ZabbixでのCPU監視と負荷テスト: 基本ステップ



はじめに
Zabbixは、オープンソースの監視ソフトウェアで、多様なITインフラストラクチャの監視に役立つツールです。ネットワークデバイスからサーバ、アプリケーションに至るまで、多くの要素を一元的に監視・管理できる特徴があります。今回の記事では、Zabbixを利用してCPUの監視と負荷テストを行う基本的なステップについて紹介します。
記事の取り組み内容
本記事では、Zabbixを使用してLinuxサーバのリソース(特にCPU)の監視に関する手順を紹介します。また、CPU使用率が特定の閾値(本検証では90%)を超過した際の警告の動作確認も解説します。Zabbixサーバーの構築やZabbixエージェントのインストールに関しては、公式サイトに詳細な手順が記載されていますので、本記事では触れません。
検証環境

- 仮想環境: VMWare Workstation 16 Player
- Zabbixサーバ (IPアドレス: 192.168.111.8) ※CentOS 7.9
- Zabbixエージェント (IPアドレス: 192.168.111.5) ※CentOS 7.9
本検証は、VMWare Workstation 16 Playerを使用した仮想環境上で、ZabbixサーバとZabbixエージェント間の通信・監視を実施しています。サーバとエージェントが正常に通信し、指定した閾値を超えたCPU使用率を検出した場合、警告が正しく表示されることを確認する目的で進行します。
- Zabbixバージョン情報:
$ zabbix_server --version
zabbix_server (Zabbix) 5.0.30
1. Zabbixを活用してサーバのCPUを監視する手順
1-1.Zabbixサーバーへのログイン
ZabbixサーバのダッシュボードにWebブラウザを使用してアクセスし、ログインを行います。
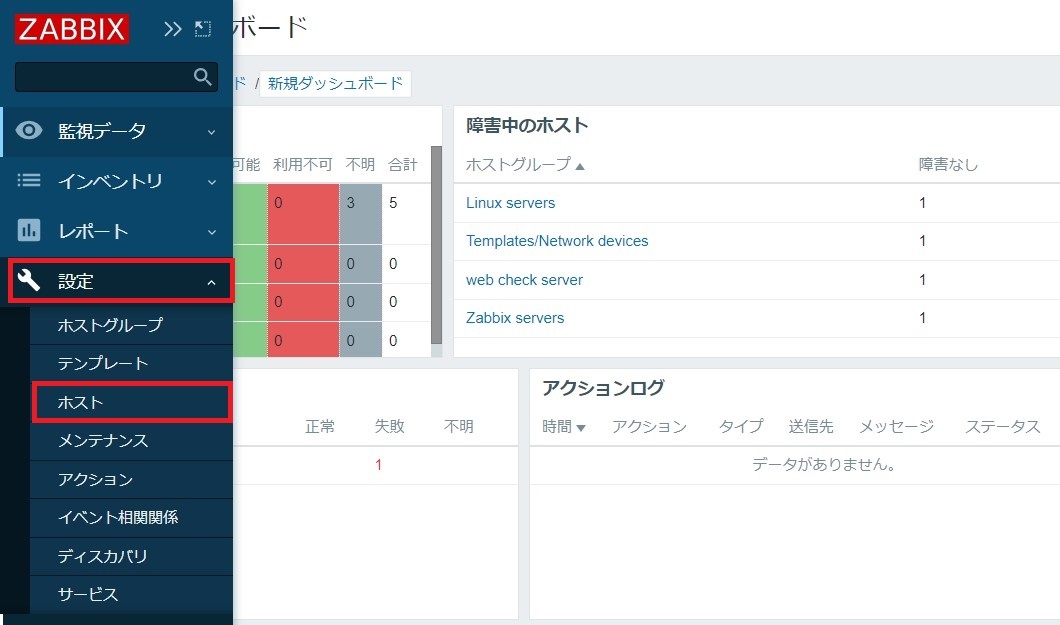
1-2. 「ホスト」の選択
左サイドバーの「設定」を選択後、続いて「ホスト」をクリックします。
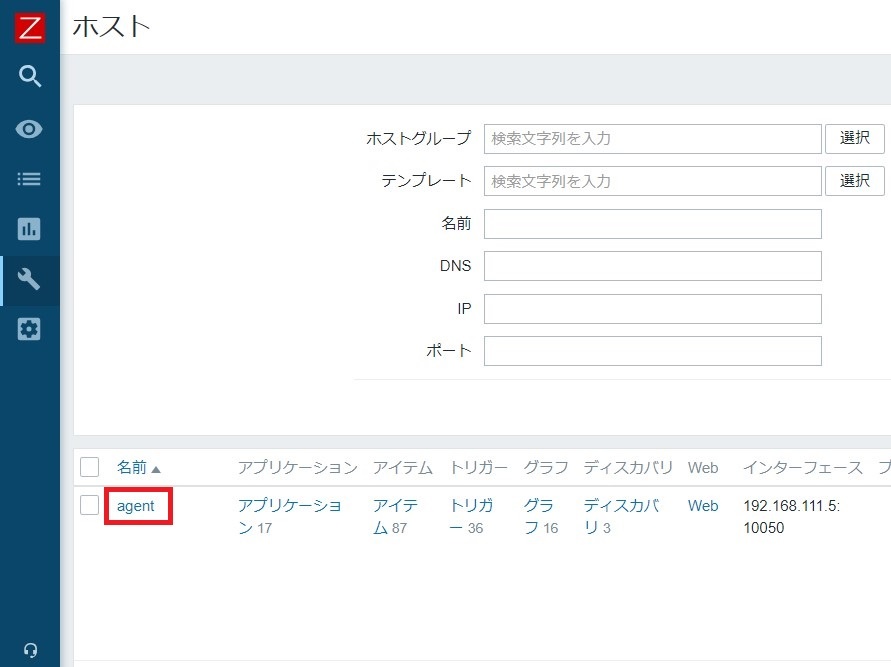
1-3. 対象ホストの選定
監視を希望するホストの一覧から、該当のホスト(Zabbixエージェントを入れたサーバ)をクリックします。
1-4. アイテムの追加
ホストの詳細画面に移動し、「アイテム」タブを選択。その後、右上の「アイテムの作成」ボタンをクリックします。

