株式会社StoreHero CTOの鳥居です。
弊社では特に今年に入ってから本気でAIを活用するべく、様々なチャレンジを行っています。
その中の一つの例として、今回は自律型AIエージェントDevinを利用して、元々の課題だった社内のデータ基盤整理に活用した事例をご紹介いたします。
記事の内容サマリ
- [仮説] 自然言語で正確なクエリが生成出来ると、クエリ作成依頼が減るはず
- [現状] ドキュメント化されていないBigQueryのデータ分析基盤
- その基盤をdevinがdbtで構造化
- その構造化されたデータを元に、自然言語でSQLを生成する
課題: 頻繁なクエリ依頼と、データ構造の未ドキュメント化
弊社StoreHeroは、Shopifyに特化したECグロース支援を行っており、広告運用からサイト改善・CRM・在庫管理まで、データに基づいた戦略でEC事業者様の成長をサポートしています[1]

つまり業務上、グロース支援メンバーがほぼ毎日のようにストア分析を行いながら売上改善のサポートを行っています。
そのような状況もあり「こういう条件の顧客セグメントを抽出したい」「こういう条件の売上データを分析したい」といったアドホックなSQLクエリ作成依頼が頻繁に開発メンバーに日々舞い込んできます。
これらに都度対応していると無視できない工数になってしまいます。
そこで 「AIに自然言語で指示してクエリを生成させられないか?」 と考えました。
データ構造問題
しかし、ここで大きな一つ課題があります。
AIにクエリを作らせるには、まずAI自身が弊社のデータ構造、つまり
- どのテーブルに
- どんなカラムがあり
- それが何を意味するのか
を正確に理解している必要があります。
現状も利用している弊社のデータ分析基盤[2]ですが、自分が入社する前から構築されたものであり、それらが全くドキュメント化されていない状態でした。
この状況ではおそらくAIに構造を理解させるのは難しいでしょう。
この「意味不明なデータ群」をどうにか整理し、AI(そして人間も)が理解できる形に構造化すること、それが今回のミッションの中核でした。
最終的なゴールとしては
AIがデータ構造を理解し、自然言語による指示で適切なSQLクエリを生成してくれる
