Child Mind Instituteの気になったSolutionまとめと反省




kaggleのChild Mind Institutionというコンペに参加し、見事惨敗しました(257位/1877チーム)。
コンペにちゃんと参加するのは初めてでしたが、それでもメダルを取れないと悔しいですね。
次のコンペでは勝てるよう、他の方のSolutionを読んで勉強しようと思い、この記事にまとめておきます。
どんなコンペであったか
このコンペの目標は、睡眠の開始と終了を検出することでした。
手首に装着された加速度計データと日にちを訓練データとして使用して、人の睡眠状態を判断するモデルを開発します。
どんなデータであったか
与えられたデータはtrain_seriesとtrain_eventです。
- train_series:複数日にわたる1人の被験者の加速度計データの連続記録
series_id : 各加速度計シリーズのユニークな識別子
step : シリーズ内の各観測に対するタイムステップ
timestamp : 日時(%Y-%m-%dT%H:%M:%S%z)
anglez : 腕の角度を体の垂直軸に対する角度
enmo : すべての加速度信号のユークリッドノルムマイナスワン
| series_id | step | timestamp | anglez | enmo |
|---|---|---|---|---|
| 038441c925bb | 0 | 2018-08-14T15:30:00-0400 | 2.636700 | 0.0217 |
| 038441c925bb | 1 | 2018-08-14T15:30:05-0400 | 2.636800 | 0.0215 |
| 038441c925bb | 2 | 2018-08-14T15:30:10-0400 | 2.637000 | 0.0216 |
| ... | ... | ... | ... | ... |
| fe90110788d2 | 592377 | 2017-09-08T00:14:45-0400 | -26.841200 | 0.0202 |
| fe90110788d2 | 592378 | 2017-09-08T00:14:50-0400 | -26.723900 | 0.0199 |
| fe90110788d2 | 592379 | 2017-09-08T00:14:55-0400 | -31.521601 | 0.0205 |
- train_event : トレーニングセット内の睡眠の開始と終了イベント。
series_id : train_series内にある、各加速度計データシリーズのユニークな識別子
night : 睡眠の開始/終了イベントのペア。各夜につき最大1つのイベントペアがあります
event : イベントのタイプ(開始or終了)
step および timestamp : 加速度計データシリーズ内でのイベントの発生時刻
| series_id | night | event | step | timestamp |
|---|---|---|---|---|
| 038441c925bb | 1 | onset | 4992.0 | 2018-08-14T22:26:00-0400 |
| 038441c925bb | 1 | wakeup | 10932.0 | 2018-08-15T06:41:00-0400 |
| 038441c925bb | 2 | onset | 20244.0 | 2018-08-15T19:37:00-0400 |
| 038441c925bb | 2 | wakeup | 27492.0 | 2018-08-16T05:41:00-0400 |
| ... | ... | ... | ... | ... |
| fe90110788d2 | 34 | onset | 574620.0 | 2017-09-06T23:35:00-0400 |
| fe90110788d2 | 34 | wakeup | 581604.0 | 2017-09-07T09:17:00-0400 |
| fe90110788d2 | 35 | onset | NaN | NaN |
| fe90110788d2 | 35 | wakeup | NaN | NaN |
どんな評価指標であったか
評価指標にはAverage Precisionというものが使われました。
ここにわかりやすい説明が載っています。
例では、48時間で、onsetとwakeupのペアを持つシリーズのサブセットを扱っています。
2つのイベントそれぞれに対応する予測を実線で示します。
注釈と予測の差が360ステップ(30分)を超えると、予測は下の図のようにスコア0になります。
つまり、±30分の差を超えると、予測はこの競技では役に立たないということです。
360ステップちょうど(予測が正解と30分ずれた)→ AP:0.0

359ステップ(予測が正解と29分55秒ずれた)→ AP:0.1

120ステップ(予測が正解と10分ずれた)→ AP:0.5

11ステップ(予測が正解と55秒ずれた)→ AP:1.0

solution
1st place solution
評価指標をしっかり理解することで、Post Processで適切に処理することが大事だと感じました。トップのひとはどれだけ複雑なことしているんだろうと思っていましたが、アーキテクチャは公開されていたもので、それを最終的にアンサンブルしたものでした。
Architecture
- input
(カテゴリ変数)
hour, minute, weekday, periodicity flag
(連続値の変数)
anglez / 45,
(enmo.log1p() / 0.1).clip_max(10.0)
anglez, enmo 12 steps rolling_mean, rolling_std, rolling_max
anglez_diff_abs 5 min rolling median
ここでカテゴリ変数にperiodicity flagというものがあります。
これは、被験者が加速度計をはずしている間のデータがある周期性を伴ったものになっており、その間はイベントが起こらないので、これを検知するために何かしらの手法でflagをたてているのですかね?
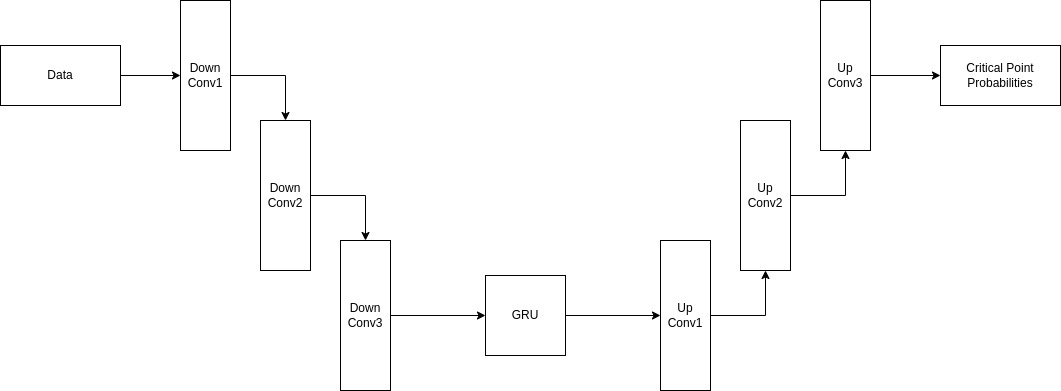
- Model Structure
このStructureを活用。
https://www.kaggle.com/code/danielphalen/cmss-grunet-train
-
input scaling
inputのスケーリングにはSEModuleを使用。
計算量は増えないけど、性能向上する?
https://qiita.com/daisukelab/items/0ec936744d1b0fd8d523 -
minute connection
ディスカッションやコードで議論されていた、イベントがminuteごとに偏った分布をしていること(これとかこれ)を考慮するために、アーキテクチャの最後にminuteの影響を反映させるようにしている? -
data preparetion
各シリーズのデータは、0.35日ずつずらした日ごとに分割される?
