言語モデルの進化とアーキテクチャ発展史概略
はじめに
「ChatGPTすご〜い」
「Claudeすご〜い」
とまあまあテキトーに放言している我が身を冷静に振り返ると、もうちょっとちゃんと整理しておくか ... と反省したので、言語モデルの歴史的な発展を整理することにした。
参考にしたのは次の資料(CCBY)。
Minaee, S. et al. (2024). "Large Language Models: A Survey"
個人的にもっと知られてもいいのになあと思うのは、次の YouTube チャンネル。
最近投稿されているLLM関連で言えば、このあたりはコンパクトにまとめられておりて、非常にわかりやすい。
言語モデルの歴史的発展
言語モデルは、その黎明期から現在に至るまで驚くべき進化を遂げてきた。初期の統計的言語モデルが単語の出現確率だけを扱っていた時代から、ニューラルネットワークを活用した現代の大規模言語モデル(LLM)まで、その変遷は自然言語処理(NLP)分野における技術革新の歴史そのものだ。この進化は、まるで自転車から宇宙船への飛躍のように、言語を扱う技術の可能性を劇的に拡大してきた。
統計的言語モデルからニューラル言語モデルへ
初期の言語モデリングは、1950年代にシャノンが人間の言語に情報理論を適用し、単純なn-gramモデルで自然言語テキストをどれだけ予測・圧縮できるかを測定したことから始まった。テキストを単語のシーケンスとして捉え、それぞれの単語の出現確率を積として計算する手法である。
| モデル世代 | 特徴 | 代表例 | 限界点 |
|---|---|---|---|
| 統計的言語モデル(SLM) | ・単語の連なりをマルコフ連鎖(n-gram)として確率計算 ・データの疎性(未見のn-gramに確率0を割り当て)を扱うための平滑化技術 ・多様な言語処理タスクへの応用 |
・N-gramモデル | ・データ疎性問題 ・言語の多様性・可変性を十分に捉えられない |
| 初期のニューラル言語モデル(NLM) | ・単語を低次元の連続ベクトル(埋め込みベクトル)へマッピング ・単語間の意味的類似性を計算可能 ・クエリと文書間の意味的類似性計算などに応用 |
・Bengio et al. (2003)のモデル ・RNNLMなど |
・タスク固有のモデル ・学習した隠れ空間がタスク固有 |
| 事前学習言語モデル(PLM) | ・タスク非依存の汎用性 ・大規模な非ラベルデータでの事前学習 ・特定タスクへの微調整が可能 ・RNNやTransformerを基盤として発展 |
・ELMo ・ULMFiT ・BERT ・GPT-1 |
・規模の限界 ・推論能力の制約 |
初期のニューラル言語モデルは、データ疎性問題に対処するため、単語を低次元の連続ベクトル空間に埋め込む手法を導入した。これは料理でいえば、限られた食材(単語)から、様々な料理(意味)を生み出せるようになった瞬間に例えられる。この革新により、単語間の意味的関係性を数値的に捉えることが可能になった。
単語埋め込み手法の導入を皮切りに、再帰型ニューラルネットワーク(RNN)とその派生形であるLSTM(Long Short-Term Memory)やGRU(Gated Recurrent Unit)を用いた言語モデルが盛んに研究された。これらのモデルは、シーケンシャルなテキストデータの時間的依存関係を捉える能力を持っていたが、長距離の依存関係を処理する際の限界が存在した。
Transformerの登場と自己注意機構
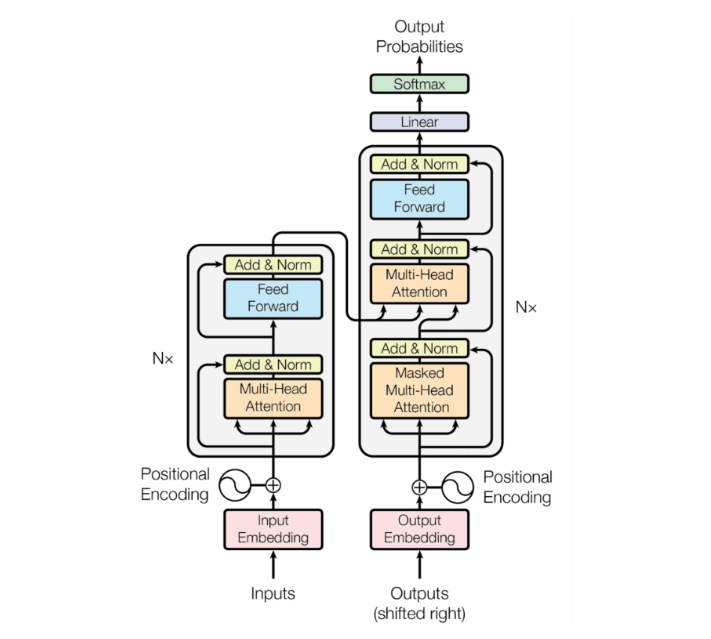
