はじめに
StoryHub株式会社の@hanamaです。
随分と間が空いてしまいましたが、今回は2025/05/09にマイクロソフトとセールスフォースの研究チームによってarXivに投稿された論文LLMs Get Lost In Multi-Turn Conversationを紹介します。
この論文は、LLMとの会話におけるsingle-turnとmulti-turnの違いについて分析したもので、弊社で提供しているStoryHubのプロダクト設計思想を補強する論文だったので、その点もご紹介したいと思います。
論文紹介
概要
現代のLLMサービスの多くは、ユーザーとの対話を前提としたチャットインターフェースを採用しています。このインターフェースにより、私たちはLLMに対して明確な指示を一度で与えるだけでなく、対話を重ねながら段階的に目的を達成することも可能になっています。
本研究は、LLMとの対話におけるsingle-turn(1往復の会話)とmulti-turn(複数往復の会話)の違いに着目し、大規模なシミュレーションを通じてその特性を分析したものです。分析の結果、調査対象となったすべてのLLMにおいて、multi-turnの会話ではsingle-turnと比較して顕著な(-39%)性能低下が確認されました。
研究の主要な発見
研究チームは200,000件を超える会話シミュレーションを実施し、多ターン会話における以下の2つの重要な性能低下を明らかにしました。
-
aptitude(能力): LLMの基本的な応答性能が緩やかに低下 (-15%) -
unreliability(信頼性): 出力結果のばらつきが著しく増大 (+112%)
LLMは対話の早い段階で得た前提に過度に依存して最終結論を出す傾向にあり、その結果、multi-turnの会話ではsingle-turnと比較して顕著な性能低下が確認されました。
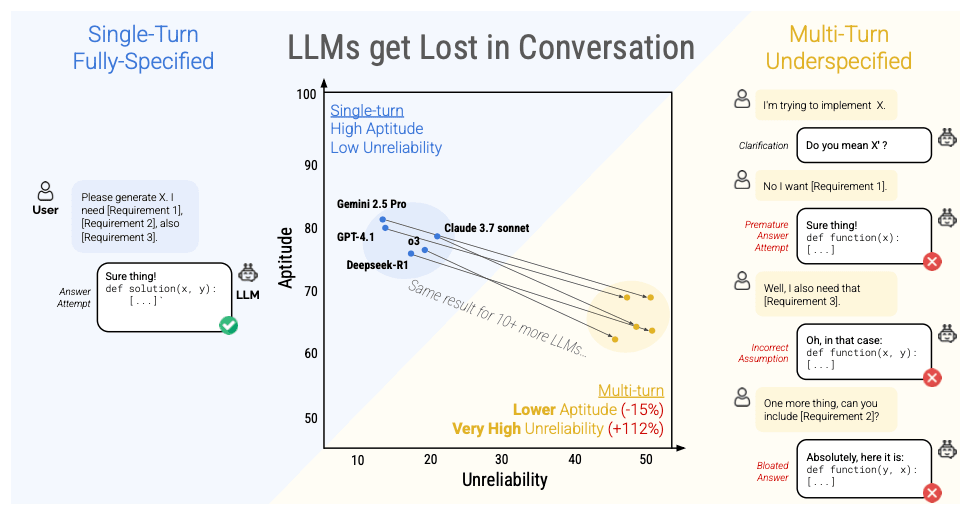
実験した全てのLLMにおいて性能が劣化したことを示す図
縦軸の
aptitudeはLLMの応答精度で、最良ケースのパフォーマンスを示し、上に行くほど性能が高いことを表す。
横軸のunreliabilityは出力結果のばらつきで、最良と最悪ケースのパフォーマンスの差を示し、左に行くほどばらつきが小さく安定したパフォーマンスであることを表す。
この図においては左上に行くほど理想的な状態であり、すべてのモデルにおいてsingle-turnの会話の方がmulti-turnの会話よりも性能が高いことがわかる。
実験手法
シャード化した指示の生成
この実験においては、GSM8Kのテストセットをsingle-turnとして扱い、さらにその指示を分割(シャード化)してmulti-turnの指示を作成しています。
シャード化するにあたって、まず最初のシャードに基礎となる高レベルな指示を記述し、後続のシャードでそれにまつわる補足情報や条件が段階的に追加されていくようにしています。
シャード全体で見た時には元の指示と同じ情報を含むように分割指示データが作成されています。
元の指示(single-turn) |
シャード化した指示(multi-turn) |
|---|---|
 |
 |
実験パイプライン
本実験は人間とLLMの会話を複数のLLMを組み合わせたシステムでシミュレーションすることで大量の会話データを収集・評価しています。
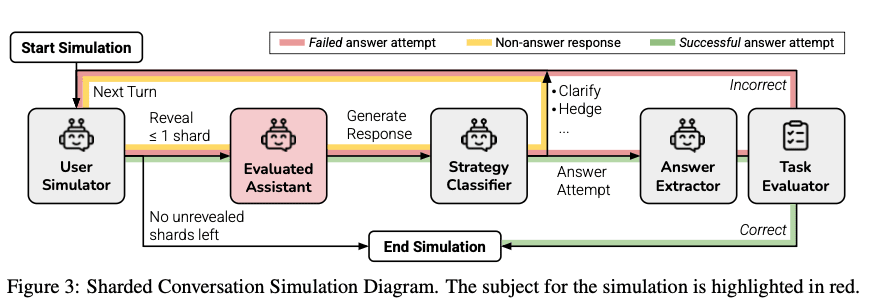
各ステップに登場するコンポーネントの役割は以下のとおりです。
-
User Simulator: 指示を出すユーザーの役割を果たすLLM
- 初回にはシャード1を提示する
- 2回目以降は話の流れに沿ったシャードを選択して提示する
-
Evaluated Assistant: ユーザーの指示に応じて回答を生成するLLM
- このLLMが実験の対象となる
-
Strategy Classifier: 会話の流れを判断するためのLLM
-
Evaluated Assistantの回答をクラスタリングするためのLLM -
