BQ上で非構造データも扱い、troccoを使って複数Detectモデルも呼び出しちゃう(BQのオブジェクトテーブル)
この記事は trocco Advent Calendar 2022 の16日目の記事となります。
はじめに(昨年のおさらいと今回)
昨年はtroccoで簡易MLOpsをまわしてみるというお題で下記をやりました
- 転送元:Https => BQでデータを取得
- troccoのデータマート上で簡易なEDA(というか加工)し、新しくテーブルを作成
- troccoのデータマート(自由記述モード)でBigQueryMLを記載(SQLでMLできる)
で、今回も引き続きML関連で記載するのですが、同じくBigQueryを使います
(そろそろ、RedshiftやSnowflakeネタもやっていきたい気持ちもありますmm)
今回やることとしては、下記をやってみます。
- 非構造データのメタデータをBQに格納
- GCS(Google Cloud Storage)にアップした画像をBQ上でメタデータ管理
- その情報を使って機械学習のObject Detection
- 物体検知モデルとしては複数(プログラミングETL呼び出しとSQL呼び出し)
- 上記をパイプライン化し、よりOps観点から考えてみる
- 推論された結果をどう可視化したり、評価できるか
じゃあ早速やっていきましょう!!
※一点お断り
2022年12月時点だと、以降記載一部の機能を使っていくためにはGoogle側への利用申請が必要です。
こちらのフォームで申請したら、数週間くらいで使えるようになっていたと思います。
BQ上でのオブジェクトテーブルを作成する
少し前にこのような記事が出ていました。
要約すると、
例えばgcs上にある非構造データ(画像や動画、音声など)はBigLakeを通して、シームレスにデータを扱えるようになり、現状のGCPが提供するサービスインタフェース上で検索や加工がしやすくなるよ