2017年、Vaswani らによる「Attention is All You Need」論文で発表されたTransformerアーキテクチャは、NLP分野に革命をもたらした。Transformerは、RNNの逐次処理という制約を取り除き、並列計算と自己注意機構(self-attention mechanism)を活用することで、文脈理解能力と処理効率を飛躍的に向上させた。
https://arxiv.org/pdf/2402.06196v2
RNNが一単語ずつ順番に情報を処理していくのに対し、Transformerは各単語が他のすべての単語と直接的に「対話」できるような情報交換の仕組みを持っており、まるで複数の読者が文書の異なる部分を同時に読みながらも互いに情報を共有できるように、テキスト全体の関係性をより包括的に把握できるようになった。
Transformerアーキテクチャの詳細解説
Transformerは、他のニューラルネットワークアーキテクチャと比較して、並列処理能力と長距離依存関係の捕捉に優れた設計を持っている。その核心部分である自己注意機構から各構成要素まで詳しく見ていく。
注意機構の仕組みとその数学的基礎
注意機構は、クエリ(query)とキー・バリューのペア(key-value pairs)を入力として受け取り、出力を計算するプロセスと捉えることができる。クエリ、キー、バリューはすべてベクトルであり、出力はバリューのベクトルの重み付き和として計算される。
Attention(Q, K, V) = softmax(QK^T/√d_k)V
この式で、重みはクエリとキーの互換性関数によって決定される。スケーリング因子√d_kは勾配消失問題を防ぐために導入されている。
| 注意機構の要素 | 役割 | 数学的表現 |
|---|---|---|
| クエリ(Q) | ・現在の位置の情報を表現 ・他の位置との関連性を問い合わせる役割 ・「何を探しているか」を定義 |
・Q = XW^Q XはELMo埋め込み W^Qは学習可能な重み行列 |
| キー(K) | ・各位置の「検索キー」を表現 ・クエリとの関連性を計算する基準 ・「何を提供できるか」を定義 |
・K = XW^K |
| バリュー(V) | ・各位置の「内容」を表現 ・注意重みに基づいて集約される情報 ・「実際に何が含まれているか」を定義 |
・V = XW^V |
| 注意スコア | ・クエリとキーの互換性を測定 ・√d_kでスケーリングして勾配の安定化 ・softmax関数で確率分布に変換 |
・score = softmax(QK^T/√d_k) |
| 出力 | ・注意スコアで重み付けされたバリューの和 ・文脈化された表現を生成 |
・output = score・V |
自己注意機構は、まるでテキスト内の各単語が会議の参加者のように、他のすべての単語と「会話」し、文脈における重要度を決定していくプロセスと考えることができる。この過程で、各単語は文中の他の単語との関係性に基づいて「豊かな文脈表現」を獲得していく。
位置エンコーディング技術
Transformerは並列処理の恩恵を受けるため、入力シーケンスの順序情報を明示的に提供する必要がある。このために位置エンコーディングが導入された。位置情報をモデルに組み込む主要な手法にはいくつかの種類がある。

https://arxiv.org/pdf/2402.06196v2
| 位置エンコーディング手法 | メカニズム | 利点 | 課題 |
|---|---|---|---|
| 絶対位置埋め込み(APE) | ・正弦・余弦関数を使用した固定パターン ・各位置に一意の位置ベクトルを割り当て ・埋め込みベクトルに加算して位置情報を付与 |
・実装が簡単 ・外挿能力(未学習の位置にも対応) |
