【図解】OllamaとOpen WebUI でローカルLLMの環境構築する手順|大規模言語モデル・生成AIをDockerで動かす
はじめに
ChatGPTなどの生成AIが普及する中、「ローカル環境で大規模言語モデル(LLM)を動かしたい」と考える方も増えてきました。とはいえ、LLMのセットアップには専門知識が必要で、「何から始めればいいのか分からない」「軽量モデルってどこで動かせるの?」と迷う人も多いと思います。本記事では、OllamaとOpen WebUIというツールを使って、ローカルでLLMを動かすための環境構築手順を、図解を交えて解説します。
構築する環境のイメージ図は以下です。Dockerコンテナを2つ作ってChatGPTのようにブラウザからプロンプトを打てるようにします。PCにNVIDIA製のGPUと搭載していないとOllamaを扱えないようなのでご注意ください。
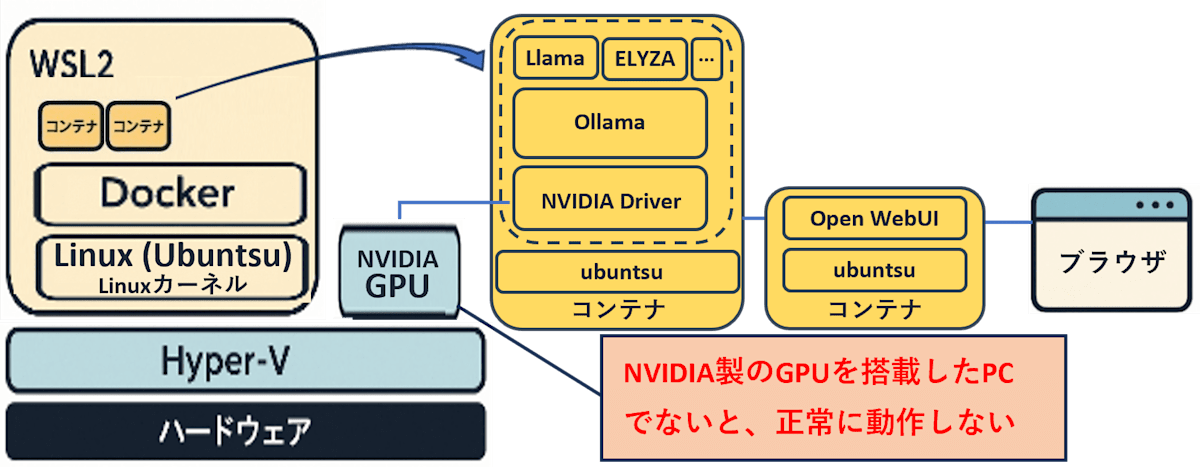
なお、筆者のPCは「ASUS ゲーミングノートPC:FX707VV-I7R4060A5200」(OS:Windows11、CPU:インテル Core i7-13620H プロセッサー、メモリ:16GB、ストレージ:1TB、GPU:NVIDIA GeForce RTX 4060)です。
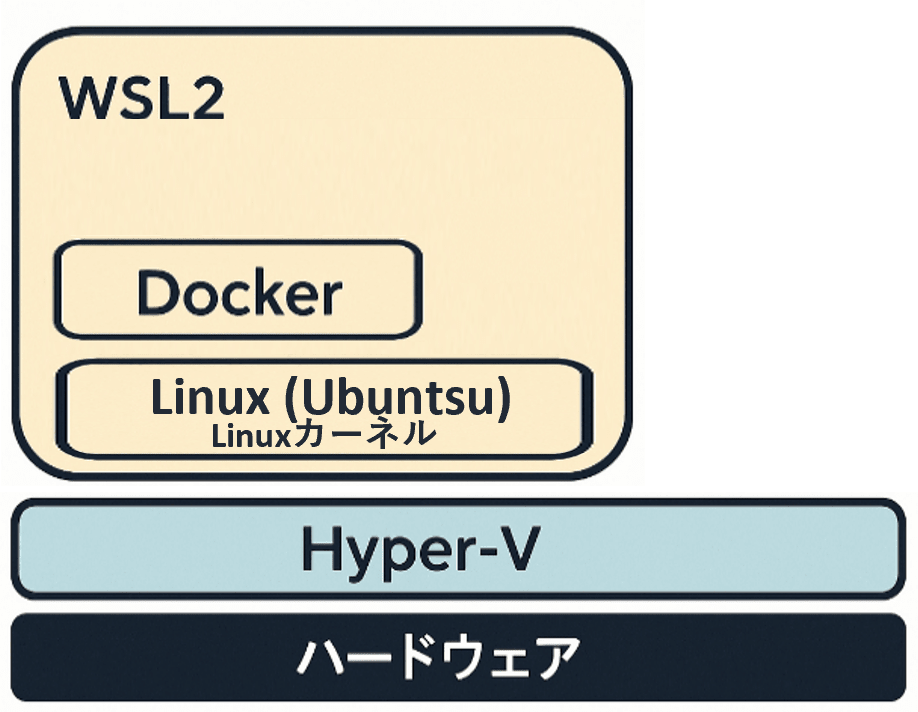