Herlihy et al. (2024) の手法を採用して7つのクラスに分類
- Answer Attemptに分類された場合はその回答を評価
- それ以外のクラスの場合は会話を継続する
-
- Answer Extractor: 回答を抽出するためのLLM
-
Task Evaluator: 回答の質を評価するコンポーネント
- ここはLLMではなく、各タスクに応じた評価関数によってスコアリングされる
Evaluated Assistant以外のLLMはGPT-4o-miniが使用されており、User Simulatorが提示するシャードが無くなるか、Task Evaluatorによって正解が出たと判断されるまで会話が続けられます。
今回の実験では、ユーザーの会話をLLMによってシミュレートしていますが、事前に人力で数百件のやりとりをアノテーションしてシミュレーションの精度を評価しています。結果は誤差は5%未満であり、その中でもアシスタントに対して不利になるものは2%未満だったので、研究チームはこのシミュレーションには一定の信頼性があると主張しています。
シミュレーションの種類
上でシャード化した指示から5種類の会話を作成し、それぞれに対して会話をシミュレートしています。
| シミュレーションの種類 | 説明 | 狙い |
|---|---|---|
| FULLY-SPECIFIED | シャード化していないオリジナルの指示文 | 各LLMの性能のベースラインを評価する |
| SHARDED | シャード化した指示文をそのまま利用 | シャード化による性能低下を評価する |
| CONCAT | シャード化した指示文を箇条書きで結合し、「全て考慮して答えるように」という指示を追加して一度に提示 |
SHARDEDとの比較を行うための対照実験 |
| RECAP |
SHARDEDの会話の最後にこれまでの会話を一括提示するrecapitulation turnを設け、最終応答の機会を設ける |
最後の要約によってLLMの性能低下を改善できるかを評価する |
| SNOWBALL | 前ターンまでの要約の提示を毎ターン繰り返し、指示文を雪だるま式に増やして提示 | 複数ターンに渡るコンテキスト記憶負荷を低減することで性能が保たれるかを評価する |
対照実験として特に重要なのはCONCATとSHARDEDです。
FULLとSHARDEDの比較だけでは、LLMの性能に差があった場合にもmulti-turn化による性能低下なのか、シャード化による性能低下なのかを判断できません。
CONCATを用いることで、FULLとCONCATで成功する指示がSHARDEDでは失敗するケースがあった場合、その要因がシャード化ではなくmulti-turn化によるものであることを確認できます。
評価指標
本研究では、以下の3つの評価指標を用いてLLMの性能を評価しています。
各タスクにおけるスコア(S)を用いてそれぞれ以下のように計算されます。
averaged performance(
aptitude(
unreliability(
実験結果
multi-turn化による平均性能の低下

実験結果は上の画像の通りで、実験対象の15種類のLLM、6つのタスクの全てにおいて平均性能が低下していることがわかります。
FULLとSHARDEDの比較で平均**39%**の性能低下が見られる一方、FULLとCONCATの比較では90%以上の性能を保っていることがわかり、multi-turn化による性能低下が顕著に見られました。
最高性能のGemini-2.5 Proや推論モデルであるOpenAI o3においても30~40%の性能低下が見られています。
最高性能とばらつきの分析
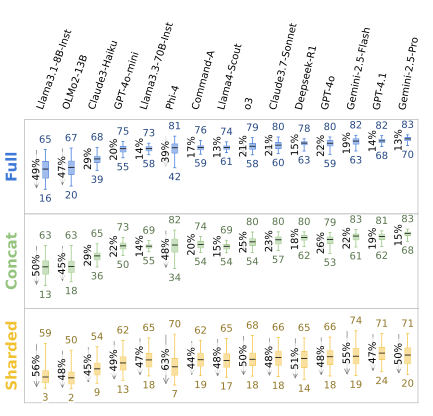
上の箱ひげ図を見るとわかるように、平均性能は劣化したものの、最高性能(Aptitude)の劣化はそこまで大きくありません。
その一方で、回答のばらつき(Unreliability)は大きく増加し、2倍以上になっていることがわかります。
