ベイズ統計学・学習メモ

ベイズ推論とは
ベイズの定理による帰納的学習の過程
帰納的学習:ある集団の一般的な特性(パラメータ
その集団の一部(
ベイズ法:ベイズ推論の原理から導出されたデータ分析のツール
- 統計的に望ましい性質を持つパラメータの推定量
- 観測されたデータの簡潔な記述
- 欠損データの予測、将来のデータ予測
- モデルの推定、選択、検証のための枠組み
ベイズの定理
→
→
→
→ 確率の総和は1になるので、事後分布がそうなるようにするための定数
ベイズ統計の流れ
- 下調べ(問題の背景を調べる)
原因と結果の関係の仮説を立てる - 統計モデル(標本モデル、尤度関数、カーネル)を作成
0をもとに統計モデルを作る - 事後分布の計算
得られたデータから事後分布を推定する
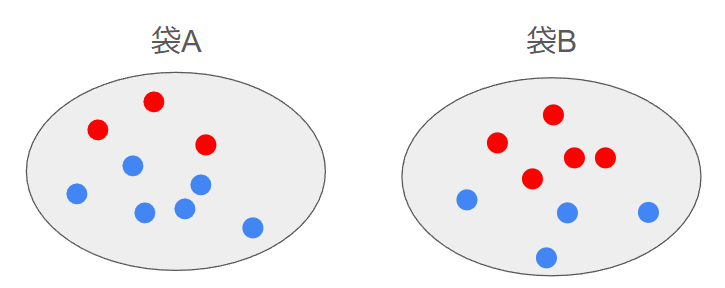
ex) 2つの袋があり、どちらかの袋から4回復元抽出をしたところ{青、青、赤、青}という結果が得られた。この時、袋Aが選ばれた確率はいくらか。
Yが赤・青の球を引く事象、Xが袋A・Bを選ぶ事象。
-
下調べ
ここで、袋Aのほうが若干選ばれやすいこと、それぞれの袋に青・赤の球がどれだけ入っているかは知っている。
p(X=a)=0.6, p(X=b)=0.4 -
統計モデル(標本モデル、尤度関数、カーネル)を作成
通常は未知である。〇〇分布に従うとかで定義する。
p(Y=r|X=a)=0.3
p(Y=b|X=a)=0.7
p(Y=r|X=b)=0.56
p(Y=b|X=b)=0.44 -
事後分布の計算
この例だと手計算だが、通常はMCMCをよく使う。
p(\theta|y) = \frac{p(y|\theta)p(\theta)}{\smallint_\Theta p(y|\theta)p(\theta)}
X=aの時は
p(y={b,b,a,b}|X=a)p(X)=0.7*0.7*0.3*0.7
=0.0617
X=bの時は
p(y={b,b,a,b}|X=b)p(X)=0.44*0.44*0.56*0.44
=0.0195
事後分布の規格化定数は
\smallint_\Theta p(y|X)p(X)
よって事後分布は
p(X=a|y={b,b,a,b}) = \frac{0.0617}{0.0617+0.0195}
=0.76
ベイズ更新
観測データが増えていくと事後分布も変わるが、どのように変わっていくのか。
データ1個の時は
データ2個の時は
となる。
このようにデータを逐次取りこんで、事後分布を更新していくことをベイズ更新という。
自然共役事前分布
※イメージ

という風に見ると、事後分布の形=事前分布の形となっている!
これが成り立つ事前分布を自然共役事前分布という。
以下、その例だがすべて覚える必要はなく、出てきたときに調べればよし。
| 確率分布 | 共役事前分布 | 事後分布 |
|---|---|---|
| ベルヌーイ分布 | ベータ分布 | ベータ分布 |
| 二項分布 | ベータ分布 | ベータ分布 |
| 正規分布( |
正規分布 | 正規分布 |
| 正規分布( |
逆ガンマ分布 | 逆ガンマ分布 |
| ポアソン分布 | ガンマ分布 | ガンマ分布 |
| 多項分布 | ディリクレ分布 | ディリクレ分布 |
何がいいのか?
→ 事後分布がベイズ更新のたびに複雑になることがない!
事後分布の推定
事後分布の推定方法には3つある。
①共役事前分布を用いて手計算(ただしパラメータが2つ以上あると難しい)
②MAP推定(確率分布全体を求めるのは諦め、代わりに事後分布の密度が最大になる点を求める)
③MCMCで事後分布をサンプリングする
共役事前分布を用いて手計算
例として、二項分布を考える。
二項分布は成功確率
二項分布の共役事前分布はベータ分布で、事後分布もベータ分布。
事後分布を計算してみると
ex)
コインを弾いたとき、表が出る確率を推定する問題を考える。
前提として、コインは歪な形をしており、どんな確率で表がでるか見当もつかなそうだ。
例えばコインを10回弾いて表が6回出た。
まず、事前分布を設定する必要がある。
ベータ分布はαとβの値によって、その形が変わるのだが、
つまり、どの確率をとる確率も一定ということになる。
→ コインを弾いたらどんな確率で表がでるか見当もつかなそうだ、という事前の信念をこれで表すことができる。
そして、実際に当てはめてみると、
別の試行で、30回弾いて18回表が出た場合も確認してみると、
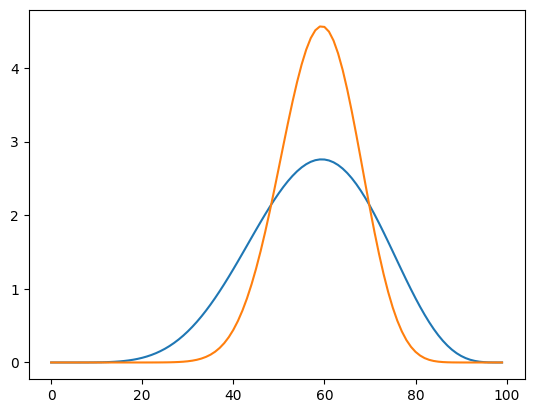
手計算で事後分布を計算する例と、事前共役分布を用いると簡単にそれが求まることが分かった。
MAP推定(事後分布の密度が最大になる点の推定)
MAPとはmaximum posterior pointの略で、事後分布の密度が最大になる点のこと。
つまり、
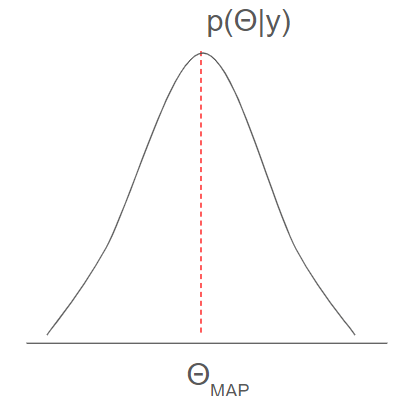
事後分布からMAP推定をする。
そのような時、
この最後の項は、最尤推定と同じ(無情報事前分布を用いたら最尤推定値とMAP推定値は一致する)。
MCMCで事後分布のサンプリング
先ほどまでは、手計算で何とか事後分布の情報を計算してきたが、実際問題として共役事前分布がすべての事前分布を表せるわけではない。また、パラメータが多い複雑な統計モデルとなるとこれらは難しい。そこで、MCMCが出てくる。これを使うと一般的な統計モデルの事後分布からパラメータをサンプリングできる。
Discussion