という理解をしております。おお素晴らしい。
で、この動画でどんなことができるのかがデモされています。
GSのバケット作成 ~ BQ上での呼び出し
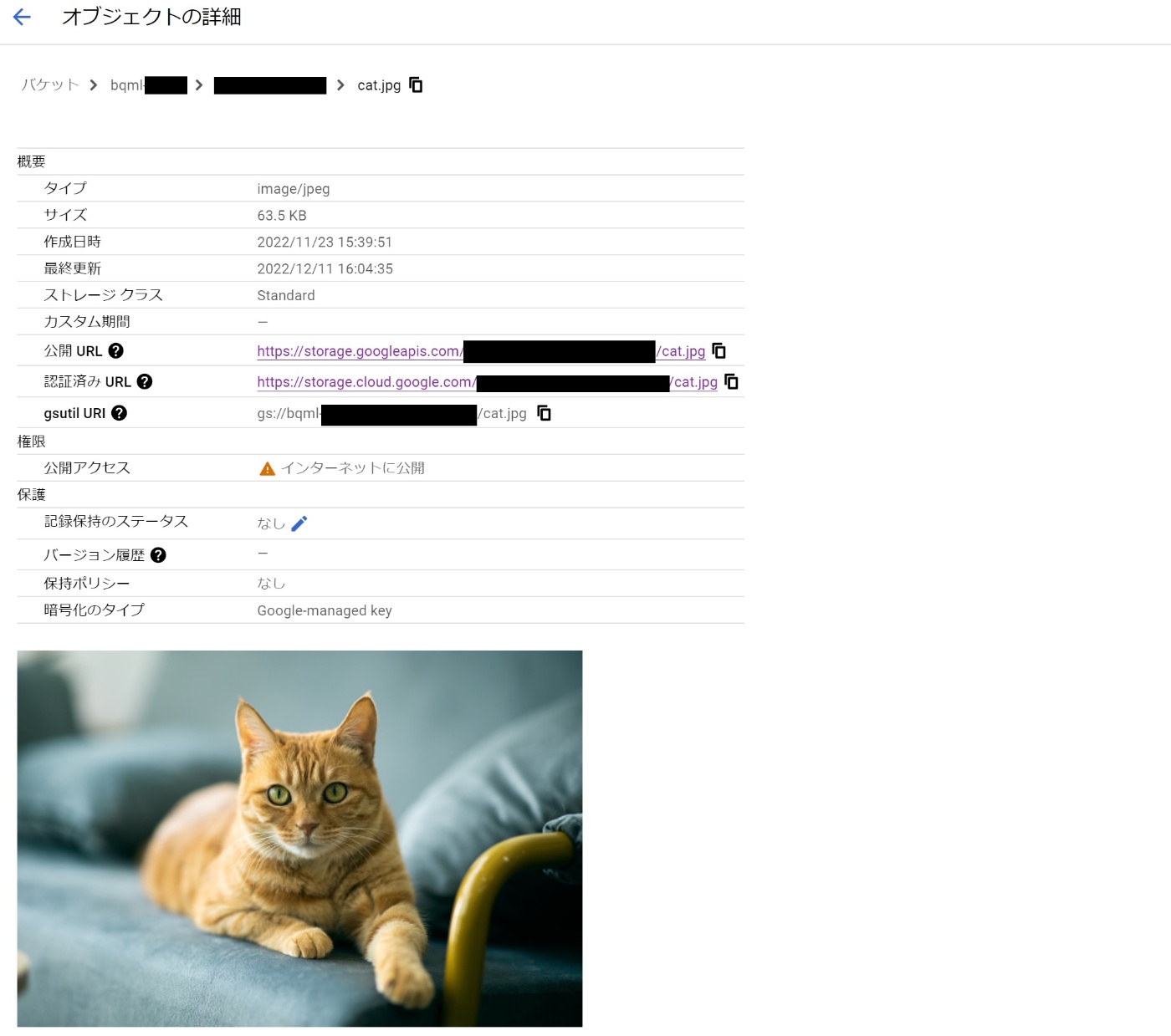
とりあえず、GCS上にバケットを作成し、猫の画像をアップロードしてみました。
ロケーションはUSを選択しています(フルオープンな機能ではないため、一旦USで統一)
※バケットを公開にしているのは、後続でpredictする際の一時的な試用のためです。
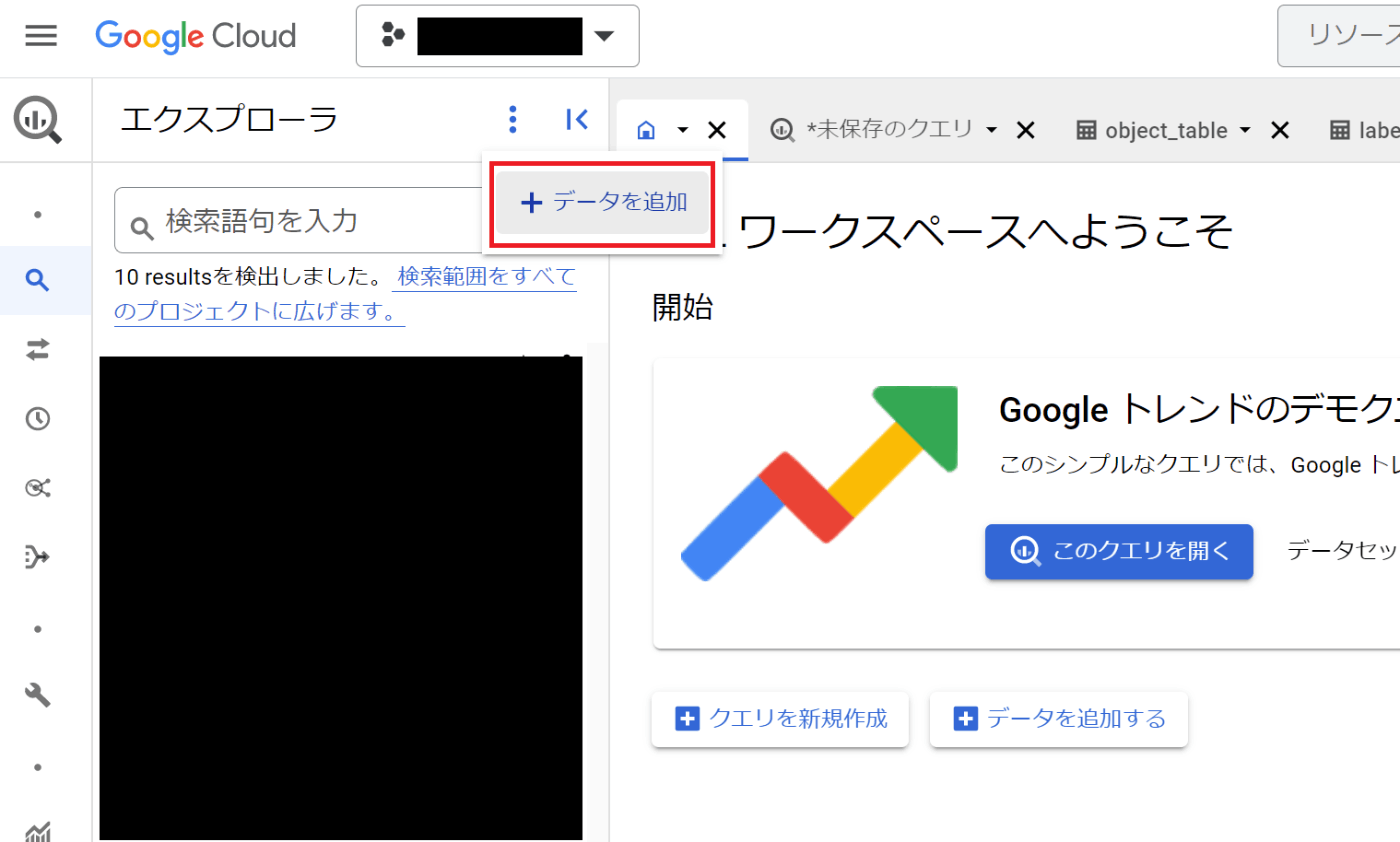
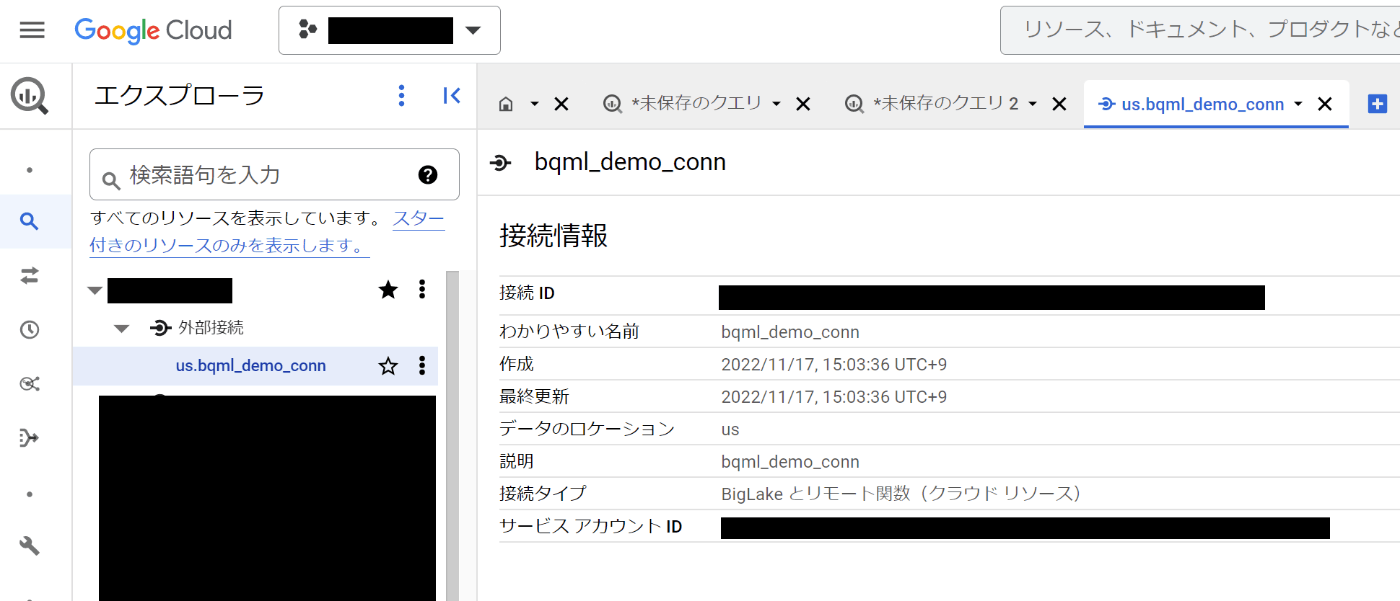
このバケットに対して、BigQueryコネクタを作成します
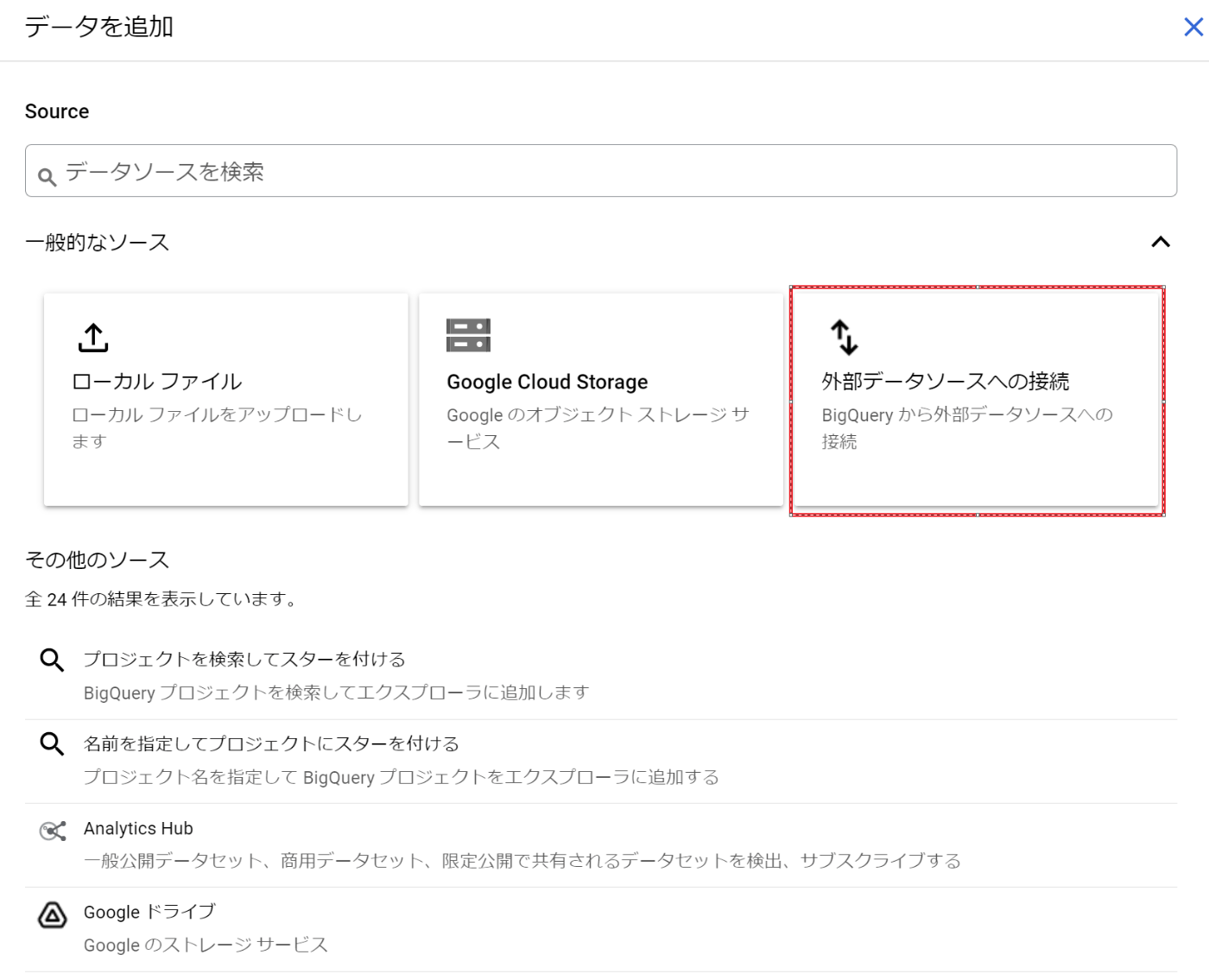
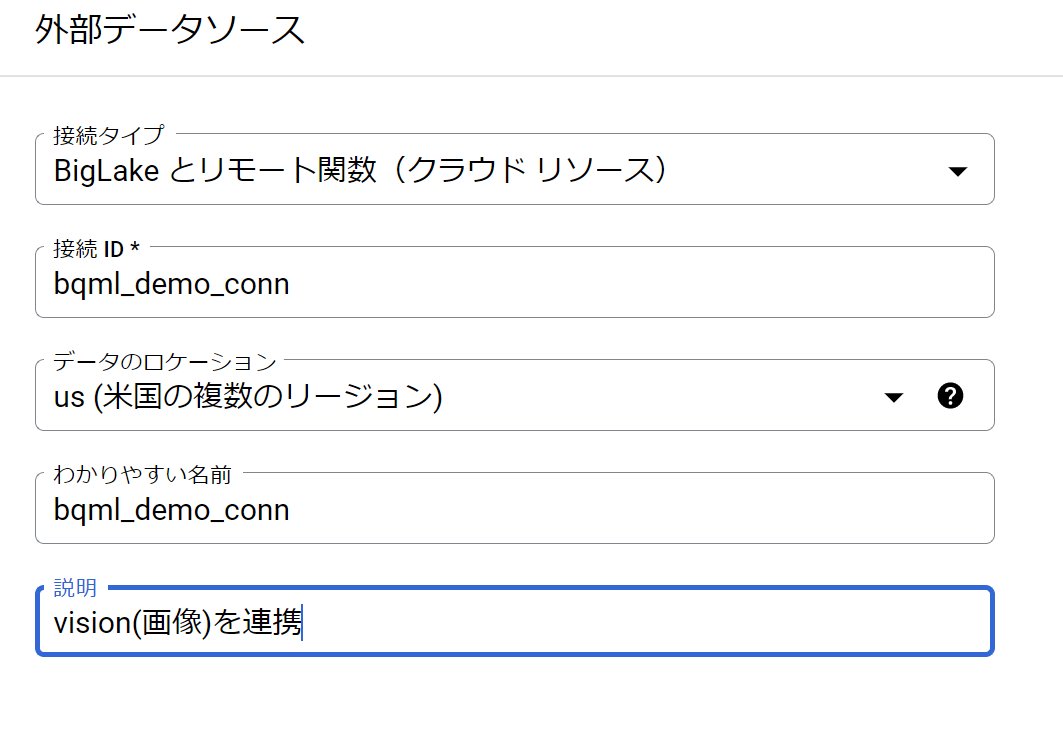
作成が終わると、外部接続のパイプが出来ているので、これを使って実際のテーブルを構築します。
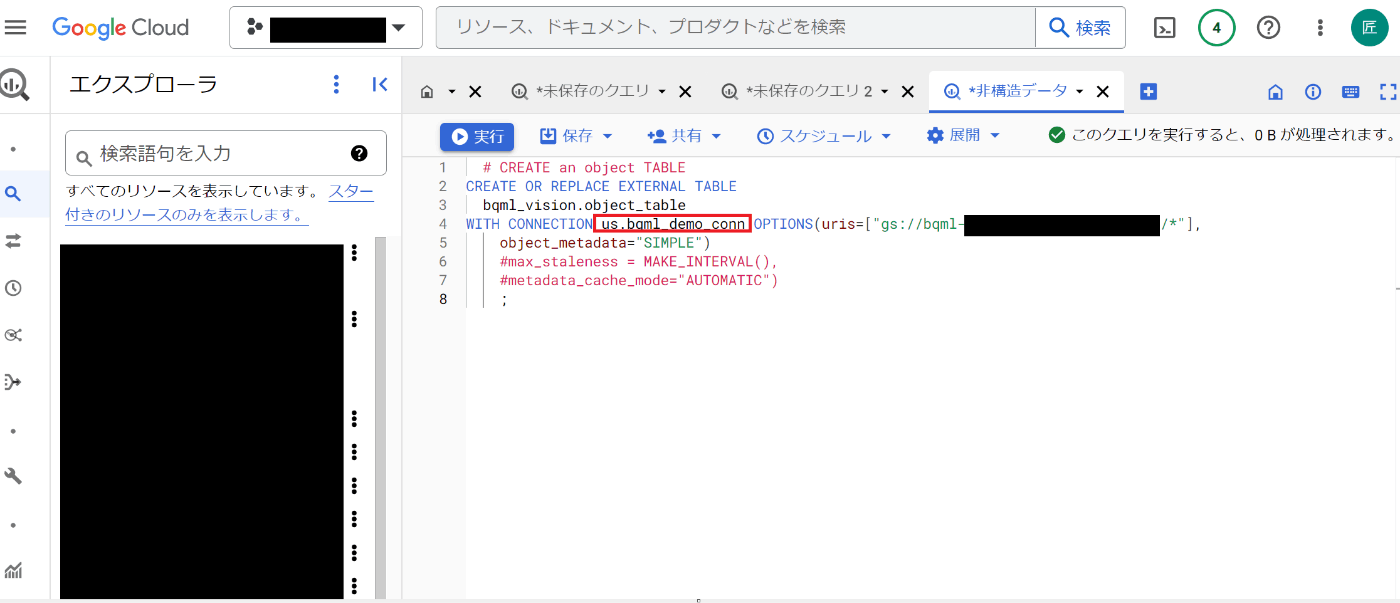
# CREATE an object TABLE
CREATE OR REPLACE EXTERNAL TABLE
bqml_vision.object_table
# 下記uriは複数してもできる様子
WITH CONNECTION 作成した外部コネクタ名 OPTIONS(uris="gs://具体的に読み込みたいバケットやフォルダ/*",
object_metadata="SIMPLE")
#max_staleness = MAKE_INTERVAL(),
#metadata_cache_mode="AUTOMATIC")
;