状態です。
解決までの計画:Devin × dbtによるデータ構造化計画
ご想像どおりではありますが、この作業自体結構手間のかかるものであり、かつ後回しタスクになりがちなものです[3]
このタスクをDevinに丸投げできないか?と考えました。
幸いにも、ほとんどのスキーマはShopify APIスキーマと一致するものが多く、これを利用すれば半自動的にドキュメント化できそうです。
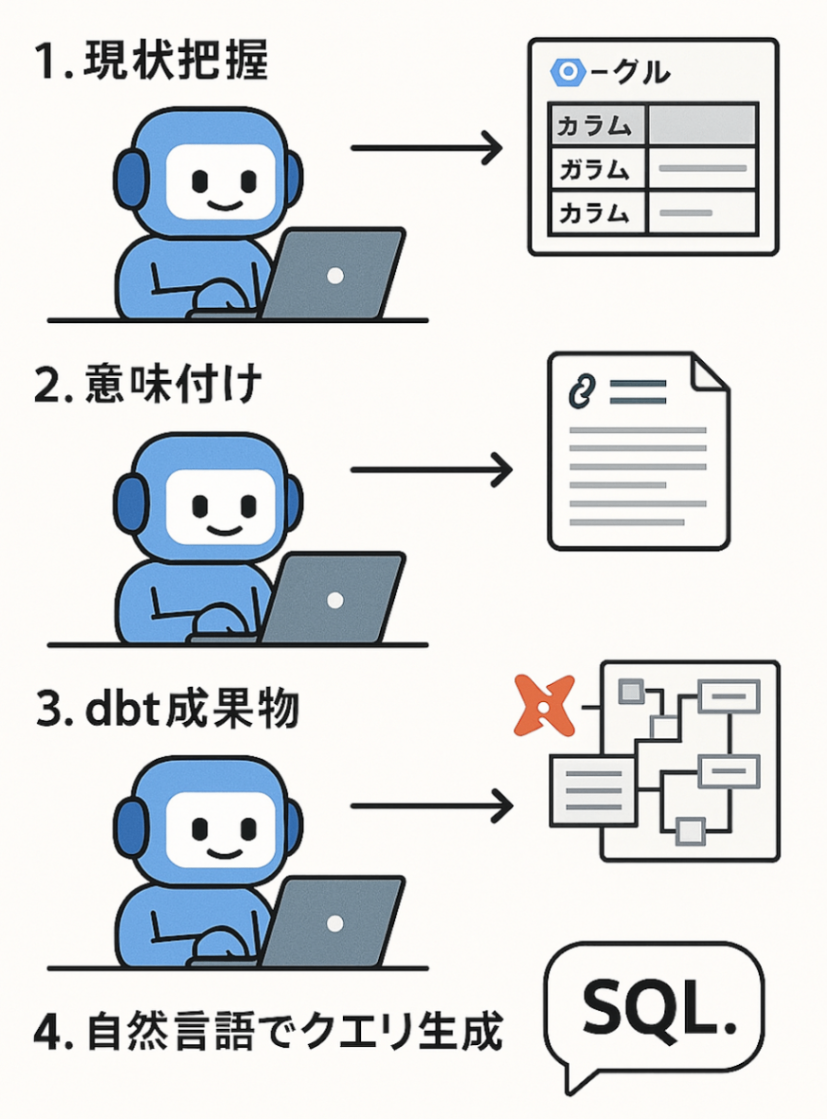
Devinを選んだ理由は、単にコードを書くだけでなく、以下のようなプロセスを 自律的に 行ってくれると期待したからです。
- 現状把握(devin): DevinがBigQueryの既存のテーブルやカラムの構造をリストアップ
- 意味付け(devin): Shopifyの公開APIドキュメントのURLなどをDevinが自発的に調査し、各データ項目がビジネス上どのような意味を持つのかを整理する
- dbt成果物(devin): 1. 2. の情報をマッピングし、データモデリングツールであるdbt (data build tool) の形式で整理・出力させる。またさらにAIが解釈しやすいように再整理する
- 自然言語でクエリ生成(人間がLLMを利用): 3. のデータをプロンプトに与えて、クエリ生成できること
これらのプロセスを「エンジニアの手から離れて勝手に実行」してくれたら完璧です!
計画通りに進めば、データ構造がdbtによって整理され、さらにAIによる自然言語クエリ生成も実現できそうです。
※この画像はAI生成(DALL·Eなど)によるものです
実践:Devinとの協業によるdbtプロジェクト構築
Step 1: BigQueryの現状把握
Devinに現状把握してもらう上で、まずはBigqueryの必要最低限の権限を付与する必要があります。
AIの権限周りではリスクを最小限に抑えるため、以下のような運用にしています。
- 同じ構造を持つテスト用データセットのみへのメタデータ読み込み権限と、ジョブ実行権限だけを与えたサービスアカウントを作成し、
- サービスアカウント認証jsonをdevinのsecretへ登録

