ストリーム処理進化史の解剖メモ ~ Everything is a stream ~
はじめに
現代のデジタル社会では、ウェブのログ、モバイル使用統計、センサーネットワークなど、膨大な量のデータが継続的に生成されている。これらの無限のデータセットからタイムリーで意味のある洞察を抽出することは非常に重要だが、同時に大きな課題でもある。
この記事では、データストリーム処理の進化と主要技術について調査メモをまとめる。
参考にしたのは「A Survey on the Evolution of Stream Processing Systems」。
ストリーム処理の世代
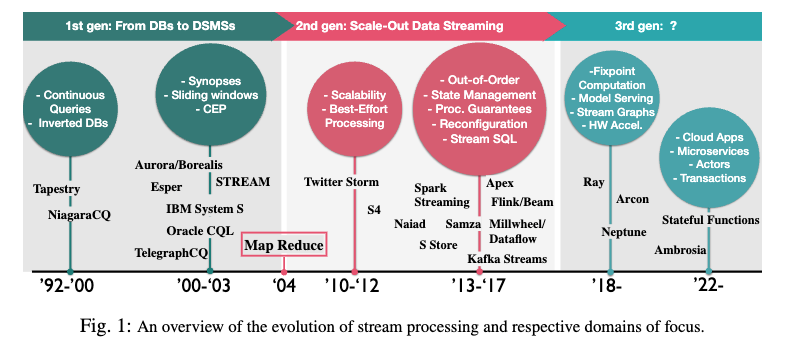
ストリーム処理システムは大きく3つの世代に分けられる。
https://arxiv.org/pdf/2008.00842
各世代の特徴とそれぞれの時代に注目された技術領域を以下の表にまとめる。
| 世代 | 期間 | 主な特徴 | 代表的なシステム |
|---|---|---|---|
| 第1世代 DBからDSMSへ |
1992-2010 | ・継続的クエリ ・転置DB ・スライディングウィンドウ ・CEP(Complex Event Processing) ・関係演算の拡張として設計 |
・Tapestry ・NiagaraCQ ・Aurora/Borealis ・TelegraphCQ ・STREAM ・IBM System S ・Oracle CQL |
| 第2世代 スケールアウトデータストリーミング |
2010-2017 | ・スケーラビリティ ・ベストエフォート処理 ・順序外処理 ・状態管理 ・処理保証 ・再構成 ・Stream SQL |
・Twitter Storm ・S4 ・Spark Streaming ・Flink/Beam ・Millwheel ・Dataflow ・Samza ・Kafka Streams |
| 第3世代 | 2018- | ・固定点計算 ・モデルサービング ・ストリームグラフ ・ハードウェアアクセラレーション ・クラウドアプリ ・マイクロサービス ・アクター ・トランザクション |
・Ray ・Arcon ・Neptune ・Ambrosia ・Stateful Functions |

https://arxiv.org/pdf/2008.00842
技術コンポーネントの進化
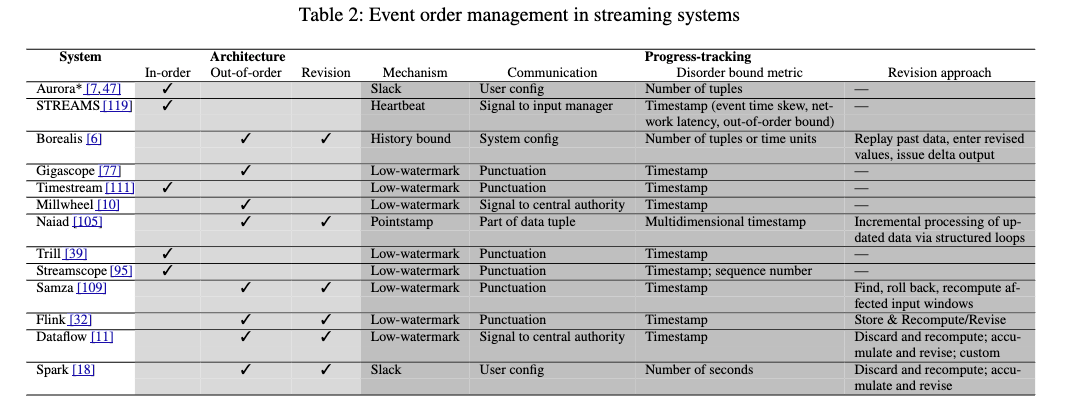
順序外データ管理
データストリームでは、ネットワーク遅延やパケットロスなどの理由で、データは必ずしも順序通りに到着しない。これに対処するため、様々なメカニズムが開発されてきた。
https://arxiv.org/pdf/2008.00842
| 世代 | 順序管理アプローチ | 主なメカニズム |
|---|---|---|
| 第1世代 | インオーダー処理 | ・Slack(Aurora) ・Heartbeats(STREAM) ・バッファリングと再順序付け |
| 第2世代 | アウトオブオーダー処理 | ・Low-watermark(Millwheel, Flink) ・Pointstamps(Naiad) |
順序外データ管理の主要メカニズム
Slack
Slackは単純なメカニズムで、特定のメトリックに基づいて順序外データを一定期間待機するものだ。元々はタプルの実際の発生と、それがタイムリーに到着していれば入力ストリームで占めていたはずの位置との間に介在するタプル数を表していた。簡単に言えば、遅延タプルのための固定の猶予期間を設けるものだ。

https://arxiv.org/pdf/2008.00842
このシンプルな集約オペレータは、4秒のイベント時間タンブリングウィンドウでタプルをカウントする。入力として、t=1からt=7までの異なるタイムスタンプを持つ7つのタプルを受け取る。オペレータは順序外データを許容するためにSlack=1を使用している。タプルt=1とt=2を受け取った後、次にタプルt=4を受け取る(ズームイン箇所)。このタイムスタンプは第1ウィンドウ[0,4)の最大タイムスタンプと一致する。通常はこのタプルがウィンドウを閉じて集約を計算させるが、Slack=1の設定により、システムはもう1タプル待機する。
次のタプルt=3がウィンドウに含まれ、Slackの期限が切れてウィンドウ計算がトリガーされ、t=[1,2,3]の3タプルに対してC=3を出力する。t=5は到着時に2タプルの遅延があり、Slack=1でカバーされないため、処理に含まれない。
