【初心者向け】DeepSeekの論文を読んだのでまとめます
はじめに
中国のスタートアップ企業であるDeepSeekが開発したAIモデル「DeepSeek-R1」は、その革新性から「DeepSeekショック」と呼ばれ、世界中で大きな注目を集めています。このモデルは、低コストでの開発と高い性能により、AI業界に大きな衝撃を与えました。
この論文について解説しますが、初心者向けに数式は用いずに解説していきます(というか自分も初心者です)。記事を書くきっかけは研究で使える知見を探しに来ました。
内容が間違えていたらコメントください!修正します。
論文のリンクを以下に記述しておきます。自分は英語が苦手なのでDeepLで翻訳してもらいました。
参考にした記事もありますのでそちらも貼っておきます。
なぜ注目されているの?
これは様々なニュースで取り扱われていますが、大きくいうと二つの点で注目されています。
- 低コストでの開発:DeepSeek-R1の開発費用は約5.58百万ドル(約8億円)と報告されており、これはOpenAIのモデル開発費用と比較して大幅に低いとされています。
- 高い性能とオープンソース化:DeepSeek-R1は、OpenAIの最新モデル(o1モデル)と同等の性能を持ちながら、オープンソースとして公開されています
Nvidiaなど、米テック企業の時価総額の話
-
Nvidia
1日目:低コストで高性能なAI開発に成功したことにより、AI開発に高性能GPUはほとんど必要ないんじゃないかという憶測から時価総額90兆円(17%下落)が吹き飛びました。
2日目:あまり知られていませんが、見直し買いにより9%程度上昇しました。 -
Apple、SalesForceなど
これらについては以外にもDeepSeekの発表を受けて株価は上昇しました。低コストでのAI開発が可能になることで、iPhoneなどの製品にAI機能を組み込む動きが加速し、製品の価値や需要が増大するとの見方が影響したようです。
どうやって高性能なAIの開発が実現したの?
大きく2つのステップで実現されました。
-
ベースモデルに対して強化学習のみを行い、強力な推論能力をもつDeepSeek-R1-Zeroを開発できた。
従来(OpenAI-o1シリーズなど)は強化学習よりも教師データを用いる教師あり学習に依存してきました。教師あり学習とは
簡単にいうと、「正解付きのデータを使ってAIを学習させる方法」です。正解付きのデータが教師データということになりますね。例えば、画像に移っている動物が犬か猫かなどです。
子供の学習にたとえると...
子供に「これは犬だよ」と写真を見せて教える(教師データ)
何度も見せると、子供は「これは犬」「これは猫」と正しく区別できるようになる(モデルの学習)
新しい犬の写真を見せると、「これは犬!」と正しく答えられるようになる(推論)AIに画像を学習させる場合...
「これは犬」「これは猫」とラベルの付いた画像データをAIに見せる(教師データ)
AIが犬と猫の特徴を自動的に学習する(モデルの学習)
新しい画像を見たとき、「これは犬だ!」と判断できるようになる(推論)このように、「正解」を教えて学習させる手法を「教師あり学習(Supervised Learning)」といいます。
DeepSeek-V3-Baseとは
DeepSeek-V3-Baseは「事前学習のみを行ったモデル」と言われています。これはつまり、一般的な自己教師あり学習(Self-Supervised Learning) の手法を使った可能性が高いです。
自己教師あり学習とは、「自分でデータの一部を隠して、それを予測する」学習方法です。
特にLLM(大規模言語モデル)では、「マスク言語モデル(MLM)」がよく使われます!Mask手法(MLM:Masked Language Model)の具体例
-
文章の一部を隠す(マスクする)
例:「今日はとても暑いです。」→「今日はとても [MASK] です。」に変更 -
AIが隠れた単語を予測する
「今日はとても 寒い です。」
「今日はとても 楽しい です。」 - 正しい答えに近づくように学習を繰り返す...