学習中は、各チャンクの半分を各エポックで使用? -
Target
onset, wakeupをそのまま正解として使うのではなく、正解からtolerance_steps = [12, 36, 60, 90, 120, 150, 180, 240, 300, 360]で中心から減衰する新しいtargetを作成(正解を中心に正規分布がひかれるイメージ)。
さらに、エポックごとにその分布が狭くなっていくようにしている。
これらの変更によっていかのようにスコアがよくなっていってます。
| 変更 | cv | +pt | public |
|---|---|---|---|
| ベースライン | 0.7510 | 0 | 0.728 |
| エポックごとにターゲットを減衰させる処理を追加 | 0.7699 | +19pt | - |
| 出力に周期性フィルタを追加 | 0.7807 | +11pt | - |
| batch_size: 16 → 4, hidden_size: 128 → 64, num_layers: 2 → 8 | 0.7985 | +11pt | 0.755 |
| 提出ファイルのスコアを日毎のスコア合計で正規化 | 0.8044 | +6pt | - |
| 入力から月と日を削除 | 0.8117 | +7pt | - |
| チャンクの両端を30分ずつトリミング | 0.8142 | +4pt | 0.765 |
| 分単位のフィーチャを最終レイヤに連結するように修正 | 0.8206 | +6pt | 0.768 |
Post Process
- コンペの評価指標
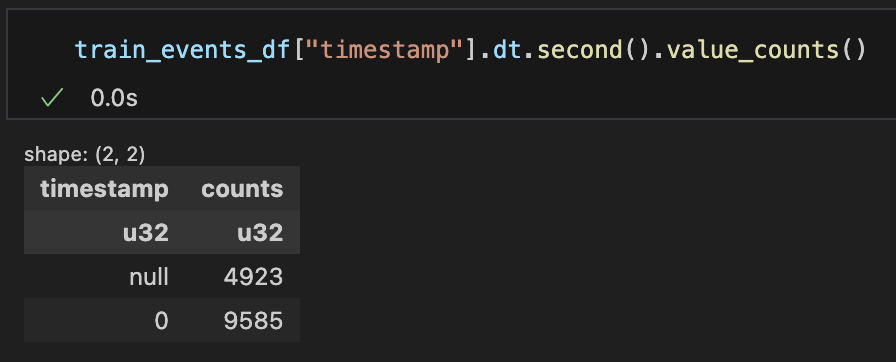
まず、このコンペティションの評価指標では、真の正解のイベントから30秒以内の予測は区別されない。そのため、提出されたタイムスタンプの秒数が5、10、15、20、...25であろうと、同じスコアが返される。