Heartbeats
Heartbeatはデータストリームに関する進行情報を伝える外部シグナルだ。このタイムスタンプ以降のすべてのタプルは、Heartbeatのタイムスタンプよりも大きいタイムスタンプを持つことを示す。

https://arxiv.org/pdf/2008.00842
入力マネージャーは到着タプルをタイムスタンプでバッファリングし、順序付けする。バッファされたタプル数(この場合は2つ:t=5、t=6)は重要ではない。ソースは定期的にタイムスタンプを持つHeartbeatをマネージャーに送信する。入力マネージャーは、Heartbeatのタイムスタンプ以下のタプルをオペレータに昇順で送出する。
Heartbeatのタイムスタンプt=4が到着すると、入力マネージャーはHeartbeatのタイムスタンプ以下のすべてのタプルを昇順でオペレータに送出する。タプルt=4のディスパッチが第1ウィンドウ[0,4)の計算をトリガーし、C=2を出力(t=1とt=2の2タプル)。遅れて到着したタプルt=3は最新のHeartbeatタイムスタンプt=4より古いため、入力マネージャーによって無視される。
Low-watermark
Low-watermarkは、ストリームの特定の属性Aについて、ストリームの特定のサブセット内のAの最小値を示す。つまり、将来のタプルは現在のLow-watermarkよりも高い値を持つ可能性が高い。多くの場合、Aはタプルのイベント時間タイムスタンプだ。
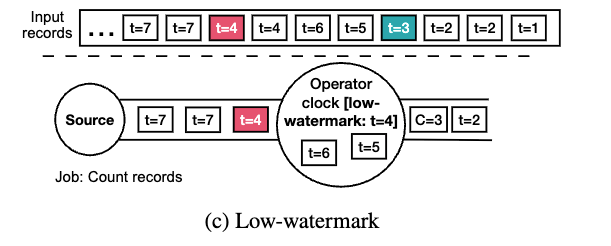
https://arxiv.org/pdf/2008.00842
オペレータはt=1とt=2の2タプルを受け取り、t=2に対応するLow-watermark、そしてタプルt=3を受け取る。次にタプルt=5を受け取ると、イベント時間タイムスタンプが4以上(第1ウィンドウの終了タイムスタンプ)であるため、このタプルがウィンドウを閉じる可能性がある。しかし、このアプローチは順序外データを考慮しない。代わりに、Low-watermark t=4を受け取るとウィンドウが閉じる。
オペレータはt=[1,2,3]の3タプルに対してC=3を計算し、タプルt=[5,6]を第2ウィンドウ[4,8)に割り当てる。タプルt=4は現在のLow-watermark値t=4より大きくない(最近でない)ため、処理に含まれない。
Pointstamps
Pointstampsはパンクチュエーションと同様にデータストリームに埋め込まれるが、パンクチュエーションが別のタプルを形成するのに対し、Pointstampは各データタプルにアタッチされる。Pointstampsはタイムスタンプと位置のペアで、データタプルをデータフローグラフの頂点または辺の特定の時点に配置する。
Naiadで採用されたPointstampsは、処理の進行状況をトラッキングするための強力なモデルを提供する。タイムスタンプtのある未処理のタプルpが、別の場所にある別の未処理のタプルp'をもたらす可能性があるとき、「could-result-in」関係が成立する。未処理のタプルpがcould-result-in関係に基づく処理フロンティアにあると、tまたはそれより早いタイムスタンプを持つタプルは処理され、フロンティアが前進する。

https://arxiv.org/pdf/2008.00842
3つのアクティブポイントスタンプを含む例を示す。ポイントスタンプは1つ以上の未処理イベントに対応するときにアクティブとなる。
左側(a):ポイントスタンプ(1, OP1)がアクティブポイントスタンプのフロンティアにある(プレカーソルカウント0)。このフロンティアでは未処理イベントの通知を配信できる。イベントe1とe2をOP2とOP3に配信できる。
右側(b):イベントe1とe2が処理され、新しいイベントe5とe6が生成される。これらは未処理イベントe3とe4と同じポイントスタンプを持つ。タイムスタンプ1のイベントがなくなり、ポイントスタンプ(2, OP2)と(2, OP3)のプレカーソルカウントが0になるため、フロンティアがこれらのアクティブポイントスタンプに移動する。
順序外データ管理メカニズムの比較
以下は各メカニズムの主な違いと特性だ。
| メカニズム | 特性 | 進行度追跡方式 | データストリームとの関係 |
|---|---|---|---|