・特定のシーケンス長に制限 ・相対的な距離情報を直接表現できない |
| 相対位置埋め込み(RPE) | ・入力要素間のペアワイズリンクを表現 ・位置差に基づく関係性の学習 ・キーと値のマトリックスに相対位置情報を追加 |
・相対的距離関係を直接モデル化 ・長いシーケンスにも適応可能 |
・計算コストがやや高い ・実装が複雑 |
| 回転位置埋め込み(RoPE) | ・回転行列を使用して位置をエンコード ・絶対位置と相対位置情報を同時に含む ・自己注意における相対位置の明示的表現 |
・シーケンス長への一般化能力が高い ・相対距離の依存関係の減少 ・線形自己注意との互換性 |
・比較的新しい手法 |
| 相対位置バイアス(ALiBi) | ・注意スコアに直接バイアスを追加 ・クエリとキーのペア間の距離に比例したペナルティ |
・学習データより長いシーケンスへの外挿能力 | ・注意重みに直接影響するため調整が必要 |
位置エンコーディングは、テキストの単語に「住所」を与えるようなものだ。それにより、モデルは「どの単語がどこにあるか」を理解し、文脈を正確に把握できるようになる。
マルチヘッド注意とフィードフォワードネットワーク
Transformerのもう一つの重要な特徴は、マルチヘッド注意機構だ。単一の高次元の注意機構の代わりに、クエリ、キー、バリューを異なる学習可能な線形投影(データの見方を変える)に分割し、各「ヘッド」が異なる表現部分空間に注目できるようにしている。
https://arxiv.org/pdf/2402.06196v2
| 構成要素 | 機能 | 具体的な実装 |
|---|---|---|
| マルチヘッド注意 | ・異なる表現部分空間に同時に注目 ・各ヘッドが異なる言語的側面を捉える ・並列処理による計算効率の向上 |
・入力をh個のヘッドに分割 ・各ヘッドで独立に注意計算 ・結果を連結して出力次元に変換 |
| フィードフォワードネットワーク | ・各位置の表現を独立に処理 ・非線形変換による表現力の向上 ・位置ごとの情報処理と特徴抽出 |
・2層の全結合層 ・第1層:ReLUまたはGELU活性化 ・第2層:元の次元に戻す変換 |
| 残差接続 | ・勾配消失問題の軽減 ・情報の直接伝播を可能に ・深いネットワークの安定した学習をサポート |
・各サブレイヤーの出力に入力を加算 ・層正規化と組み合わせて使用 |
| 層正規化 | ・学習の安定化 ・特徴分布の正規化 ・勾配爆発の防止 |
・各層の出力を正規化 ・学習可能なスケールとバイアスパラメータ |
マルチヘッド注意は、複数の専門家が同じテキストを異なる視点から同時に分析するようなものだ。言語学者が文法を、心理学者が感情を、歴史学者が文化的文脈を分析するように、各ヘッドが異なる側面に注目することで、テキストの多面的な理解が可能になる。
LLMアーキテクチャの系譜と分類
大規模言語モデル(LLM)のアーキテクチャは、主に三つの基本的なカテゴリに分類できる。これらの違いを理解することで、それぞれのモデルの特性や適した用途が見えてくる(実際には、有効性を試行されている他のカテゴリもあるが割愛)。

エンコーダのみモデル
エンコーダのみのモデルは、テキスト全体を同時に処理し、各単語が他のすべての単語との関係性を考慮した文脈表現を生成する。これらのモデルは、テキスト分類や固有表現抽出などの言語理解タスクに特に適している。
| モデル | 発表年 | 主要な特徴 | 革新点 |
|---|---|---|---|
| BERT | 2018 | ・双方向エンコーダを使用 ・マスク言語モデリング(MLM) ・次文予測タスクで事前学習 |
