DAMO-YOLO(物体検出)のファインチューニング手順


概要
YOLOの派生モデルであるDAMO-YOLOを使用して画像内の任意の物体を検出する、ということを行ったのでその手順をまとめて共有します。
検出したい対象の画像を準備し、ファインチューニングを行ったものです。
基本的に公式の情報をなぞっていますが、うまく動かなかった部分や注意点をまとめていきます。
本記事の目標
以下のような画像から、鳥を検出することを考えます。

「3羽の鳥が写っているということを検出する」だけならば、ベースのYOLOモデルを利用するだけで可能なのですが、ここから発展して「左側の鳩と中央・右の白鳥を別々に検出したい」と考えたという問題設定で進めます。
なお、画像はStable Diffusion 3 Mediumで生成しているので、一部おかしなこともありますが無視してください。
YOLOについて
YOLOは高速な物体検出手法の一つです。
You Only Look Onceの頭文字をとってYOLOなのですが、名前の通り「一目見ただけで判断」というコンセプトのものになっています。
ここでは手法の中身自体には触れませんが、バージョンや派生についてだけ簡単に。
YOLOは最初に公開されたあと、v2,v3と進化していましたが、そこから更新が停止し最初の作者とは別の人が引き継ぐ形になりました。
その後も派生版ができたりと、元のYOLOとは異なるものがどんどん公開されています。
歴史や派生については詳しい記事がありますので、興味のある方はどうぞ。
DAMO-YOLO
今回はこのYOLOファミリーの中から、比較的最近まで更新されていること・扱いやすいライセンス・提供されている情報量などを加味して、DAMO-YOLOを選択しました。
ベースモデルの実行
では早速動かしていきます。
手元のUbuntu環境とGoogleのColaboratory環境で動作を確認しましたが、みんな手軽に使えるColaboratory環境で動かすことを想定して以下サンプルコードを書いていきます。