| Slack | ・固定の猶予期間 ・単純な実装 ・ユーザー指定のパラメータ |
固定量の遅延を許容 | 外部(クエリパラメータ) |
| Heartbeats | ・シグナリングベース ・ソースまたはシステムが生成 ・環境パラメータに基づく推定が可能 |
入力ソースでの進行状況 | 外部(シグナル) |
| Low-watermark | ・より一般的な概念 ・任意の進行属性に適用可能 ・システム内部の進行状況を反映 |
システム内の最も古い保留中の作業 | データストリームに埋め込まれる(パンクチュエーション) |
| Pointstamps | ・細粒度の制御 ・循環クエリをサポート ・進行度と場所の両方を追跡 |
幅広い依存関係のグラフを追跡 | データタプルにアタッチ |
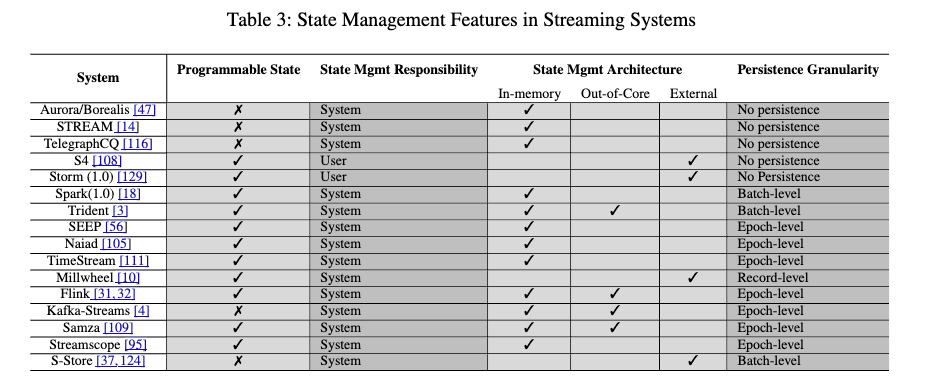
状態管理
ストリーム処理における「状態」は、継続的なストリーム計算の内部副作用をすべて捕捉するものだ。ウィンドウ、レコードのバケット、集計の部分結果など、アプリケーションで使用されるすべてのものを含む。
https://arxiv.org/pdf/2008.00842
| 世代 | 状態管理の特徴 | 永続性粒度 |
|---|---|---|
| 第1世代 | ・システム定義の内部状態 ・主にメモリ内 ・限定的なユーザー制御 |
・永続性なし ・主にメモリ内 |
| 第2世代 | ・明示的なAPI ・ユーザー定義状態 ・パーティション化された状態 ・メモリを超える大規模状態 |
・レコードレベル(Millwheel) ・エポックレベル(Flink, Samza) ・バッチレベル(Spark) |
プログラマビリティと責任
状態はプログラミングモデルで暗黙的または明示的に宣言および使用できる。
| アプローチ | 説明 | 長所 | 短所 | システム例 |
|---|---|---|---|---|
| システム定義状態 | ・システム設計者が定義 ・内部オペレータが使用 ・「シノプシス」とも呼ばれる |
・最適化された実装 ・ユーザーの複雑さを軽減 |
・表現力が限られる ・関係演算の限定的なサブセット |
・STREAM ・Aurora/Borealis |
| ユーザー管理状態 | ・ユーザーが状態を宣言・管理 ・フレームワークが提供するメモリ内で使用 ・または外部に保存 |
・柔軟性 ・実装の自由度 |
・永続性、拡張性などの管理が必要 ・追加の複雑さ |
・Storm 1.0 ・S4 |
| ユーザー定義/システム管理状態 | ・ユーザーがAPIを通じて状態を定義 ・システムが状態を管理 |
・豊かな表現力 ・障害耐性などのシステムサポート |
・データ構造の直接制御が制限される | ・Flink ・Spark Streaming ・Samza |
初期のデータストリーム管理システムでは、メインメモリが限られていたため、状態はシステムオペレータの実装をサポートする補助的な役割だった。ユーザーはこの状態を意識せず、その暗黙的な性質はDBMSの中間結果の使用に似ていた。STREAM、Aurora/Borealisなどのシステムは、ウィンドウ最大値、結合インデックス、入力ソースバッファなど、さまざまなオペレータをサポートするためにストリームアプリケーションのデータフローグラフに特別な「シノプシス」をアタッチした。
MapReduce以降の時代では、計算のスケーラビリティに焦点が当てられ、Storm、S4などのシステムはタスクの分散パイプラインの構成を可能にしたが、状態管理は提供せず、すべてをプログラマに委ねた。ユーザー管理状態は柔軟性を提供するが、永続性、メモリ外スケーラビリティ、必要なサードパーティのストレージシステムの統合などについて考慮する必要がある。
現在、ほとんどのストリーム処理システムはステートフル処理APIを通じてユーザー定義状態のレベルを許可し、システムがアクセスして永続性、スケーラビリティ、障害耐性のためのデータ管理メカニズムを使用できるようにしている。
状態管理アーキテクチャ

https://arxiv.org/pdf/2008.00842
データストリームランタイムシステムにおいて、3つの異なるステートフル処理の方向性が観察されている。
| アーキ | 説明 | 利点 | 課題 | 代表例 |
|---|---|---|---|---|
| インメモリ | ・メインメモリ内のデータ構造に状態を保存 ・各ノードで利用可能なメモリに限定 |
・高速アクセス ・低レイテンシ |