・双方向コンテキスト考慮 ・大規模データでの事前学習 ・ファインチューニングの効率性 |
| RoBERTa | 2019 | ・BERTの頑健性向上版 ・次文予測タスクを除去 ・より大きなバッチサイズと学習率で訓練 |
・より長い訓練 ・動的マスキング ・より大規模なデータセット |
| ALBERT | 2019 | ・パラメータ削減技術 ・埋め込み行列の分解 ・層間パラメータ共有 |
・省メモリ設計 ・訓練速度の向上 ・文章の一貫性予測タスク |
| XLNet | 2019 | ・自己回帰事前学習 ・Transformer-XLベース ・順列言語モデリング |
・双方向コンテキスト ・長距離依存関係の扱い ・マスキングアーティファクトの回避 |
| DeBERTa | 2020 | ・分解された注意機構 ・内容と位置の分離表現 ・拡張マスクデコーダ |
・より精密な位置情報処理 ・マスクトークン予測の精度向上 ・逆位置エンコーディング |
BERTは、言わば本の内容を「全体を一度に読み込んで理解する読者」のようなモデルだ。文書全体を俯瞰して、各単語の文脈における意味を双方向に理解することができる。
デコーダのみモデル
デコーダのみのモデルは、自己回帰的なテキスト生成に特化している。各単語を予測する際に、それまでに生成された単語のみを参照する。これにより、一貫性のあるテキスト生成が可能になる。
| モデル | 発表年 | 主要な特徴 | 革新点 |
|---|---|---|---|
| GPT-1 | 2018 | ・生成的事前学習 ・自己回帰言語モデリング ・様々なNLPタスクへの転用 |
・転移学習の効果実証 ・幅広いタスクへの適用性 ・微調整の効率性 |
| GPT-2 | 2019 | ・GPT-1の拡張版 ・より大規模なWebテキストデータセット ・1024トークンまでのコンテキスト長 |
・ゼロショット学習能力 ・WebTextデータセット ・より大きなモデルサイズ |
| GPT-3 | 2020 | ・1750億パラメータ ・インコンテキスト学習能力 ・300Bトークンで訓練 |
・フューショット学習 ・タスク非依存の汎用性 ・大規模モデルの創発能力 |
| PaLM | 2022 | ・Pathwaysシステムで訓練 ・5400億パラメータ ・マルチタスク能力 |
・優れた推論能力 ・コード生成能力 ・数学的問題解決能力 |
| LLaMA | 2023 | ・オープンソースLLM ・計算効率の向上 ・SwiGLU活性化関数とRoPE使用 |
・効率的な訓練 ・優れた推論能力 ・小型モデルの高性能化 |
GPTシリーズのモデルは、小説を一文一文書き進めていく作家のようなものだ。前の文脈を踏まえて次の単語を予測し、一貫性のある文章を生成していく。
エンコーダ-デコーダモデル
エンコーダ-デコーダモデルは、入力テキストをエンコーダで処理して文脈表現を生成し、それをデコーダが利用して新しいテキストを生成する。翻訳や要約などのシーケンス変換タスクに適している。
| モデル | 発表年 | 主要な特徴 | 革新点 |
|---|---|---|---|
| T5 | 2019 | ・テキスト間変換フレームワーク ・すべてのNLPタスクをテキスト生成として統一 ・様々なタスクで事前学習 |
・統一されたフレームワーク ・大規模コーパスでの訓練 ・転移学習の効率性 |
| MASS | 2019 | ・マスクされたシーケンス生成 ・エンコーダとデコーダの共同訓練 ・文断片の再構築タスク |
・エンコーダとデコーダの統合訓練 ・多言語転移 ・言語生成タスクでの優位性 |
| BART | 2019 | ・ノイズ除去自己エンコーダ ・任意のノイズ関数で破損したテキスト ・元のテキストを再構築 |