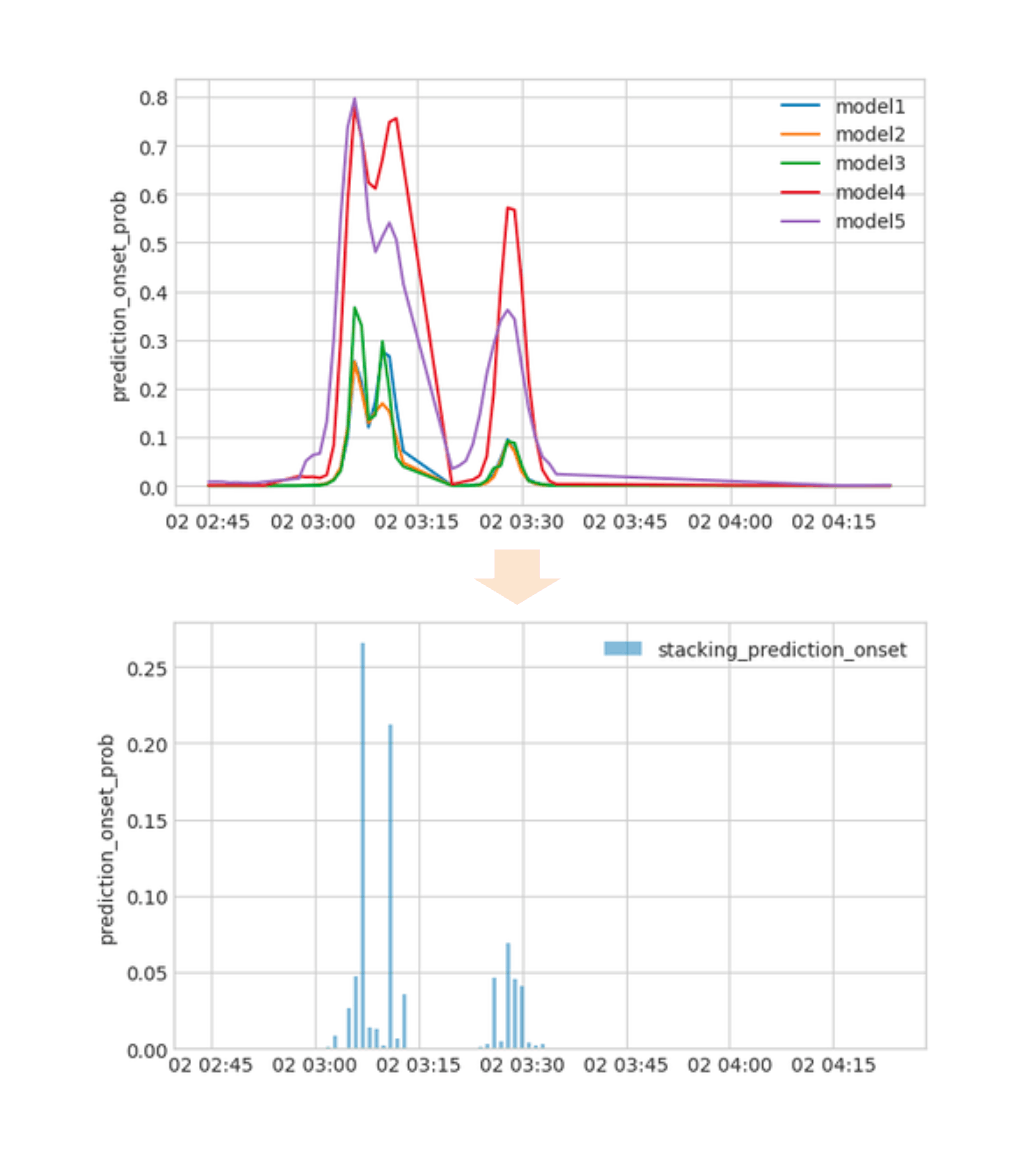
- 第2レベルモデルの作成
第1レベルモデルの予測は、真の正解のイベントから一定範囲内の事象を正と認識するように学習されている。
しかし、第2レベルモデルでは、これを各分ごとに真の正解のイベントが存在する確率に変換する。
具体的には、hh:mm:00 付近に集約された特徴量を入力し、イベントが発生した正確な時刻のみ 1 を予測し、それ以外は 0 を予測するように学習する。
- 各ポイントの得点計算
先に説明したように、同じ分内のどの秒を提出しても同じ得点になる。そこで、各分の15秒地点と45秒地点で得点を推定し、その値が最も高いものを提出することで、実質的に全ポイントで最も高い得点を提出することになる。得点の推定方法は以下の通りである:
- 例えば、10時00分15秒の時点での得点を推定してみよう。
10:00:15でのスコアを推定したいといった状況を考える
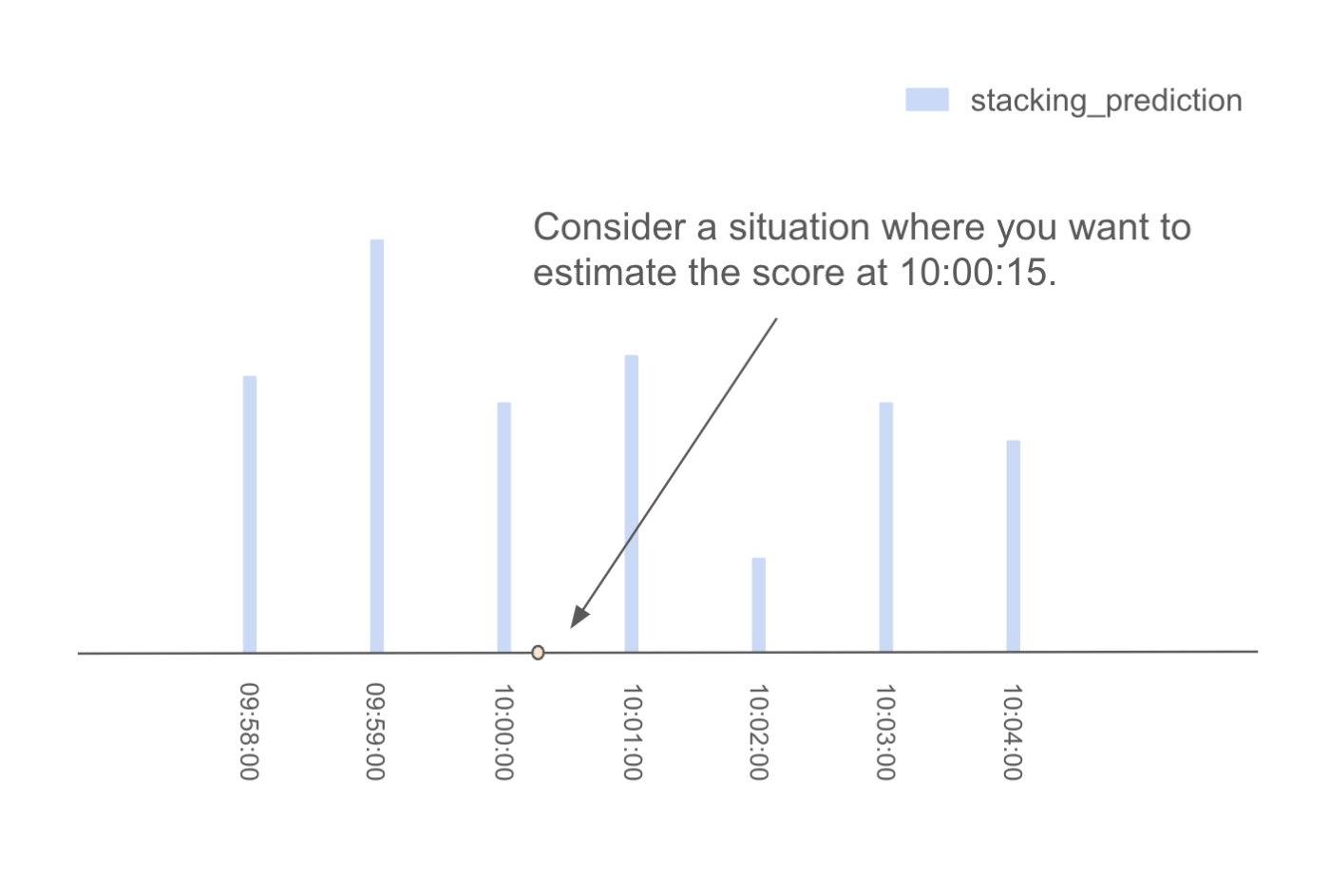
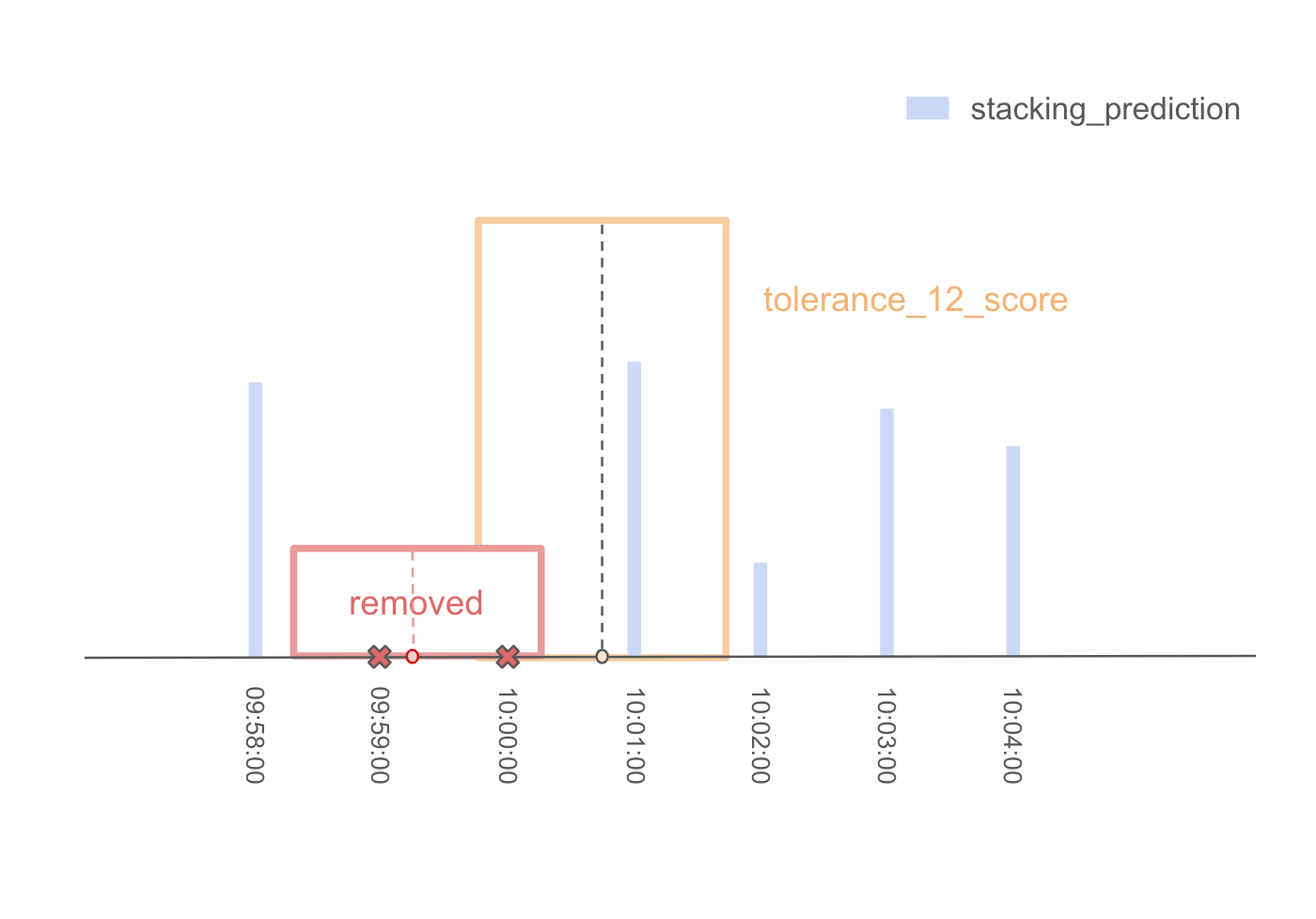
- まず、注目点から12ステップのウィンドウを作成し、このウィンドウ内の第2レベルモデルの予測値を合計してtolerance_12_scoreを計算する。
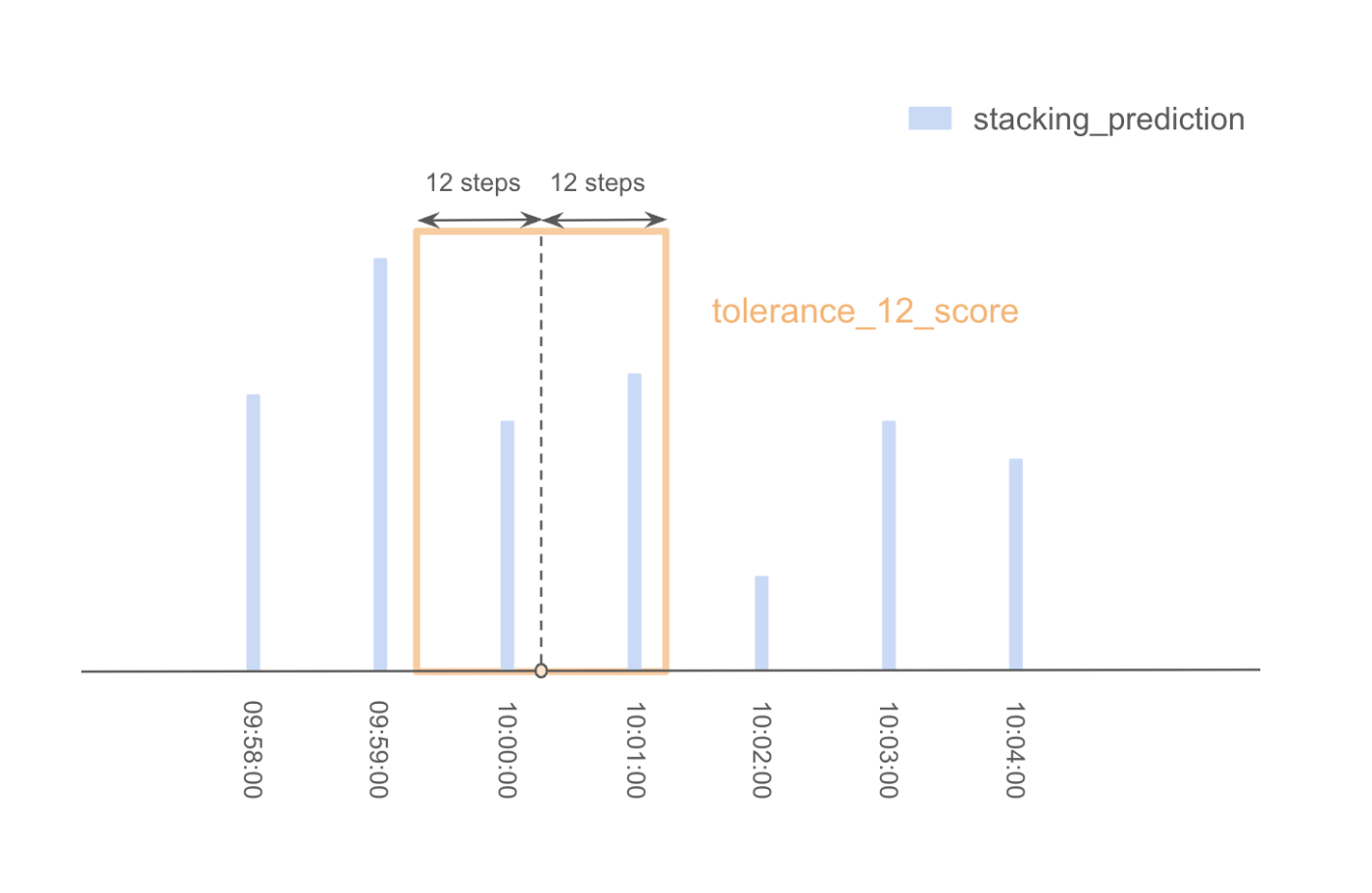
- 同様に、評価に使用されるそれぞれの範囲(tolerance_steps = [12, 36, 60, 90, 120, 150, 180, 240, 300, 360])について、tolerance_36_score、tolerance_60_score、...を計算し、これらのスコアの合計を注目点のスコアとみなす。