・メモリ容量に制限 ・永続性の欠如 |
・初期のシステム ・小規模状態アプリケーション |
| アウトオブコア | ・複数のストレージメディアを使用 ・LSM-Treeなどの階層的構造 ・FASTER、RocksDBなどを使用 |
・大規模状態の管理 ・メモリと永続性のバランス |
・アクセス時間の増加 ・ソフトウェアスタックの複雑化 |
・Flink(RocksDB) ・最新の多くのシステム |
| 外部 | ・計算と状態を分離 ・外部データベースやキーバリューストアを使用 ・クラウドフレンドリー設計 |
・モジュラー設計 ・データベースシステムの機能再利用 ・スケーラビリティ |
・レイテンシの増加 ・外部依存関係の管理 |
・Millwheel(BigTable) ・Google Dataflow ・Apache Storm(外部KVストア) |
Millwheelでは、タスクは事実上ステートレスだ。最近のローカル変更をメモリに保持するが、すべての作業状態とログ、チェックポイントを単一のトランザクションとしてBigTableにコミットする。これにより、非べき等更新のための強力な保証が提供されるが、高いレイテンシが発生する可能性がある。
永続性の粒度
永続性の粒度とは、ストリーミングシステムが状態のスナップショットを作成する粒度を指す。
| 粒度 | 説明 | 利点 | 課題 | 採用システム |
|---|---|---|---|---|
| エポックレベル | ・定期的または特定のイベント数後 ・アプリケーションレベルのスナップショット ・通常は非同期の一貫したスナップショット |
・バッチ最適化の機会 ・回復時間と容量のバランス |
・エポック間の状態損失の可能性 ・遅延変動 |
・Flink ・Samza ・Streamscope |
| バッチレベル | ・厳密なマイクロバッチング処理 ・バッチ処理後に保存 |
・バッチごとの簡単な一貫性保証 ・実装の単純さ |
・レイテンシの増加 ・バッチ境界に依存 |
・Spark Streaming ・Trident/Storm ・S-Store |
| レコードレベル | ・各出力のエポックモデル ・各状態遷移を保存 |
・細粒度の回復 ・厳密な一貫性保証 |
・高いオーバーヘッド ・ストレージ最適化の必要性 |
・Millwheel ・Google Cloud Dataflow |
一貫性と永続性の管理
ストリーム処理における一貫性は、障害やその他の変更の際にシステムが提供できる保証に関連している。多くのシステムはトランザクショナルな処理システムとなり、一貫性ルールと処理保証によって管理されている。
イベント粒度での状態永続性
Millwheelのようなシステムでは、ローカルアクションごとにトランザクションを採用している。各計算アクション(入力イベント、状態遷移、生成された出力を含む)をBigTableにコミットする「“strong productio"」と呼ばれるアプローチを採用している。
出力イベントごとにオペレータの状態を永続化することは、高いレイテンシオーバーヘッドを引き起こすように見えるが、ストレージレイヤーでの書き込み先行ログ、ブラインド書き込み、ブルームフィルター、バッチコミットなどの従来のデータベース最適化を使用してコミットレイテンシを短縮できる。
エポック粒度での状態永続性

https://arxiv.org/pdf/2008.00842
レコードごとの粒度処理を採用する代わりに、エポックレベルのアプローチでは計算を一連の「エポック」と呼ばれるミニバッチに分割する。図5はこのアプローチを示している。入力、システム状態、出力を明確なエポック識別子でマークする。エポックは、ストリーミングアプリケーションのログ入力にマーカーを配置することで定義できる。
エポックを原子的にコミットするプロトコルには、いくつかのアプローチがある。
| プロトコル | 説明 | 利点 | 課題 | 採用システム |
|---|---|---|---|---|
| 厳格な2フェーズコミット | ・フェーズ1:エポックの処理 ・フェーズ2:システム状態の永続化 |
・単純な実装 ・強い一貫性保証 |
・同期実行による低いタスク使用率 ・他のタスクを待つ必要性 |
・Apache Spark ・S-Store |
| 非同期2フェーズコミット(非整列スナップショット) | ・Chandy-Lamportアルゴリズムベース ・パンクチュエーションやマーカーを使用 ・スナップショット前後のアクションを分離 |