また、YOLOの実行のみの場合はGPUなしで問題ありませんが、学習までさせたい方はランタイムタイプを変更 → T4 GPU を選んでおきましょう。無料版で問題なく動きます。
まずインストール部分から。
!git clone https://github.com/tinyvision/damo-yolo.git
!pip install -e damo-yolo/
次にGitHubのページを参照して、学習済みモデルをダウンロードします。
今回はDAMO-YOLO-Tを使ってみます。
!wget https://idstcv.oss-cn-zhangjiakou.aliyuncs.com/DAMO-YOLO/release_model/clean_model_0317/damoyolo_tinynasL20_T_420.pth
このモデルとサンプルのデモコードを使って物体認識を行おうとしたところ、描画関連のエラーが出たので、まず以下を調整します。
-
damo-yolo/tools/demo.py#L321
描画のためのvisualize関数の第一引数にorigin_imgをそのまま入れるのではなく、cv2で変換したものを入れます。
vis_res = infer_engine.visualize(origin_img, bboxes, scores, cls_inds, conf=args.conf, save_name=os.path.basename(args.path), save_result=args.save_result)
↓
image_cv = cv2.cvtColor(origin_img, cv2.COLOR_RGB2BGR)
vis_res = infer_engine.visualize(image_cv, bboxes, scores, cls_inds, conf=args.conf, save_name=os.path.basename(args.path), save_result=args.save_result)
-