この手法を大量のテキストデータで繰り返し行うことで、AIは言葉の意味や文脈を学習していきます。
-
文章の一部を隠す(マスクする)
-
SFT(Supervised Fine-Tuning)+強化学習により、さらなるスペックを兼ねそろえたDeepSeek-R1を開発した。
DeepSeek-V3-Baseに対して、SFT(教師付きファインチューニング)を実施しました。その後、強化学習を適用させることで、今回発表された「DeepSeek-R1」が開発されました。SFT(Supervised Fine-Tuning)とは
すでに事前学習済みのAIモデルに対して、教師あり学習を使って追加学習を行うことです。
(例)法律専門のAIを作る
-
事前学習の状態(Wikipediaやニュースを読んだ状態)
❌ ユーザー:「著作権法第30条について教えて?」
🤖 AI:「申し訳ありませんが、わかりません。」 -
SFTを行う(法律の質問と正解のデータを学習)
✅ ユーザー:「著作権法第30条について教えて?」
🤖 AI:「著作権法第30条は、私的使用のための複製に関する規定です。」
-
(予備知識)OpenAI-o1シリーズはなぜ優れていたのか?
結論を言うと、o1モデルは、ポストトレーニングでCoT(Chain of Thought)を学習することで、推論能力を向上させています。 推論能力向上のためにポストトレーニングを行ったということですね。
ポストトレーニングとは
「ポストトレーニング」は、事前学習のあとに行う追加の学習(ファインチューニングなど)を指します。 ファインチューニング(fine-tuning)とは、すでに学習済みのAIモデルを特定の目的に合わせて追加学習させることです。
具体例
- 事前学習(プリトレーニング):AIは大量のテキストデータ(例えばWikipediaや本)を読んで、一般的な知識を学びます。
- ファインチューニング(ポストトレーニング):その後、特定の目的(数学の問題を解く、法律の文章を書くなど)に合わせて、追加の学習をします。
例えるならば?
- 事前学習 → 学校でいろんな科目を勉強する
- ファインチューニング → 医者になりたいなら、医学の専門知識を学ぶ
CoT(Chain of Thought)とは
CoTとは難しい問題をいくつかのステップに分けて考える方法です。
例えば、「2個のリンゴと3個のリンゴの合計は?」を解くときに、
- 2個と3個を足すということは計算式にすると、、
- 2 + 3
- この答えは5だな
- 答えは5個だ!
このように、順番に計算することで正しく答えを出せますよね。人間はこのようにして推論プロセス(計算プロセス)を実行しています。
強化学習を適用した手法であるDeepSeek-R1-Zeroの作り方
このDeepSeek-R1-Zeroの従来との違いは大きく二つだと思っています。
- ルールベースで評価値を決定したこと。
- グループに分けて相対的に良いかどうかを判断したこと。
そして、状態価値モデルと報酬モデルが必要なくなりました...計算量が削減されるわけですね...すごいです。これらについても解説しています。
そもそも強化学習って?
強化学習とは、「試行錯誤しながら最適な行動を学ぶ学習方法」 です。
「報酬(ごほうび)」を最大化するように行動を調整することで、AIがより賢くなります。
強化学習のイメージ(ゲームで例える)
例えば、マリオのようなゲームをAIにプレイさせるとしましょう。
マリオといえば、クリボーを倒したらスコア(報酬)がもらえますね。あとは早くゴールしてタイムボーナス(報酬)がもらえます。この報酬を最大化するように学習するということです。
- 最初のAIは下手 → 適当に動く
- 試行錯誤しながら報酬を最大化するように改善する → クリボーを倒せば報酬が少し高くなった。 ゴールしたらもっと報酬が高くなった。早くゴールすればさらにもっと報酬がもらえた!
このように、「試して → 結果を見て → 改善する」 を繰り返すのが強化学習というわけです。
DeepSeekは報酬をどのように決定したの?