・アプリケーションの一時停止なし ・効率的な通知配信 |
・インフライトイベントの記録が必要 ・リカバリ時に余分な処理 |
・IBM Streams ・Flink(非整列モード) |
| 非同期2フェーズコミット(整列スナップショット) | ・非整列スナップショットの拡張 ・スナップショット前にマーカーを同期 ・部分的に入力チャネルをブロック |
・リカバリ時間の改善 ・再構成の複雑さを最小化 ・クエリのサポート |
・コミット時間の増加(同期フェーズ) | ・Flink(整列モード) ・Chi |
耐障害性と高可用性
耐障害性は、障害にもかかわらずその動作を継続し、障害が発生しなかったかのように期待されるサービスを提供するシステムの能力だ。ストリーミングシステムでは特に重要で、その理由は2つある。
- ストリーミングシステムは長時間実行され、状態を蓄積する
- 現代のストリーミングシステムは分散アーキテクチャを採用しており、障害が一般的

https://arxiv.org/pdf/2008.00842
処理セマンティクス
処理セマンティクスは、障害によってシステムのデータ処理がどのように影響を受けるかを伝える。近年、ストリーム処理ドメインでは、at-least-onceとexactly-onceという用語が処理セマンティクスを特徴付けるために定着している。
| セマンティクス | 説明 | 利点 | 課題 | 代表例 |
|---|---|---|---|---|
| At-least-once | ・障害からの回復時に重複レコードが生成される可能性 ・失敗することなくすべてのレコードが処理される |
・実装が比較的簡単 ・低いオーバーヘッド |
・重複の可能性 ・下流での重複排除が必要 |
・Storm ・初期のSpark Streaming |
| Exactly-once(状態) | ・システム内部での一貫性保証 ・システムの状態に反映される重複なし ・決定的な計算を前提 |
・内部状態の信頼性 ・多くのユースケースに十分 |
・非決定的計算での状態の発散 ・出力の重複は依然として可能 |
・Flink ・Spark Streaming ・Samza |
| Exactly-once(出力) | ・出力コミット問題を解決 ・障害時に同じ出力を生成 ・外部システムへの二重出力なし |
・完全な一貫性 ・外部世界との一貫性 |
・実装の複雑さ ・高いコスト ・強い前提条件 |
・Clonos ・Millwheel ・特定の出力シンク |
出力コミット問題
出力コミット問題は、ストリーム処理システムが障害から回復する際に「同じデータを二度出力してしまう」ことを表す。まるで銀行の送金システムが同じ取引を2回実行してしまうようなものだ。
ストリーム処理ドメインでのソリューションは、3つのカテゴリにグループ化できる。
| アプローチ | 説明 | 前提条件 | 制限 | 代表例 |
|---|---|---|---|---|
| トランザクションベース | ・レコードに一意のIDをコミット ・重複を排除 ・高可用性ストレージに出力を保存 |
・高スループットのトランザクションストア ・順序付けされたトランザクション |
・外部ストレージのオーバーヘッド ・レイテンシの増加 |
・Millwheel ・Trident |
| 進行度ベース | ・タイムスタンプ比較を使用 ・単調に増加するスカラータイムスタンプ ・タイムスタンプに基づく重複排除 |
・決定的な計算 ・モノトニックに増加する論理クロック ・タイムスタンプで順序付けされたレコード |
・決定的な計算のみ ・副作用のない計算が必要 |
・Seep |
| 依存関係ベース | ・依存関係の追跡 ・シーケンス番号による一意識別 ・失敗したオペレータの依存関係の取得 |
・決定的な計算と入力 ・順序と値の点での決定性 |
・最後のオペレータの障害に脆弱 ・スナップショットの非同期保存による重複 |
・Timestream ・Streamscope |
レプリケーション戦略
レプリケーションは、実行を回復するための追加の計算リソースの使用を意味する。
| 戦略 | 説明 | 利点 | 課題 | 代表例 |
|---|---|---|---|---|
| アクティブ | ・同じ実行の2つのインスタンスを並行実行 ・レプリカの進行を調整 |
・ほぼゼロの回復時間 ・高い可用性 |
・リソース使用率の高さ ・レプリカの同期オーバーヘッド |
・Flux ・Borealis |