1-5. アイテム詳細の設定
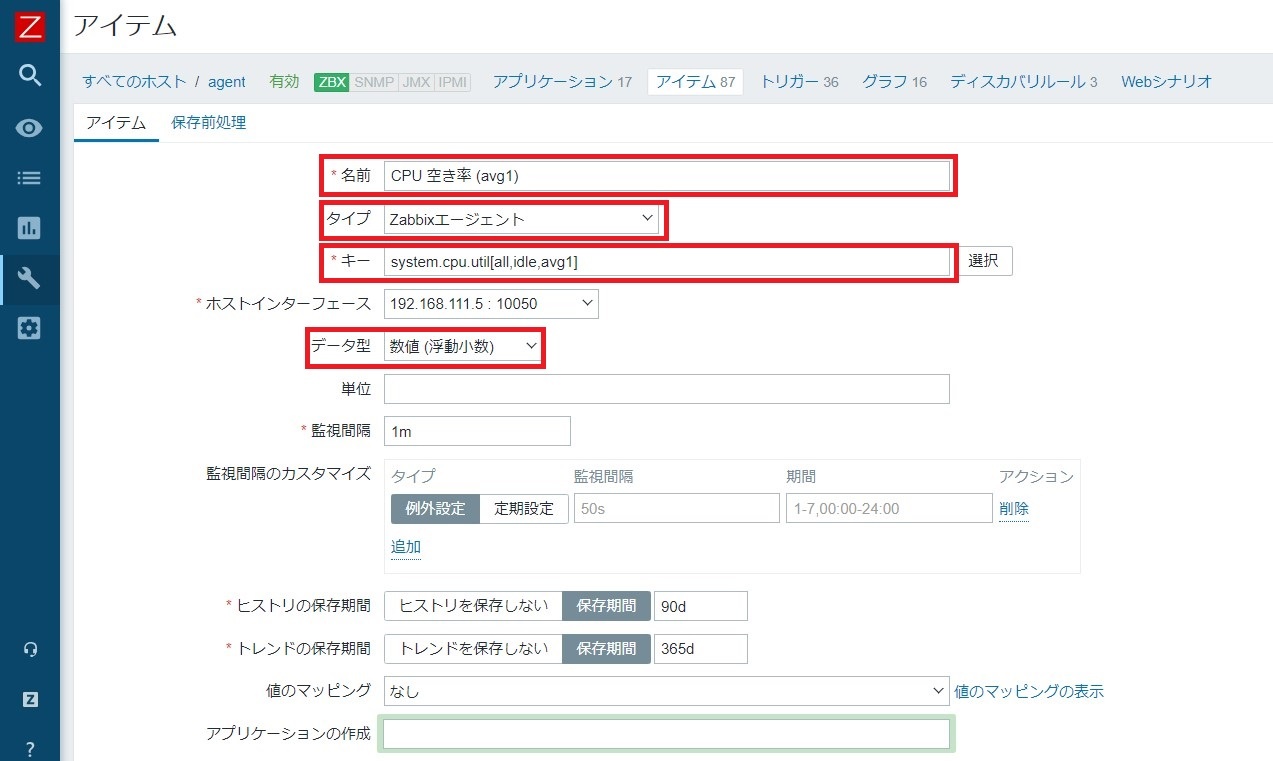
名前: 任意(例: "CPU 空き率 (avg1)")
タイプ: Zabbixエージェント
キー: system.cpu.util[all,idle,avg1]
データ型: 数値 (浮動小数)
他の設定はデフォルトのままで問題ありません。設定完了後、下部の「追加」ボタンをクリックしてアイテムを追加します。
1-6. トリガーの追加