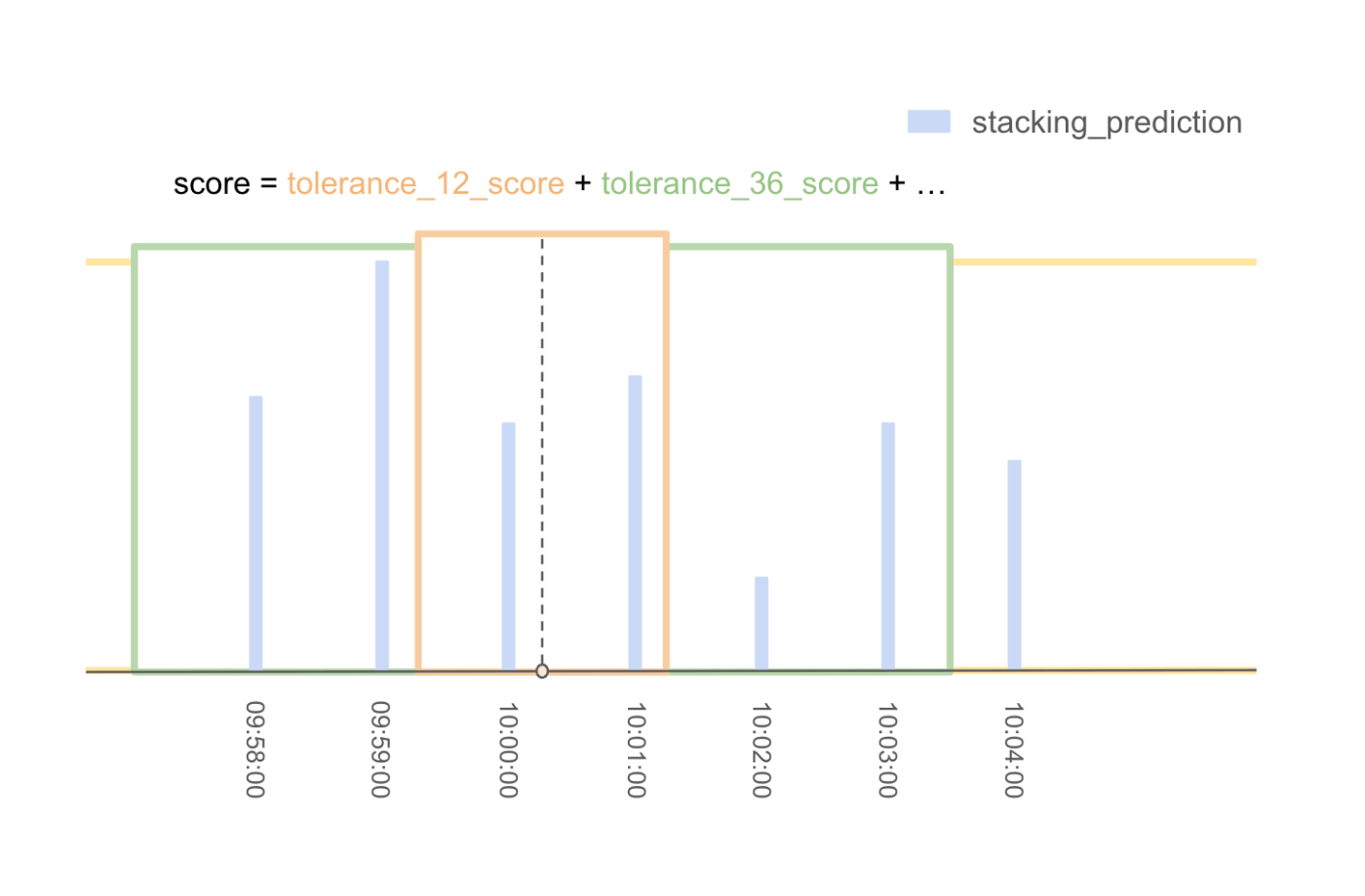
- すべてのポイントについてこの計算を行い、各シリーズについて、最もスコアの高いポイントを採用し、投稿DataFrameに追加する。
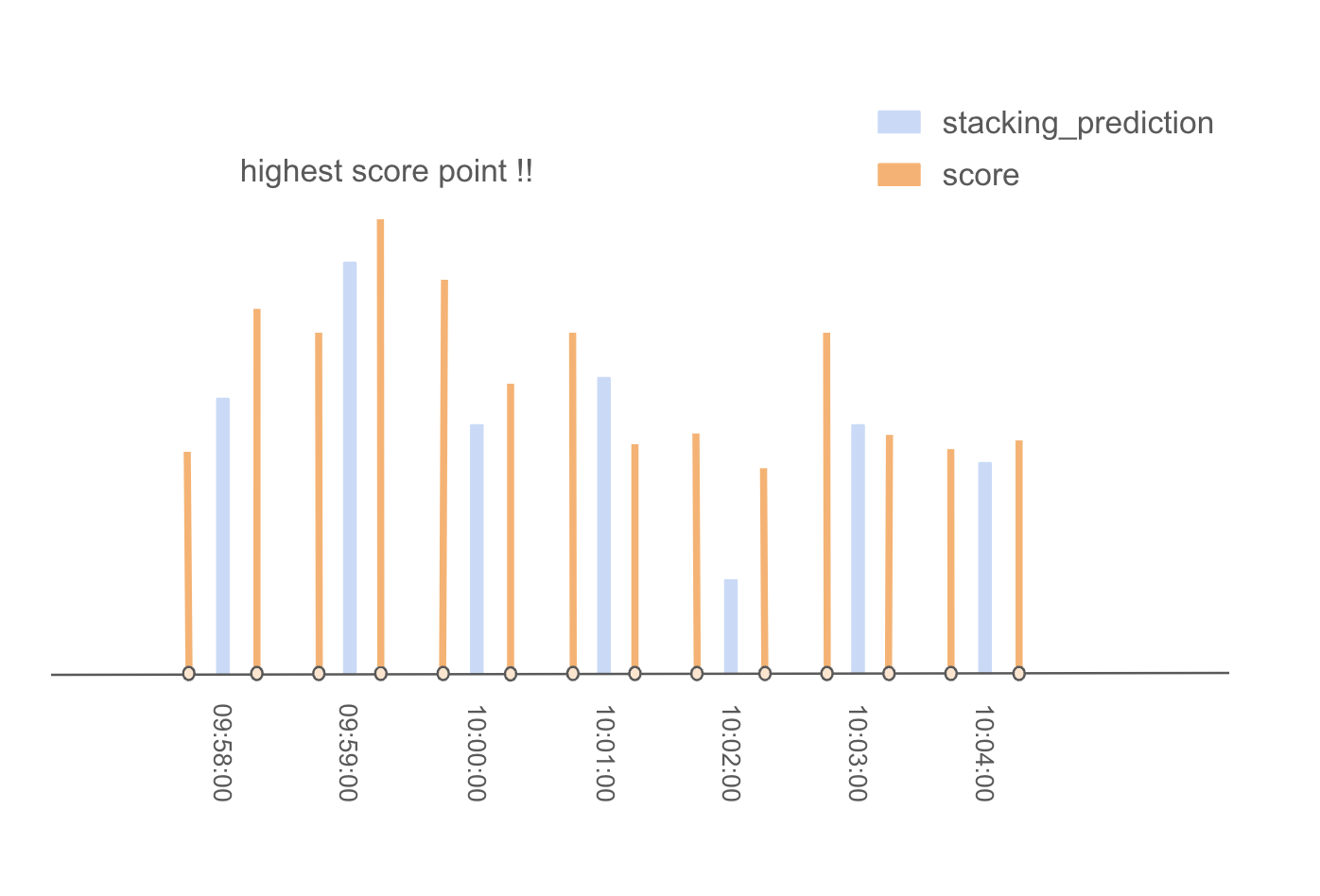
- スコアの再計算
- 次に、スコアを再計算し、次に採用するポイントを決定する。例えば、09時59分15秒が選ばれたとする。
まず、tolerance_12_scoreの更新を考えます。採用されたポイントから前後12ステップ以内のイベントは、次に提出されるポイントと重複して一致することはできません。
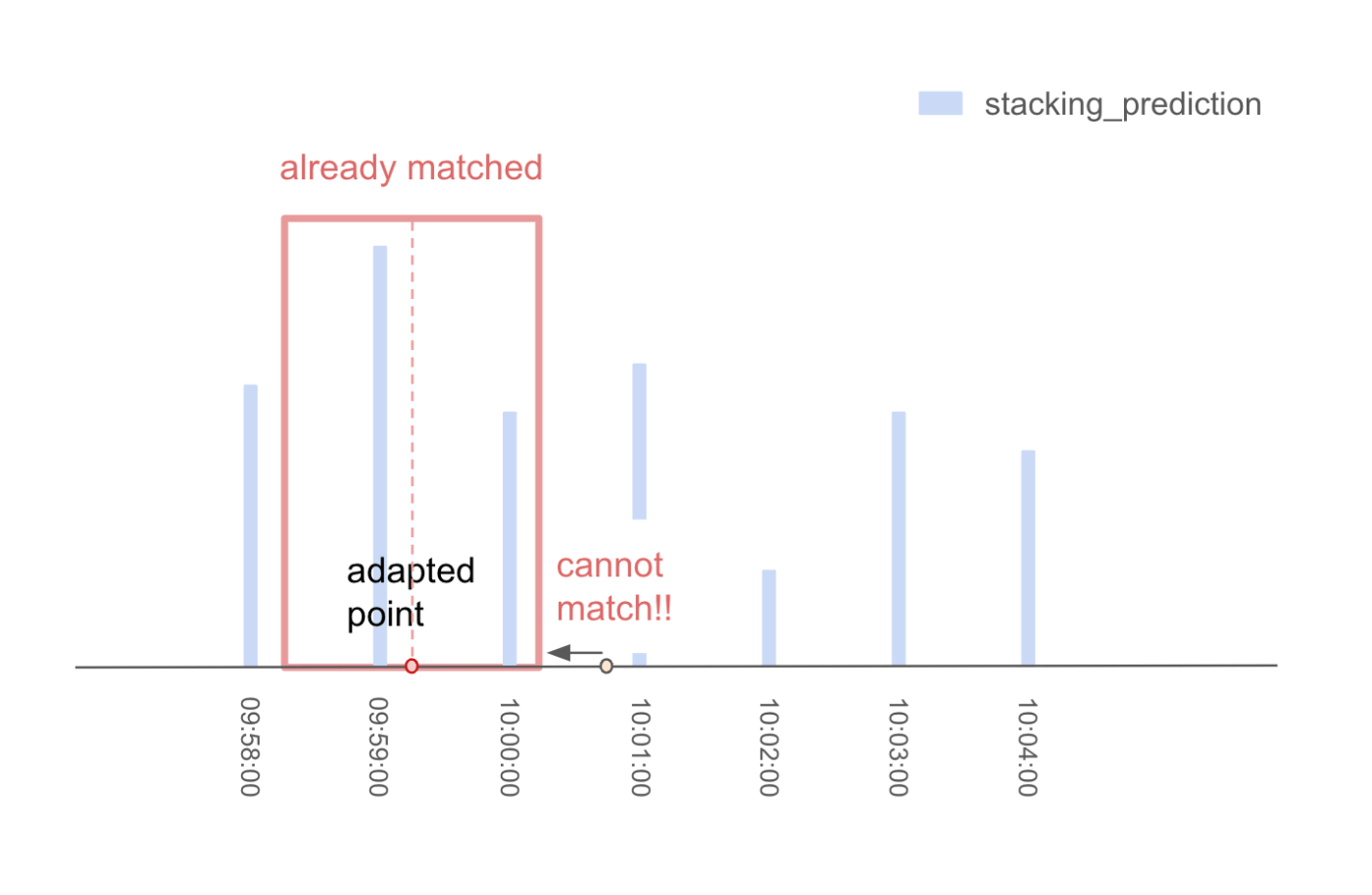
-そのため、次に採用するポイントのtolerance_12_scoreを計算する際には、現在採用されているポイントから12ステップ以内の予測値を割り引く必要がある。
- 同様に、tolerance_36_score、tolerance_60_score、...については、採用点から36、60、...ステップ以内の予測値を割り引いて再計算する。
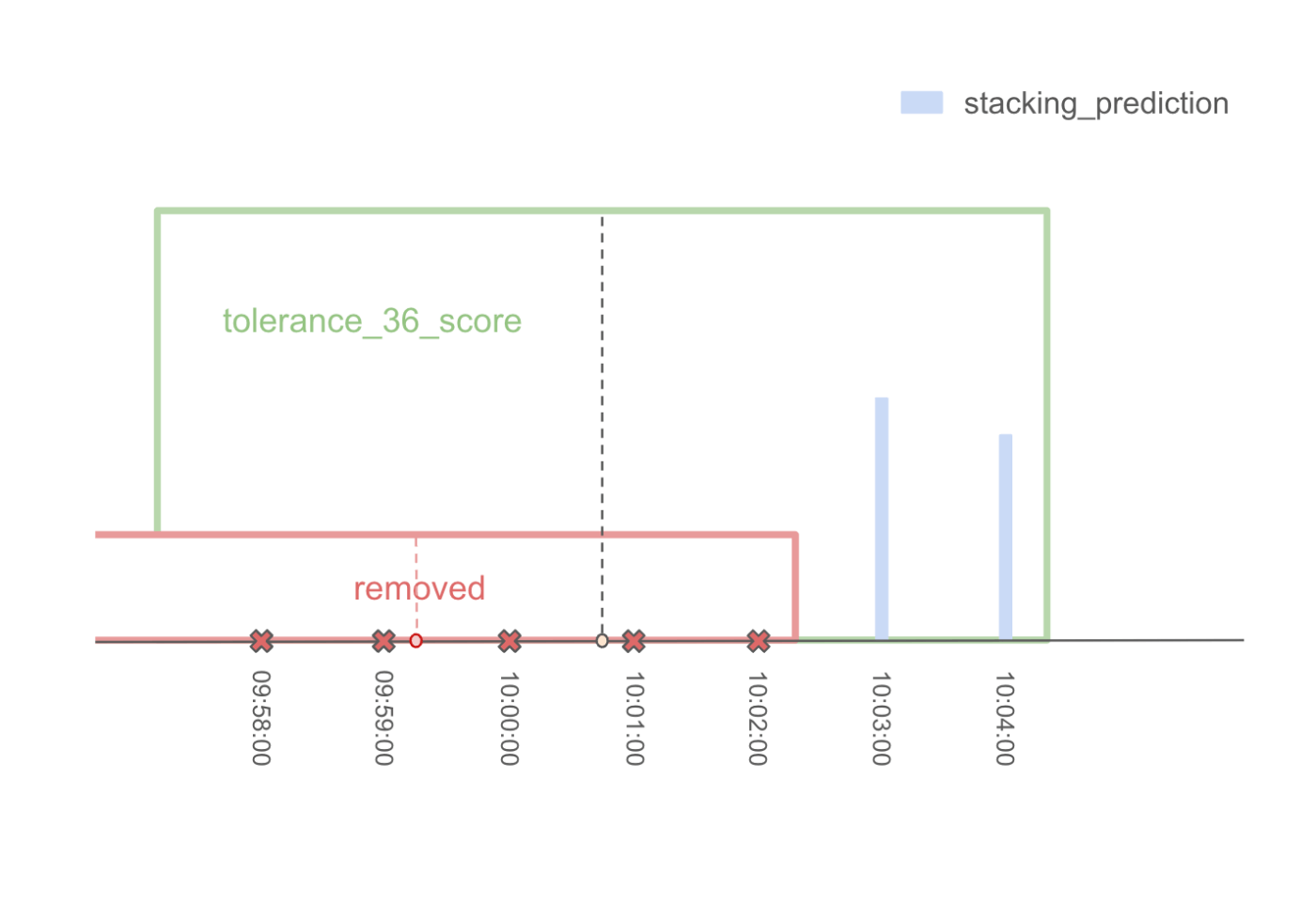
更新された得点を計算したので、再び各シリーズの最高得点を採用し、提出データフレームに追加する。
- submissionsの作成
- 上記のステップ4を繰り返して、十分な数の提出ポイントを抽出し、それらをDataFrameにいれてsubを作成する。
その他のテクニック
後処理を効果的に行うために、他にもいくつかのテクニックが用いられた:
- 第2レベルモデルの予測値を日ごとに正規化。
- スコアを再計算する際、前回のスコアとの差を計算し、計算量を減らす。
- JITコンパイルを使用して上記の計算を高速化する。
第2レベルモデルの詳細
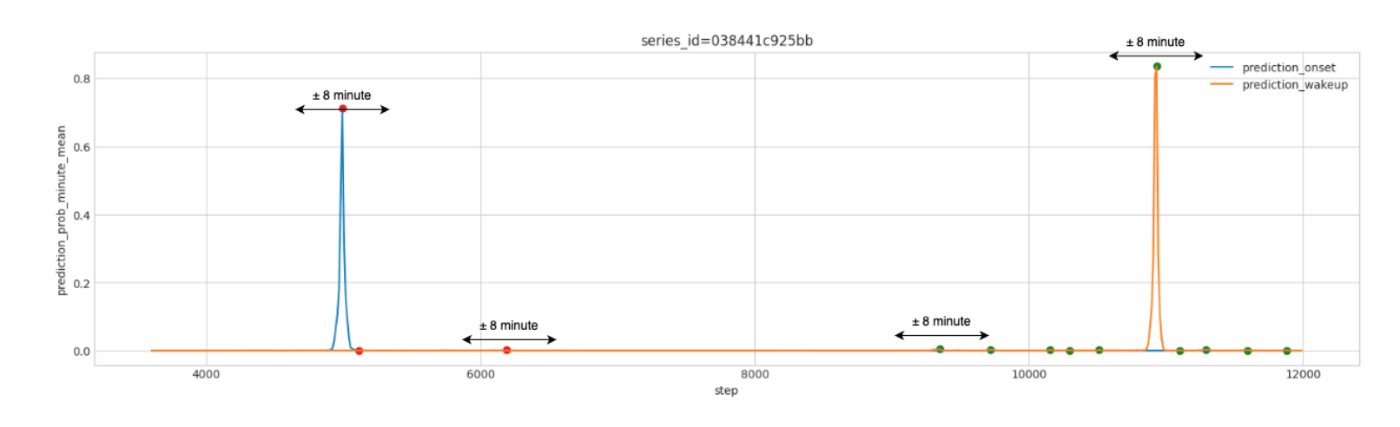