ここが面白いところで、最初に挙げた
- ルールベースで評価値を決定したこと。
につながっています。
まず、マリオのようなスコアが決まるゲームならその報酬の最大化は難しいことではありません。しかし、文章に点数(報酬)をつけるって難しいですよね?
そこで、従来は、この点数付けにまた違うAI(報酬モデルといいます)を使用していました。しかし、この場合、その点数付けAIの点数を最大化するように学習してしまいます。例えば、推論プロセスが長いほど点数が高いのだとしたら、無駄に推論プロセスを長くしてしまうということです。
DeepSeekでは点数付けAIの使用をやめたようです。そして以下の単純な二つのルールで報酬を決定しました。
-
正確さの報酬
数学の問題であれば、最終的な答えがあっているかどうかで報酬を渡します。 -
フォーマットの報酬
推論プロセスが決められた場所に書かれているかで報酬を渡します。
この二つのルールで高度な推論が可能になったということです。実質2つ目は推論には関係ないので、ほとんど1だけで高度な推論が可能になったというのは驚きの事実だと思います。
DeepSeekのGRPO(Group Relative Policy Optimization)とは?
これが最初に挙げた
- グループに分けて相対的に良いかどうかを判断したこと。
につながってきます。
従来であれば、報酬を最大化するように学習していました。
さらに学習をよりうまくいく方法としてPRO(Proximal Policy Optimization)という手法があります。これは状態価値モデル(構造は一般にAIと同じニューラルネットワークベースです)というモデルを事前に準備し、それより報酬が高いか低いかを計算し、その差に基づいて学習を行うという手法です。しかしこれには問題があります。それは常に良い報酬になる時や常に悪い報酬になる時など、学習の調整が大幅になったり小幅になったり学習の状況に応じてスケールがばらばらだということです。
そこで、GRPOではそもそも何個か文章生成して、それの平均報酬を求めます。これより高いやつに寄せて低いやつからは遠ざければよいという発想に至っているというわけです。相対的に良いかどうかなので、学習状況によってスケールが大幅に異なるということはなくなったわけですね。
図で表すと以下のようになるわけです。
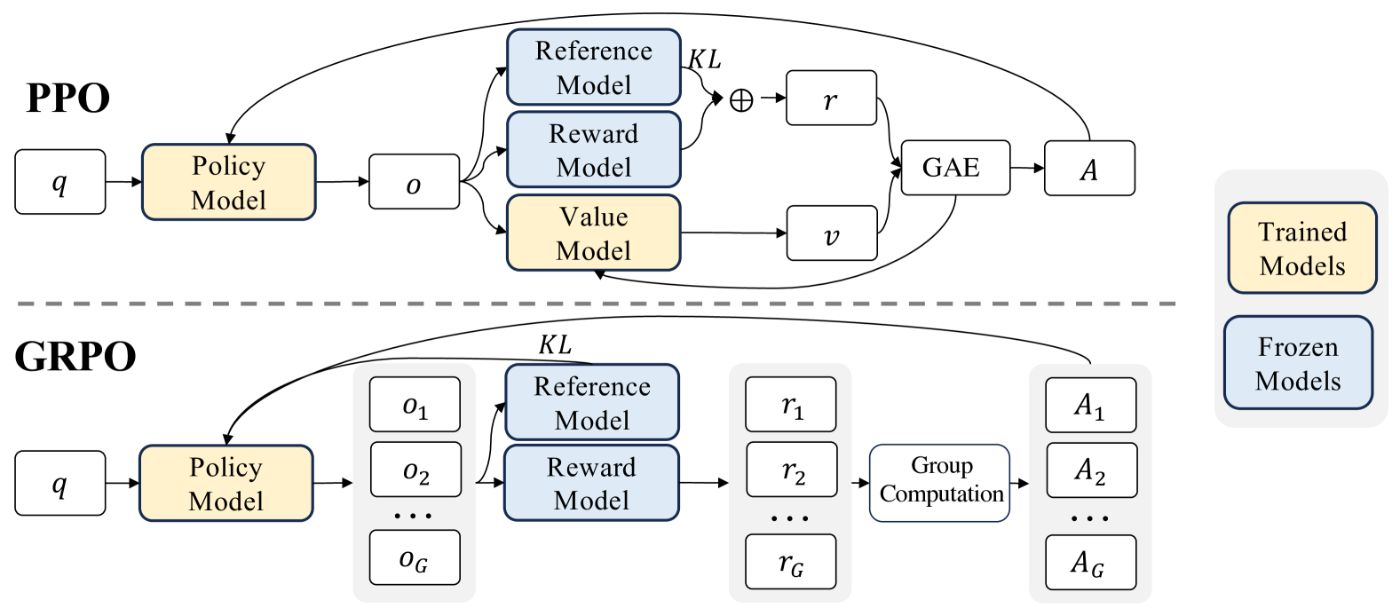
出典は以下です。
以上でDeepSeek-R1-Zeroの開発が終了しました。
SFT+強化学習を適用した手法であるDeepSeek-R1の作り方
DeepSeek-R1-Zeroはすごい性能です。しかし、二つの問題がありました。
- 強化学習の初期段階では学習が不安定である。(コールドスタート問題)
- 可読性の低さや言語の混在
この問題を解決するためにSFTが使用されました。