| パッシブ | ・チェックポイントされた状態を別のサーバにシップ ・障害時に新しいノードで実行を再開 |
・低いランタイムオーバーヘッド ・リソース効率 |
・長い回復時間 ・チェックポイント最適化の必要性 |
・SGuard ・Clonos ・Flink |
| ハイブリッド | ・通常時はパッシブモード ・一時的な障害時にアクティブモードに切り替え ・または動的に選択したオペレータのみアクティブレプリケーション |
・パッシブよりも短い回復時間 ・アクティブよりも低いメッセージオーバーヘッド ・障害相関に対応 |
・複雑な実装 ・モード切り替えの判断ロジック |
・Zwangらのアプローチ ・Heinzeらのアプローチ |
高可用性の定義と測定
興味深いことに、ストリーム処理における高可用性の明確な定義はまだ確立されていない。実証的研究は、回復時間、スループットやレイテンシの観点からのパフォーマンスオーバーヘッド、リソース使用率の3つのメトリックを使って高可用性を定量化している。
ストリーム処理固有の可用性の定義として、「ストリーミングシステムは、現在の入力の処理に基づいて出力を提供できるときに利用可能になる」と述べることができる。つまり、システムが入力に遅れることなく処理を継続できるかどうかだ。
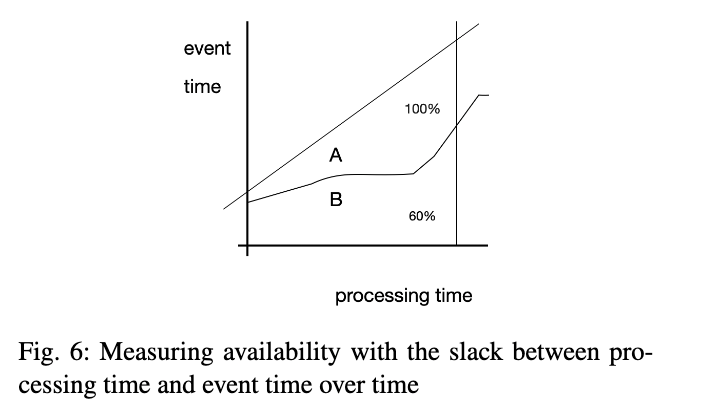
https://arxiv.org/pdf/2008.00842
測定方法としては、イベント時間と処理時間の間のスラックを時間の経過とともに追跡し、システムの処理進行状況を入力に対して定量化することが適切だ。図6は、イベント時間と処理時間の間のスラックを使った可用性の測定を示している。Aのエリアは100%の可用性を、Bのエリアは60%の可用性を表している。
負荷管理と伸縮性
外部データソースからのプッシュベースの性質により、ストリーム処理システムは入力イベントのレートをコントロールできない。入力レートがシステム容量を超えたときのパフォーマンス低下を避けるために、ストリーム処理システムは負荷を持続するためのアクションを取る必要がある。
https://arxiv.org/pdf/2008.00842
負荷シェディング
負荷シェディングは、入力レートがシステム容量を超えたときに過剰なタプルを一時的に破棄するプロセスだ。負荷シェディングは結果の精度を持続可能なパフォーマンスと引き換えに、厳格なレイテンシ制約があり近似結果を許容できるアプリケーションに適している。
負荷シェッダーは、いつ(オーバーロードを検出するタイミング)、どこで(クエリプランのどこで)、どれだけ(タプルをいくつ)、どのタプル(どのタプルを破棄するか)を決定しなければならない。
| コンポーネント | アプローチ | 例 |
|---|---|---|
| オーバーロード検出 | ・統計に基づく検出 ・制限されたオペレータセット(フィルタ、ユニオン、結合など) ・フィードバック制御 |
・入力レートモニタリング ・タプル遅延測定 ・バッファ占有率 |
| ドロッピング戦略 | ・ドロップオペレータの配置 ・負荷シェディングロードマップ(LSRM) ・セマンティックな重要性に基づく選択 |
・ランダムサンプリング ・ウィンドウ対応シェディング ・コンセプト駆動型シェディング |
スケジューリングとフロー制御
結果の正確性が低レイテンシよりも重要な場合、タプルを破棄することはオプションではない。負荷の増加が一時的なものであれば、システムは過剰なデータを確実にバッファリングし、入力レートが安定した後で処理することを選択できる。
| メカニズム | 説明 | 利点 | 課題 | 代表例 |
|---|---|---|---|---|
| 負荷対応スケジューリング | ・オペレータ実行順序の選択 ・リソース割り当ての適応 ・バックログを最小化する優先度 |
・バッファサイズの削減 ・オペレータ選択性の活用 ・効率的な処理順序 |
・選択性と処理コストの知識が必要 ・非決定的結果 ・高レイテンシの可能性 |
・Eddies ・Chain |
| バックプレッシャー | ・消費者の処理速度に合わせて生産者を遅くする ・ボトルネックオペレータの伝播 |
・データ損失なし ・オーバーフローの防止 ・自己調整 |
・システム全体の遅延 ・永続的な入力キューが必要 |
・多くの現代システム ・Apache Flink |
| クレジットベースフロー制御 | ・受信者からのバッファ可用性シグナル ・チャネルごとの仮想制御 ・クレジットベースのシステム |