オプションの補足等はこちらを参照。特にシンクの頻度などもテーブル作成時のクエリパラメータで設定できるようなので、試行錯誤の作り直しも非常に簡単です。では、作成されたオブジェクトテーブルに対してクエリを叩いてみます

結果が取れました!ちゃんとストレージのパスやオブジェクト自体の情報も格納されています。また今後このあたりメタデータがよりリッチに取れるかもしれないですね。Docはこちら
Detectモデルの呼び出し(ResNet)
では、まず伝統的なモデルを使って、先ほど作成したオブジェクトテーブルを対象にObject Detectionをやってみます
ポイントは完全にSQLで呼び出しができるところです。これはDocはこちら
GSへのモデル配置と有効化
モデルは下記からダウンロードし解凍
解凍すると saved_model.pb ファイルと variables フォルダが展開されるのでこちらをGS上にアップロードしておきました。

配置が完了したら、モデルをBQ上に読み込みます。下記のクエリをBQコンソール上で叩きます
CREATE MODEL bqml_vision.resnet
OPTIONS(
model_type = 'TENSORFLOW',
model_path = 'gs://モデル配置したバケット名/*');
推論の実施
では作成したモデルに対して、オブジェクトテーブルの情報で推論をかけてみます。
SELECT *
FROM ML.PREDICT(
MODEL bqml_vision.resnet,
(SELECT uri, ML.DECODE_IMAGE(data) AS input_1
FROM bqml_vision.object_table)
);

取れました!ポイントはスキャン量がまあまあ大きいぐらいですかね(それでも知れてますが)
あと現状クエリ結果の返却時間がそれほど早くはない(n=1ですが10秒くらい)ので、この辺は今後調整が入ってくるかもですかね。