- 第2レベルのモデルは、第1レベルモデルの予測値を分単位で平均化し、高さ 0.001、距離 8 の find_peaks を使用してこれらの平均値からピークを検出することから開始します。
検出されたピークに基づいて、元の時系列からチャンクが作成され、各ピークの前後8分をキャプチャする。(リコール:0.9845)
このstep_sizeは非常に重要であった。というのも、いくつのstep_sizeが含まれるかによって、正例と負例の比率が変化し、後続ステージの精度に影響を与えるからである。したがって、最適なパフォーマンスを得るためにステップ数を調整した。
チャンクがつながっている場合、それらは1つのチャンクとして扱われる。
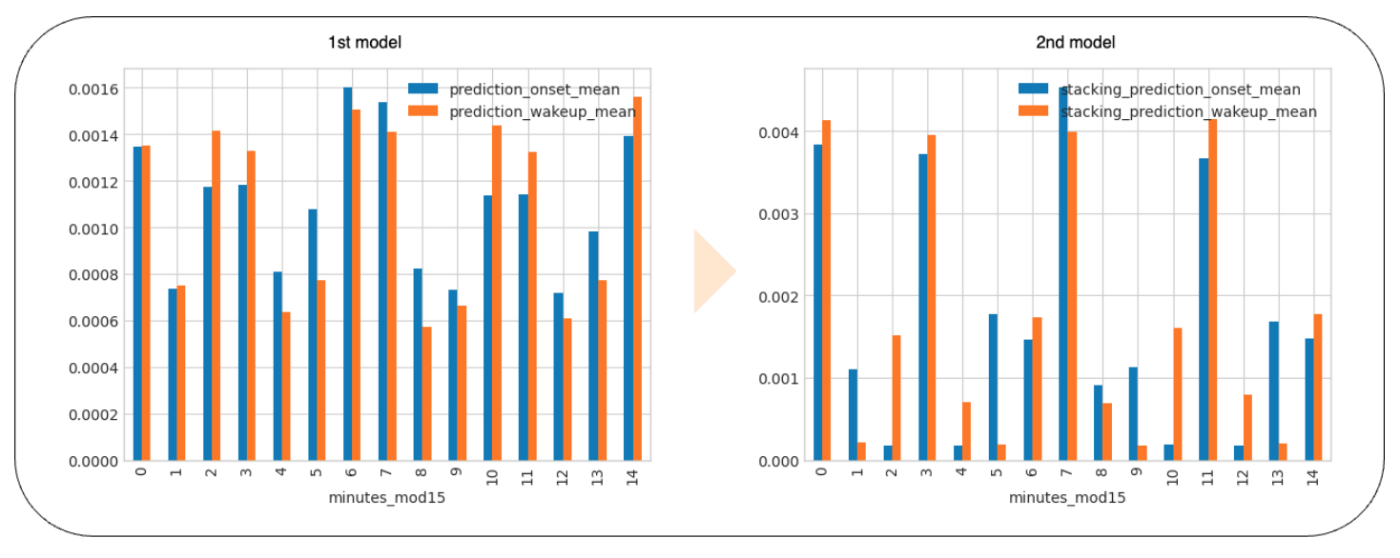
- 各チャンクについて、1つ目のモデルの予測値と、anglezやenmoのような他の特徴量から特徴量を集約した。これらの集約された特徴量は、LightGBMやCatBoostなどのモデルの学習に使用された。
- さらに、CNN-RNN、CNN、Transformerモデルを学習するために、各チャンクをシーケンスとして扱いました。その結果、第1レベルのモデルでは完全には対処できない微細なバイアスを考慮できるモデルを開発した。
5th place solution
LGBMでこのコンペに参加された方の解説です。Post ProcessでLGBMを使っている人はちらほらいましたが、最初から最後までをLGBMでやられたかたはこの方くらいでしょうか?ここでもやはりdiscussionから得た知見が実装されていました。
概要
・ヒューリスティック・ルールによるステップ候補の生成
・ステップの質を向上させるステップ修正モデル
・提出のためのスコア生成
・後処理
candidate生成
