標準ベイズ統計学 7章 -欠損値の補完-


はじめに
欠測値・欠損値は実際のデータ解析でもよく出てくる問題です。
この問題に対して、よくやるのは以下の2つかと思います。
①欠測値を含む行もしくは列ごと消す②欠測値を平均値や最頻値で埋める
①は有用な情報が破棄されていますし、②は実際には観測されていないのに、その値が確実だというもとで分析をしているため、統計的に正しくない方法です。
そんな中、標準ベイズ統計学(https://amzn.asia/d/4uf8I61) の7章で解説されている
「欠測データと代入法」が業務でも使えるかもと思い、まとめました。
本ではRで実装されているため、これをPythonで実装しなおしています。
概略
欠測を平均値で埋める → ギブスサンプリングで更新する
扱うデータ
標準ベイズ統計学の原著者であるピーター・D・ホフさんのウェブサイトから、本で扱ったデータがダウンロード可能でしたので、それを用います。Y.pima.miss.txtとY.pima.full.txtです。
Link: https://www2.stat.duke.edu/~pdh10/FCBS/Inline/
このデータはアリゾナ州にするピマ・インディアンを先祖に持つ200人の女性の健康状態の測定値です。4つの変数があり、それぞれglu(血漿グルコース濃度)、bp(拡張期血圧)、skin(肌のひだの厚さ)、bmi(BMI)です。
欠測データについて
まず、欠測データには3つの種類があります。
本では今回の欠測は、MARであると仮定しています。
- MCAR (Missing Completely At Random):
欠損値がランダムに発生する場合です.
つまり,ほかの説明変数の値が欠損の生じやすさに影響しないというケースです. - MAR (Missing At Random):
欠損値の発生がほかの説明変数に依存する場合です.
例えば、gluが大きいとbpが測れないとかがある場合です。 - MNAR (Missing Not At Random):
欠損値の発生が欠損値の値に依る場合です.
例えば、gluが大きいほどgluが欠測しやすいとかです。
理論
多変量正規モデルを考えます。
この時、
観測されているデータから、未知のパラメータと未知の観測に関する事後分布
ここで、ギブスサンプリングを行うことで、目的のパラメータを近似できます。
-
\theta^{s+1} p(\theta|Y_{obs}, Y^{(s)}_{miss}, \Sigma^{(s)} -
\Sigma^{s+1} p(\Sigma|Y_{obs}, Y^{(s)}_{miss}, \Sigma^{(s+1)} -
Y^{s+1}_{miss} p(Y_{miss}|Y_{obs}, \theta^{(s+1)}, \Sigma^{(s+1)}
どのような分布からサンプリングされるのかの詳細は原著(https://sites.math.rutgers.edu/~zeilberg/EM20/Hoff.pdf) や上記の本を参考にして下さい。
実装
Google Colabを用います。
まず、データをダウンロードしたらpythonで読み込めるようにcsvファイルにしようと思います。
以下はtxtファイルからRでcsvファイルを作成するコードです。
Google ColabはRも動かせるので、以下でファイルを作成します。
data <- dget("/content/pima_miss.txt")
write.csv(data, file = "data_miss.csv", row.names = FALSE)
data <- dget("/content/pima_full.txt")
write.csv(data, file = "data_full.csv", row.names = FALSE)
そのあと、csvファイルをpandasで読みます。
import pandas as pd
df_miss = pd.read_csv("/content/data_miss.csv")
df_full = pd.read_csv("/content/data_full.csv")
df_miss.head()
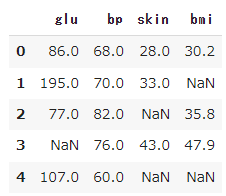
df_full.head()
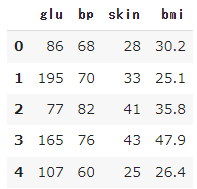