アイテムが追加された後、ホストの詳細ページにて「トリガー」タブを選択。右上の「トリガーの作成」ボタンをクリックします。
1-7. トリガー詳細の設定

名前: 任意(例: "CPU 使用率 90% 超過警告")
条件式: {ホスト名:system.cpu.util[all,idle,avg5].max(#1)}<10
この式は、最新のデータ値が10%未満かどうかを評価します。条件が真の場合(CPU使用率が90%以上)、トリガーが起動します。
深刻度: 任意(例: "警告")
設定完了後、下部の「追加」ボタンをクリックしてトリガーを追加します。
1-8. 監視のスタート
全ての設定が完了したら、ZabbixダッシュボードでCPU使用率が90%を超えた際のトリガー動作を確認します。
これにて、Zabbixを使用してCPUの使用率の監視設定が完了しました。
2. ”stress”を使用したCPU負荷テストの実施
CPUの使用率を上昇させる目的で、stressというツールを用います。このツールは、指定したコア数や時間にわたってCPUやメモリに負荷をかけることができます。
CentOSでのstressのインストールおよび使用手順を以下に示します。
2-1. stressのインストール
sudo yum install epel-release -y
sudo yum install stress -y
2-2. CPUへの負荷実施
stress --cpu $(nproc) --timeout 60
--cpu $(nproc) はシステムに存在する全CPUコアに負荷をかけるための指定です。
--timeout 60 はstressを60秒間実行することを指示します。
このコマンドを実行すると、CPU使用率が増加し、指定した時間が経過すると自動的に負荷が停止します。Zabbixで監視を実施している場合、先に設定したトリガーが適切であれば、この間に警告が生成されるはずです。
2-3. stressコマンド実行例
# stress --cpu $(nproc) --timeout 60
stress: info: [25428] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
stress: info: [25428] successful run completed in 60s
| メッセージ部分 | 説明 |
|---|---|
stress: info: [9868] |
stressの情報メッセージで、[9868]はプロセスIDを示す。 |
dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd |
負荷をかけるリソースとその量を示す。 |
1 cpu |
1つのCPUコアに負荷をかける。システムに複数のコアが存在する場合、1つのコアのみが負荷される可能性がある。 |
0 io |
I/O(入出力)への負荷はなし。 |
0 vm |
仮想メモリへの負荷はなし。 |
0 hdd |
ハードドライブへの負荷はなし。 |
この結果から、stressは指定されたCPUコアだけに負荷がかかっていることがわかります。I/O、仮想メモリ、ハードドライブに対しては負荷はかけられていません。
3. CPU負荷テストの影響を監視データで確認