1. Docker環境を構築する
記事「【図解】Windows11でWSL2+DockerによるPython開発環境を構築する手順」の「1. WSL2でUbuntuをインストールする」「2. Docker EngineをUbuntuにインストールする」を参照ください。
ここまでの完成図
これ以降、Linux上でコマンドを実行します。ubuntuのbashを起動させるか、PowerShell上でwsl ~でwslを起動させてから後続の作業を進めてください。
2. Ollama用のコンテナを作成する
2-1.NVIDIA Container Toolkitをインストールする
NVIDIAのガイドやOllamaのガイドに沿ってインストールします。
$ curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
$ sudo apt-get update
$ sudo apt install -y nvidia-container-toolkit
インストールが完了したら、dockerデーモンを再起動します。
$ sudo systemctl restart docker
2-2.Ollama用のコンテナを作成・起動する
Ollamaのガイドに沿って、コンテナを作成・起動します。
$ docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
2-3. NVIDIA Container Toolkitの動作確認をする
コンテナ内外でnvidia-smiを実行した時に、同様の出力がされればOKです。
$ nvidia-smi
$ docker exec -it ollama /bin/bash
$ nvidia-smi
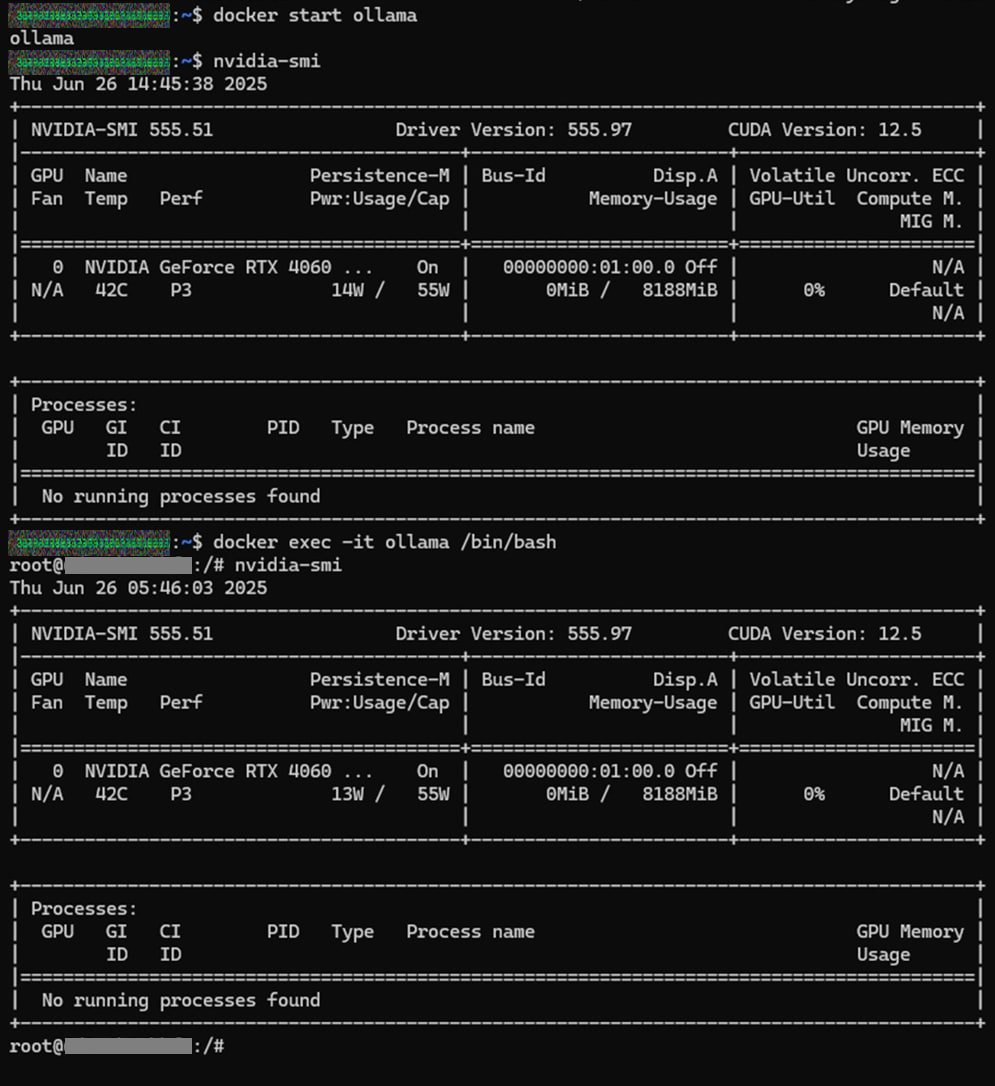
ここまでの完成図
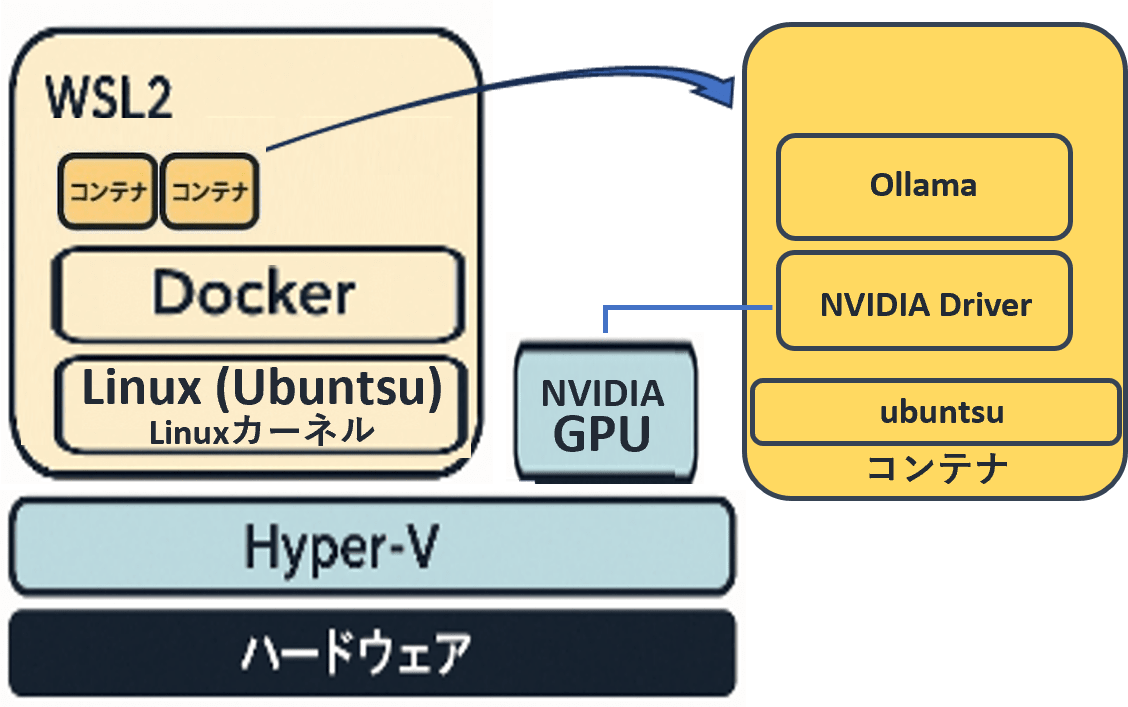
3. OllamaのlibraryにあるLLMをコンテナに乗せる
使いたいモデルをOllamaのlibraryからインストールします。例えば、Llama(llama3.1:8b)をダウンロードする場合は、以下のコマンドを実行します。
$ docker exec ollama ollama pull llama3.1:8b
サイズが大きいLlama4やMistral-largeは精度が良く実用的なようですが、個人用PCでの利用はおすすめしません。インストールに3時間程度かかる上に、結局PCのスペック不足で動かないことが多いようです。
ここまでの完成図
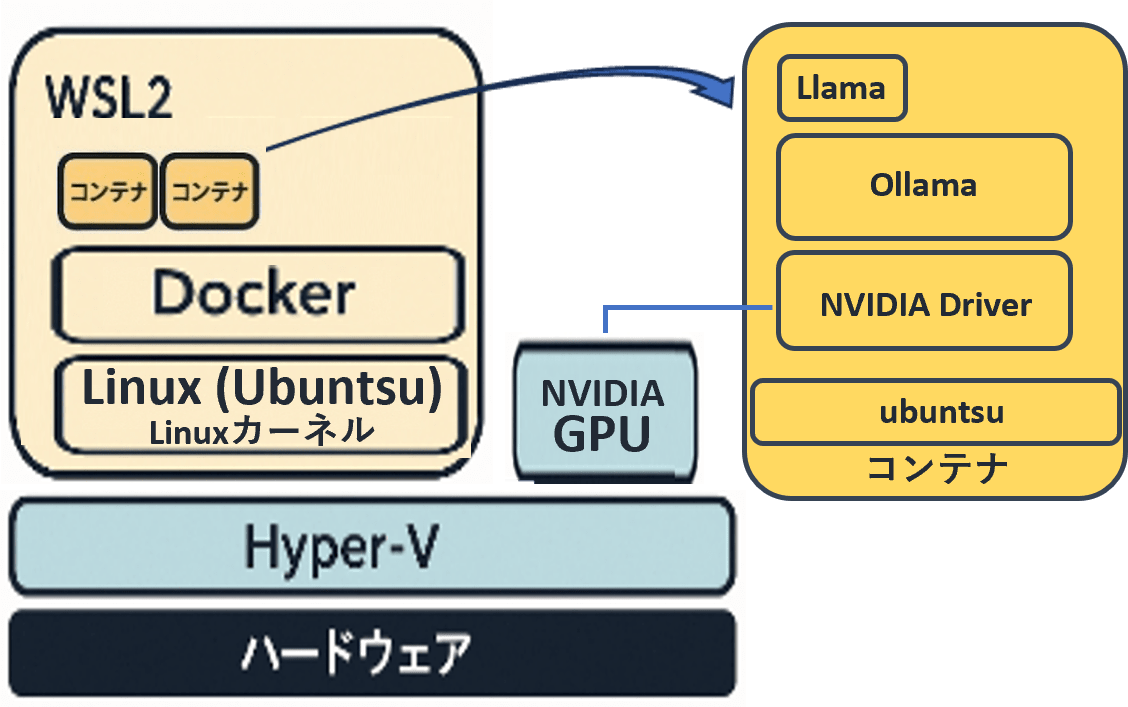
4. 任意:OllamaのlibraryにないLLMをコンテナに乗せる