devinには「この情報を利用してね」とお願いした上で作業を行ってもらいました。
Step 2: Shopify APIドキュメントの読解
次に、抽出したテーブル・カラム情報に「意味」を与えるため、ShopifyのAPIドキュメントをDevinに読み込ませます。実際のプロンプトはこちら

Step 3: dbt成果物
step1 / step2 で必要なデータが揃ったところで、いよいよdbtモデルの生成を指示します。
ただここがやはりなかなかうまくは行かず、試行錯誤しながら対話してdevinに構築を進めてもらいました。[4]
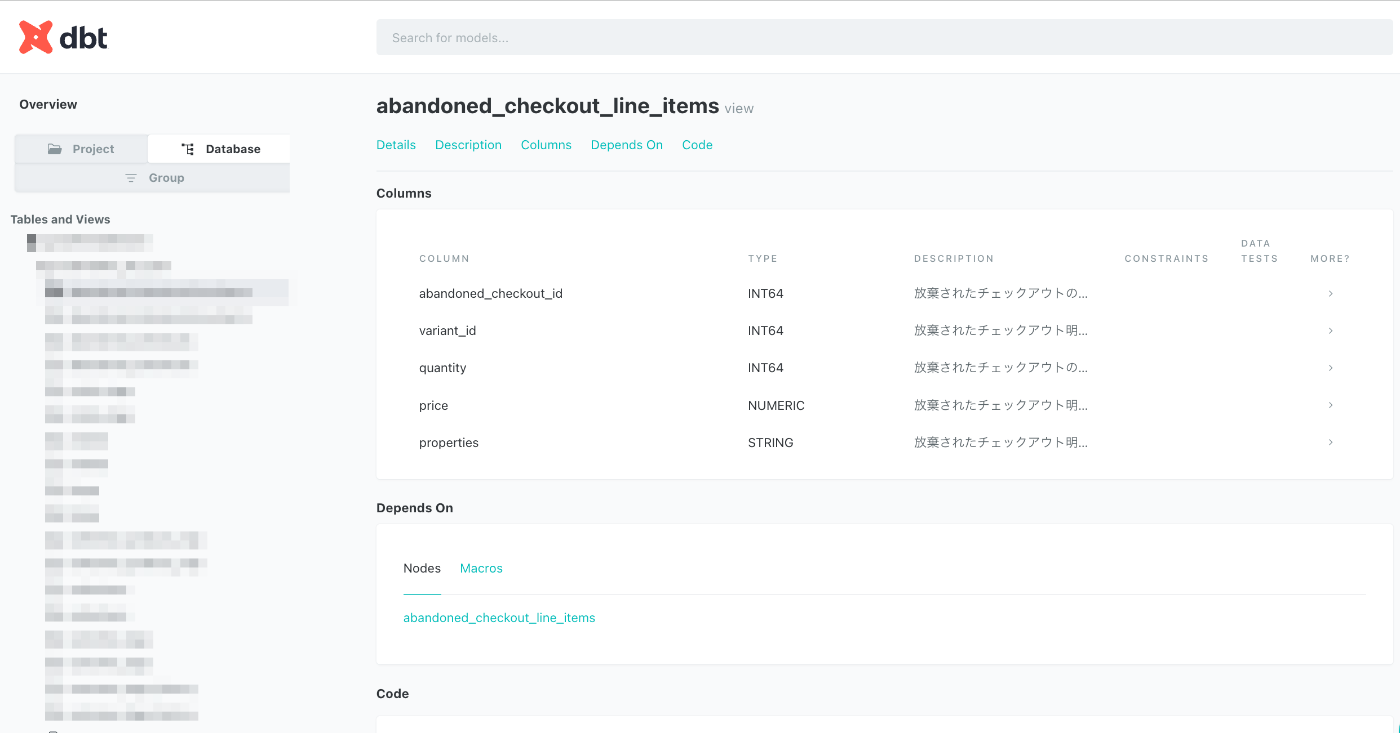
最終的な成果物としては
dbt docs generate
で生成される、静的なcatalog.jsonです。
Step 4: 自然言語でSQL生成
step3の成果物を元にLLM[5]にそのまま食わせたところ「ファイル大きすぎ」と言われたので、クエリ構築に必要最小限な以下の情報だけ残すようなファイルを作るようにしました。
この作業ももちろんdevinにおまかせです。
- スキーマ名
- スキーマ説明
- カラム名
- カラム説明
- リレーション情報
そして、最終目標であった「自然言語でのクエリ生成」の検証です。
上記で調整した成果物をLLM先に渡した上で、依頼されたクエリを実行してみました。

どうやらうまく行ったようです!🎉
これにより、メンバーからの定型的なクエリ作成依頼は大幅に削減できる見込みが立ちました。
またそれ以上に大きいのは、これまでブラックボックス化していたデータ構造がdbtによって可視化・共有可能になり、データに基づいた議論や施策立案ができるようになったことです。
まとめと考察
結果として エンジニアがコードを一切書かずにデータ基盤整理を実現 できました!🚀
今回の事例を通じて、Devinのような自律型AIエージェントは、データ基盤整理のような複雑なタスクにおいても十分活用できるものであると実感しました。
もちろん、AI活用は一発でうまくものではなく、実際に触れてみて試行錯誤しながら「AI自身も」そして「AIを利用する側も」両軸で成長させていくことが大事なのではないかと思いました。
今回の事例が、皆さんのAI活用の一助となれば嬉しいです!

Discussion