・柔軟なノイジング戦略 ・双方向エンコーダ ・自己回帰デコーダ |
| mT5 | 2020 | ・T5の多言語版 ・101言語のテキストで訓練 ・クロスリンガル転移能力 |
・言語間の知識転移 ・低リソース言語への適用 ・多言語理解と生成 |
T5やBARTは、翻訳者のように機能する。原文(ソーステキスト)を深く理解し、その意味を保持しながら新しい形式(ターゲットテキスト)に変換する能力を持っている。
主要LLMの技術的発展タイムライン
ここ数年の言語モデルの発展は目覚ましく、様々な技術革新によって性能が飛躍的に向上している。主要な大規模言語モデルの発展を時系列で追いながら、その技術的進化を見ていこう。

https://arxiv.org/pdf/2402.06196v2
BERT (2018)からGPT-4 (2023)までの技術的進化
| 時期 | モデル | パラメータ数 | 主要な技術的特徴 | 画期的な能力 |
|---|---|---|---|---|
| 2018 | BERT | 3.4億 | ・双方向エンコーダ ・マスク言語モデリング ・次文予測 |
・文脈を考慮した単語表現 ・多様なNLPタスクへの適用 |
| 2018 | GPT-1 | 1.2億 | ・自己回帰言語モデリング ・左から右への予測 ・転移学習の実証 |
・ゼロショット/フューショット学習 ・自然言語生成能力 |
| 2019 | GPT-2 | 15億 | ・拡張コンテキスト長 ・WebTextデータセット ・より大きなモデルサイズ |
・タスク非特定的な生成能力 ・コヒーレントな長文生成 |
| 2019 | RoBERTa | 3.55億 | ・BERTの拡張・改良版 ・より大規模かつ多様なデータセット ・動的マスキング |
・頑健な言語表現 ・下流タスクでの性能向上 |
| 2019 | T5 | 2.23億 | ・テキスト間変換フレームワーク ・すべてのNLPタスクをテキスト生成として統一 ・C4コーパスでの訓練 |
・統一された転移学習 ・マルチタスク能力 |
| 2020 | GPT-3 | 1750億 | ・莫大なパラメータサイズ ・インコンテキスト学習 ・フューショット学習 |
・高度な自然言語理解と生成 ・創発的能力 ・少数例からの学習 |
| 2021 | Codex | 120億 | ・GPT-3をコードデータで微調整 ・GitHub公開リポジトリで訓練 ・プログラミング言語の理解と生成 |
・コード生成能力 ・自然言語からコードへの変換 |
| 2022 | InstructGPT | GPT-3ベース | ・人間のフィードバックからの強化学習(RLHF) ・指示に忠実に従う調整 ・有害出力の削減 |
・より意図に沿った応答 ・安全性と有用性の向上 |
| 2022 | PaLM | 5400億 | ・Pathwaysシステムでの分散訓練 ・多様なタスクでの高性能 ・マルチタスク、マルチモーダル能力 |
・推論能力の向上 ・複雑な問題解決 ・数学的能力 |
| 2022 | ChatGPT | GPT-3.5ベース | ・会話に特化した調整 ・人間のフィードバックで継続的に改善 ・対話形式のインターフェース |
・会話的な対話能力 ・汎用AI助手としての機能 ・広範な知識アクセス |
| 2023 | LLaMA | 70億〜700億 | ・計算効率を重視した設計 ・高品質データセットでの訓練 ・オープンリサーチ向けリリース |
・小規模モデルの高性能化 ・研究コミュニティへの貢献 |