監視データは、左サイドバーの「監視データ」から参照できます。
負荷がかかった状態(CPU使用率90%以上)

深刻度に「警告」の表示が点灯しています。

障害に表示されているトリガー名からグラフを確認してみます。
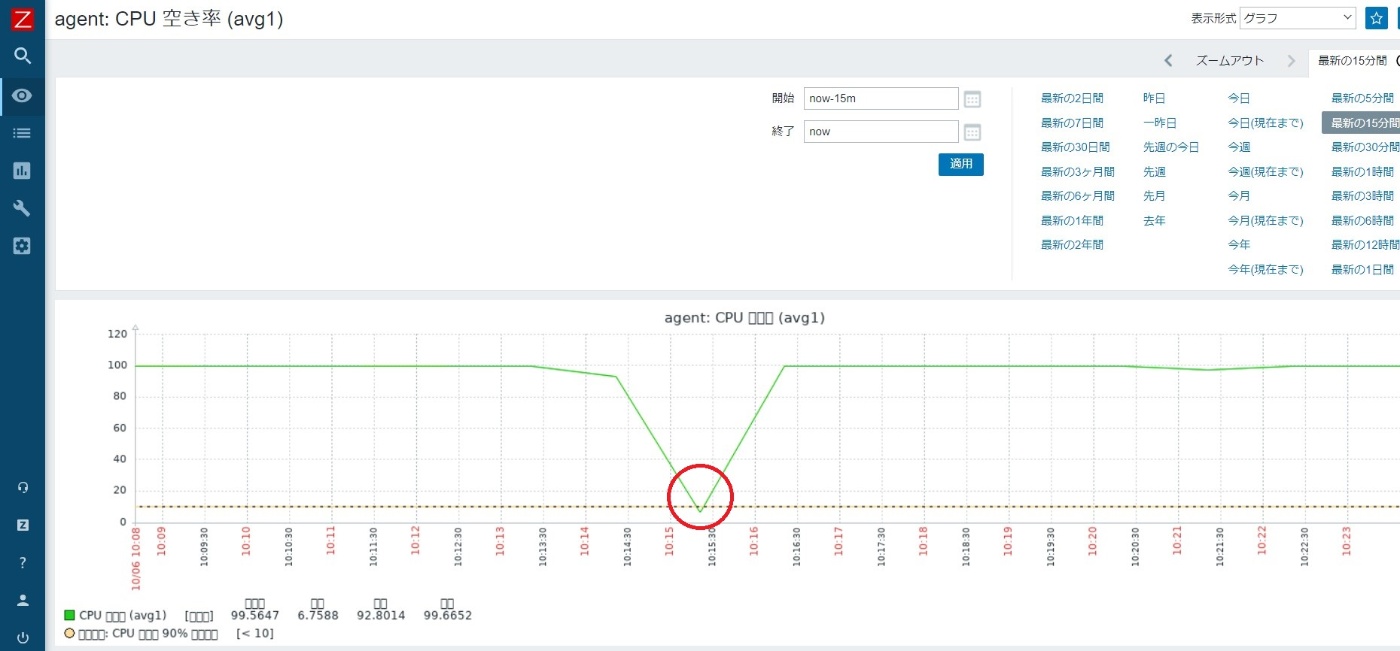
グラフ上でCPUの空き率が10%未満、つまりCPU使用率が90%を超えていることが確認できます。
最後に
Zabbixは多様な監視機能を持つツールです。今回紹介したのはその中の一部に過ぎませんが、検証結果として、CPU使用率が設定した閾値を超過する瞬間や、それに伴う「警告」の表示を確認できました。もちろん、特定のトリガーが作動した際にはメール通知などのアクションも設定可能です。
Discussion