damo-yolo/tools/demo.py#L253
保存部分も同様に調整します。
cv2.imwrite(save_path, vis_img[:, :, ::-1])
↓
cv2.imwrite(save_path, cv2.cvtColor(vis_img[:, :, ::-1], cv2.COLOR_RGB2BGR))
その後、実行コマンドがこちら。
GPUありの場合は --device cuda、CPUのみの場合は --device cpuを指定。
ちなみにYOLOはCPUのみでも十分高速に動作します。
!(cd damo-yolo && python tools/demo.py image -f configs/damoyolo_tinynasL20_T.py --engine ../damoyolo_tinynasL20_T_420.pth --conf 0.6 --infer_size 640 640 --device cuda --path ../test.png)
実行結果は、damo-yolo/demo/に出力されて、こんな結果になります。

最も小さい学習済みモデルでも綺麗にbirdが検出されています。
さて、ここから鳩とそれ以外を分けるようチューニングすることを考えます。
ファインチューニング手順
狙った物体を検出できるようにするためにファインチューニングを行います。(ファインチューニングとは?は別記事をご覧ください・・・)
実行方法については、こちらのページに記載されていますが、まずは学習するデータを作成するところからスタートが必要です。
Finetune on your data
学習データの準備
ファインチューニングを行うために、正解となるデータが必要です。
ここが鳩、ここが白鳥、という座標とラベルを設定したデータです。
これを一つ一つ画像と睨めっこして座標を調べて設定していくのは非常に大変なので、支援してくれるツールを使いましょう。
Label Studio
こういった学習データの作成支援ツールは色々ありますが、今回はLabel Studioを使ってみます。