・|diff(anglez)|<5の領域:開始→睡眠、終了→覚醒とした。
・フェイク領域が非アクティブ領域によって拡張される:開始→ウェイクアップ、終了→オンセット?(理解ができませんでした)。
・720*2stepの範囲に他のcandidateがない場合、現在のcandidateは±720だけずれる。
モデル
・Lightgbm L1回帰。
・ターゲットにマッチしたステップの品質に興味があるだけなので、 |target|>=720 のデータポイントの重みはゼロに設定される。
・threshold_class_width^(-6)で重み付けを行い、ターゲットに近いデータポイントに重点を置く(例:120<y=127<150の場合、クラス幅は(150-120)=30)。
・minute%15とsecondが最も重要な特徴であるため、この段階は実際にステップの質を向上させるというよりも、ラベル生成プロセスにおけるバイアスを修正することが主な目的であると思う。そして、このステージの最も大きな利益は、実際には、特徴量の重要性リストには反映されていない、〜11ステップのシフトから来る。
・CVはinner foldで行われ、series_idで5fold group-k-fold。
スコアモデル
・クロスエントロピーを目的としたLightgbm
・target=max(0,1-|nearest_target_step-step|/360)とする。
・負のデータ点(target=0)は、|nearest_target_step-step| >/<360のデータ点に対して*0.7/0.4だけ重み付けを下げる。
・targetは、前ステージのout-of-fold予測によって与えられた補正されたステップに作成される。
・オンセット候補とウェイクアップ候補で異なるモデルを作成。series_idで5fold group-k-foldして検証。
後処理