| 2023 | GPT-4 | 非公開(推定1.76兆+ ) | ・マルチモーダル入力対応 ・画像と言語の統合理解 ・さらなる安全性と有用性の向上 |
・人間レベルの専門知識 ・高度な推論と問題解決 ・視覚理解能力 |
この技術的進化は、より大きな住宅地図から、詳細な3D都市モデルへの進化に例えられる。初期のモデルが基本的な地形を把握していたのに対し、最新のモデルは都市の複雑な構造、建物の内部構造、さらには人々の移動パターンまでも表現できるようになった。
スケーリング法則とその応用
スケーリング法則の発見は、LLMの設計と訓練に革命をもたらした。この節では、Kaplanらの先駆的研究から、チンチラモデルの設計原理を見ていく。
Kaplanらのスケーリング法則(パラメータ数、データ量、計算量の関係)
2020年にOpenAIのKaplanらが発表したスケーリング法則は、言語モデルの性能がモデルサイズ、データ量、計算量とどのように関連するかを体系的に分析した。この研究は、LLMの開発に科学的基盤を提供した画期的な成果だ。
モデルのパラメーター数(モデルサイズ)や、データセットのサイズ、トレーニングに使用される計算量が増えるにつれて、損失(Loss、誤差)が「べき乗則」に従って減少する、という法則のことである。
| スケーリング関係 | 数学的表現 | 実践的意味 |
|---|---|---|
| モデルサイズと性能 | L(N) = (Nc/N)^αN ・Lは損失(低いほど良い) ・Nはパラメータ数 ・αN ≈ 0.076, Nc ≈ 8.8 × 10^13 |
・より大きなモデルほど性能向上 ・性能はパラメータ数の対数に比例 |
| データ量と性能 | L(D) = (Dc/D)^αD ・Dはデータトークン数 ・αD ≈ 0.095, Dc ≈ 5.4 × 10^13 |
・より多くのデータで性能向上 ・データ量の増加に対する限界収穫逓減 ・データ品質と多様性も重要 |
| 計算量と性能 | L(Cmin) = (Cmin_c/Cmin)^αmin_C ・Cminは計算量 ・αmin_C ≈ 0.050, Cmin_c ≈ 3.1 × 10^8 |
・計算予算に基づく最適設計 ・過剰なパラメータ化は非効率 |
これらの法則は、LLM開発を「芸術」から(完全ではないが)「科学」へと転換させた。モデルの設計と訓練に関する決定を、理論的根拠に基づいて行えるようになったのだ。
チンチラモデルの設計原理(最適なパラメータとデータ比率)
Hoffmannらの研究(2022)は、Kaplanらのスケーリング法則をさらに発展させ、同じ計算予算内でより効率的なモデルを設計する方法を示した。その結果生まれたのが「チンチラ」モデルであり、「小さなモデルをより多くのデータで訓練する」という新たなパラダイムを確立した。
| チンチラの設計原理 | 具体的な比率 |
|---|---|
| モデルサイズとトークン数の最適比率 | ・パラメータ : トークン ≈ 1:20 ・70億パラメータなら約1400億トークン ・700億パラメータなら約1.4兆トークン |
| 小規模モデルの長期訓練 | ・訓練ステップ数の増加 ・より多くのデータを処理 ・同じ計算量でより多くの情報を学習 |
| データ品質と多様性の重視 | ・高品質データの選別 ・重複除去と品質フィルタリング ・多様なドメインのバランス |
チンチラモデルの革新は、スポーツカーの例えで理解できる。巨大なエンジン(大量のパラメータ)だけを積んでも、適切な量の燃料(データ)がなければ性能を発揮できない。チンチラは「適切なサイズのエンジンに十分な燃料を供給する」という効率的な設計思想を示した。つまり、単にモデルサイズを大きくするよりも、適切な規模のモデルにより多様で質の高いデータを学習させる方が計算効率が良いということだ。これは限られた計算資源で最大の性能を引き出す実用的なアプローチである。