・チャネルごとの細粒度制御 ・スキューの存在下でも機能 ・TCPコネクション共有 |
・追加のクレジットアナウンスメント ・エンドツーエンドレイテンシの増加 |
・Apache Flink |
バッファベースのフロー制御
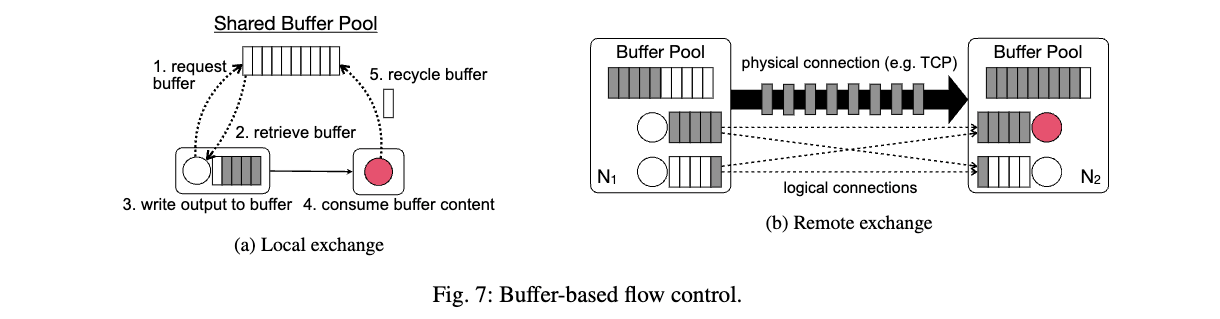
https://arxiv.org/pdf/2008.00842
図7はバッファベースのフロー制御を示している。固定量のバッファスペースを考慮すると、ボトルネックオペレータはそのデータフローパスに沿ってバッファが徐々に満たされる原因となる。
プロデューサーとコンシューマーが同じマシンで実行されている場合(図7a)、プロデューサーは共有バッファプールから出力バッファを取得しようとするかもしれないが、コンシューマーが遅い場合、バッファが利用できないことがある。この場合、プロデューサーの処理速度はコンシューマーがバッファを共有プールにリサイクルする速度に合わせて低下する。
プロデューサーとコンシューマーが異なるマシンにデプロイされ、TCP経由で通信している場合(図7b)、コンシューマー側でバッファが利用できない場合、TCP接続は中断される。
クレジットベースのフロー制御
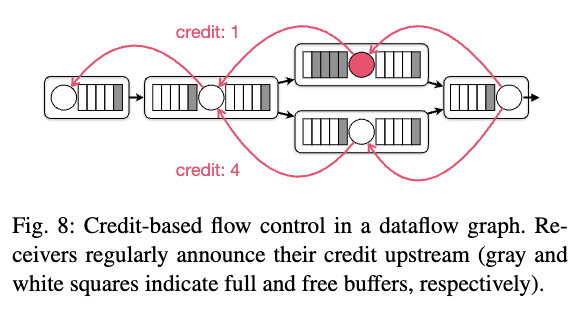
https://arxiv.org/pdf/2008.00842
クレジットベースのフロー制御(CFC)は、ATMネットワークスイッチで使用されるリンクバイリンク、チャネルごとの輻輳制御技術だ。クレジットシステムを使用して、レシーバーからセンダーへのバッファスペースの可用性をシグナルする。
図8は、仮想チャネルがTCP接続で多重化された仮想的なデータフローを示している。各タスクはクレジットメッセージを通じてバッファの可用性をセンダーに通知する。これにより、センダーは常にレシーバーがデータメッセージを処理するために必要な容量を持っているかどうかを知ることができる。レシーバーのクレジットがゼロ(または指定されたしきい値)に低下すると、その仮想チャネルにバックプレッシャーが現れる。
エラスティシティ
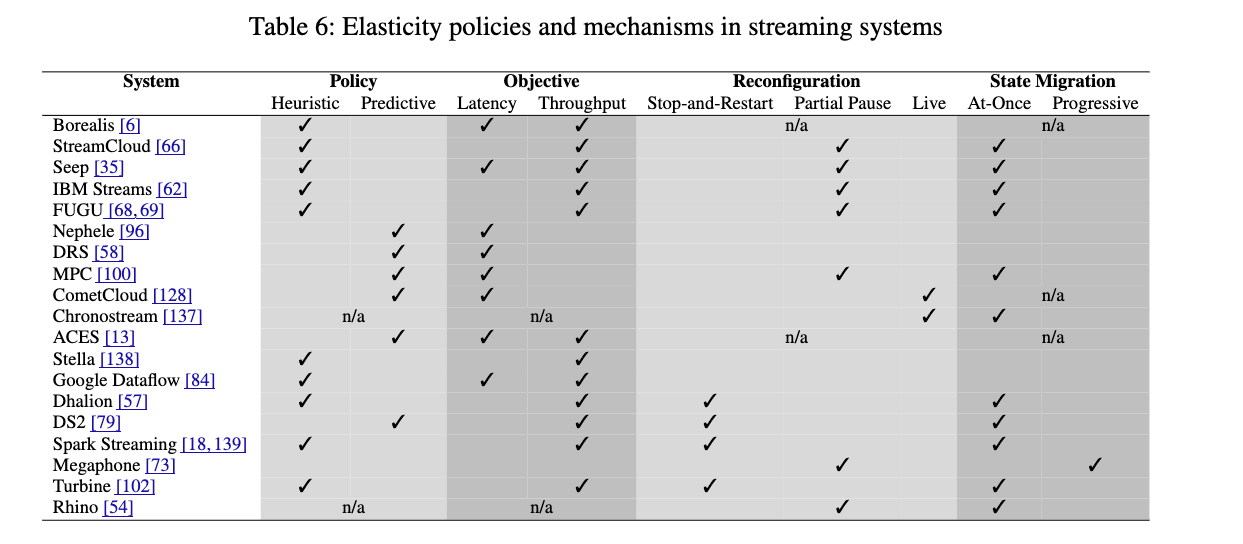
エラスティシティは、実行中の計算に利用可能なリソースを変化させて、ワークロードの変動を効率的に処理するストリーム処理システムの能力だ。エラスティックなストリーミングシステムの構築には、ポリシーとメカニズムが必要だ。
| コンポーネント | 説明 | 代表的なアプローチ |
|---|---|---|
| ポリシー | ・パフォーマンスメトリクスの収集 ・いつ、どれだけスケールするかを決定 ・ヒューリスティックまたは予測モデル |
・ヒューリスティック(しきい値ベース) ・キュー理論 ・制御理論 ・計測駆動線形パフォーマンスモデル |
| メカニズム | ・構成変更の実現 ・リソース割り当て、作業の再割り当て、状態移行 ・結果の正確性を保証 |
・停止と再起動 ・部分的な一時停止と再起動 ・プロアクティブレプリケーション |
エラスティシティポリシー
スケーリングポリシーには、2つの個別の決定が必要だ。まず、不健全な計算の症状を検出し、スケーリングが必要かどうかを判断する必要がある。次に、ポリシーは症状の原因(ボトルネックオペレータなど)を特定し、スケーリングアクションを提案する必要がある。
| ポリシータイプ | 説明 | 利点 | 課題 | 代表例 |
|---|---|---|---|---|
| ヒューリスティック | ・経験的に事前定義されたルール ・しきい値やトリガー条件 ・粗い粒度のメトリクス使用 |
・実装が簡単 ・低オーバーヘッド ・人間にとって理解しやすい |
・マルチテナンシーでの精度の低さ ・リソース過剰プロビジョニングの検出が困難 |
・StreamCloud ・Google Cloud Dataflow ・Dhalion |
| 予測 | ・分析的パフォーマンスモデル ・数学的関数としてのスケーリング問題 ・キュー理論、制御理論など |
・多演算子決定のワンステップ化 ・より正確な予測 ・理論的裏付け |
・モデル構築の複雑さ ・実践での精度維持の課題 |
・DS2 ・DRS ・MPC |
状態再配分
状態の再配分は、キーセマンティクスを保持する必要がある。つまり、特定のキーの既存の状態と、そのキーを持つ将来のすべてのイベントは、同じワーカーにルーティングされる必要がある。