画像以外にも様々なものに対応しているようです。
とりあえず使ってみるだけならdockerで一発です。
docker run -it -p 8080:8080 -v $(pwd)/mydata:/label-studio/data heartexlabs/label-studio:latest
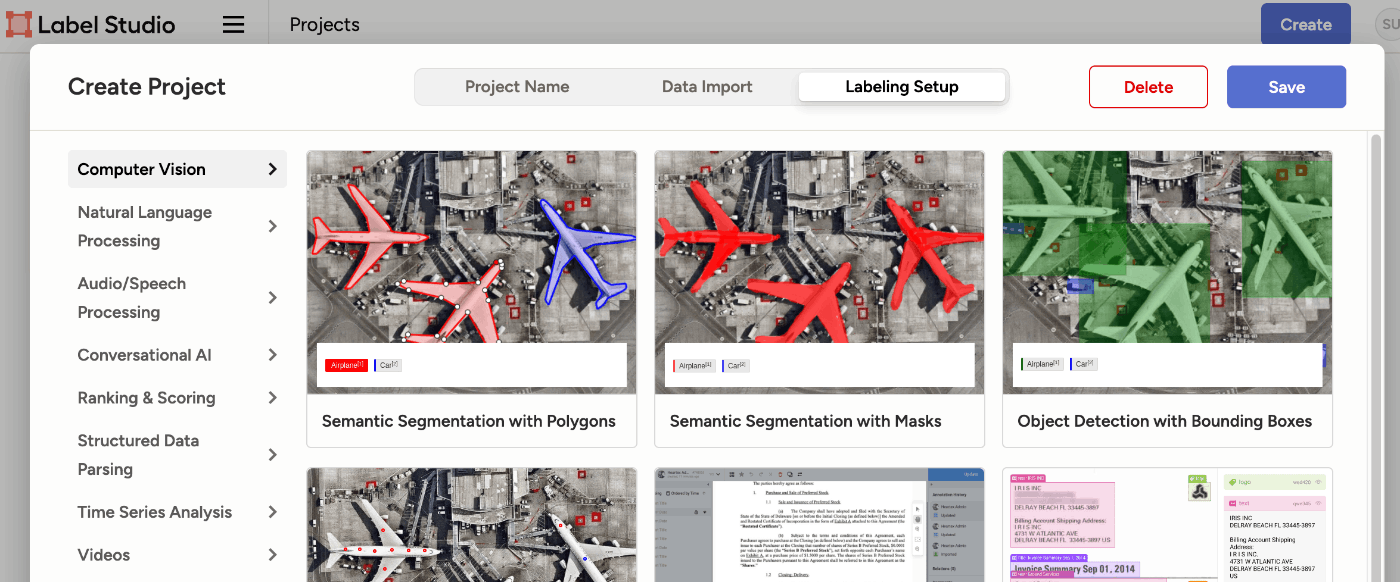
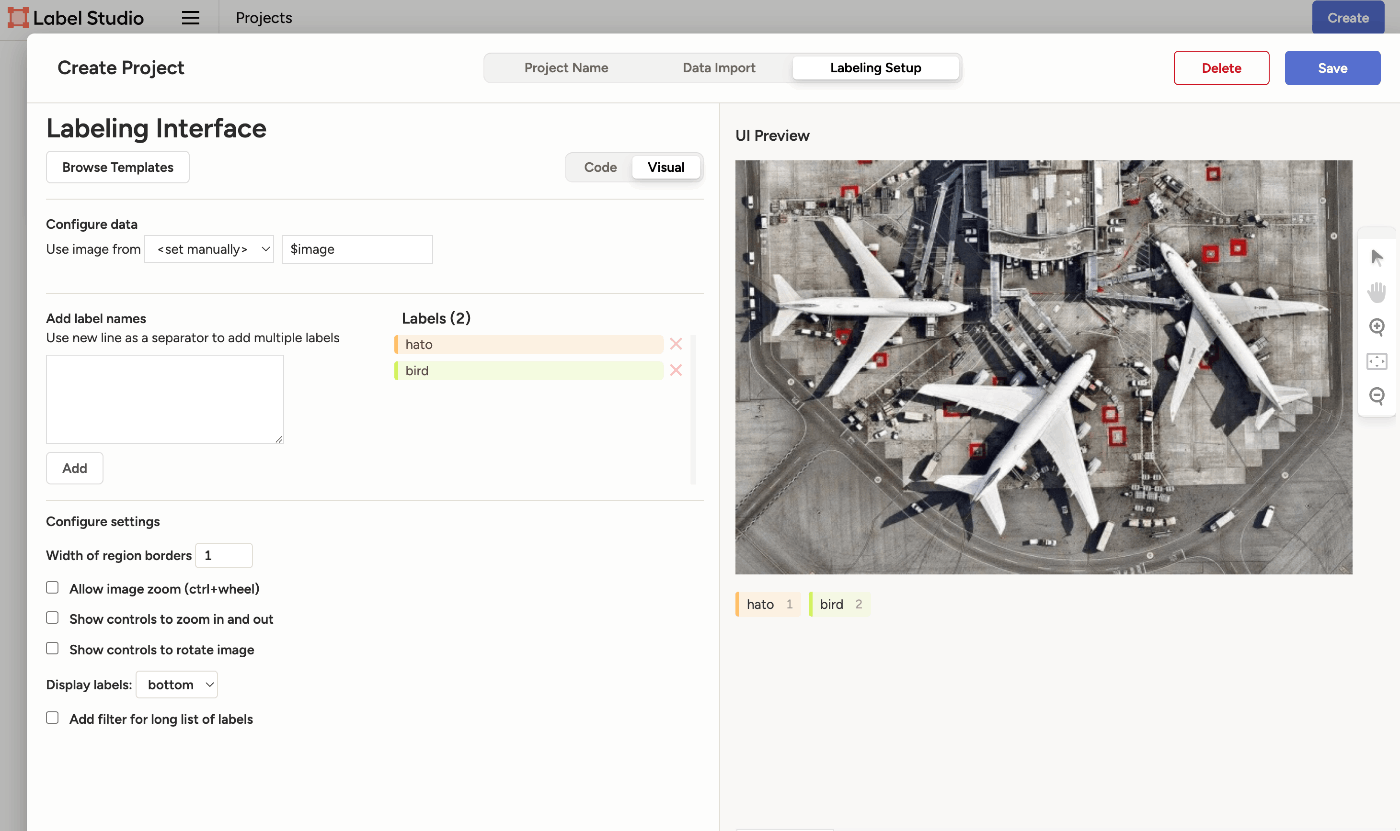
- プロジェクトをCreateし、Computer Vision > Object Detection with Bounding Boxes を選択
- 必要なラベルを設定
- 画面上で領域を定義していく
1
2
3
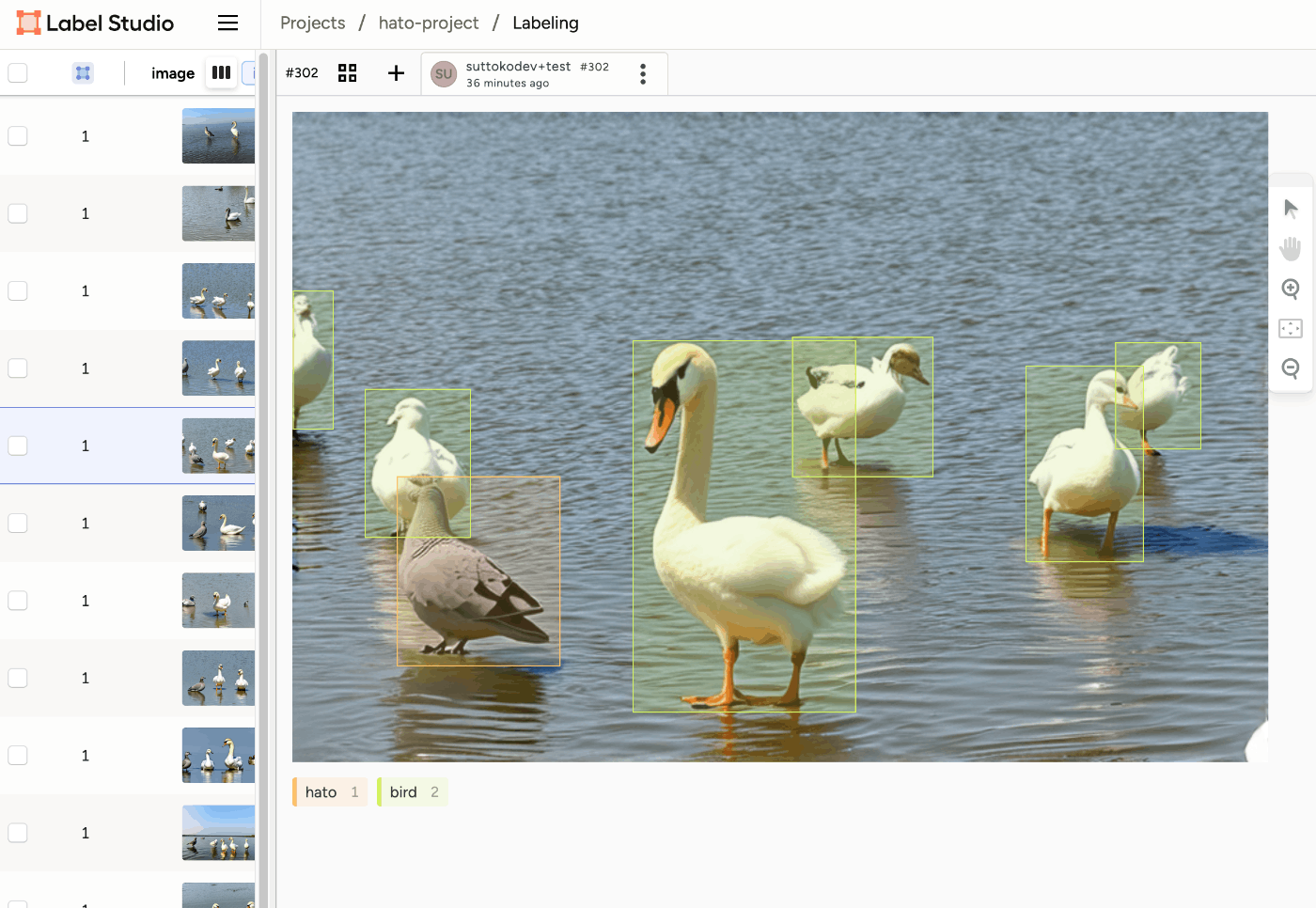
学習用の画像は何枚作ればOKというのはないのですが、大体の感覚としてラベル一つにつき100枚ぐらいあれば精度安定してくるなという印象です。
お試しでやるには大変なので最初は少なめでどうぞ。
フォーマット調整
データができたら、Exportして最終調整します。
Export形式はCOCOにします。
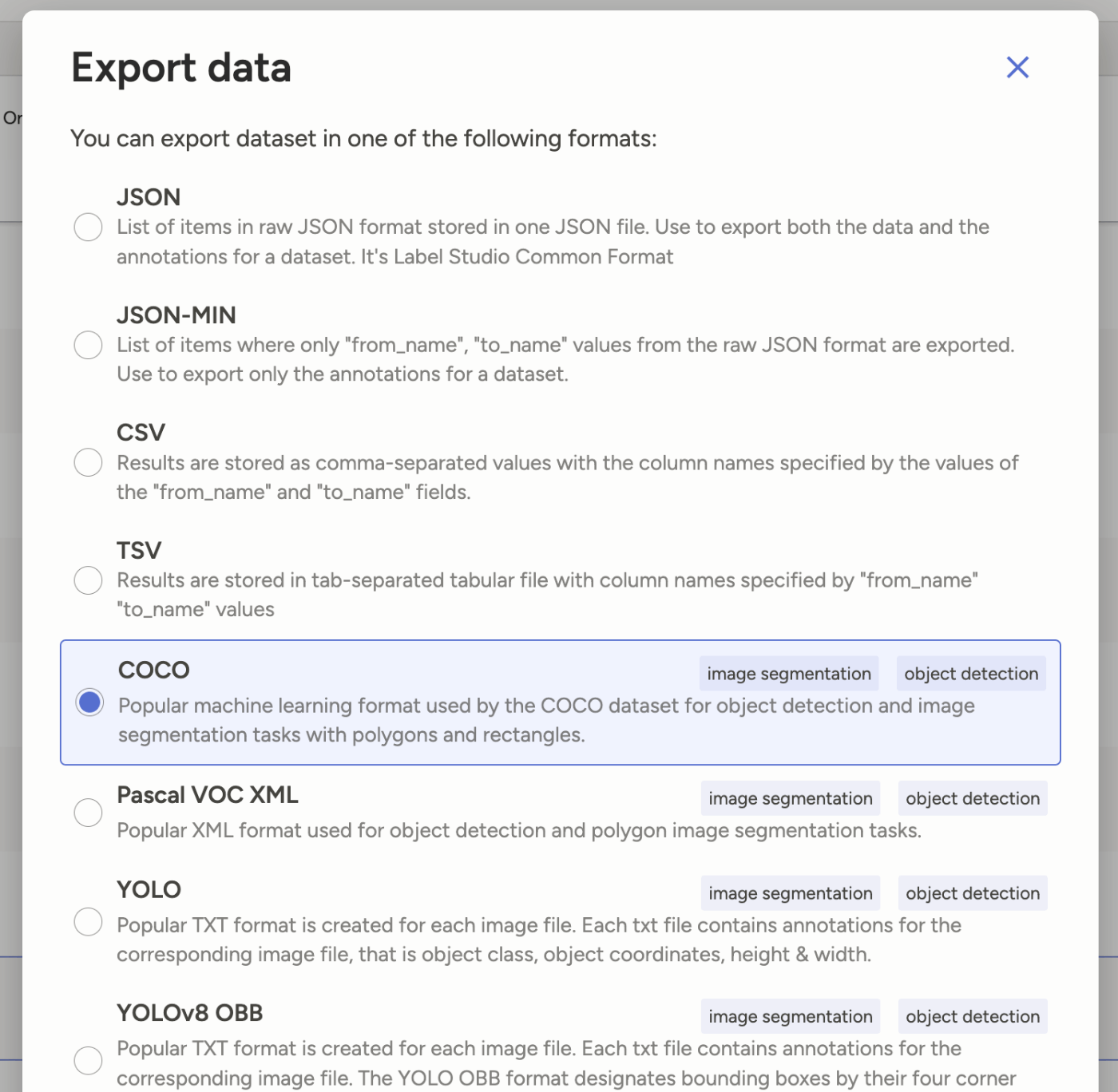
これで、image/ディレクトリとresult.jsonが生成され、ダウンロードされたと思います。
※オプション
学習させる時に、学習用データ(train)と検証用データ(valid)を指定するのですが、result.jsonを2つに分けて、result.train.jsonとresult.valid.jsonを作っておきます。
具体的にはresult.jsonをコピーして、result.train.jsonとresult.valid.jsonを作成した上で、
{
"images": [
{
"width": 768,
"height": 512,
"id": 0,