以下がギブスサンプリングによる、欠測値の補完です。
本で紹介されているRのコードを、Pythonで書き直したものです。
本では事前分布の平均として、
事前分散では、各平均値を2で割ったものを用いています。
import numpy as np
from numpy.linalg import inv
from scipy.stats import multivariate_normal,wishart
np.random.seed(1) # 乱数シードの設定
# データの次元を取得
n = df_miss.shape[0]
p = df_miss.shape[1]
# 事前分布のパラメータを初期化
mu_0 = np.array([120, 64, 26, 26])
sd_0 = np.array([60, 32, 13, 13])
L_0 = np.full((p, p), 0.1)
np.fill_diagonal(L_0, 1)
L_0 = L_0 * np.outer(sd_0, sd_0) # L0の非対角要素にsd_0の要素同士の積を乗算
nu_0 = p+2
S_0 = L_0
Sigma = S_0.copy()
Y_full = df_miss.copy()
# Yの各要素がNAでない場合は1、NAの場合は0となるマスクを作成
O = (~df_miss.isna()).astype(int)
# 各列について、NAをその列の平均値で置き換え
Y_full = Y_full.fillna(Y_full.mean())
THETA, SIGMA, Y_MISS = [], [], []
for s in range(1000):
# データの平均を計算
ybar = np.mean(Y_full, axis=0)
# thetaのサンプリング
L_n = inv(inv(L_0) + n * inv(Sigma))
mum = L_n.dot(inv(L_0).dot(mu_0) + n * inv(Sigma).dot(ybar))
theta = multivariate_normal.rvs(mean=mum, cov=L_n)
# sigmaのサンプリング
diff = (Y_full.values.T - theta.reshape(-1, 1))
S_n = S_0 + diff.dot(diff.T)
nu_n = nu_0 + n
Sigma = inv(wishart.rvs(df=nu_n, scale=inv(S_n), size=1))
# 欠損値のサンプリング
for i in range(n):
b = np.where(O.iloc[i, :] == 0)[0] # 欠損しているカラム
a = np.where(O.iloc[i, :] == 1)[0] # 欠損していないカラム
# bが空でない場合のみ処理を実行
if b.size > 0:
iSa = inv(Sigma[np.ix_(a, a)])
beta_j = Sigma[np.ix_(b, a)].dot(iSa)
Sigma_j = Sigma[np.ix_(b, b)] - Sigma[np.ix_(b, a)].dot(iSa).dot(Sigma[np.ix_(a, b)])
# Sigma_jが正定値であることを確認し、必要に応じて微調整
eigenvalues = np.linalg.eigvalsh(Sigma_j)
if np.any(eigenvalues <= 0):
Sigma_j += np.eye(Sigma_j.shape[0]) * 1e-6 # 対角要素に1e-6を加える
theta_j = theta[b] + beta_j.dot((Y_full.iloc[i, a] - theta[a]).values)
# Y_fullの更新
try:
Y_full.iloc[i, b] = multivariate_normal.rvs(mean=theta_j, cov=Sigma_j)
except np.linalg.LinAlgError:
print("共分散行列が正定値でないため、サンプリングに失敗しました。")
THETA.append(theta)
SIGMA.append(Sigma.flatten()) # flattenしてリストに追加
np.mean(THETA, axis=0)
