファイルとしてメッセージを管理するアーキテクチャが特徴。 |
| アーキテクチャ | ・分散コミットログ: Topic/Partitionをディスク上のログファイルとして永続化 ・Pullモデル: ConsumerがBrokerからデータを能動的に取得 ・Consumerによるオフセット管理: Consumerが自身の読み取り位置を管理 ・ZooKeeper依存(以前): クラスター管理やリーダー選出にZooKeeperを利用。近年KRaftプロトコルによりZooKeeperレス構成も可能に。 |
| 主要機能 | ・高いスループットと低いレイテンシ(OSページキャッシュ、sendfile API、バッチ処理の活用) ・永続性、耐障害性(レプリケーション) ・Consumer Groupによる負荷分散とPub/Sub ・Kafka Streams: ストリーム処理ライブラリ ・Kafka Connect: 外部システムとの連携フレームワーク |
| 利用シーン | 大規模ログ集約、リアルタイム分析パイプライン、イベントソーシング、マイクロサービスの非同期通信、Webサイトアクティビティ追跡 |
Kafkaは現代の分散システムの中核として広く採用されている。特に「ログはキューである」という発想は、多くの新しいアーキテクチャパターンを可能にした。
RabbitMQ (AMQP実装)
Erlangで実装されたメッセージブローカー。AMQP (Advanced Message Queuing Protocol) の代表的な実装の一つで、柔軟なルーティングとメッセージ配信の信頼性に重点が置かれている。
| 項目 | 詳細 |
|---|---|
| 概要 | AMQPを実装した信頼性の高いメッセージブローカー。MQTT, STOMPなど他のプロトコルもサポート。 |
| アーキテクチャ | ・ExchangeとQueue: ProducerはExchangeにメッセージを送信し、ExchangeがBindingルールに基づいてQueueにルーティング ・多様なExchangeタイプ: Direct, Topic, Fanout, Headersの4種類があり、様々なルーティングロジックを実現 |
| 主要機能 | ・柔軟なルーティング ・Push/Pullモデルの選択が可能 ・メッセージ永続化オプション(Durable Queue/Message) ・Consumer ACKによる確実なメッセージ処理 ・優先度付きキュー、TTL(Time To Live)などの機能 ・管理UIとプラグイン機構 |
| 利用シーン | エンタープライズアプリケーション統合、マイクロサービス間の信頼性の高い通信、タスクキュー、通知システム、金融システムなど、柔軟なルーティングや確実な配信が求められる場面 |
RabbitMQはその柔軟性と信頼性で多くの企業に愛用されている。特にルーティングの多様性は、複雑なメッセージングニーズに対応する強力な武器となっている。Erlangという比較的マイナーな言語で実装されていながら、安定性と可用性の高さで定評がある。
その他のシステム
| システム | 概要 |
|---|---|
| Apache ActiveMQ | Javaベースのメッセージブローカー。JMS (Java Message Service) 仕様の完全実装として有名。AMQP, MQTT, STOMPなどもサポート。 |
| Apache RocketMQ | Alibabaによって開発された分散メッセージングおよびストリーミングプラットフォーム。高いスループット、低レイテンシ、高可用性を特徴とする。 |
| Apache Pulsar | Yahoo!によって開発された分散Pub/Subメッセージングシステム。KafkaとRabbitMQの特徴を併せ持ち、マルチテナンシー、Geoレプリケーション、階層型ストレージなどの先進的な機能を提供。 |
クラウドベースのサービス
| サービス | 概要 |
|---|---|
| Amazon SQS (Simple Queue Service) | AWSのフルマネージドなメッセージキューイングサービス。標準キューとFIFOキューを提供。 |
| Google Cloud Pub/Sub | Googleのグローバルにスケーラブルなフルマネージドリアルタイムメッセージングサービス。 |
クラウドネイティブな環境では、これらのマネージドサービスが人気を集めている。運用の手間を大幅に削減でき、従量課金制で柔軟にスケールできる利点がある。特にスタートアップやクラウドネイティブなアプリケーションでは、これらのサービスが第一選択肢となることが多い。