研究チームはこの現象を、lost in conversation phenomenon(会話で迷子になる現象)と呼んでいます。
そのほか、RECAPとSNOWBALLの比較や、LLMのTemperature調整による性能変化の違いについても分析していますが、記事が非常に長くなってしまうので割愛させていただきます。
考察とまとめ
現在のLLMはmulti-turn化によって性能が大きく低下し、その改善にはRECAPやSNOWBALLのような手法やTemperatureの調整があまり有効でないという結果が得られました。
研究チームはLLMの開発者たちにmulti-turnな会話におけるモデルのreliabilityを改善することに優先して取り組むように提言しています。
各種LLMのAPIを用いたサービスを提供している私たちにとってもこの論文の結果は非常に興味深いものです。最高性能を誇るモデルであっても指示の渡し方によって性能が大きく変動するということを前提としたプロダクト設計が必要であるということが示唆されており、ChatGPTをラップしたような単純なチャットインターフェースではない体験を提供することが重要なのではないかと思います。
StoryHubでの事例
我々は提供しているAI編集アシスタントStoryHubのベータ版を通して、チャット形式でのやり取りではユーザーの望むアウトプットを出すことが難しいことを見出しました。
そこで昨年9月の正式版リリースでは「レシピ機能」を実装し、提供を開始しています。
レシピ機能では、メディアの専門家のノウハウが詰まった基本指示と各メディアが持つ一次情報を組み合わせて1つのプロンプトを作り上げ、それをもとにLLMにワンショットでアウトプットを生成させます。これによって日々のワークフローにLLMを導入する際の3つの大きなハードルを同時に解決しています。
- プロンプトを書くのが難しい
- メディアの専門家が監修したオフィシャルレシピとチームメンバーが作り上げたオリジナルレシピを使うことでプロンプトを書くのが苦手なひとでもAIを使いこなせる

- メディアの専門家が監修したオフィシャルレシピとチームメンバーが作り上げたオリジナルレシピを使うことでプロンプトを書くのが苦手なひとでもAIを使いこなせる
- 生成物のクオリティが安定しない
- 論文中に示唆されている通り、必要な指示と1次情報をレシピにまとめて実行することで
Unreliabilityを抑えることができる
- 論文中に示唆されている通り、必要な指示と1次情報をレシピにまとめて実行することで
- 入出力トークンが嵩んでしまう
- チャット形式ではやり取りを行うごとに利用トークンが2次関数的に増加するのに対し、レシピ機能では1回の実行で済むため、利用トークンは線形に抑えられる
このレシピ機能を実際に日々のワークフローに取り入れ、1ヶ月でコンテンツ数2.5倍、PV約2倍に成長したメディアの活用事例もご紹介しておきます。
興味のある方は下記LPなどからお気軽にお問い合わせください。
まとめ
今回はマイクロソフトとセールスフォースの研究チームが発表した論文LLMs Get Lost In Multi-Turn Conversationを紹介しました。
LLMはmulti-turnな会話において性能が顕著に低下することが示されています。この結果はLLM開発者とLLMを活用したプロダクト開発者の双方にとって重要なものだと思われます。
弊社ではすでにこの傾向を踏まえたプロダクトを提供しており、今回の大規模な実験を通してその有効性が示唆されたことを非常に嬉しく思っています。
引き続きLLMの特性を踏まえた上でより使いやすく、より安定したサービスを提供できるように取り組んでいく所存です。
引用元
LLMs Get Lost In Multi-Turn Conversation
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, Jennifer Neville

Discussion