本と近い結果が得られた。
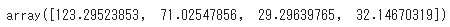
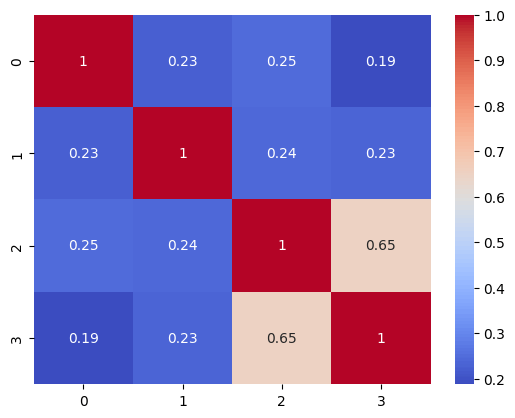
また、本では得られた
nn = len(THETA)
SIGMA = np.array(SIGMA)
# 相関行列を格納するための3次元配列を初期化
COR = np.empty((p, p, nn))
for s in range(nn):
# SIGMA の各行を p x p の行列に変形
Sig = SIGMA[s, ].reshape(p, p)
# 相関行列の計算
# 対角要素(標準偏差)の外積の平方根で Sig を除算
denom = np.sqrt(np.outer(np.diag(Sig), np.diag(Sig)))
COR[:, :, s] = Sig / denom
sns.heatmap(COR.mean(axis=2), annot=True, cmap="coolwarm")
本とほぼ同じ結果が得られた。
また、周辺事後分布の95%分位点に基づく信用区間を以下で算出できる。
# 結果を格納するための空の辞書
quantiles = {}
# 2.5% と 97.5% の分位数を計算
probabilities = [2.5, 97.5]
for i in range(COR.shape[0]):
for j in range(COR.shape[1]):
# COR[i, j, :]で、特定の位置における全ての値にアクセス
quantiles[(i, j)] = np.percentile(COR[i, j, :], probabilities)
# quantilesは、キーとして(i, j)のタプルを持ち、値として2.5%と97.5%の分位数のリストを持つ辞書です
# 結果を2つの(4, 4)形状の配列に整形
lower_quantile = np.zeros((COR.shape[0], COR.shape[1]))
upper_quantile = np.zeros((COR.shape[0], COR.shape[1]))
for i in range(COR.shape[0]):
for j in range(COR.shape[1]):
lower_quantile[i, j], upper_quantile[i, j] = quantiles[(i, j)]
cols = df_miss.columns.to_list()
# 4つの図を表示するコード
for i in range(4):
plt.figure(figsize=(10, 6))
positions = np.arange(1, 5)
# エラーバーの下限と上限を計算
lower_errors = lower_quantile[i, :] - lower_quantile[i, :]
upper_errors = upper_quantile[i, :] - lower_quantile[i, :]
# エラーバーをプロット
plt.errorbar(positions, ((upper_quantile[i, :]+lower_quantile[i, :])/2), yerr=[upper_errors/2, upper_errors/2], fmt='o', ecolor='r', capsize=5, capthick=2, label='Estimated Correlation')
plt.title(f'Correlation Coefficients with {cols[i]}')
plt.ylabel(f'{cols[i]}')
plt.xticks(positions, cols)
plt.ylim(0,1)
plt.legend()
plt.grid(True)
plt.show()
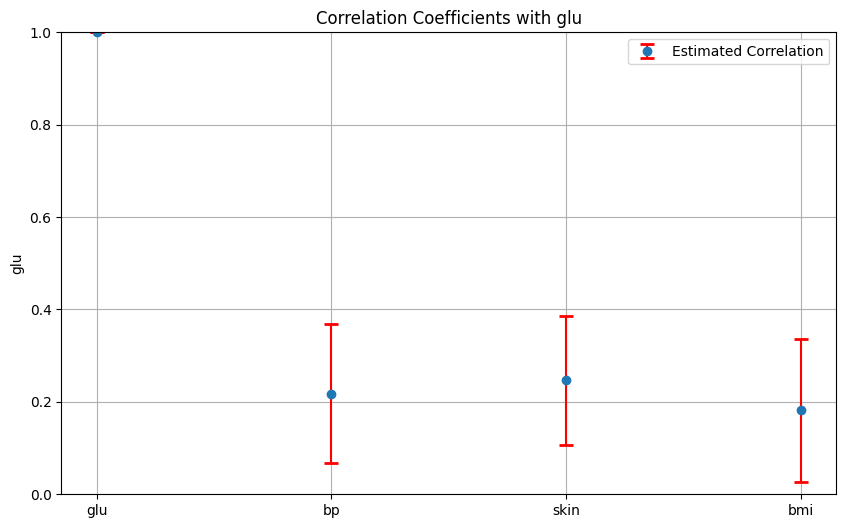
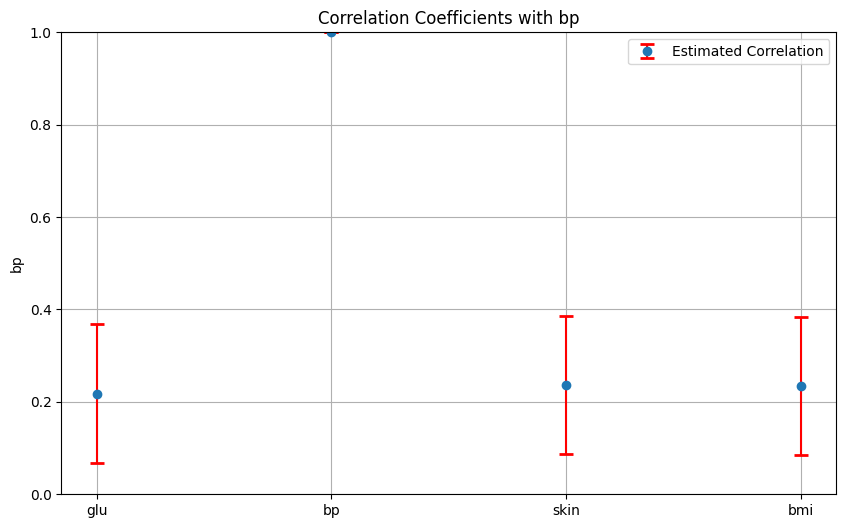
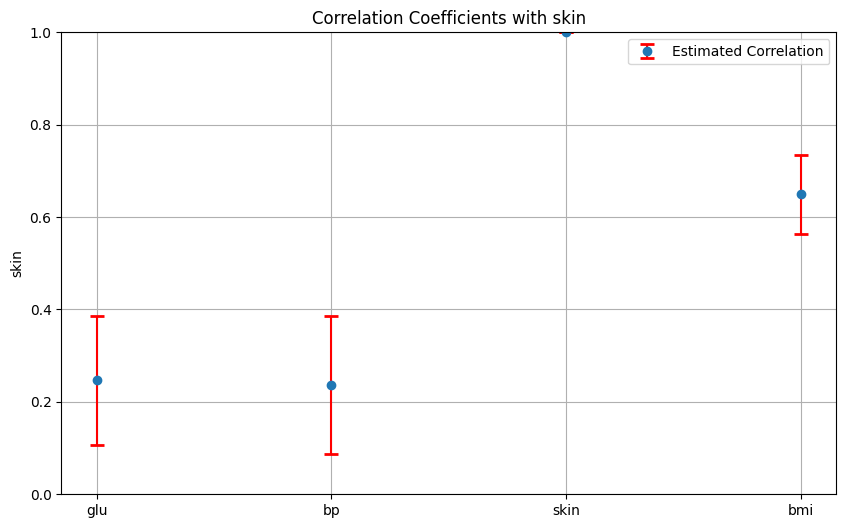
まとめ
標準ベイズ統計学の7章で解説されている「欠損データと代入法」を簡単に解説した。
その中の、Rで書かれたコードをPythonで実装した。
次はこの結果を用いた回帰を行いその精度を確認する。
Discussion