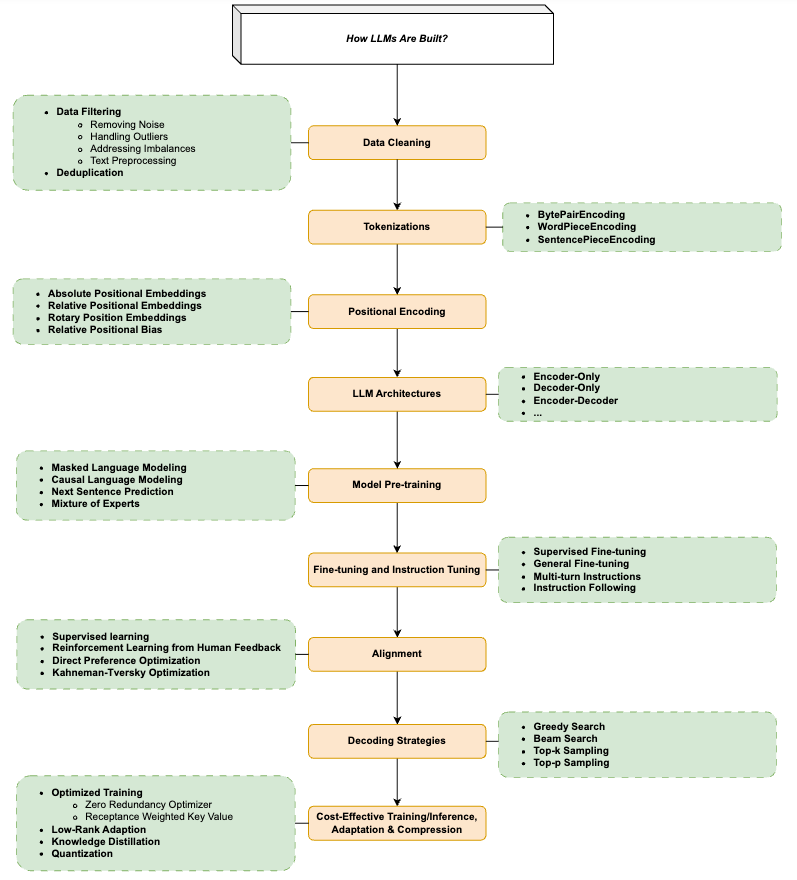
LLMの構築技術と方法論
大規模言語モデルの開発は、アーキテクチャの設計だけでなく、データの準備から訓練、最適化、そして評価に至るまでの複雑なプロセスを含んでいる。ここでは、LLMを構築する上で重要な技術要素と方法論について詳しく見ていく。
https://arxiv.org/pdf/2402.06196v2
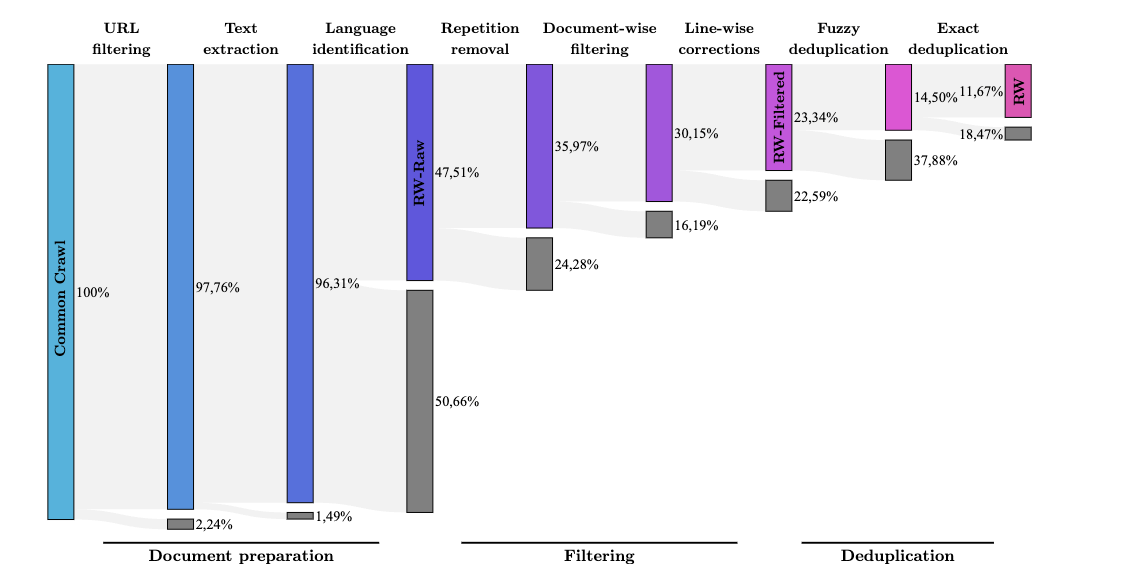
データ準備とクリーニング
LLMの性能は使用する訓練データの質と量に大きく依存している。データ準備のプロセスは、収集、フィルタリング、クリーニング、重複排除など複数のステップから構成される。
| データ処理ステップ | 主要技術 | 目的と効果 |
|---|---|---|
| データ収集 | ・ウェブクローリング ・公開データセット活用 ・専門分野のコーパス構築 |
・多様かつ大量のテキストデータ確保 ・様々なドメインの知識獲得 ・特定分野の専門知識の取り込み |
| 品質フィルタリング | ・統計的フィルタリング ・ヒューリスティックルール ・機械学習ベースの選別 |
・低品質コンテンツの排除 ・偏りや有害コンテンツの削減 ・教育的・事実的価値の高いコンテンツ優先 |
| 重複排除 | ・n-gramベースの類似度計算 ・ハッシュベースの重複検出 ・セマンティック重複検出 |
・過学習の防止 ・特定コンテンツへの過度の偏りを防止 ・計算効率の向上 |
https://arxiv.org/pdf/2402.06196v2
RefinedWebやRedPajamaなどの高品質データセットは、元のCommonCrawlデータから最大90%のドキュメントを除去する精緻なフィルタリングプロセスを経て作成されている。これにより、残りの10%程度のデータだけで、より高品質なモデルを訓練することが可能になっている。
学習とアライメント
LLMの訓練は通常、事前学習、指示微調整、人間のフィードバックによる強化学習(RLHF)という段階を経て進められる。
| 訓練段階 | 目的 | 主要アプローチ |
|---|---|---|
| 事前学習 | ・言語の基本的理解 ・広範な知識の獲得 ・基礎的な生成能力の習得 |
・自己教師あり学習(次トークン予測など) ・大規模コーパスでの訓練 ・スケーリング法則に基づくパラメータとデータ量設計 |
| 指示微調整 | ・人間の指示に従う能力 ・特定タスクでの性能向上 ・出力形式の改善 |
・教師あり微調整 ・指示-回答ペアデータセットの活用 ・少数ショットによる例示学習 |
| アライメント | ・人間の価値観との整合 ・有害出力の削減 ・有用性と正確性の向上 |
・RLHF(人間フィードバックからの強化学習) ・DPO(直接選好最適化) ・KTO(Kahneman-Tversky最適化) |
特にアライメントプロセスは、モデルが社会的規範や人間の価値観に沿った出力を生成するために不可欠である。例えば、InstructGPTの開発では、人間の評価者がさまざまな回答の質を評価し、その選好データに基づいて報酬モデルを構築、最終的にRLHFによってモデルを調整している。

https://arxiv.org/pdf/2402.06196v2
効率的な訓練と推論技術
LLMの大規模化に伴い、効率的な訓練と推論のための技術も急速に発展している。
| 効率化技術 | メカニズム | 効果 |
|---|---|---|