で結果の値はなんのこっちゃ?に見えますが、各決められたクラス(認識できるオブジェクトは全部で1001クラス)に対してのAccuracyスコアとなります。なので、結合してスコアが高いクラスを並び変えてみましょう。
1001のクラス情報はこちらからダウンロードし、BQ上のテーブルに読み込みました。
では改めて、ラベル情報を結合したクエリはこんな感じ
WITH predict AS(
SELECT
*
FROM
ML.PREDICT( MODEL bqml_vision.resnet,
(
SELECT
uri,
ML.DECODE_IMAGE(DATA) AS input_1
FROM
bqml_vision.object_table))
), t_unnest AS (
SELECT
score
FROM
predict,
UNNEST(activation_49) AS score
), t_score AS (
SELECT
ROW_NUMBER() OVER () AS row_num,
score
FROM
t_unnest )
SELECT
t_score.row_num,
t_score.score,
label.string_field_1 AS label
FROM
t_score
JOIN
`bqml_vision.label` AS label
ON
t_score.row_num = label.int64_field_0
ORDER BY
t_score.score desc

今度こそ見やすくなりました。先の猫ちゃん画像に対しては、Siamese cat(シャムネコ)という推論のようです。間違っていますが、それらしい結果が取れました。
おそらくfine-tuning等も実施できるはずなので、クラス情報を適宜BQに再読み込みとGCS側にモデルもアップロードし直せば、よりカスタマイズの効いたDetectはより簡易に実現できそうですね。