| 再配分方式 | 説明 | 利点 | 課題 | 代表例 |
|---|---|---|---|---|
| 均一ハッシング | ・並列タスク間でキーを均等に分散 ・計算が高速 ・ルーティング状態が不要 |
・実装が簡単 ・均等な分散 ・低メモリ要件 |
・高い移行コスト ・ランダムI/O ・ネットワーク通信量が多い |
・基本的なハッシュパーティショニング |
| コンシステントハッシング | ・リングに複数のポイントとしてマッピング ・新しいワーカーが複数の既存ノードからデータを引き継ぐ ・変更されないワーカー間での状態移動なし |
・低い移行コスト ・増分的なリバランシング ・スケールアップ/ダウンに適している |
・スキューに弱い ・複雑な実装 |
・Apache Flink(キーグループ) ・Samza |
| ハイブリッドパーティショニング | ・コンシステントハッシングと明示的マッピングの組み合わせ ・パーティショニングキー値の頻度追跡 ・通常のキーと人気のキーの異なる扱い |
・スキュー存在下でのロードバランス ・コンパクトなハッシュ関数 ・適応的 |
・頻度追跡のオーバーヘッド ・複雑な実装 |
・Gedikのアプローチ |
再構成戦略

再構成戦略は、エラスティシティポリシーが決定を下した後、アプリケーションのリソースを変更するプロセスだ。
| 戦略 | 説明 | 利点 | 課題 | 代表例 |
|---|---|---|---|---|
| 停止と再起動 | ・計算を停止 ・すべてのオペレータの状態スナップショット ・新しい構成で再起動 |
・実装が簡単 ・正確性の保証が簡単 |
・パイプライン全体の不必要な停止 ・高いレイテンシ |
・多くの現代システム ・Spark Streaming |
| 部分的な一時停止と再起動 | ・影響を受けるサブグラフのみをブロック ・上流チャネルと上流オペレータを含む ・状態移行後に再開 |
・システムの健全な部分への影響が少ない ・より低いレイテンシ |
・より複雑な実装 ・同期が必要 |
・FLUX ・Flink ・Dhalion |
| プロアクティブレプリケーション | ・複数のノードでの状態バックアップコピーの維持 ・小さなパーティションに状態を整理 ・必要に応じてライブに近い再構成 |
・ほぼライブな移行 ・低レイテンシ ・低い移行時間 |
・高い保守オーバーヘッド ・ストレージ要件の増加 |
・ChronoStream ・Rhino |
状態転送
別のワーカーに状態を移行する際の重要な決定は、状態を一度に移動するか、または段階的に移動するかだ。
| アプローチ | 説明 | 利点 | 課題 | 代表例 |
|---|---|---|---|---|
| 一度に | ・単一のオペレーションで状態を移動 ・原子的転送 |
・シンプルな実装 ・明確な一貫性ポイント |
・再構成中の高レイテンシ ・大量の状態の場合に大きな遅延 |
・多くのシステム ・基本的なチェックポイント/リストア |
| 段階的 | ・より小さな部分で状態を移動 ・処理と状態転送の間に処理を交互に行う ・レイテンシスパイクをフラット化 |
・再構成中の低レイテンシ ・ユーザー体験の向上 |
・長い移行期間 ・複雑な実装 ・一貫性の確保が難しい |
・Megaphone ・Rhino |
現代のストリーム処理システム
現代のストリーム処理システムは、第1世代と比較して大きく異なる特性を持っている。主な違いを以下の表にまとめる。
| 側面 | 第1世代 | 第2-3世代 |
|---|---|---|
| 結果 | 近似または正確 | 正確 |
| 言語 | SQL拡張、CQL | UDF重視 - Java、Scala、Python、SQL風など |
| クエリプラン | グローバル、最適化、事前定義オペレータ | 独立、カスタムオペレータ |
| 実行 | 主にスケールアップ | 分散 |
| 並列性 | パイプライン | データ、パイプライン、タスク |
| 時間と進行 | ハートビート、スラック、パンクチュエーション | ローウォーターマーク、フロンティア |
| 状態管理 | 共有シノプシス、メモリ内 | クエリごと、パーティション化、永続的、メモリ超え |
| 耐障害性 | HA重視、限定的な正確性保証 | 分散スナップショット、exactly-once |
| 負荷管理 | 負荷シェディング、負荷対応スケジューリング | バックプレッシャー、エラスティシティ |
まとめ

Gemini
Discussion