・step%12=0 の場合、step+/- 1 で、より多くのターゲット・ステップに一致させる。
・gap<720の2つの候補について、以下の場合にのみ保持する:
min(|gap|/720,1)(exp_score1exp_score2/(exp_score1^2+exp_score2^2))^0.5>0.083
ここで
exp_score=np.exp(np.arctanh(2*score-1))
でなければ、スコアの小さい方を削除する。
これは候補が密集しすぎるのを避けるためで、候補に対するモデルの選好が明らかに偏っている場合にのみ機能する。
・その日のスコア合計>1の場合、すべてのスコアはスコアの合計で割られる。
29th place solution
このコンペに参加するにあたり、私もT氏のアーキテクチャをそのまま使っていました。
archtecture
2DCNN特徴抽出器 -> Unet -> Unetデコーダー
LSTM特徴抽出器 -> 1DCNN -> LSTMデコーダー
input
・enmo、anglez、anglez_diff、hour、weekday、ノイズフラグ。
・同じ系列_idで5分以内に同じ(enmo + anglez)が発生した場合、ノイズフラグが立つ。
・入力ステップは5760と11520が使用され、アンサンブルモデルと入力ステップのペアに基づく4つのモデルが使用された。
推論プロセス
・チャンクはinput_step/4をスライドして作成される。
・例えば5760モデルでは、チャンクのステップは0、1440、2880などから始まる。
・すべてのチャンクはステップごとに予測され、平均化される。
・CNNベースのモデルでは、エッジ予測は12.5%トリミングされる。
後処理
・イベント予測のみを使用(sleepフラグは使用しない)。
・SciPyシグナルからfind_peaksを利用し、予測スコアに基づいて検出されたシグナル付近のステップに加重平均を適用。