"file_name": "images\/4ccbafac-sample_000.png"
},
{
"width": 768,
"height": 512,
"id": 1,
"file_name": "images\/0baa1c2e-sample_1_007.png"
},
...
trainでは↑のようになっているimagesのリストのうち7割ぐらいを残し、validでは残りの3割ぐらいを残して他のimageは消します。
これで、7割で学習して3割で検証しつつモデルの学習を進めていくことになります。
ですが、データ数が少ない場合やとりあえずのお試しの場合はtrainとvalidを分けず、両方ともresult.jsonを指定してしまって問題なさそうです。
元のサンプルでもそうなっています。(少し過学習が心配ですが)
設定の追加
学習の準備を行なっていきます。
まず、上記で準備したimages/とresult.jsonをdatasetsに配置します。
damo-yolo/
└ datasets/
└ my_dataset/
├ images/
└ result.json (or result.train.json / result.valid.json)
次に設定ファイルを作成します。
必要なファイルは二つで、
- damo-yolo/config/paths_catalog.py への追記
- damo-yolo/configs/damoyolo_tinynasL20_T.py をコピーして編集
します。
paths_catalog.py
追加するデータのパスを設定します。
名前に coco の文字を入れておくと良いようです。
'mydata_train_coco': {
'img_dir': 'my_dataset',
'ann_file': 'my_dataset/result.train.json'
},
'mydata_valid_coco': {
'img_dir': 'my_dataset',
'ann_file': 'my_dataset/result.valid.json'