ちなみにここまでの流れが完全にSQLのみなので、この一連の流れをtroccoのデータマート上に実装できます。これは最後にまとめてワークフロー化してみます。
Detectモデルの呼び出し(Vision API)
盛りだくさんになってきましたが、もうひとつ推論のパイプラインを作ってみます。こちらはGCPのサービスである、Vision APIを呼び出す形となります。Docはこちら
公式では、Cloud Function側にリクエストを受け付ける関数を用意し、それをSQLで呼び出すような形で記載されているのですが、今回はtroccoの転送ジョブ1本で対応してしまおうと思います。
使用するのは転送ジョブ(転送元:BigQuery、転送先:BigQuery)に加えて、プログラミングETL機能を使うことでそれが実現できます!ではやってみましょう。
troccoにログインして「転送設定」から
転送元:BigQuery => 転送先:BigQueryを選択します

ジョブの設定自体の補足は下記に譲るとして
転送元:BigQuery
転送先:BigQuery
抽出すべきデータは先で作成したオブジェクトテーブルの情報なので、シンプルに下記でOKですね
select
uri,
generation,
content_type,
size,
md5_hash,
updated,
from
`bqml_vision.object_table`
でサクサクとSTEP2にうつるとプレビューが取れることを確認。

で、ページ下層のプログラミングETLに移り、リクエストを発行していきます。trocco上のプログラミングETLではPythonとRubyでスクリプトが書けるので、今回はPythonでコードを書きます。
でPythonのクライアントライブラリを使えば、下記で書ける(はずです)
(+あとGCPサービスアカウントの読み込みが必要)
from etl_base import EtlBase
from google.cloud import vision_v1