ブローカーレスの実装
| 実装 | 概要 |
|---|---|
| ZeroMQ (ØMQ) | 軽量なメッセージングライブラリ。Brokerを介さず、ソケットベースで様々な通信パターン(Pub/Sub, Request/Reply, Push/Pullなど)を構築可能。 |
ブローカーレスのアプローチは、超低レイテンシが要求される特殊なユースケースで選択される。中間のBrokerを省略することで、通信の遅延を最小限に抑えられるが、信頼性やスケーラビリティの面では一般的にBrokerベースのシステムに劣る。
課題と考慮事項
分散メッセージキューシステムは強力であるが、導入・運用にはいくつかの課題と考慮点がある。
パフォーマンスチューニング
| 課題 | 説明 |
|---|---|
| トレードオフ | スループット、レイテンシ、信頼性(ACKレベル、永続化設定など)はトレードオフの関係にある。ユースケースに合わせて最適なパラメータ設定を見つける必要がある。 |
| パラメータ最適化 | 多数の設定項目があり、最適な組み合わせを見つけるのは困難な場合がある。負荷テストに基づいたチューニングや、近年では機械学習を用いた自動最適化(例: DMSCO)の研究も進んでいる。 |
運用上の複雑さ
| 課題 | 説明 |
|---|---|
| クラスター管理 | Brokerクラスターの構築、監視、スケール、アップグレードには専門知識が必要。 |
| 調整サービス | KafkaにおけるZooKeeper/KRaftなど、協調・管理サービスの運用も必要になる場合がある。 |
運用の複雑さは、分散メッセージキューシステムの導入における最大の障壁の一つである。特に自社運用の場合、専門知識を持ったエンジニアの確保が課題となる。この点は、クラウドベースのマネージドサービスの大きなアドバンテージとなっている。
メッセージ順序保証
| 課題 | 説明 |
|---|---|
| Partition内保証 | 同一Partition内での順序は保証される。 |
| Partition間保証の限界 | 複数のPartitionにまたがるメッセージの順序は基本的に保証されない。厳密な順序が必要な場合は、単一Partitionにするか、アプリケーション側で順序を再構築する必要がある。 |
スケーラビリティの課題
| 課題 | 説明 |
|---|---|
| Partition数の制約 | Partition数を増やしすぎると、管理オーバーヘッドが増加する可能性がある(特にリーダー選出やリバランス時)。 |
| リソース消費 | Broker数やConsumer数の増加に伴うネットワーク帯域や調整サービスの負荷。 |
Exactly-once処理の難しさ
| 課題 | 説明 |
|---|---|
| 実装の複雑さ | 理論上は可能だが、実装は複雑で、パフォーマンスへの影響も大きい。 |
| 現実的なアプローチ | 多くの場合、At-least-once + アプリケーション側での冪等性(重複処理しても結果が変わらないようにする)確保が現実的な解決策となる。 |
Exactly-once処理は、分散システムにおける「聖杯」の一つである。理論的には可能でも、実際の実装は複雑になりがちである。多くの現実世界のシステムでは、「少なくとも1回」の保証と、アプリケーション側での重複処理対策の組み合わせが採用されている。
まとめ
分散メッセージキューシステムの世界は、まるで高度に組織化された郵便システムのようなものだ。メッセージ(小包)は、Producer(差出人)からBroker(郵便局)を経由してConsumer(受取人)に届けられる。この間、信頼性を確保するためのACK(配達証明)や、順序を保証するためのPartitioning(仕分け)、障害に備えたReplication(バックアップ)などの仕組みが働いている。
モダンな分散システムの中核として、メッセージキューは目に見えない形で私たちの生活を支えている。Netflixの動画推薦から銀行の取引処理、IoTデバイスのセンサーデータ収集まで、膨大な量の情報が日々やり取りされているのだ。
今日、お気に入りのECサイトで注文したあの商品も、恐らく裏側では複数のマイクロサービス間でメッセージキューを介した情報のやり取りが行われているに違いない。
ちょっとだけ理解した。もっと探求したいトピックはたくさんある。
Discussion