DeepSeek-R1のSFT(Supervised Fine-Tuning)について、論文の内容をもとにわかりやすく解説します。
DeepSeek-R1のSFTの流れ
DeepSeek-R1のSFTは、以下の4ステップで開発されました。
-
Cold Start(SFT)
いきなり強化学習を行うと学習が不安定になる(コールドスタート問題)現象が生じるようです。そのため、少量の長いChain of Thought(CoT)データを用いたSFT を最初に実施します。これにより初期の強化学習を安定化させ、より良い推論プロセスを確立できるようにします。 -
推論強化型強化学習(RL)
- 初期SFTを終えたモデルに、強化学習(RL)を適用します。
- 数学・コーディング・論理推論などのタスクに特化した報酬を設定し、推論能力を向上させます。
- 言語混在を防ぐため、「言語一貫性報酬」も導入します(例えば、英語と中国語の混在を抑える)。
- 再度SFT
- 強化学習後のモデルから、新たにSFT用のデータを生成します。
- DeepSeek-V3を活用し、人間の好みに近いデータを収集・最適化します。
- ここで、数学や論理推論だけでなく、一般的な文章生成・自己認識の能力も向上させます。
- 再度強化学習
- 「数学や論理の正解率」だけでなく、ユーザーの好みに沿った回答ができるように報酬を最適化します。
例えば、「明確で簡潔な回答を出せるか」や「ステップごとの推論を適切に行えるか」を評価する仕組み を導入しています。
DeepSeek-R1のまとめ
DeepSeek-R1のSFTは、段階的にデータを増やしながらモデルを最適化する形で行われました。また、推論タスクは主に強化学習、それ以外はSFTという認識です。
- Cold Start(SFT)
- 推論強化型強化学習(RL)
- 再度SFT
- 再度強化学習
この結果、DeepSeek-R1は推論能力が強化された上に、多様な言語タスクにも対応できるモデルになりました。
最後に
本当はこの後に蒸留の話もありますが、そこについては省略させていただきます。
強化学習についてより学びたいなと思っておすすめされている本をまとめておきました。
リンク先はアマゾンアフィリエイトになります。よかったら買ってみてください!
私は2の方しか読んだことがないのですが1の本も買いました。リンクは張らないですが、2番の本のシリーズはおすすめです。
(1)理論とコードどちらも知りたい方にはこれがおすすめ!
ゼロから作るDeep Learning ❹ ―強化学習編
(2)コードや実践向けのことを詳しく知りたい方はこれがおすすめ!
機械学習スタートアップシリーズ Pythonで学ぶ強化学習
いいねしていただければ嬉しいです。ここまで読んでくれて本当にありがとうございました!
Discussion
分かりやすいよー!😊