import urllib.request
import json
class Etl(EtlBase):
# def __init__(self):
# pass
def transform_row(self, row):
#Pythonのクライアントこれだけで書ける
client = vision_v1.ImageAnnotatorClient()
replies = []
results = client.label_detection({'source': {'image_uri': row["uri"]}})
row["response"] = vision_v1.AnnotateImageResponse.to_dict(results)
return row
検証かつ、突貫でやっていたので、クライアントがPython環境にinstallされていなかったので、RestAPI呼び出し + APIアクセスキーで書いています。その場合は下記のようなコードになります
from etl_base import EtlBase
import urllib.request
import json
#from google.cloud import vision_v1
class Etl(EtlBase):
# def __init__(self):
# pass
def transform_row(self, row):
# row["new_column"] = "trocco"
#{}.formatはNG
url = "https://vision.googleapis.com/v1/images:annotate?key=発行したAPIキーを記載"
json_requests = '{ "requests":[ { "image":{ "source":{ "imageUri": "' + row["uri"] + '"} }, "features":[ { "type":"OBJECT_LOCALIZATION", "maxResults":1 } ] } ] }'
headers = {'Content-Type': 'application/json'}
req = urllib.request.Request(url, json_requests.encode(), headers)
with urllib.request.urlopen(req) as res:
rsp = json.loads(res.read())
row["response"] = rsp
return row
で、実際に実行してみると、vision-apiでの推論結果でcatがちゃんと取れました。

これで一旦完了ですね。もし追加で考えるべきとしては、DWH側への格納方法でしょうか。
今回は物体は猫だけでしたが、実際は複数あるはずです。
プログラミングETLでは1行のinputに対して、1行のアウトプットとなります。
もしResponseであるJSONをバラして縦持ちしたい場合は、一旦このままJSON形式でDWHに格納し、後続のデータマートジョブでparse_jsonするのがよさそうです。または、maxのResult数がリクエストパラメータで固定できるので、1行のレコードに対してその設定した数だけカラムを横持ちさせて必要に応じてNULL埋めするのもありです。でも個人的には縦持ちがやっぱ好きですね。
で、ジョブを作成完了し、実行結果です。
最終的にオブジェクトテーブル情報が必要であればBQ上でテーブルを結合すればよいので、URIとresponseのみをカラムとして持たせました。ここにjson_parseをするデータマートを加えればワークフローは完成です。


ワークフロー化
長くなってきたので、さいごに作ったものをワークフロー化してみます。