| ゼロ冗長オプティマイザ(ZeRO) | ・モデルの状態(重み、勾配、最適化状態)の分散管理 ・通信オーバーヘッドの最小化 ・計算粒度の維持 |
・より大きなモデルの訓練が可能 ・メモリ使用量の大幅削減 ・分散訓練の効率化 |
| 量子化 | ・32ビット浮動小数点から8ビット整数などへの精度低減 ・モデル重みの低精度表現 ・計算操作の簡略化 |
・推論速度の大幅向上 ・メモリフットプリントの削減 ・エッジデバイスでの展開可能性 |
| LoRA(Low-Rank Adaptation) | ・事前学習済み重みの凍結 ・低ランク行列を通じた更新のパラメータ化 ・タスク特化の効率的適応 |
・微調整の計算効率向上 ・微調整用パラメータの大幅削減 ・複数適応の並列管理 |
これらの技術により、限られた計算資源でもより大きなモデルを訓練したり、既存のモデルをより効率的に特定タスク向けに調整したりすることが可能になっている。例えば、LoRAを用いることで、70億パラメータのLLaMAモデルを単一のGPUで微調整することができる。
デコーディング戦略
LLMからテキストを生成する際のデコーディング戦略も、モデルの出力品質に大きな影響を与える。
| デコーディング手法 | 動作原理 | 適した用途 |
|---|---|---|
| 貪欲法(Greedy Search) | ・各ステップで最も確率の高いトークンを選択 ・一意の確定的な出力を生成 ・最も単純な手法 |
・一貫性が重要なタスク ・短い応答生成 ・事実に基づく質問応答 |
| ビームサーチ(Beam Search) | ・複数の候補シーケンスを並行して評価 ・各ステップでトップkの候補を保持 ・最終的に最高スコアの系列を選択 |
・翻訳タスク ・要約生成 ・高品質な長文生成 |
| Top-k サンプリング | ・各ステップで確率上位kトークンから無作為抽出 ・低確率トークンを除外 ・パラメータで多様性調整 |
・創造的なテキスト生成 ・会話的応答 ・ストーリー作成 |
| Top-p サンプリング | ・累積確率が閾値pに達するまでのトークンから抽出 ・動的候補プール ・文脈に応じた多様性 |
・長文コンテンツ生成 ・会話的なAI ・多様な応答が望ましい場合 |
効果的なデコーディング戦略は、モデルの生成する文章の品質、多様性、一貫性のバランスを制御する上で重要な役割を果たしている。例えば、ChatGPTのような会話モデルでは、適度な温度設定とTop-pサンプリングを組み合わせることで、自然で多様性のある応答が実現されている。
まとめ
言語モデルは統計的な単語予測から、高度な文脈理解と生成能力を持つ大規模言語モデルへと進化してきた。Transformerアーキテクチャの登場と自己注意機構の革新が、この急速な発展の鍵となった。エンコーダのみ、デコーダのみ、エンコーダ-デコーダといった異なるアーキテクチャの系譜が形成され、BERTからGPT-4に至る技術的進化の道筋を築いてきた。
スケーリング法則の発見により、モデルサイズ、データ量、計算量と性能の関係が明らかになり、チンチラ則はより効率的なモデル設計の指針を提供した。これらの知見は、より小型で効率的なモデル、専門化されたモデル、そして新しいアーキテクチャパラダイムへの道を開いている。
言語モデルの進化は今も続いており、マルチモーダル能力の強化、効率性の追求、応用領域の拡大など、多くの方向に発展している。この急速に発展する分野を理解することは、AIの可能性と限界を把握し、その進歩を形作る上で不可欠だろう。
これらの技術的発展は、単なるアルゴリズムの進化を超えて、人間とコンピュータの関わり方を根本的に変える可能性を秘めている。

Discussion