},
ここで、result.jsonを2つに分けていない場合は、両方ともにresult.jsonを設定してください。
tinynasL20_T.py
my_damoyolo_tinynasL20_T.py のデータセットの指定とclass_namesの設定を書き換えます。
まず、データセットの設定です。上記のpaths_catalog.pyに記載した名称を設定します。
self.dataset.train_ann = ('mydata_train_coco', )
self.dataset.val_ann = ('mydata_valid_coco', )
次にカテゴリの設定で、学習させるラベルの数と名前を定義します。
num_classesに数、class_namesに名前を列挙します。
ZeroHead = {
'name': 'ZeroHead',
'num_classes': 80, #この記事の例の場合は 2 にする
self.dataset.class_names = ['bird', 'hato'] #元は80程度のカテゴリが列挙されている
ここの指定順番はresult.jsonの中のcategoriesに記載されている順番になるよう注意してください。
また、必須ではありませんが、画像が多くなりGPUメモリを食いすぎる場合はこちらのbatch_sizeを小さくすると動く場合もあります。
# optimizer
self.train.batch_size = 256
学習の実行
学習準備が整いました。
学習コマンドはこちら。
!(cd damo-yolo && torchrun --nproc_per_node=1 tools/train.py -f configs/my_damoyolo_tinynasL20_T.py)
こちらは元の記載ではエラーが出ました。おそらくtorchのバージョンアップに伴うものと思われるので上記の書き方にしています。
これで学習が始まるので結果を待ちます。
20枚程度の学習データだと10分程度で終わりました。