Ollamaのlibraryにないモデルであっても、gguf形式のモデルであればOllamaで動かすことができます。本記事ではELYZA(Llama-3-ELYZA-JP-8B)をコンテナに乗せる方法を紹介します。
4-1. gguf形式のモデルファイルをダウンロードする
hugging faceのページから「Llama-3-ELYZA-JP-8B-q4_k_m.gguf」をダウンロードします。
4-2. Modelfileを作成する
モデルの作成に必要な情報を記載したModelfileファイルを作成します。
FROM ./Llama-3-ELYZA-JP-8B-q4_k_m.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|reserved_special_token"
4-3. gguf形式のモデルとModelfileをコンテナ内に配置する
PCのローカルにあるgguf形式のモデルとModelfileを、コンテナ内の同じ場所に配置します。
$ cd [現状の配置場所] #gguf形式のモデルとModelfileが配置されている場所に移動
$ ls -ltr #gguf形式のモデルとModelfileが配置されていることを確認
$ docker cp ./Llama-3-ELYZA-JP-8B-q4_k_m.gguf ollama:/Llama-3-ELYZA-JP-8B-q4_k_m.gguf #gguf形式のモデルをコンテナ内にコピー
$ docker cp ./Modelfile ollama:/Modelfile #Modelfileをコンテナ内にコピー

4-4. モデルを作成・起動する
(Ollama用のコンテナが起動している状態で)以下を実行します。実行後に「success」と表示されればOKです。
$ docker exec ollama ollama create elyza:jp8b -f Modelfile

ここまでの完成図
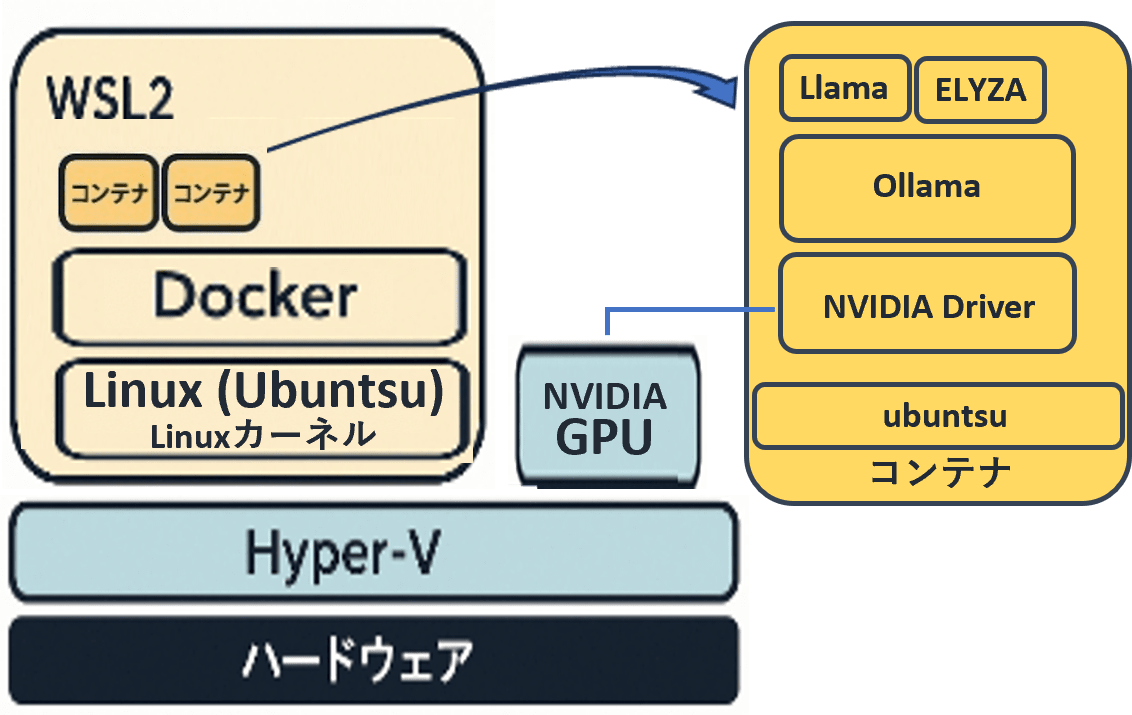
5. Open WebUI用のコンテナを作成する
以下を実行し、Open WebUI用のコンテナを作成してOllama用のコンテナと繋いで起動します。
$ docker run -d -p 3000:8080 --env WEBUI_AUTH=False --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
ここまでの完成図
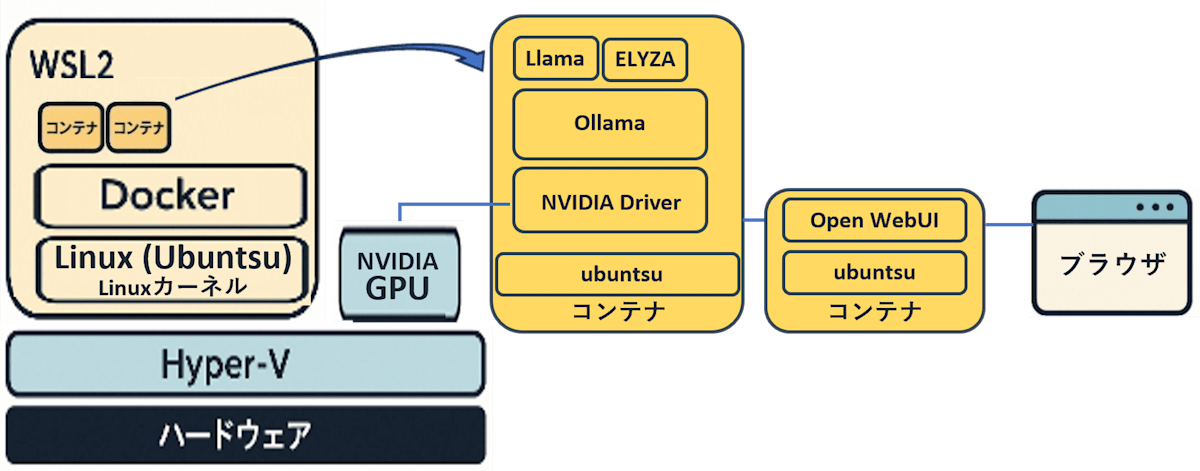
6. 動作確認する
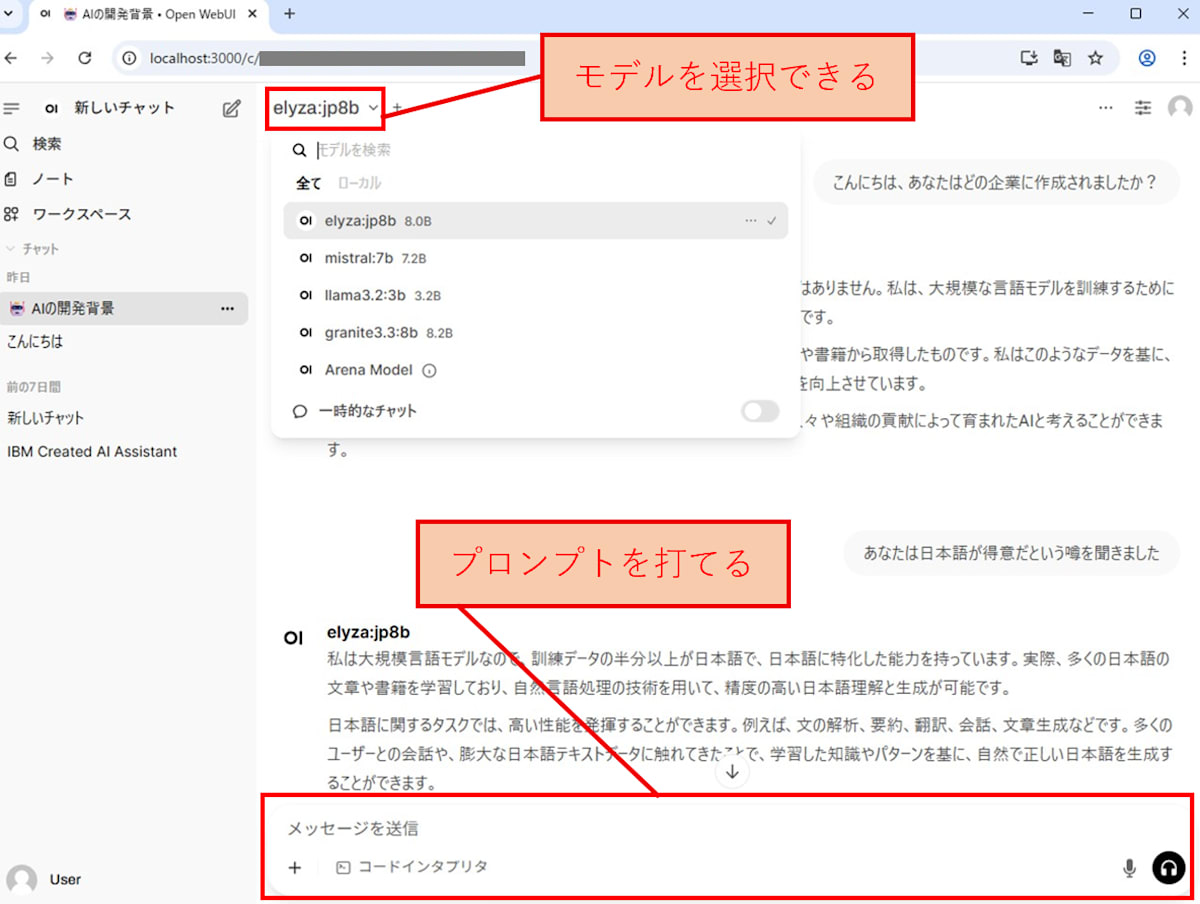
6-1. LLMをブラウザから動かしてみる
ブラウザでhttp://localhost:3000/にアクセスして、モデルが使えるか確認します。
6-2. おまけ(よく使うコマンド)
Ollamaを再起動する時は以下を実行します。
$ docker restart ollama
インストールしたモデル(例:llama3.2:3b)を削除したい時は以下を実行します。
$ docker exec ollama ollama rm llama3.2:3b
一度Linuxを停止した後、再度LLMを使う際は以下を実行します。
$ docker start ollama # Open WebUIはOllamaと一緒に起動される
$ docker stop open-webui # open-webui用のコンテナを停止する
$ docker stop ollama # Ollama用のコンテナを停止する
$ exit # wslの外に出る
$ wsl --shutdown # wslを停止する
おわりに
今回は、OllamaとOpen WebUIを使ってローカル環境でLLM(大規模言語モデル)を動かす方法を解説しました。Dockerを活用することで、OSに依存せず再現性の高い環境を構築でき、生成AIを手元で自由に扱えるようになります。今回の手順をもとに、ぜひご自身の環境でもLLMを立ち上げ、モデルのカスタマイズや応用にチャレンジしてみてください。
Discussion