Athena分析のためのAWS Glue Crawler活用法: 躓きポイントと解決策
はじめに
S3に保管されているデータ(APIGatewayなどのAWSサービスのログやAppFlowから連携されたSalesForceのデータ)に対してAthenaから分析するために、AWS Glue Crawler(以下クローラ)を使用してGlueテーブルを作成しました。その際に、ちょこちょこ躓いてしまう部分があったので共有します。
そもそもクローラを使う場面とは
Athenaでデータ分析を行う際には、対象データに対してクエリを実行可能なテーブルの作成が必要となります。このテーブル作成には、クローラを使用して自動的に行う方法と、Athenaから直接SQLクエリを使って手動で作成する方法があります。クローラを使用しなくても、Athenaで直接CREATE TABLE文を実行し、テーブルを作成することもできます。
AWSサービスのログであれば、以下のように公式ドキュメントにテーブル作成用のクエリが記載されている場合もあります。(以下はAWS WAFについてのドキュメント)
ただ、対象データの構造が明確でない場合などは、クローラを使用すると便利です。クローラは自動的にS3バケット内のデータを探索し、データ構造を解析してテーブル定義を生成してくれます。データの構造やスキーマをあらかじめ知らなくても、Athenaで分析するための準備が簡単にできます。
また、クローラはスキーマの変更を自動的に検出し、テーブル定義を最新の状態に更新できるため、データの構造が変わっても、分析作業をスムーズに続けることができます。データセットの規模が大きい場合、様々なソースからのデータを扱う場合や、スキーマが頻繁に更新されるような環境では、手動でテーブルを都度更新するのはつらいです…。クローラを使用すれば、これらのスキーマ変更に柔軟に対応できます。
クローラを使用した構成
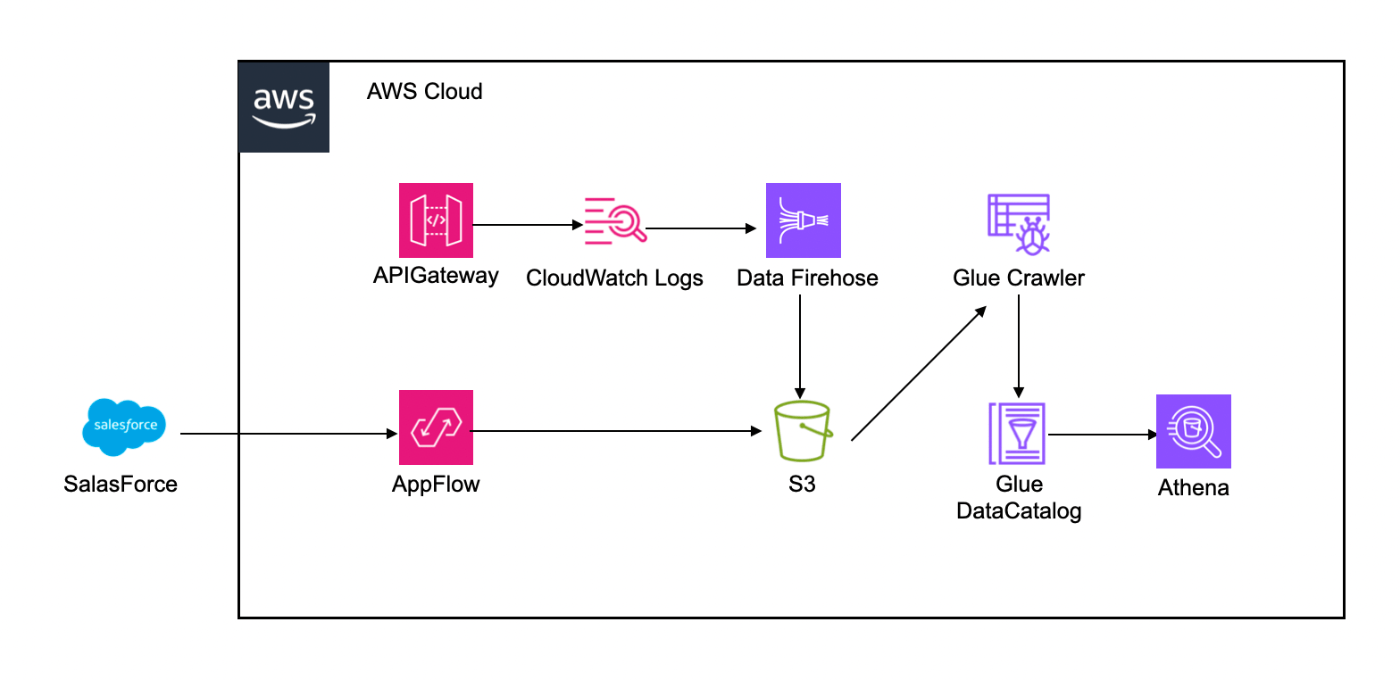
APIGatewayなどのAWSサービスのログはCloudWatchLogsからAWS Data Firehose(2023年2月にKinesisが名前からはずれましたね…Kinesisシリーズの中で一番馴染み深いサービスだったのでなんだか寂しいです)経由で、SalesForceのデータはAppFlowを使ってS3に転送する構成です。
躓いたところ
Firehoseから出力されたログをクローラが識別できない
これは結構あるあるの気がしてます。僕は1回引っかかって対処したのにその1年後ぐらいに完全に忘れててまた同じことをやってしまいました。
CloudWatchLogsのログはFirehoseを経由してGZip形式でS3に出力されますが、拡張子が付与されません(“.gz”などが付かない)。そのためクローラが圧縮形式を読み取れず、スキーマを抽出できません。また、Firehoseで出力するファイルの形式にgzipを指定すると拡張子が付与されますが、もともと圧縮されているデータをさらに圧縮することになってしまいます。
対処方法としては、過去はLambdaで解凍処理を挟むのが一般的でした。ただ、2023年12月からFirehose側で解凍処理を行えるようになっていました。 このアップデートは追加でLambdaを作成する必要がなくなったのでありがたいですね。