300枚程度の学習データだと3時間ぐらいかかったこともありますので、画像の量や大きさなどにより学習時間は結構変化すると思っていただければと思います。
実行結果は
damo-yolo/workdirs/my_damoyolo_tinynasL20_T/latest_ckpt.pth に保存されます。
ではこちらを使って改めて鳥の検出を行なってみましょう。
!(cd damo-yolo && python tools/demo.py image -f configs/my_damoyolo_tinynasL20_T.py --engine ./workdirs/my_damoyolo_tinynasL20_T/latest_ckpt.pth --conf 0.4 --infer_size 640 640 --device cuda --path ../test.png)
--conf は検出の閾値です。追加学習が十分ではない場合、なかなか検出されない場合もあるので数値を上げ下げしてどの程度の精度で検出できているか確認しましょう。
参考までに学習中のリソース状況。
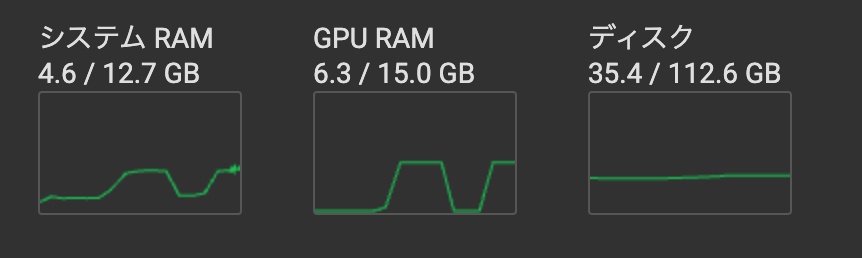
結果

さらに学習に使っていない画像で試してみた結果をいくつか。

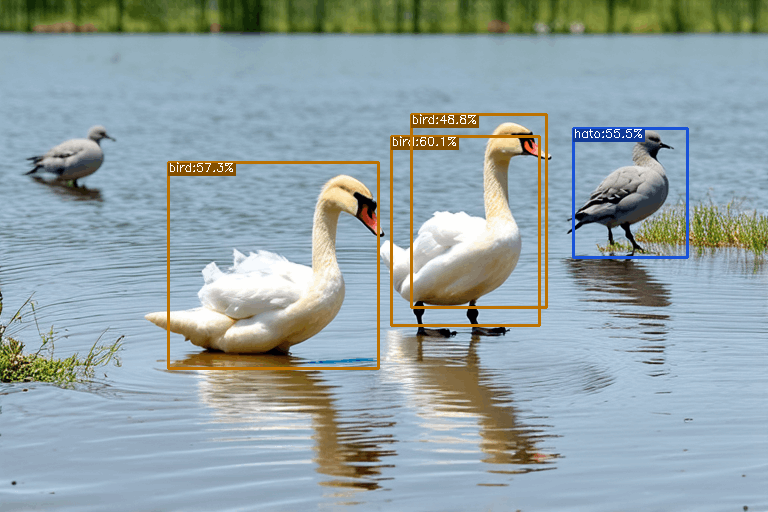
今回はかなり少ない枚数で試したので精度は良くありませんが、最初のモデルでは判定できなかった鳩と白鳥が分離できていることがわかります。
学習データをもっと増やすことでまだまだ精度を上げることはできそうです。
まとめ
ファインチューニングは学習データの準備や学習時間など大変なことも多いですが、逆に言うと頑張れば一人で準備できる程度のデータ量・学習リソースで十分に実用的な精度のモデルが作成できるのが魅力です。(もちろんモデルや解かせたいタスクにもよりますが・・・)
どうも既存のモデルだけだと精度でないなぁという時に参考になれば。
Discussion