各工程の結果を全てBQ上に残して、推論結果もマージするところまでワークフロー化できました。
オブジェクトテーブルは毎度replaceする形で再作成していますが、実際はGS読み込みの頻度設定ができるため、ジョブとしては不要かもしれません。
ワークフローの処理時間は1枚の画像に対しての推論なのであてにはなりませんが、troccoではワークフローの並列度を上げることも可能なので、vision apiの他の判定タスクを並行して呼んだり、fine-tuningしたモデルを呼んだりもすることができそうですね。
複数のモデルを並列で評価できるようなパイプラインを自前でしっかり組んでいる、またはマネージドのサービスを使っている方はそれほどメリットに感じられない点かもしれませんが、簡易的に進めていきたい方には是非おすすめできます。
さいごに
素晴らしいことに各工程のデータがBQ上に蓄積されているので、今後trocco上でできることは
- Lookerstudioでダッシュボードを作成し、判定結果を可視化する
- trocco上のデータマートジョブやdbt機能を使ってより判定やテストを行うことで、別モデルでの再評価や画像の振り分けを行う
- 判定結果をgsのURIとともに他のサービスに書き戻す(リバースする)
などが楽にできるため、より精密なパイプラインやOpsを構築することができます。
さらに、今回非構造データをDWH上で管理できたということもあり、構造化データのパイプラインと並列管理をすることで新たなシナジーを生むことが考えられます。例えば、SaaSに入っている営業のユーザーデータ(構造化)と名刺の画像データ(非構造)を同じパイプラインで管理することもできそうです。紐づけがよりやり易くなるため、社内のオブジェクト整理や検索などにも使えるかもしれません。
夢は広がる一方なので、今日はこのあたりまでにしておきます
troccoに興味が出てきた方は是非、お問い合わせや一緒に働きましょう!
👍👍👍
Discussion