FirehoseでLambdaを挟んでいる場合、その実行失敗ログがクローラの邪魔をする
これはFirehoseの転送設定でLambdaを使用してログデータの変換処理などを行っている場合に発生する可能性があリます。そのLambdaがなんらかの理由で実行中に失敗した場合、”processing-failed”というディレクトリが作成されます。このディレクトリが存在している状態でクローラを実行すると、うまくテーブルが作成されません(パーティションをうまく認識できず、日時単位でテーブルができてしまう等)。”processing-failed”ディレクトリはLambdaの実行が失敗しない限り作成されないので、初回のクローラ実行時には気づかず、クローラを定期実行する設定にしているといつの間にかテーブルが増えている、なんてこともあり得ます。私は手動でテーブルを更新するためにクロールを行った際になぜかテーブルが増えていたことに気づきました。
クローラを使用する上で予期せぬテーブルの増加には注意する必要があります。
対処方法としては、クローラの除外パターンに”processing-failed/**”を指定することで回避することができます。クローラはクロールする際に対象にしたくないディレクトリやオブジェクトを指定することでクロール対象から除外することができます。
CSVファイルのクローリングとスキーマの変更
AppFlowでSalesForceのデータをS3に出力する際、ファイルの形式をCSVに設定していました。そのファイルを対象にクローラでテーブルを作成しAthenaでクエリを実行すると、
エラーメッセージ”GENERIC_INTERNAL_ERROR: builder is null”が出てしまいました。
この問題をAWSサポートで問い合わせたところ、クローラはJSON形式の特定のカラムをSTRUCT型にマッピングできない場合があり、JSON形式のカラムをSTRUCT型ではなくSTRING型として定義する必要があるそうでした。そのためCSVカスタム分類子を使用し、全てのカラムの型を事前に定義することで回避しようとしていました。(CSVカスタム識別子は各カラムのデータ型をカンマ区切りで指定できるものです。 )それはもはやクローラを使う意味があるのか…というツッコミはご容赦ください。
ただ、カスタム分類子は各項目にそれぞれ対応する型を定義しているため、スキーマの項目数に増減があると設定が無視されます。そのため、スキーマに更新があった後にクローラを走らせるとまたSTRUCT型の項目が生まれ、Athenaでクエリが失敗するようになってしまうという魔のループが発生します。
解決方法はシンプルで、AppFlowでファイルの形式をCSVからJSONに変更することです。特にCSVである必要がなかったのでJSON方式に変更するとAthenaからクエリが正常に実行できました。JSON or CSVのどちらでも選択できる状況ではJSONにしようと心に誓った瞬間です。
まとめ
クローラはスキーマを手取り早く抽出したい場合に便利ですが、CSVファイルのスキーマ変更やFirehoseからのログデータの取り扱いなど、特定の場面ではちょっとした工夫が必要になる場合があります。様々な種類のデータを迅速に分析できるように、クローラの設定には気を付けて活用しましょう。
Discussion