例えば、候補ステップが5000の場合、ステップ4998-5002の加重平均が計算される。
まとめ&反省
-
Kaggleでメダルをとるならアンサンブルは必須かもしれない
正直T氏のアーキテクチャをいい感じにいじっていけば、そのままメダルまで行けんじゃね?って思ってました。しかし、大体の人は複数のモデル出力をイベント予測に用いていたり、subをWBFや平均とったりしていました。 -
discussionをあまりにも読んでいなかった
私は、イベントの分布が変になっていたことは知りませんでしたし、評価指標の挙動も正確に理解できていませんでした。上位Solutionの解説を眺めていると、ほとんどの人はdiscussionから何かしらの知見を得て、それを実装していました。 -
NNのことについて知らなさ過ぎた
今回のコンペで初めてpytorchを触りました。本などで体系的に学んだことがないので、何がどうなっているのかがしっかり理解できていませんでした。 -
類似のコンペを探して、どんなアプローチが効果的なのかを調べるべきだった?
T氏のコードを見ていると、過去のコンペのアーキテクチャを参考にしている部分がありました。
他の方のSolution解説の中でも、過去の人のNotebookをもとにアーキテクチャを作っている人がいました。今のところpytorchやNNについて理解ができていない部分が大きいので、改良も難しいかもしれませんが、今後参考にできれば強力な手段になりそうです。
反省することも多いですが、学べたことも多くありました。特に、polarsを勉強するいい機会になったと思います。
というわけで、まず私はpytorchやNNについて体系的に学んでから次のコンペに参加することにしました。CMIコンペに参加した方は、数か月間お疲れ様でした。お互い高みをめざして頑張りましょう。
Discussion